Anthropic 正式发布了 Claude Opus 4.7。虽然它并非其最顶级的模型(更强的 Mythos Preview 仍在预览阶段),但它已是目前我们能稳定使用的最强大、最可靠的模型。
此次升级的核心并非追求“更聪明”,而是强调 “更靠谱”。以往的 AI 往往像一名顺从的实习生,机械执行指令,哪怕指令本身存在问题。而 Opus 4.7 则如同一位经验丰富的资深同事,它敢于对错误的方案提出反驳,遇到障碍时会主动寻找替代路径,而不是直接报错或虚构答案。
对于普通用户而言,这意味着什么?简单来说:当你清晰交代任务后,它能更准确地完成任务,图像识别更细致,产出的内容也更具直接可用性。

敢于“反驳”的智能协作者
Opus 4.7 最显著的变化在于其不再一味地顺从指令。在早期测试中,开发者们观察到一个有趣的现象:它会在技术讨论中主动提出质疑,帮助你做出更优的决策。
知名云端开发平台 Replit 的评价十分直接:“它真的像一位更优秀的同事。”
这种“靠谱”的特质在极端案例中同样有所体现。
Anthropic 公布了一项测试:要求 Opus 4.7 从零开始构建一个完整的 Rust 文本转语音引擎。结果它不仅独立编写了神经网络模型和 SIMD 加速内核,还自主地将输出结果输入语音识别器进行验证,连测试环节也一并完成。整个过程无需人工干预,它自己完成了规划、验证与纠错。
在另一项测试中,任务是仅使用 CSS(不允许使用 JavaScript)制作一个复古电风扇。面对这个约束严格的挑战,Opus 4.7 没有像其他模型那样暗中违规,而是通过复杂的样式叠加,逼真地还原了风扇的立体结构与光影效果。
这种在既定规则内寻找最优解的能力,正是高级工程思维的体现。

视觉与长时记忆能力的跃升
除了推理能力的增强,Opus 4.7 的视觉输入能力也得到显著升级。它现在支持最高 2576 像素长边的图像输入,分辨率是前代的三倍以上。这使得它能够解析密集的数据截图,识别产品原型中的细微差别,甚至从复杂的流程图中精准提取关键信息。
在视觉推理基准测试中,Opus 4.7 的得分实现了翻倍增长,从 54.5% 跃升至接近满分的 98.5%。这意味着在计算机使用(Computer Use)能力方面,它已初步具备了替代人类执行屏幕操作的基础。
