CPU拿到一个虚拟地址,怎么知道它对应哪块物理内存?这个转换过程究竟是怎么做的?
答案是页表(Page Table)。在64位Linux系统上,这是一套精密的四级页表结构。这篇文章,我们把从虚拟地址到物理地址的完整转换过程、TLB的作用与必要性、以及NUMA架构对性能的实际影响,用图解的方式一次讲清楚。
这套知识不只是面试考点,它直接影响你写代码时对内存访问性能的直觉判断。
一、从一个问题开始
进程A和进程B都有一个地址 0x7fff1234。这个地址对两个进程来说是同一块物理内存吗?
不是。虚拟地址是每个进程私有的,同一个虚拟地址值,在不同的进程里指向完全不同的物理内存。
那操作系统是如何做到这一点的?秘诀在于,每个进程都有自己独立的一套页表,这张表记录了“虚拟地址 → 物理地址”的映射关系。
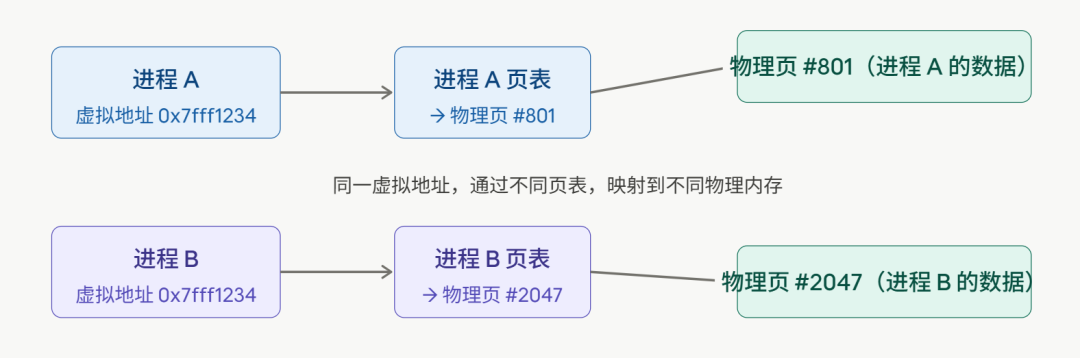
这正是进程隔离的物理基础——它不是什么魔法般的“隔离层”,其本质就是每个进程拥有自己独立的页表。
二、四级页表:64位地址如何拆解
64位系统理论上能寻址16EB(2^64字节),但当前Linux x86_64实现仅使用了48位虚拟地址(未来会扩展到57位以支持更大内存)。
这48位被精确地分成了5段:
虚拟地址(48位):
[47:39] [38:30] [29:21] [20:12] [11:0]
9位 9位 9位 9位 12位
PGD PUD PMD PTE 页内偏移
每一级索引对应一级页表:
- PGD(Page Global Directory):全局页目录
- PUD(Page Upper Directory):上层页目录
- PMD(Page Middle Directory):中间页目录
- PTE(Page Table Entry):页表项,最终指向物理页帧
最后的12位是页内偏移,一页大小 = 2^12 = 4KB。
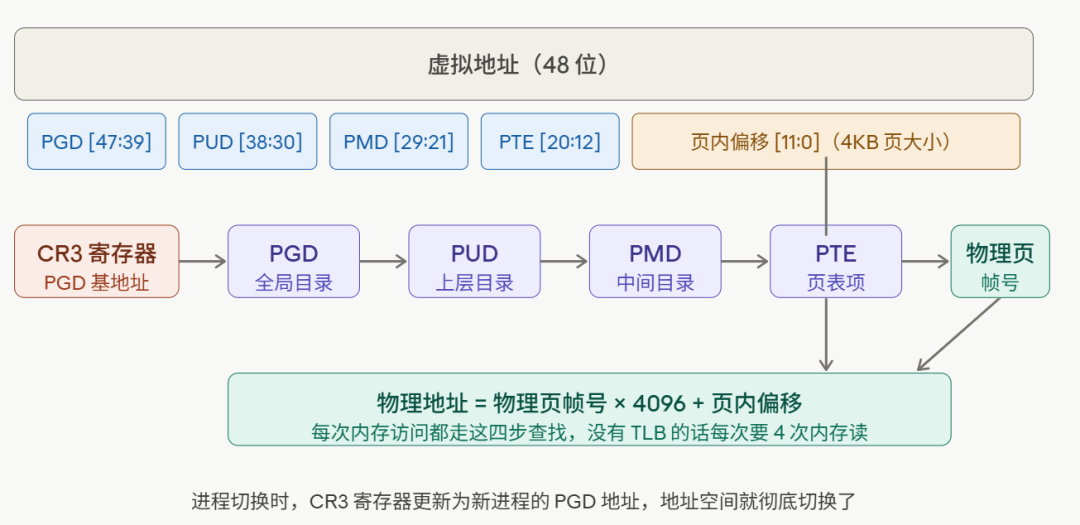
这意味着,每次CPU访问内存,理论上都要走完这四步查表流程。每次页表查询本身也是一次内存访问,所以一次数据访问需要:4次(查页表)+ 1次(读数据)= 总共5次内存访问!
