姚顺雨入职腾讯后首次交卷。腾讯混元 Hy3 preview 今日正式官宣并开源,目前已在元宝和 WorkBuddy 上线。模型总参数 295B,激活参数仅 21B,定位实用性,在真实业务场景里追求好用。
官方标注的重点能力是 Agent 和 Coding,恰好是姚顺雨在 OpenAI 深耕的方向——Operator 和 Deep Research 背后都有他,ReAct 框架也是他提出的。
Hy3 preview 在 SWE-Bench Verified、Terminal-Bench 2.0 等主流代码智能体基准,以及 BrowseComp、WideSearch 等搜索智能体基准中取得了有竞争力的结果。
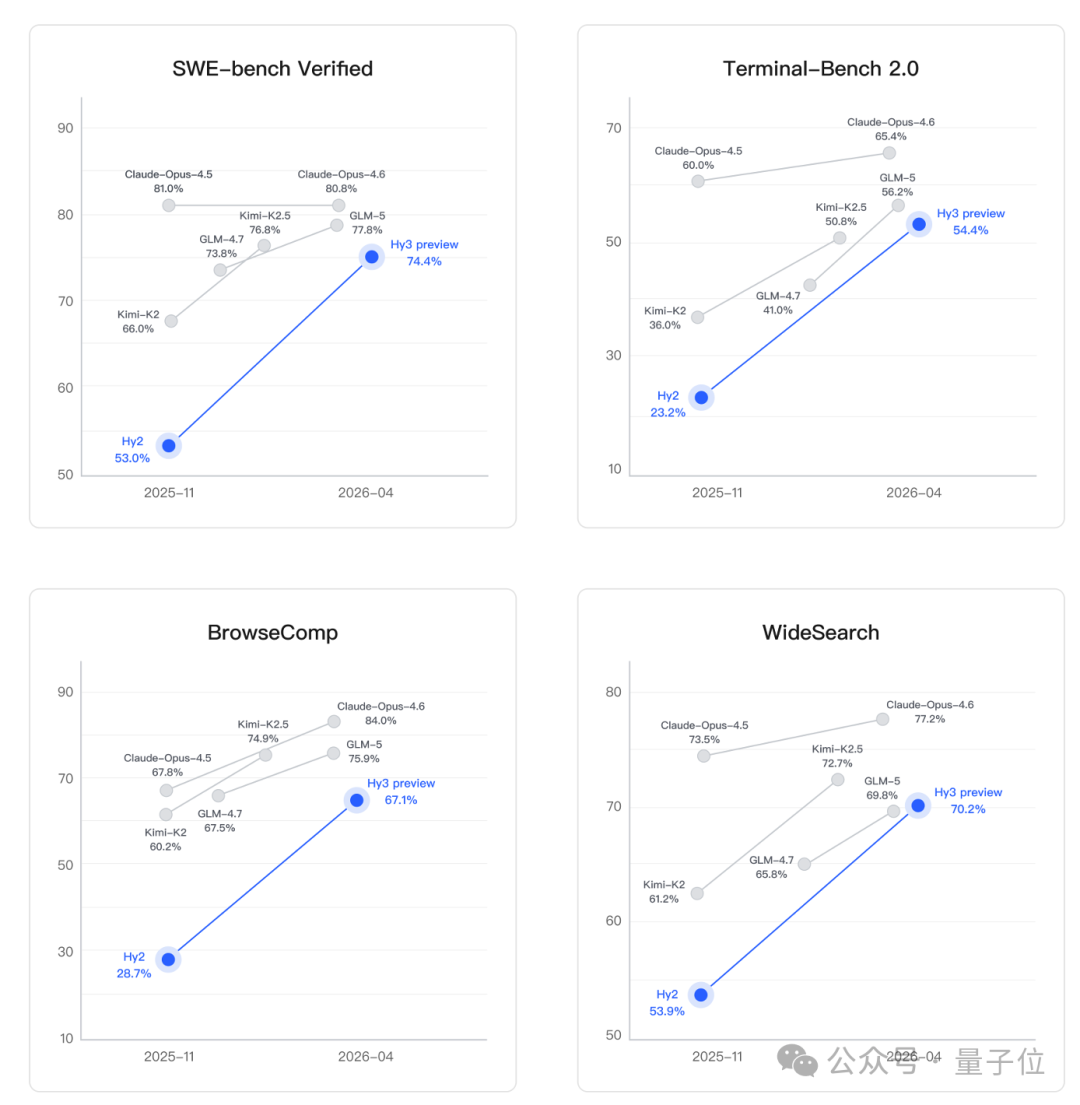
智能体能力方面,Hy3 preview 在 ClawEval 和 WildClawBench 等评测中同样表现突出。
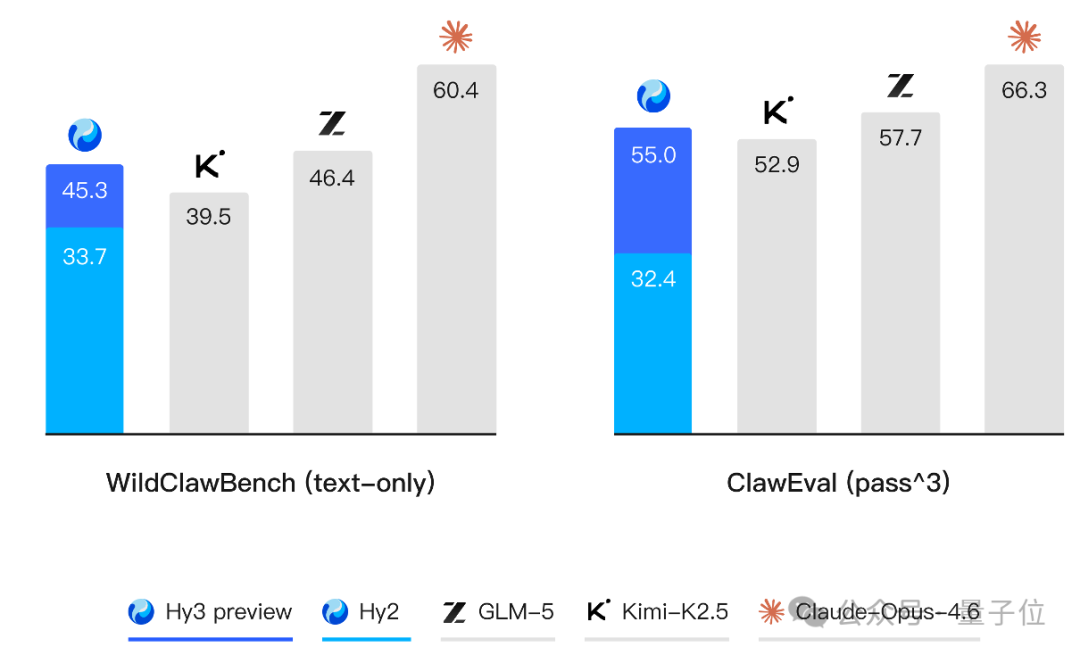
快慢思考融合、长上下文理解、指令遵循也是官方强调的方向,闲聊写作同样可玩。除了公开榜单,腾讯混元还构建了多个内部评测集,结果 Hy3 preview 均体现强竞争力。
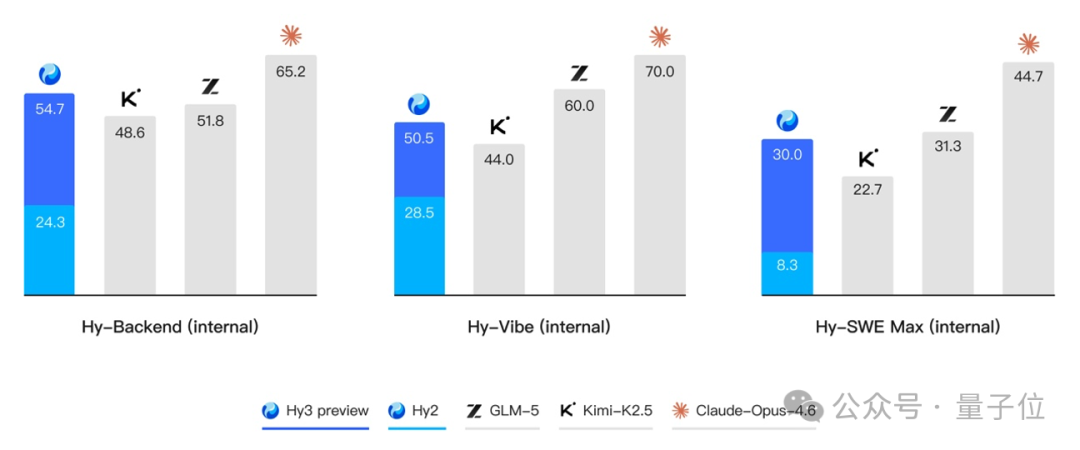
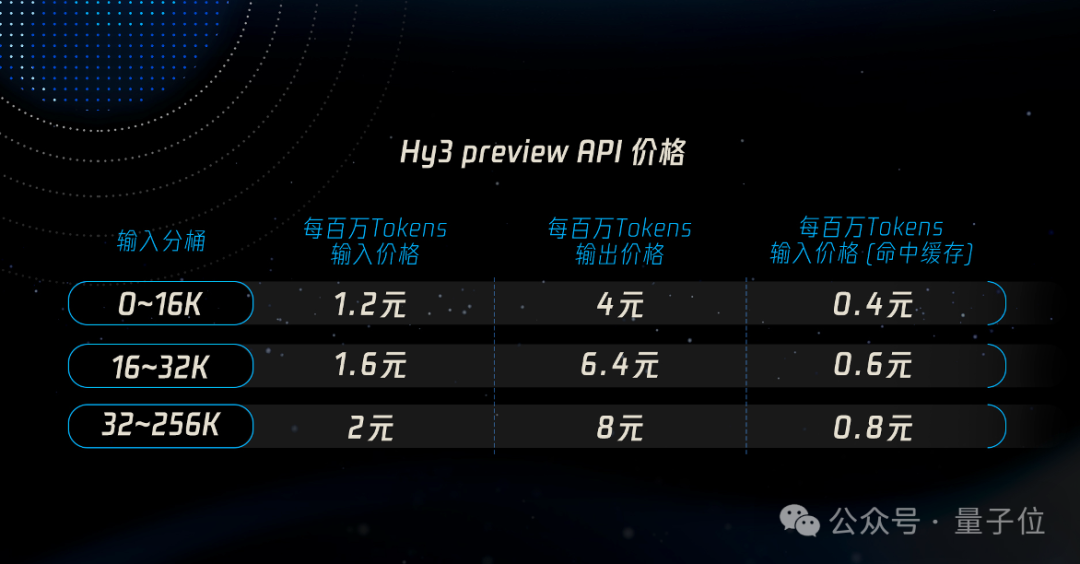