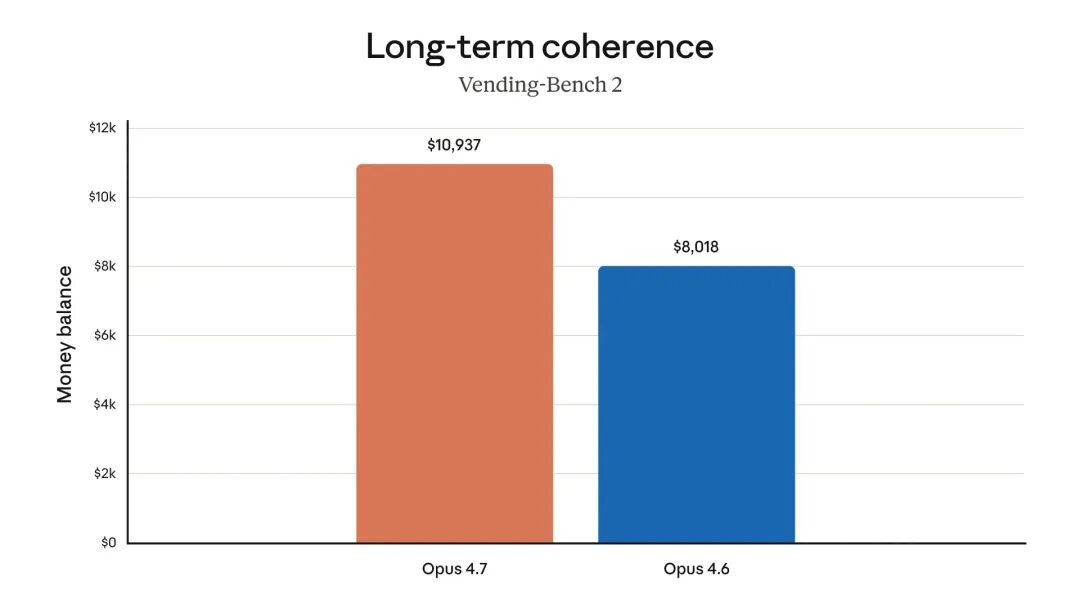
更重要的是,它的“记忆力”更强了。在一项模拟经营自动售货机的长任务测试(Vending-Bench 2)中,Opus 4.7 最终获得了 10,937 美元的余额,相比前代模型的 8,018 美元高出 36%。这表明在需要长时间、多步骤协作的工作流中,它能更好地保持决策的一致性与连贯性,避免中途“偏离主题”或“忘记”关键信息。
能力提升带来的“成本”
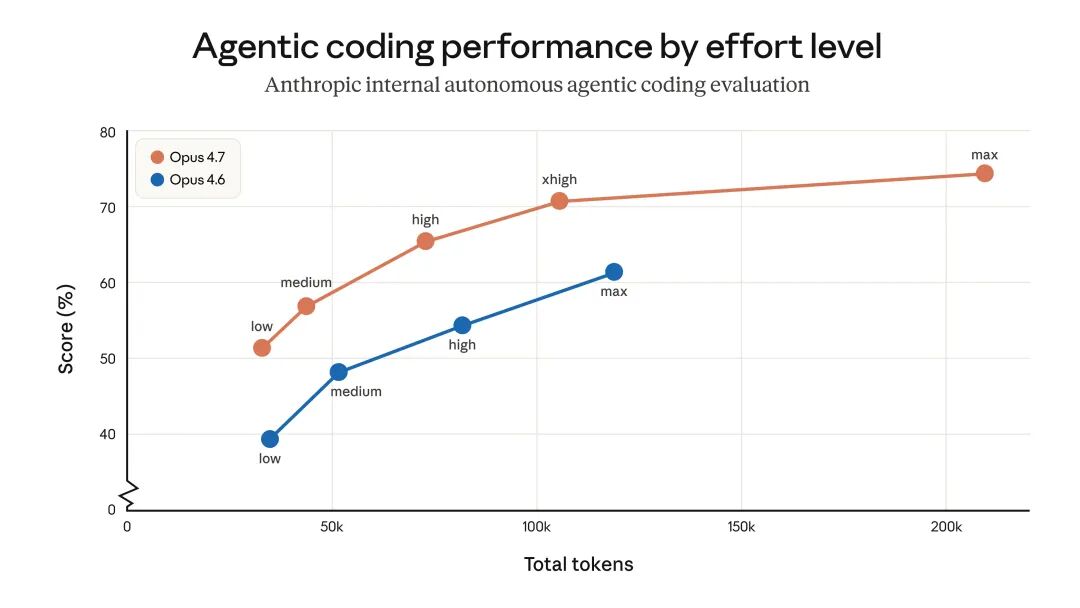
当然,能力的提升伴随着相应的代价。Opus 4.7 采用了全新的分词器,同样的文本内容可能会被拆分成比之前多 1.0 至 1.35 倍的 Token。加之它在处理高强度任务时倾向于进行更深入的“思考”,实际消耗的 Token 数量几乎必然增加。
为了适配这种工作模式,Anthropic 推出了全新的 “Xhigh”(超高) 努力级别。在此级别下,面对复杂难题,Claude 会消耗更多 Token 和计算时间去进行深度推理。虽然这会增加单次任务的成本,但换来的是代码质量的显著提升和错误率的降低。
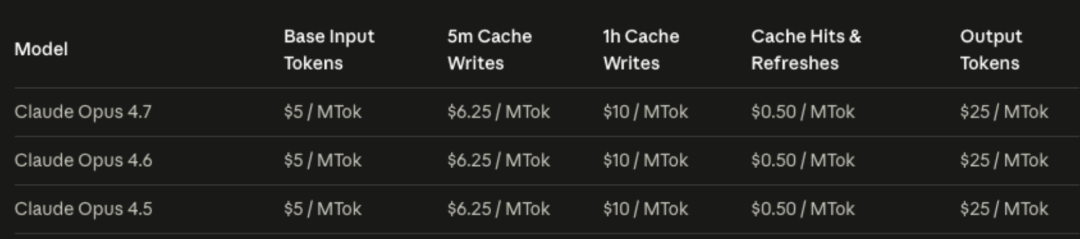
一个利好消息是,其基础定价维持不变,输入 Token 仍为每百万 5 美元,输出为每百万 25 美元。但对于依赖其 API 的开发者而言,需要重新评估成本结构,因为“思考得更深入”往往意味着“消耗得更多”。
从“能够执行”到“能够交付”
Claude Opus 4.7 的升级标志着其角色从简单的指令执行者,转变为能够提出建设性意见、主动解决难题、甚至敢于质疑不合理方案的智能协作者。
对于开发者、数据分析师、法律从业者等专业人士来说,这种进步是颇具变革性的。它能够接手过去需要紧密监督的高难度工作,产出更接近最终成品的文档、代码和演示方案。尽管使用成本可能略有上升,但考虑到它所节省的人力时间成本和工作质量的整体提升,其综合价值依然非常可观。想了解更多关于 人工智能 领域的最新动态与技术实践,欢迎在 云栈社区 进行交流探讨。
 发表于 2026-4-18 19:27:12
|
查看: 123|
回复: 0
发表于 2026-4-18 19:27:12
|
查看: 123|
回复: 0
