你的 agent 在一次查询里向用户收了 38 美元。
不是因为它做了什么复杂事,而是因为它把同一份文档来回总结了 47 次:它发现自己已经做过这件事,然后又再做了一遍。没有崩溃,没有告警。只是一个不断空转的循环和不断增长的账单。
你去看模型日志。模型的表现完全符合训练预期。
问题在于:包裹在它外面的所有东西对它已经做过的事毫无记忆,没有 state 文件,没有停止条件。系统没有任何方式能说出:
“我们来过这儿了。”
这就是 demo 与生产级 agent 之间的鸿沟。
本文将为你拆解用来构建可靠 AI Agents 的 7 个 Harness 组件,并探讨为何 Agent 能力的天花板往往不在于模型本身。
没人会提前告诉你的鸿沟
做一个能跑通一次的 agent 真不难。调用一个 LLM,给点 tools,让它循环起来。二十来行 Python。你录个 demo,看起来干净漂亮。
然后你上线。真实用户发来意料之外的输入。
某个 tool 调用返回空。40 分钟后上下文(context)塞满。两个子 agent 互相矛盾。模型决定无限期重试某件事。
那些在 demo 里看不见的问题,到了生产里就变成了故障。
问题不在模型质量,而在 harness 质量。
“没有 harness 的模型就像没有神经系统的大脑。思考会发生,其他什么都不会。”
Agent = Model + Harness
这个框架会改变你的构建方式。
Agent = Model + Harness
Model → reasoning, language, decisions
Harness → everything the model needs to act reliably
如果你不是在做 model,你就在做 harness。
Harness 是包裹模型的每一行代码、每一份配置、每一个执行钩子(execution hook),它把一个文本生成器变成一个真正能完成工作的东西。
Model 决定做什么。Harness 确保它能安全、可重复、可扩展地去做。
大多数工程师把 90% 的时间花在 model 上:更好的 prompt、更新的模型、更多示例。生产上的失败几乎总是出在他们忽略的那 10%。
真正重要的 7 个组件

1. 控制循环(Control Loop)
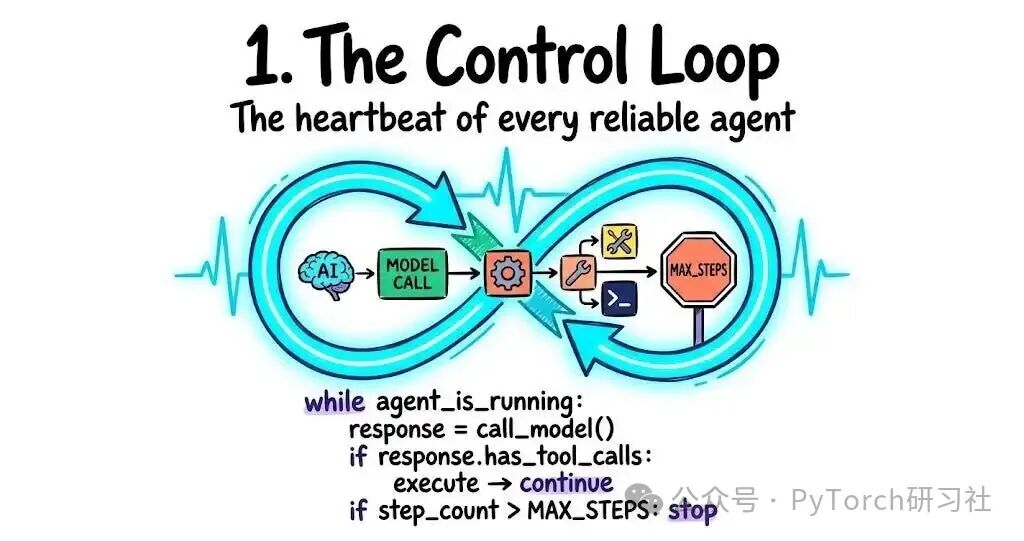
循环是 agent 的心跳。没有它,你只会得到一次模型调用和一次响应。那不是 agent,那只是个 chatbot。
这个循环运行模型,读取返回结果,执行任何 tool 调用,把结果反馈回去,然后重复,直到模型不再调用 tools,或者触发步数上限(step limit)。
while agent_is_running:
response = call_model(context)
if response.has_tool_calls:
results = execute_tools(response.tool_calls)
append_to_context(results)
continue
if response.is_final_answer:
return response.content
if step_count > MAX_STEPS:
return "Task incomplete. Max steps reached."
