如果你经常在Web应用中处理文档预览,大概率经历过这种崩溃场景:用户上传了一个TXT文件,点开预览却是满屏乱码,最终不得不引导用户下载到本地,再手动用记事本转换编码格式。又或者,当用户上传一份几十页的PDF时,却发现预览器只展示了前5页,用户误以为文件损坏,体验大打折扣。
为了彻底解决这些真实且高频的痛点,我们近期对 JitViewer 文件预览SDK进行了深度打磨。上周,我们刚刚帮助一个知识库团队解决了其上千份历史TXT文档的预览乱码问题;同时,也根据社区开发者的反馈,重构了底层的PDF预览机制,移除了页数限制。
今天,我们正式发布 JitViewer V1.5.0。本次更新的核心是两大功能:全格式TXT文件支持与PDF不限页完整预览,旨在让文件预览体验变得真正丝滑、无感。
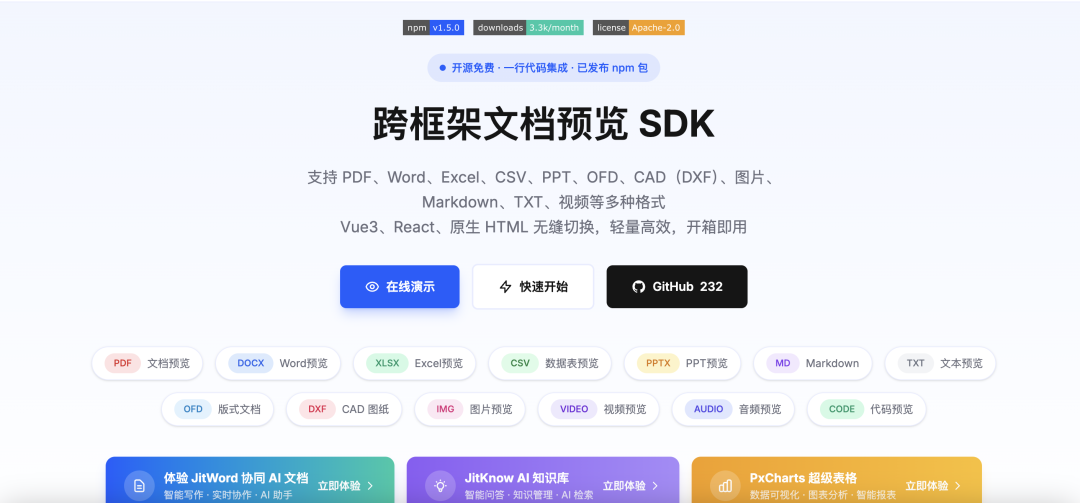
项目地址:
本次更新详解
1. 全格式TXT文件预览,告别乱码时代
这个功能能做什么?
无论用户上传的是UTF-8、GBK、GB2312还是其他相对冷门的编码格式(如UTF-16、Big5)的TXT文件,JitViewer现在都能自动检测编码并正确渲染。用户看到的不再是“天书”,而是排版整齐、内容清晰的干净文本。
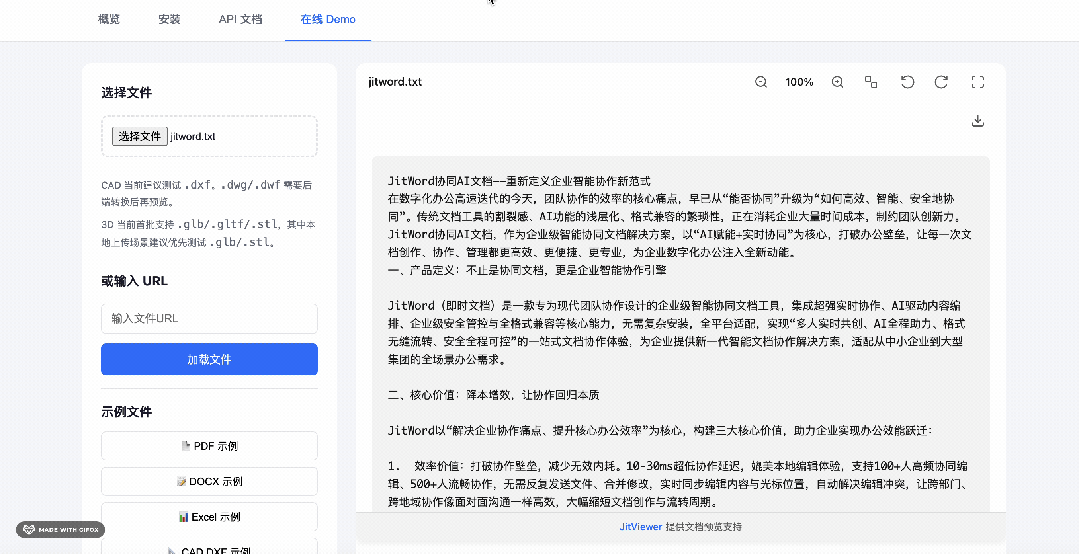
技术实现要点:
这个功能的实现,我们借助了AI Coding进行辅助分析和修复,其核心是新增了一个智能的编码检测与解码函数。主要逻辑如下:
- 修复问题:修复TXT预览在GBK / GB2312 / UTF-16等非UTF-8编码下出现乱码的问题。