这要是真这么干,程序会慢到什么程度?简直无法想象。所以,硬件设计了一个关键的加速部件:TLB。
三、TLB:页表的“高速缓存”
TLB(Translation Lookaside Buffer,翻译后备缓冲区) 是集成在CPU内部的一块硬件缓存,专门用来缓存最近使用过的“虚拟地址 → 物理地址”映射结果。
- TLB命中(Hit):约 1个时钟周期 就能完成地址翻译。
- TLB未命中(Miss):需要走完整的四级页表流程,耗时 几十到上百个时钟周期。
性能差距之所以如此巨大,根本原因就在于此。

TLB的容量通常很小,只有几百到几千条记录。它能发挥巨大威力,依赖的是程序访问的局部性原理——程序在大部分时间里,访问的都只是少数几个连续的内存区域,这些区域的映射关系可以一直驻留在快速的TLB中。
TLB对代码性能的实际影响:
// 示例:顺序访问 vs 随机访问,TLB命中率差距极大
int arr[1024 * 1024];
// 顺序访问:局部性极好,TLB命中率高,速度极快
for (int i = 0; i < N; i++) arr[i]++;
// 随机跳跃访问:每次都可能触发TLB miss,速度慢很多
for (int i = 0; i < N; i++) arr[rand() % N]++;
顺序访问的速度可以比随机访问快10倍不止,其中一个根本原因就是TLB命中率的巨大差异。
四、进程切换时TLB发生了什么?
当CPU从进程A切换到进程B时,必须切换页表(即更新CR3寄存器)。
问题来了:TLB里缓存的全是进程A的地址映射,而进程B使用的是另一套完全不同的页表,此时TLB里的内容全部失效了。
这就是进程切换开销不小的原因之一——除了要保存和恢复寄存器状态,还需要刷新TLB(TLB flush)。切换后的前几百次内存访问几乎全是TLB miss,必须重新走慢速的页表查询路径。
理解了这一点,你也就明白了为什么Linux内核会极力减少不必要的进程切换次数,以及为什么线程切换开销远小于进程切换——同一进程内的线程共享同一份页表,切换时无需刷新TLB。
五、大页内存(HugePage):直接减少TLB压力
既然TLB容量有限,有没有办法让同样数量的TLB条目覆盖更多的内存呢?
答案是使用更大的内存页。
Linux支持2MB甚至1GB的大页(HugePage)。使用2MB大页时,一条TLB记录就能覆盖2MB的连续内存;而使用4KB普通页,覆盖同样大小的内存则需要512条TLB记录。
| 页大小 |
覆盖1GB内存需要的TLB条目数 |
| 4KB(普通页) |
262,144 条 |
| 2MB(大页) |
512 条 |
| 1GB(超大页) |
1 条 |
这就是为什么MySQL、Redis、JVM等内存密集型服务都强烈建议配置HugePage。它们通常需要管理数十GB的内存,使用大页能显著降低TLB miss率,从而提升内存访问性能。
# 查看系统大页配置
cat /proc/meminfo | grep Huge
# 配置2048个2MB大页(总计4GB)
echo 2048 > /proc/sys/vm/nr_hugepages
# 程序中使用大页(通过mmap + MAP_HUGETLB标志)
void *p = mmap(NULL, size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB,
-1, 0);
六、NUMA:多CPU下的内存访问并非等距
现代服务器通常有多个CPU插槽(Socket),每个CPU都有自己直接连接的内存,这种架构被称为NUMA(Non-Uniform Memory Access,非统一内存访问)。
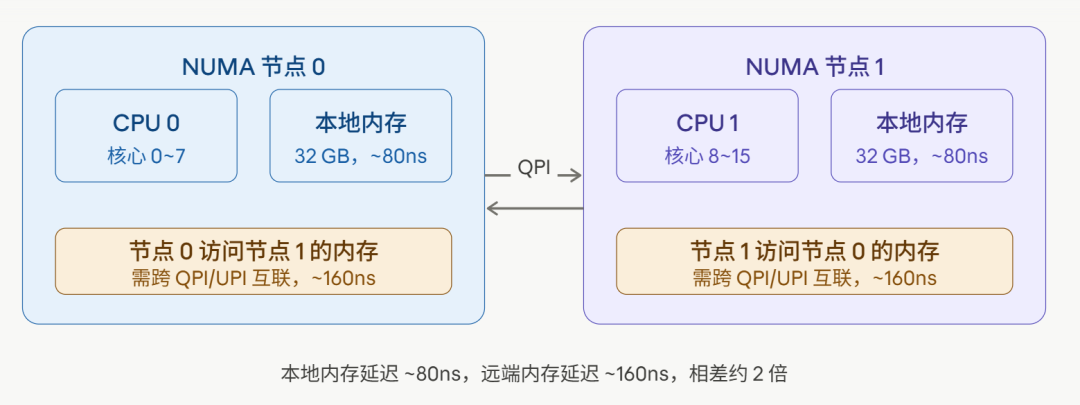
在NUMA架构下,内存访问延迟不是固定的:
- 访问本地节点(Local Node)内存:延迟较低,约80ns。
- 访问远端节点(Remote Node)内存:需要跨CPU之间的QPI/UPI互联,延迟较高,约160ns,几乎是本地访问的两倍。
对于数据库、Redis、消息队列等内存密集型服务,频繁的跨NUMA节点访问会带来显著的性能损失。
实际排查与调优命令:
