Claude Code 五分钟就能生成两万行代码,按“代码产出量”来算,软件工程师的效率似乎该提升 10~100 倍。但现实呢?远未达到预期,甚至差得很远。

原因很简单——我们之前以为“写代码”是瓶颈,其实它只是最显眼的一层。
当这一层被 AI 拿掉之后,真正决定效率的部分才浮出水面:
判断是否正确、清晰表达需求、补齐业务上下文
现在,这三件事占据了绝大部分时间(成本)。
1. 验证成本
一个显而易见的反驳是:
既然 AI 写得这么快,为什么不让 AI 自己验证?
因为“生成”和“验证”是两种完全不同的能力。

模型可以生成看似合理、置信度很高的代码,但问题往往藏在细节里:错误的业务逻辑、差一错误、以及“看起来几乎正确”的界面。
因此仍然需要人工去做:点击 UI、阅读差异、运行各种边界情况。
虽然代码流水线几秒钟就生成了,但验证它仍然需要和以前一样的时间。
2. 反馈成本
验证之后,进入下一个成本:反馈。
一旦发现问题,需要将问题准确表达给 AI,并确保修复过程中不引入新的问题。这形成一个迭代循环:
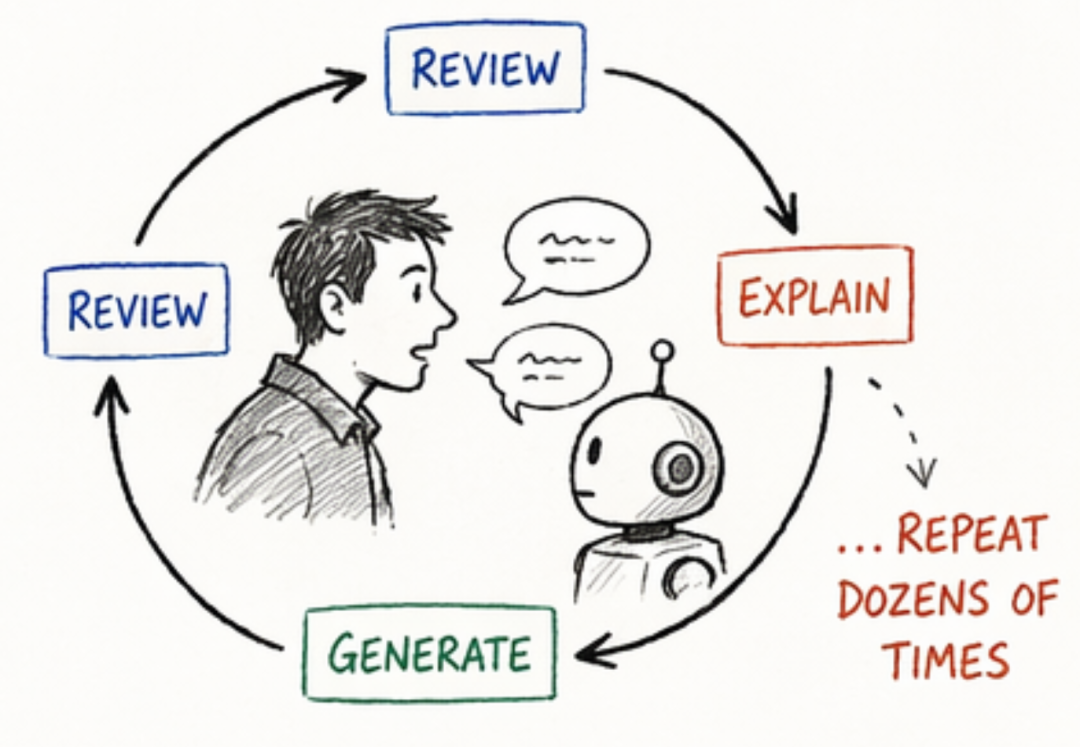
审查 → 解释 → 生成 → 再审查
每一轮的效率,取决于问题表达的清晰度,而不是代码生成的速度。
实际上,这意味着一个几秒能生成的功能,往往需要多轮对话才能稳定落地。
代码生成是瞬时的,但沟通对齐过程是缓慢的。
3. 上下文成本
这是最容易被低估的一项成本。
在真实场景中,决定“正确”的信息大多不在代码里,而在代码之外:会议讨论、项目历史、非正式决策,以及系统设计背后的隐性共识。
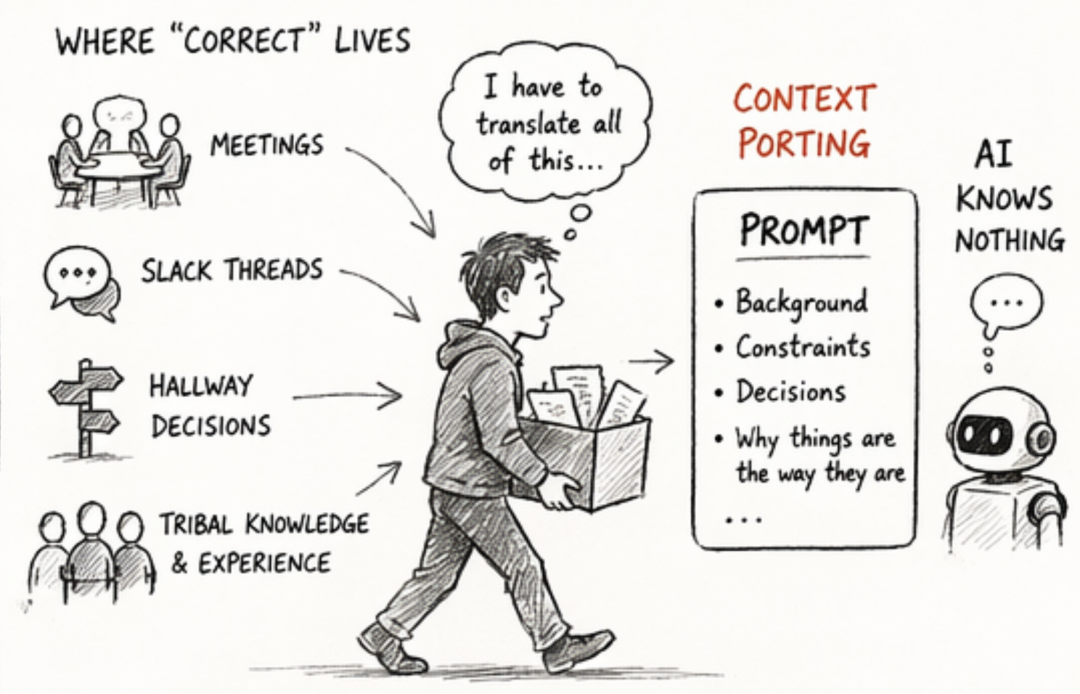