价格方面,在腾讯云大模型服务平台 TokenHub 上,Hy3 preview 输入价格最低 1.2 元/百万 tokens,输入命中缓存价格 0.4 元/百万 tokens,输出价格最低 4 元/百万 tokens。比较各开源模型大小与智能体综合表现,Hy3 preview 展现出高性价比。
目前,Hy3 preview 已在腾讯云、元宝、ima、CodeBuddy、WorkBuddy、QQ、QQ 浏览器、腾讯文档、腾讯乐享等首发上线。元宝和 WorkBuddy 两个场景,我们抢先实际体验了一番。
Hy3 preview 上线元宝
元宝是最直接的对话入口。我们出了两道题,一道逻辑推理,一个创意写作,想看看基础对话能力。
第一题是:
六个人A B C D E F参加一个循环赛,每两人之间恰好比赛一次,赢得1分,输得0分,平局各得0.5分。比赛结束后:A的得分严格高于B,B严格高于C,C严格高于D,D严格高于E,E严格高于F,所有人得分各不相同,且A和F的比赛结果是平局。请问C的得分是多少?给出完整推理过程。
这道题的难点在于“A和F平局”——第一名和最后一名平局,直觉上说不通,但不违反规则。六人循环赛总分固定 15 分,分数严格递减且各不相同,约束够多,答案唯一。结果答案正确,C=3,推理过程也没有问题。它处理“A和F平局”的方式干净:直接从总分 15 分倒推 A 只能是 4.5,F 自然锁定 0.5,剩下四人的分配唯一确定,没有绕弯子。

