上次发完五行知识库的介绍之后,一直在闷头开发。这周主要在做两个功能:一个是让系统自动识别你的意图——问具体问题就走精准检索,问总结性的问题就遍历所有文档综合分析;另一个是优化检索策略。过程中踩了几个坑,记录一下。
上下文窗口:从 32K 砍到 4K
这个是目前最大的挑战。
最初给模型的上下文窗口设的是 32K token,结果用 RTX 3080 跑的时候,系统直接卡死了——显存和内存都被吃光,整个电脑卡到动不了。
分析了一下原因:32K token 的上下文,加上模型本身的参数,本地 12G 显存的 3080 根本扛不住。
最后把上下文压缩到了 4K token,大约 2500 个中文字符。这个范围内模型运行稳定,系统不会卡。但代价也很明显——能塞进去的文档内容少了很多,检索结果必须精了再精。
所以这周专门做了检索优化:原来只有向量语义检索一条路,现在加了关键词检索,两路结果用 RRF 算法融合。简单说就是语义匹配和关键词匹配互补,在有限的上下文窗口里尽量塞进最相关的内容。
AI 回复格式问题
还有一个目前没完全解决的问题:AI 回复的内容里,有时候会直接带出 markdown 的原始标记。
比如回答里会出现 #### 标题 这样的井号标记,或者 **加粗** 的星号没有被正确渲染。这在全局分析功能里尤其明显——因为 Reduce 阶段的 prompt 要求模型输出结构化内容,模型有时候会混入 markdown 语法。
这个问题的根因是前端对模型输出的 markdown 解析不完整,后续需要优化渲染逻辑。
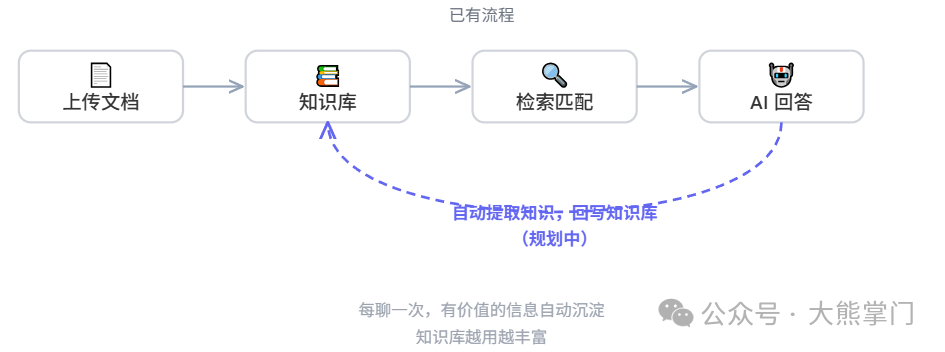
知识库的“自动生长”
最后聊一个更远的方向。
现在的知识库是“静态”的——你上传什么文档,它就只能基于这些文档回答。你跟它聊了一百次,它也不会变得更聪明。
理想状态是:每次对话结束后,系统自动从对话中提取有价值的知识(比如你告诉它某个产品的关键参数、某个结论的推理过程),然后自动写回知识库。下次再问相关问题,它就能用到这些“聊出来”的知识。
行业里管这个叫 Memory Layer(记忆层),目前最主流的开源方案是 Mem0。但这个功能实现起来不简单——怎么判断哪些对话内容值得沉淀、怎么去重、怎么处理过时信息,都是需要解决的问题。目前还在探索阶段。
对这个“自动生长”的概念感兴趣的朋友,可以在 云栈社区 和同好们一起聊聊,看看大家在本地 人工智能 项目里都踩过哪些坑,又是怎么解决的。 |  发表于 2026-4-29 05:21:16
|
查看: 101|
回复: 0
发表于 2026-4-29 05:21:16
|
查看: 101|
回复: 0