AI 不具备这些上下文,因此必须将这些信息转化为输入,这个过程可以称为:上下文迁移(Context Porting)
其成本体现在:
- 每个任务都需要补充背景
- 每个项目都需要重建上下文
- 原本的团队默契被显性化表达
AI 一旦理解问题,执行会非常快;但让它理解问题本身,是一个慢过程。
结论
人工智能并没有消除软件工程中的难点,它只是移除了最表层的部分——代码编写。本质上的难点依然存在:判断是否正确、沟通需求边界,以及理解和补齐上下文。这些依然依赖人类认知能力,也因此成为新的主要瓶颈。
效率的提升是客观存在的,但更接近 2~3 倍,而不是 100 倍。
在三类成本中,“上下文成本”最有可能在短期内被降低。随着组织知识检索和上下文注入能力的发展,会议记录、决策信息以及隐性经验,正在被纳入 AI 工作流,从而降低解释成本。
相比之下,“验证成本”和“反馈成本”更难被替代,本质上仍然依赖判断力和表达能力,短期内难以实现显著突破。
因此,在可预见的阶段:人仍然是系统的限速环节。
这也是为什么,企业依然需要持续招聘软件工程师。
PS 旧代码重构的效率例外
在旧代码重构中,AI 的效率提升显著高于普通开发任务,通常可达数倍,部分场景接近数量级。
本质原因在于:重构不是设计新系统,而是对既有结构进行“等价迁移”,如模块拆分、逻辑合并、接口迁移与规范统一。
这些任务规则清晰、语义稳定、可批量处理,使 AI 能在理解结构、生成改写和保持一致性上同时放大效率。
因此,遗留系统改造是少数真正显著受益于 AI 的软件工程场景。
 发表于 2026-4-24 16:58:55
|
查看: 178|
回复: 0
发表于 2026-4-24 16:58:55
|
查看: 178|
回复: 0