再看看写作,任务是这样的:
写一段对话。场景是:一个人正在和自己五分钟后的自己通电话,五分钟后的自己一直在哭,但不肯说为什么。200字以内。
结果元宝写得出乎意料:不肯说为什么没有绕开,反而成了核心。“我现在说……就全都完了”把沉默变成有重量的东西,暗示说出口会改变某些事。结尾“看着屏幕上显示的‘5分钟后’,脊背发凉”留白干净。

WorkBuddy 也被进驻
元宝测对话,WorkBuddy 换个维度——本地安装跑,直接操作电脑文件和终端,不走云端。我们布置了三件需要真正做成的事。
第一个任务测它处理本地文件的能力:一堆散落的业务数据文件,格式各异,命名混乱。我们准备了五个文件(销售订单流水、用户日活数据、渠道投放明细、企业客户合同台账、费用月度明细),有 txt 有 csv,共约 100KB。
prompt 是:
扫描我桌面上data文件夹里的内容。这是一家公司散落的业务数据,格式各异、命名混乱。请读取全部文件,整理成一份清晰的业务数据摘要报告,输出为一个可以直接在浏览器打开的HTML文件。
结果它自己写了一个 Python 脚本来读取数据,逐一处理完五个文件,txt、csv 都没卡住。

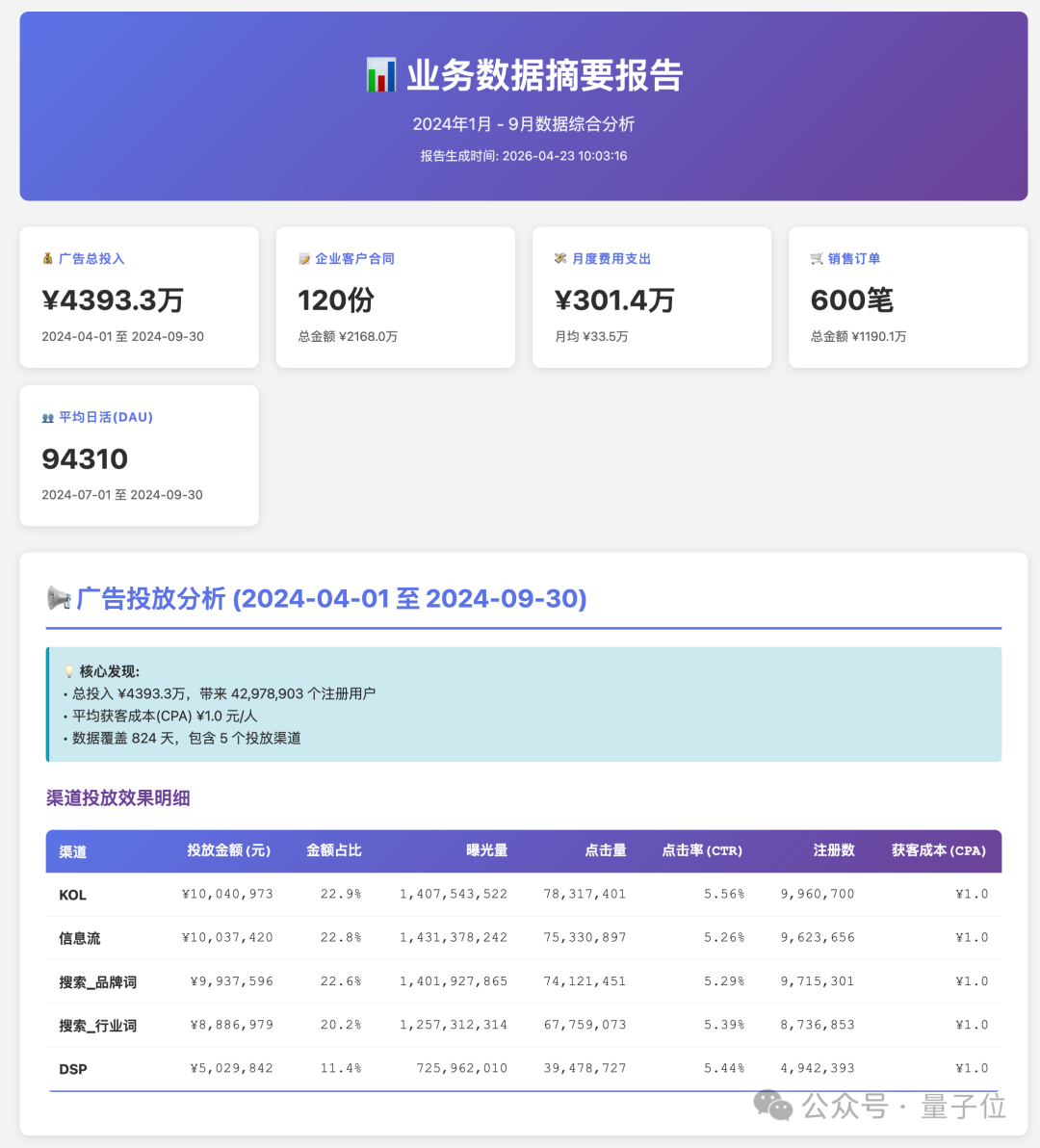