MAX_STEPS 这一行不是可选项。它是乖巧 agent 与 38 美元事故之间的分界线。在你写任何一个 tool 之前就把它加上。
一个糟糕的循环比没有循环更糟。没有停止条件、没有状态跟踪、没有检测重复 tool 调用,意味着模型可能会在一个它已经完成的任务上无限工作下去。
2. 状态管理(State management)

模型默认是无状态的。每次 API 调用都是从零开始。如果 harness 不明确跟踪发生过什么,agent 就不会记得自己已经做过什么、什么成功了、停在了哪里。
你需要两类 state:
- Session state:会话内发生的事:对话历史、tool 结果、当前 step 编号。
- Persistent state:会话结束后还会保留的东西。长任务的进度、已完成的子任务、已处理的文件。
最简单的生产级 state 存储就是一个 JSON 文件。跟踪任务进度、已处理项和当前状态。它可读、可调试、能在进程重启后幸存,而且不需要额外基础设施。
{
"task_id": "refactor-auth-module",
"completed_files": ["auth.py", "middleware.py"],
"pending_files": ["routes.py", "tests/test_auth.py"],
"current_step": 3
}
对跨大型代码库工作的 coding agent 而言,这个文件是能否持续推进的关键——没有它,agent 会在每次循环里反复改同一个文件。Git 再在此之上提供版本化:agents 可以跟踪工作、回滚错误、分支实验。
3. 记忆(Memory)
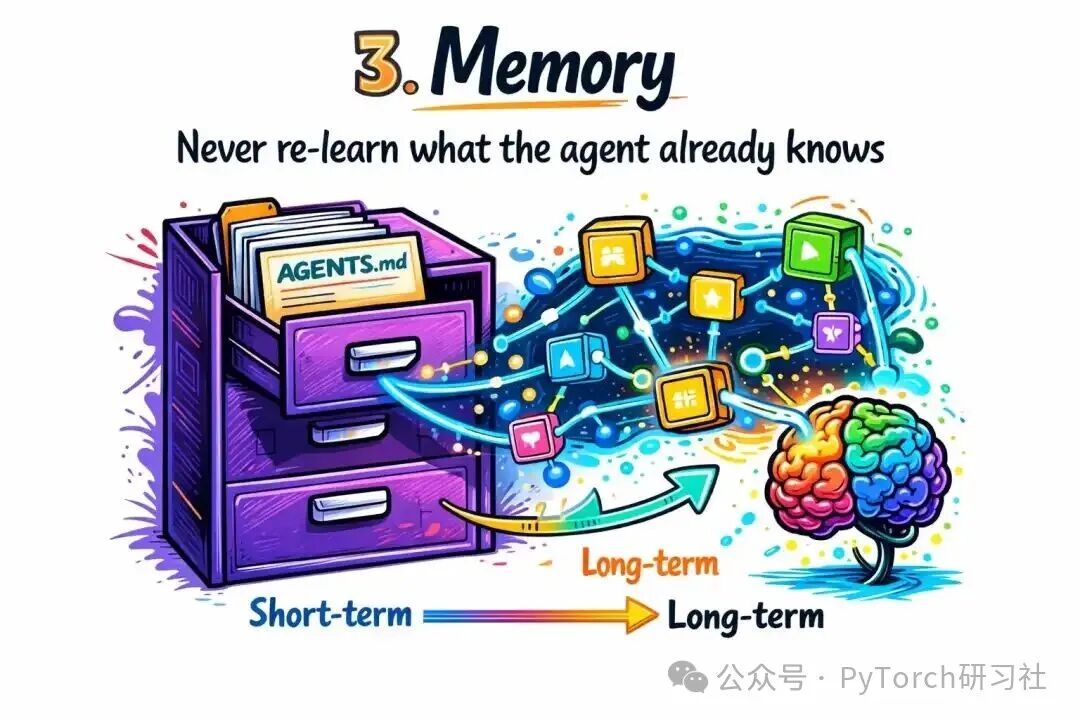
State 记录 agent 本次会话做了什么;Memory 则是它跨会话所知道的东西。
短期记忆就是对话历史:每条消息、每次 tool 调用及其结果都被添加到传给模型的列表中。
这实现起来很便宜,但不管理的代价很高。随着列表增长,token 成本攀升,性能会在触及硬上限前就开始下降。
长期记忆更难。一个帮助你写代码的 agent 应该记得你偏好显式错误处理而非异常。一个处理客服的 agent 应该记得某个客户上周遇到过账单问题。这通常存放在 vector database 里用于语义检索,或者在事实很具体时放在结构化文件中。
一个不错的生产模式:
Session start:
1. Load AGENTS.md or project memory file → inject into system prompt
2. Retrieve relevant memories based on current task → add as context
During session:
3. Maintain rolling conversation history
Session end:
4. Summarize key learnings → write to memory store
这些步骤里,harness 负责 1、2 和 4。Model 不会自行管理记忆——它做不到。
没有长期记忆的 agent 每次运行都要重新学习上下文。用户会注意到。他们会觉得 agent 在“忘记他们”,尽管模型本身完全有能力。这种信任的流失是 harness 问题,不是 model 问题。
注:system prompt 指系统级指令,上下文(context)和 context window 指传入模型的可见信息及其窗口大小。

Tools 把语言转化为行动。没有它们,模型只会生成“想做什么”的文本;有了它们,模型才能真的去做。
Tool 的设计比 Tool 的数量更重要。每加一个 tool 都要消耗 context(它的描述要塞进 prompt),也会增加模型选错 tool 的概率。三个描述出色的 tools 往往胜过十五个含糊不清的。
一个优秀的 tool 描述要回答三个问题:
- 这个 tool 实际做什么?