# 查看系统的NUMA拓扑结构
numactl --hardware
# 查看各NUMA节点的内存使用情况
numastat
# 将进程绑定到指定NUMA节点运行(避免跨节点访问)
numactl --cpunodebind=0 --membind=0 ./myapp
# 查看特定进程的NUMA内存分布
numastat -p <pid>
常见的NUMA性能陷阱:
最典型的问题是进程在节点0的CPU上运行,但其通过 malloc 分配的内存却被操作系统分配到了节点1。这被称为NUMA内存失衡。其典型症状是:CPU利用率看似不高,但内存带宽已经打满,应用延迟却很高。
解决方案之一就是使用 numactl --membind 将进程的内存分配绑定到特定节点,或者在内核层面配置 vm.zone_reclaim_mode = 1,让内核优先回收并使用本地节点的内存。
七、几个重要的实用命令
# 查看进程的虚拟内存映射(能看到每段虚拟地址对应什么内容)
cat /proc/<pid>/maps
# 或者
pmap -x <pid>
# 查看系统页大小
getconf PAGE_SIZE # 输出通常是4096(4KB)
# 查看TLB相关的CPU性能计数器(需安装perf)
perf stat -e dTLB-load-misses,dTLB-store-misses ./myapp
# 查看大页使用情况
cat /proc/meminfo | grep -i huge
# 查看NUMA信息
numactl -H
八、高频面试题精析
Q:为什么64位系统只用48位虚拟地址,不用满64位?
48位虚拟地址可以寻址256TB,这已经远超当前绝大多数服务器的物理内存容量。如果使用完整的64位,页表层级会深达6-7级,地址转换的开销(时间和空间)会急剧增加,TLB压力也变得不可承受。实际上,AMD等厂商已在推进5级页表(57位虚拟地址),可寻址128PB,以应对未来的需求。
Q:进程A和进程B可以有相同的虚拟地址,但进程A能直接访问进程B的内存吗?
不能。虽然两个进程的虚拟地址值可能相同(例如都是 0x400000),但通过各自独立的页表,它们会被映射到完全不同的物理内存页上。进程间的隔离正是通过页表实现的。唯一合法的跨进程内存访问方式是共享内存(通过 mmap 或 shmget 创建),此时两个进程的页表中,不同的虚拟地址会指向同一块物理页。
Q:TLB在进程切换时为什么必须刷新?有没有办法不刷新?
因为不同进程的页表不同,TLB中缓存的映射对新进程无效。但现代CPU支持ASID(Address Space Identifier,地址空间标识符),可以给每个进程分配一个ID并标记在TLB条目中。这样,当切换进程时,只要ASID不同,不同进程的TLB条目就可以在缓存中共存,无需整体刷新。Linux内核在支持ASID的CPU架构上会利用此特性来减少TLB刷新的开销。
Q:为什么HugePage能显著提升数据库(如MySQL)的性能?
数据库(如MySQL的InnoDB缓冲池、PostgreSQL的共享缓冲区)通常会分配数十甚至上百GB的内存作为缓存。如果使用4KB普通页,假设要缓存64GB数据,则需要超过1600万条TLB记录,这远远超出了TLB的容量,导致大量的TLB miss。而使用2MB大页,仅需约32K条TLB记录,TLB命中率大幅提升,内存访问延迟自然显著降低。
写在最后
虚拟内存、四级页表、TLB、NUMA——把这四个核心概念串联起来,你就掌握了Linux内存管理子系统的工作原理。
理解了这些底层机制,很多看似“玄学”的性能差异就有了清晰的解释:
- 为什么顺序访问远比随机访问快?(TLB命中率)
- 为什么大页对数据库等内存密集型应用至关重要?(减少TLB压力)
- 为什么在多路服务器上绑核运行进程很重要?(NUMA本地访问优先)
这些绝非纸上谈兵的理论,每一条都能直接指导生产环境下的性能调优实践。如果你想深入探讨更多系统底层或C/C++相关的优化话题,欢迎到云栈社区与更多开发者交流心得。
 发表于 2026-4-18 03:19:52
|
查看: 229|
回复: 0
发表于 2026-4-18 03:19:52
|
查看: 229|
回复: 0