脚本跑完,HTML 报告在浏览器打开就可用,有核心指标卡片、分渠道明细表,样式干净。数字上,广告总投入 4393.3 万、Q3 平均 DAU 94310、企业客户合同 120 份总金额 2168 万,与原始数据逐一核对全部对得上,跨文件数字也整合关联了。
第二个任务换个方向,让它自己从零开始找信息:
帮我做一份关于“AI Agent在企业办公场景落地”的深度研究报告。自己搜集资料,找到真实的产品案例和数据,识别目前落地的主要障碍,给出你认为接下来半年最值得关注的方向。不要只罗列信息,要有自己的判断。
它先拆成 4 个子任务,跑了 5 轮搜索,中途觉得不够又追加一轮,最后在本地建了工作记忆目录存结果。整个过程 18 次工具调用、21 条过程消息,没有一次等人指示下一步。

报告本身也撑得住。引用了 Google Cloud、微软财报、第一新声智库等来源,覆盖 7 个真实落地案例,信源多样。更值得说的是它对 数据 的态度:拿到数字后主动质疑,比如对 120% 复合增长率直接说“更多反映的是采购合同金额而非实际产生的业务价值”。
这种处理不像是只做检索总结,更像是真在研究。
第三个任务,让它做一个打字练习游戏:
做一个打字练习游戏,要求:HTML单文件,浏览器直接打开可以玩;随机生成一段英文单词供用户输入;实时高亮显示输入正确/错误的字符;计时从第一次按键开始;完成后显示准确率和WPM(每分钟字数);有重新开始按钮。不依赖任何外部库,所有代码写在一个HTML文件里。