- 什么时候应该用它(不只是“可以用它的时候”)?
- 输出长什么样,以便我知道它是否成功?
bash 应急通道是改变 agents 能力版图的架构性举措。与其预先设计好每一个可能的 tool,不如给 agent 访问 bash 的能力,让它临时编写自己需要的 tools。这正是 Claude Code 处理开放式任务的方式。模型不受限于固定工具集,它会自行设计所需工具。
代价是安全性,因此一旦引入 bash,sandbox 隔离就变得不可妥协。
在本机运行 agent 生成的代码是有风险的,且单一环境无法扩展到并发工作负载。Sandboxes 提供安全、隔离的执行环境:运行代码、安装依赖、检查文件,且不触碰主机系统。它们按需启动、并行扩展、在工作完成后销毁。
一个配置良好的 sandbox 还应内置合适的默认项:语言 runtime、git CLI、测试运行器、浏览器。这使 agents 能自我验证:写代码、跑测试、看日志、修失败。Harness 负责搭建环境,Model 负责使用它。
5. 上下文管理(Context management)
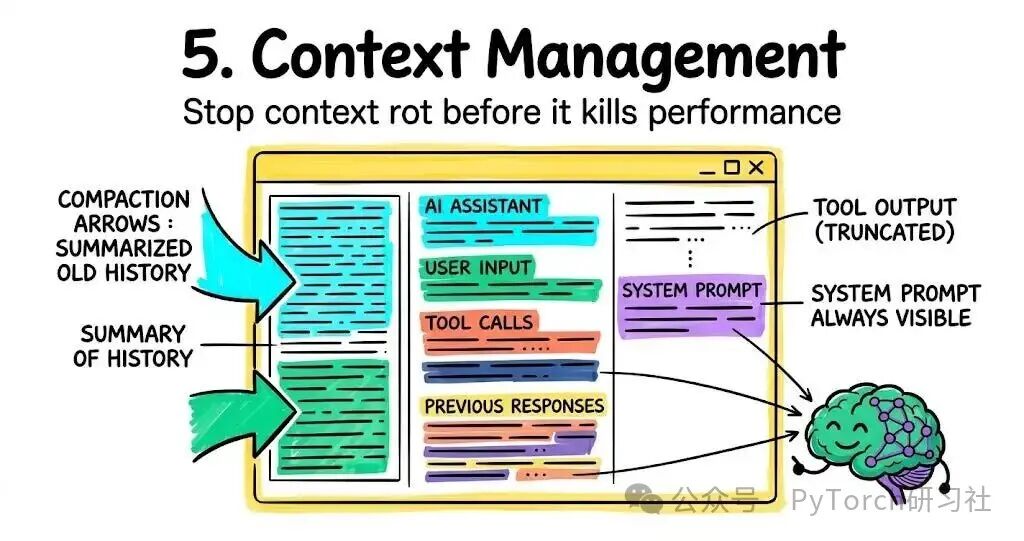
上下文腐烂(context rot)是最隐蔽的生产失败之一。
Agent 在前 40 分钟运行良好。现在它开始忽略自己的 system prompt。没有崩溃,没有报错。只是 context window 塞满了,重要指令被埋在中间,模型逐渐不再关注它们。
Harness 控制模型能看到什么——模型自己不行。
三种在生产中真正有效的模式:
- Compaction:当 context window 逐渐填满时,压缩较早的对话历史,而不是直接丢弃。关键约束:永远不要压缩最初的任务定义或 system prompt。其他都可商量。
- Tool output truncation:防止庞大的 tool 返回值淹没上下文。一份从抓取调用(fetch)里返回的 50 页文档会吃光预算,挤掉所有有用内容。Harness 只保留开头和结尾的 N 个 tokens,把完整输出存到 filesystem,如有需要给模型一个指针。
- Skills via progressive disclosure:解决冷启动问题。在会话开始时加载所有 tool 描述会让上下文在 agent 还没开始做事前就臃肿。Skills 在需要时按需加载其前置信息。当真正工作开始时,懒加载 50 个 skills 的 agent 往往优于一开始就加载 10 个 tools 的,因为上下文负担更低。
生产法则:你的 system prompt 和任务定义必须始终可见。先压缩历史,再动它们。
6. 规划(Planning)
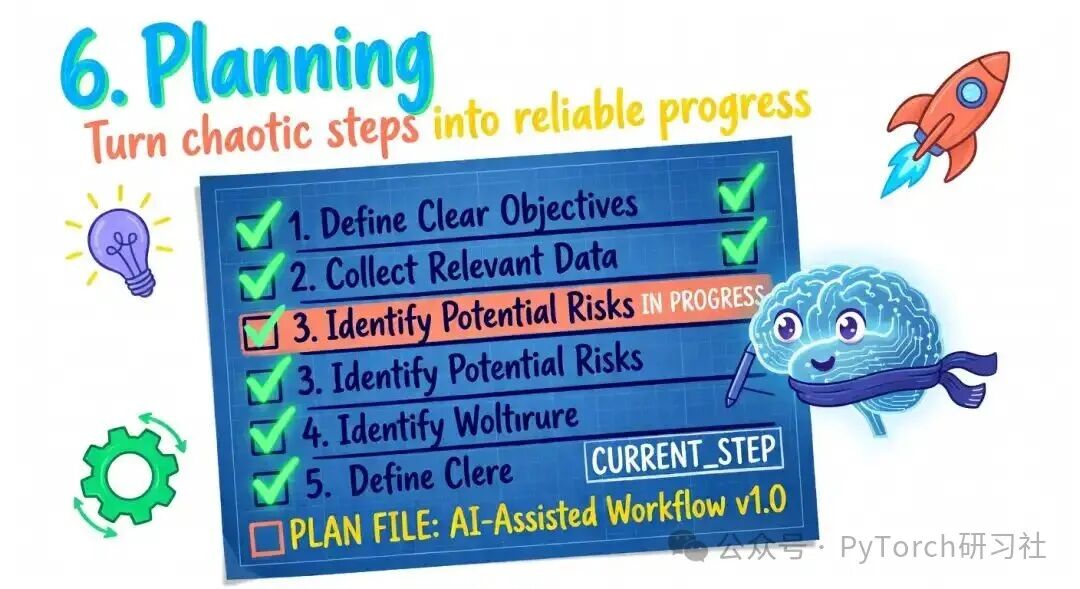
没有规划(planning)的模型会选择看起来最显而易见的下一步,哪怕它并不通往目标的连贯路径。
对简单任务来说这还行。对复杂的多步骤工作,则会导致不连贯:步骤乱序、重复、或因为不明显而被跳过。Agent 可以很强,但仍会失败,因为没人给它一个可执行的结构。
Plan file 模式是一个在生产中行之有效的最简修复:
