作为Opus 4.6的直接继任者,Claude Opus 4.7这次带来了全方位的显著提升。更新重点放在了长时间任务处理的严谨性、指令遵循的精准度、输出的自我验证以及视觉能力上,旨在让开发者能更安心地将复杂的项目交付给这个人工智能助手,大大减少了人工监督的需求。
此次更新的主要亮点如下:
1. 长时任务与智能体能力大幅提升
- 更持久、更缜密的推理:模型现在能够自主处理耗时数小时的复杂任务,可以主动识别逻辑漏洞、跳出无效循环、优雅地恢复状态,并在最终报告前自我验证输出结果的可靠性。
- 指令遵循与角色扮演更精准:在团队协作或多代理工作流中,它能更稳定地维持角色设定,精确遵循复杂指令。
- 效率跃升:在较低投入(effort)设置下,Opus 4.7的表现已大致相当于之前中等投入(medium effort)下的Opus 4.6,效率提升明显。
2. 视觉能力实现飞跃(分辨率提升3倍以上)
- 支持处理最长边高达2576像素的图像,分辨率是前代模型的3倍多。
- 能够清晰解析高密度代码截图、复杂的技术图表、化学结构式等细微视觉信息,其生成的UI界面、演示文稿和文档质量也因此得到显著提升。
- 在视觉基准测试(XBOW)中,得分从4.6版本的54.5%飙升至98.5%。
3. Claude Code 新增实用功能
- 新增
/ultrareview 命令:专为代码审查设计,可系统性检查代码变更,深度挖掘潜在缺陷(Pro和Max用户各有3次免费试用机会)。
- Auto模式向Max用户开放:在长任务中中断更少,Claude能够自主决策的时间窗口更长。
- 默认推理强度提升:编程和智能体场景下的默认effort级别已提升至
xhigh。
4. API 引入新特性
- 新增
xhigh effort级别:位于high和max之间,为开发者在推理深度与响应延迟之间提供了更精细的控制选项。
- Task budgets(任务预算)进入公开测试:该功能有助于更好地管理和预测长周期任务的token消耗与成本。
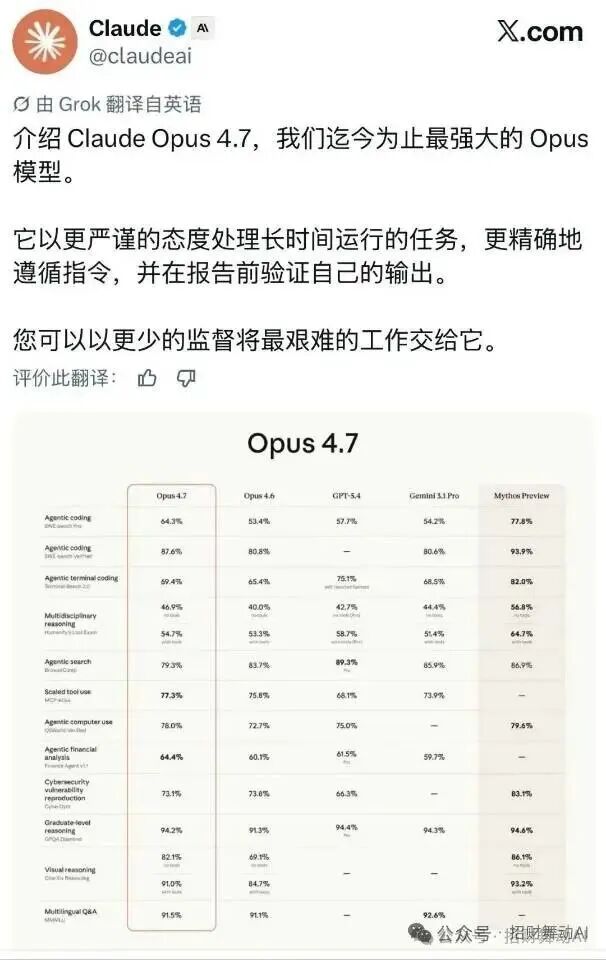
5. 基准测试表现
- 93项编码任务:解决率提升13%(比4.6多解决了4个任务)。
- CursorBench:得分达到70%(4.6为58%)。
- Rakuten-SWE-Bench:在生产环境任务解决数量上是4.6的3倍,代码和测试质量均有两位数百分比的提升。
- 智能体基准:在Finance Agent、Notion Agent等评估中进步明显,整体在长上下文、高经济价值的工作上达到了当前最优水平(SOTA)。
可用性与定价
- 立即可用:已在 claude.ai 及所有主流云平台上线。
- 价格不变:与Opus 4.6保持一致(输入token:$15 / 百万,输出token:$75 / 百万)。
- 重要提示:新的分词器(tokenizer)可能导致相同的提示词消耗1.0–1.35倍的token,建议用户根据情况适当调整提示词策略。
总结与思考
一句话概括,Opus 4.7在“将最难的工作放心交给AI”这个目标上又迈进了一大步,特别适合重度编码、长时间运行的智能体任务以及对视觉精度要求极高的场景。
不过,需要提醒的是,据部分开发者反馈,新版本在纯文字创作方面可能略有退步。同时,由于处理能力增强和token消耗可能增加,处理单个复杂任务的成本确实会更高,这也是追求极致性能时需要权衡的一点。 |  发表于 2026-4-20 06:12:38
|
查看: 157|
回复: 0
发表于 2026-4-20 06:12:38
|
查看: 157|
回复: 0