代码一次出来就能用,打开浏览器直接玩,没有报错,逻辑正确:
- 计时从第一次按键触发,不是页面加载就开始
- WPM 用标准 5 字符/词算法,实时更新
- 准确率按字符逐个比对,完成后结果面板自动弹出,有动画,重新开始也干净
- 词库分常用词、技术词汇、日常词汇三层,随机抽取,不会每次都一样
另外,空格显示为·而不是空白,方便用户知道空格位置,是个主动做的用户体验设计。

混元重建的第一步
混元内部把 Hy3 preview 定调为团队、架构、基础设施全面重建之后交出的第一个版本。尺寸较小,定位实用性,不追参数规模,把重心压在真实业务场景中能不能跑出效果上。这个路子与姚顺雨一直讲的判断一致:AI 已进入下半场,光堆规模没用,得定义真正有用的任务,在真实业务和复杂场景中反复锤炼。
姚顺雨表示:Hy3 preview 是混元大模型重建的第一步,希望通过开源和发布获得社区和用户的真实反馈。同时,混元团队也在继续扩大预训练和强化学习的规模,提升模型智能上限,并通过与腾讯众多产品的深度 Co-Design,持续提升模型在真实场景中的综合表现,探索特色模型能力。
 发表于 2026-4-26 00:54:26
|
查看: 174|
回复: 0
发表于 2026-4-26 00:54:26
|
查看: 174|
回复: 0