- 根因分析:原实现使用
blob.text()固定以UTF-8解码,无法处理其他编码的文件。
- 新增函数:实现
decodeText(buffer)函数,进行多级自动编码检测,优先级如下:
- BOM检测:识别UTF-8 BOM(
EF BB BF)、UTF-16 LE(FF FE)、UTF-16 BE(FE FF)并剥除BOM头。
- UTF-8严格校验:使用
TextDecoder('utf-8', { fatal: true }),实现零误判。
- GBK / GB18030:通过双字节配对命中率(≥ 50%)启发式判断是否为GBK字节流,避免Latin-1误判。
- Big5(繁体中文):检测到高字节内容时尝试Big5解码。
- UTF-8宽容兜底:非法字节替换为
\uFFFD,保证预览过程不崩溃。
- 视觉提示:对于非UTF-8编码的文件,会在预览界面右上角展示编码标识徽章(如
GBK、UTF-16 LE),UTF-8文件则无干扰,保持界面简洁。
解决的问题:
以往遇到编码不兼容的TXT文件,要么需要用户自行下载后用专业工具转换,要么需要开发团队在业务层编写复杂的编码检测逻辑。现在,这些麻烦都无需再考虑,SDK底层已经完成了所有编码适配工作。
适用场景:
- 知识库/SaaS产品:用户上传的日志文件、配置文件、代码片段、小说章节都能直接在线预览。
- 企业OA/文档中台:那些年代久远、编码混杂的历史文档,终于无需经历“下载-转码-再上传”的繁琐流程。
- 网盘/云存储:TXT文件的预览体验得以大幅提升,直接对标头部产品的使用感受。
2. PDF预览不再“腰斩”,支持全本畅读
这个功能能做什么?
