在 Web3 应用开发中,链上合约部署完毕仅仅是第一步。紧随其后的核心挑战是如何实时、高效地获取并结构化链上数据,以支撑复杂的前端展示与后端分析。传统的 RPC 轮询方案在面对高频交易和海量历史数据时,往往在性能和成本上捉襟见肘。
本文将带你深入实战,展示如何利用 StreamingFast Substreams 技术,为你的 Solana 智能合约(以 Pinocchio Vault 为例)构建一个工业级的实时索引器(Indexer)。我们将把链上原始的字节流,精准、实时地转化为本地 PostgreSQL 数据库中的结构化数据,彻底告别“轮询地狱”。
为何选择 Substreams 替代传统 RPC?
在深入代码之前,先明确我们为何要升级技术栈:
- 告别轮询与限流:无需编写死循环去轮询
getProgramAccounts,避免被 RPC 节点限流或产生高昂请求费用。
- 极致的历史数据同步速度:借助 Substreams 的并行架构,可以在几分钟内同步完过去数月甚至数年的链上交易数据。
- 优雅处理链分叉:内置的 Cursor 机制能自动、优雅地处理 Solana 上常见的链重组(Reorg),确保数据库中的数据永远与最长链保持一致,保障最终一致性。
整体架构:数据上链与下行的双路径闭环
一个完整的 Web3 应用数据流可以拆解为两条互补的路径:
- 上行路径(写数据):利用合约 IDL 自动生成 Client SDK,解决如何方便地“往链上写数据”(发送交易)的问题。这正是 Pinocchio/Shank/Codama 等工具链所擅长的领域。
- 下行路径(读数据):利用 Substreams 实时解析并存储数据到数据库,解决如何高效地“从链下读数据”进行复杂查询的问题。这是本文的核心。
我们的 Substreams 索引器,正是这下行路径的“心脏”。它持续监听区块链,将合约交互产生的原始日志和交易数据,实时地过滤、解析并持久化。
理解索引目标:Pinocchio Vault 合约逻辑
在编写索引器之前,必须明确目标合约的业务逻辑。我们的 Pinocchio Vault 主要包含三个指令:InitializeVault(初始化)、Deposit(存款)和 Withdraw(取款)。
索引器的核心任务,就是准确捕捉 Deposit 和 Withdraw 指令执行时产生的“事件”。例如,在存款流程中,资金从用户(Owner)钱包转移到金库的 PDA 账户,这个过程会“铸造”份额(MintShares);取款则是“销毁”份额(BurnShares)并将资金转回。我们的索引器就是要解析这些关键操作,记录下“谁、在哪个金库、存/取了多少钱”这些核心信息。
实战开始:从零构建 Substreams 索引器
步骤一:初始化项目脚手架
使用 substreams init 命令可以快速生成一个针对 Solana 的索引器项目模板。这是一个交互式命令,你需要指定项目名、网络(如 Devnet)、起始区块和最重要的过滤规则。
substreams init
在交互过程中,当询问过滤规则时,输入你的合约 Program ID:
program:A11gcDm7e8Pit4RiunfhtrK1BKU4oYAa3nx54R4YnFgS
并选择输出到 Postgres。该命令会自动生成包括 substreams.yaml(清单文件)、proto/(数据协议)、src/lib.rs(主逻辑)以及 docker-compose.yaml 在内的全套脚手架。
步骤二:定义数据结构(Protobuf)
在 proto/mydata.proto 中,定义我们希望从链上提取并最终存入数据库的数据结构。例如,对于存款事件:
syntax = "proto3";
package pinocchio_vault.v1;
message DepositEvent {
string owner = 1;
string vault = 2;
uint64 amount = 3;
string tx_hash = 4;
}
message WithdrawEvent {
string owner = 1;
string vault = 2;
string tx_hash = 3;
}
message ProgramData {
repeated DepositEvent deposit_events = 1;
repeated WithdrawEvent withdraw_events = 2;
}
定义完成后,运行 substreams protogen 生成对应的 Rust 结构体代码。这确保了类型安全。
步骤三:编写核心索引逻辑(Rust)
接下来,在 src/lib.rs 中编写核心的 map_program_data 模块。这段 Rust 代码将在 WASM 环境中运行,负责解析每一笔经过过滤的交易。
#[substreams::handlers::map]
fn map_program_data(block: Block) -> Result<ProgramData, Error> {
let mut deposit_events = Vec::new();
let mut withdraw_events = Vec::new();
for trx in block.transactions {
let tx_hash = bs58::encode(&trx.transaction.signature).into_string();
for (instruction_index, instruction) in trx.transaction.message.instructions.iter().enumerate() {
// 1. 验证指令是否来自我们的目标程序
if instruction.program_id != TARGET_PROGRAM_ID {
continue;
}
// 2. 解析指令的第一个字节(Discriminator)来判断类型
let disc = instruction.data.first().copied().unwrap_or(0);
match disc {
0 => { /* InitializeVault - 可能不需要索引 */ },
1 => { // Deposit
if let Ok(event) = parse_deposit_instruction(&instruction, &tx_hash) {
deposit_events.push(event);
}
},
2 => { // Withdraw
if let Ok(event) = parse_withdraw_instruction(&instruction, &tx_hash) {
withdraw_events.push(event);
}
},
_ => {}
}
}
}
Ok(ProgramData { deposit_events, withdraw_events })
}
parse_deposit_instruction 等函数需要根据你合约指令的具体数据布局(账户列表、数据字段)来编写解析逻辑,提取出 owner、vault、amount 等字段。
步骤四:编译与本地测试
- 编译:运行
substreams build。这将把你的 Rust 代码编译成 .spkg 包(WASM 格式)。
- 认证:运行
substreams auth 获取访问 StreamingFast 服务的令牌。
- 本地流式验证:使用 GUI 模式快速验证索引逻辑是否正确。