现在,用户可以上传完整的PDF文件,并在线上流畅地翻阅至最后一页,彻底告别了“仅预览前5页”的限制。
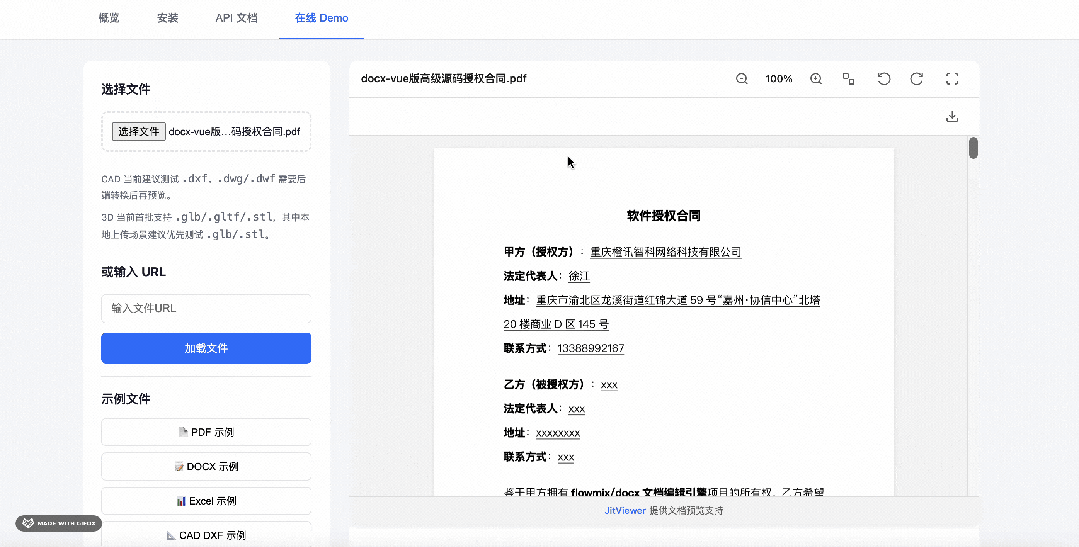
解决的问题:
之前的5页限制容易让用户产生困惑,误以为是文件损坏或上传不全。GitHub issue中类似“为什么我的PDF只能看一半?”的反馈可以就此清零。对于内容型产品而言,提供完整的阅读体验是提升用户留存的关键。
适用场景:
- 在线教育平台:学生可以完整地在线浏览整本教材或课件,无需中断下载。
- 法律科技/电子合同:律师或法务需要逐页核对合同条款,完整的预览能力至关重要。
- 电子书/内容社区:用户不再被“试读5页”的门槛劝退,能够深度消费完整内容。
V1.5.0 核心价值与应用场景
本次更新并非简单地增加功能,而是直击了两个影响用户体验的关键短板:编码兼容性与阅读完整性。我们想要解决的,不仅仅是“能看”,更是“看得爽”、“看得全”。
| 场景 |
原来的痛点 |
现在的体验 |
| 知识库/SaaS产品 |
用户上传的TXT日志、配置文件经常乱码,需要人工干预。 |
全编码自动兼容,上传即看,管理后台零负担。 |
| 企业文档中台 |
历史文档格式混杂,编码不一,维护和预览成本高。 |
一套SDK接管所有TXT预览,实现统一、标准化的体验。 |
| 内容社区/文库 |
PDF资源只能预览开头,用户无法判断内容价值,转化率低。 |
完整预览提升内容消费深度,帮助用户决策,提高留存。 |
| 网盘/云存储 |
文件预览体验参差不齐,成为产品短板。 |
提供统一的高标准预览能力,增强产品竞争力。 |
关于 JitViewer
说了这么多,JitViewer究竟是什么?简单来说,它是一款纯前端的文件预览SDK。无需后端转换服务,无需安装任何插件,开发者通过几行代码集成,就能让Web应用在浏览器内获得媲美专业软件的文档预览能力。
它支持多种主流前端框架,如 Vue3 和 React,也支持原生HTML集成,开箱即用。
目前,JitViewer已支持预览的格式包括:
- Office文档:DOCX, PPTX, XLSX
- PDF文档
- 表格数据:CSV
- 标记语言:HTML, Markdown
- 文本文件:TXT(全编码支持)
- 代码文件:JS, CSS, Java, Go, C#, PHP, TypeScript等
- 多媒体:音频、视频
- 专业格式:CAD图纸 (DXF), 3D模型, OFD(国产版式文档)
我们始终在聆听社区的反馈,并持续迭代。你可以在 GitHub 上找到项目源码、提交Issue或参与贡献。也欢迎到云栈社区的技术板块与其他开发者交流文件预览乃至更广泛的Web开发实战经验。
未来展望
本次V1.5.0的发布是一个重要的里程碑。而更强大的 JitViewer 2.0 版本已在开发进程中,它将致力于提供更广泛的格式支持、更极致的渲染性能以及更轻量便捷的接入体验。敬请期待! |  发表于 2026-4-18 18:31:15
|
查看: 576|
回复: 0
发表于 2026-4-18 18:31:15
|
查看: 576|
回复: 0