. ./.substreams.env # 加载认证
substreams gui substreams.yaml map_program_data -e devnet.sol.streamingfast.io:443 --start-block 440182366 --stop-block +1000
如果一切正常,终端将实时输出解析到的 DepositEvent 和 WithdrawEvent 的 JSON 数据。
步骤五:持久化到 PostgreSQL
验证逻辑正确后,下一步是将数据实时写入数据库。
- 准备数据库 Schema:创建
schema.sql 文件,定义 deposits、withdraws 等表结构。
- 启动本地数据库:使用 Docker Compose 一键启动 PostgreSQL 和 pgweb(一个 Web 管理界面)。
docker compose up -d
- 运行 Sink 连接器:这是连接 Substreams 数据流和数据库的桥梁。使用
substreams-sink-sql 工具。
substreams-sink-sql run \
“psql://dev:insecure@127.0.0.1:5432/main?sslmode=disable" \
./pinocchio-vault-indexer-v0.1.0.spkg \
440092945 --endpoint devnet.sol.streamingfast.io:443
此命令会从指定区块开始,持续监听链上数据,并通过你编写的 Rust 逻辑解析后,将结构化的 DatabaseChanges 写入 PostgreSQL。
步骤六:验证与查询
启动 Sink 后,打开 pgweb (http://localhost:8081),你就能在 deposits 表中看到实时同步进来的链上存款记录。
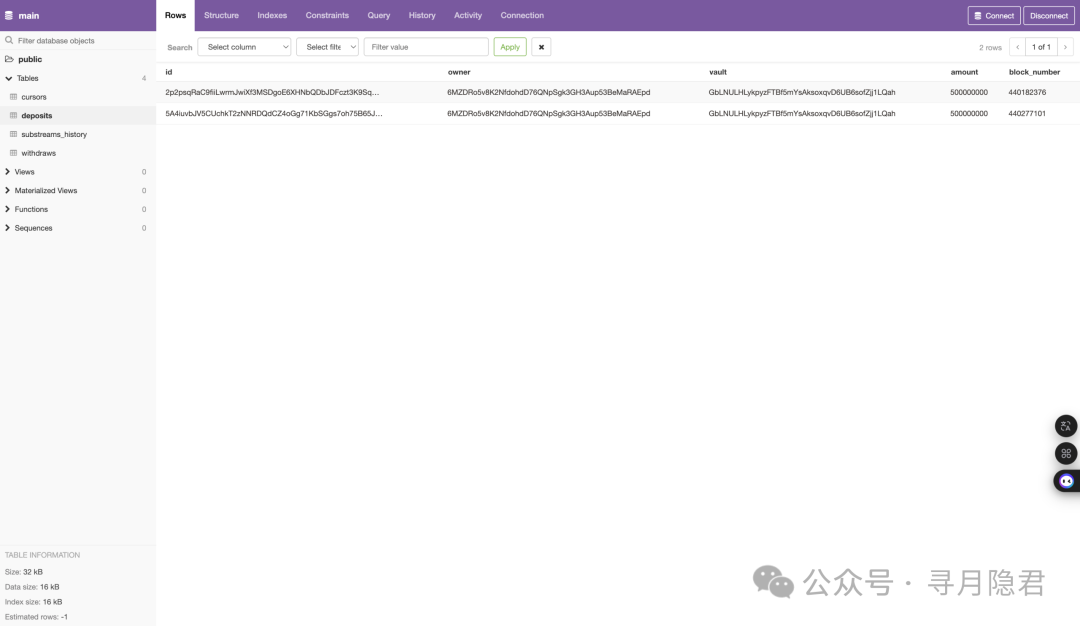
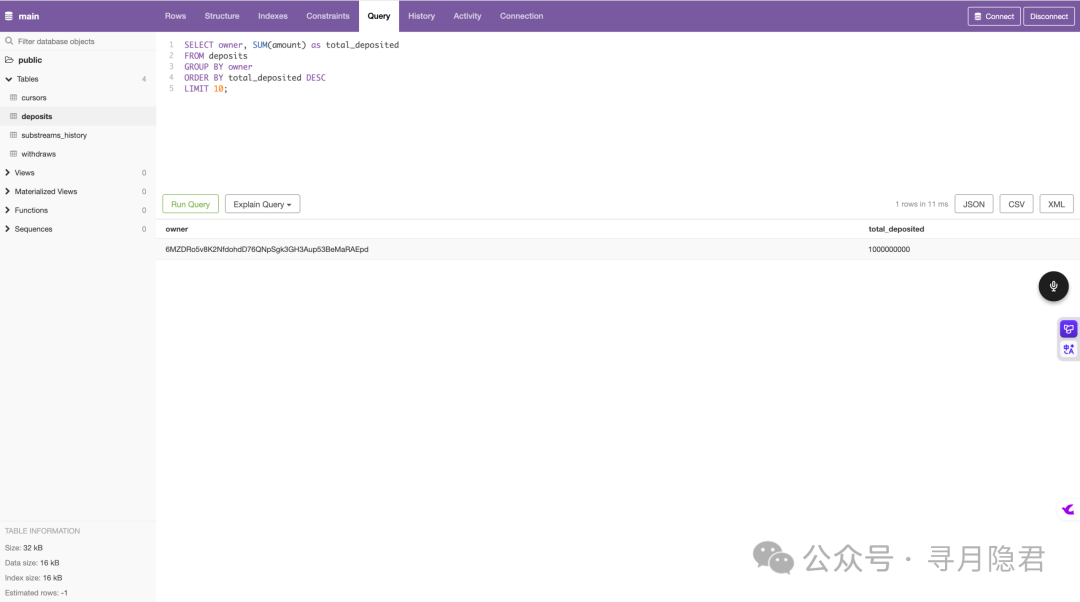
随后,你可以像操作任何关系型数据库一样,使用 SQL 进行复杂的业务查询,例如计算用户总存款:
SELECT owner, SUM(amount) as total_deposited
FROM deposits
GROUP BY owner
ORDER BY total_deposited DESC;
总结与优势
通过本次实战,我们成功构建了一个基于 Substreams 的高性能 Solana 数据索引器。相比传统方案,它带来了根本性的提升:
- 开发效率:
substreams init 提供标准脚手架,protogen 保障类型安全,让开发者聚焦业务逻辑。
- 运行性能:利用云端并行节点,实现历史数据的秒级同步与实时数据的毫秒级延迟。
- 数据可靠性:内置 Cursor 和分叉处理机制,保证数据最终一致,无需自行处理复杂的状态回滚。
- 架构清晰:将链上数据实时下沉至熟悉的 PostgreSQL,使 Web3 应用的后端查询逻辑与传统互联网应用无异,极大降低了复杂业务(如分页、聚合、关联查询)的开发门槛。
这套架构解锁了真正的实时链上数据应用场景,如实时资产看板、交易风控、用户行为分析等,是构建成熟 Web3 产品不可或缺的基础设施。
希望这篇实战指南能为你构建自己的数据索引器提供清晰的路径。区块链开发不仅是智能合约,构建强大、可靠的数据管道同样至关重要。欢迎在 云栈社区 交流你在 Solana 或 Substreams 开发中遇到的问题与心得。
 发表于 2026-4-20 14:17:41
|
查看: 201|
回复: 0
发表于 2026-4-20 14:17:41
|
查看: 201|
回复: 0