task: Migrate database schema from v1 to v2
steps:
- Backup current schema [ ]
- Generate migration script [ ]
- Run migration on staging [x]
- Verify data integrity [ ]
- Run migration on production [ ]
- Update documentation [ ]
current_step: 4
Harness 在每次循环开始时把它注入上下文。Agent 完成步骤后打勾。会话结束后,plan 会持久化。当 agent 恢复时,它确切知道自己走到哪一步了。
自我验证(self-verification)闭合这个回路。每步完成后,agent 在继续之前验证结果。Harness 可以通过运行测试套件并反馈失败来强制执行这一点。一个写出迁移脚本并立即在 staging 环境上验证的 agent,要比写完就假设正确的 agent 可靠得多。
The Ralph Loop 值得你记住这个名字。当一个 agent 在长任务中用尽 context window 仍未完成目标时,Ralph Loop 通过一个钩子拦截这次退出,把原始目标注入一个全新的 context window,强制继续。Filesystem 让这成为可能:每个新的 context 都会从前一轮迭代读取 state。这就是跨多个 context window 实现真正长视程(long-horizon)自治的方式。
7. 错误处理(Error handling)

现实世界不会配合你。Tools 会失败。API 会限流。文件会缺失。模型偶尔会返回无法解析的输出。
没有明确的错误处理,agent 遇到这些情况只有两个烂选项:崩溃,或对错误视而不见并编造继续。两者在生产里都是失败。
Tool fails:
→ Retryable? (timeout, rate limit) → exponential backoff
→ Data error? → try alternative approach
→ Permissions error? → escalate to human
Model output malformed:
→ Retry with explicit format reminder
→ Three failures → fall back to structured output enforcement
Agent looping:
→ Step counter fires → force stop
→ Repeated identical tool calls detected → interrupt and redirect
Confidence low:
→ Flag for async human review
→ Do not block the user while waiting
升级路径(escalation path)是多数 harness 缺失的最重要一环。一个知道何时停下来求助的人类 agent,比一个总想强行做完的 agent 更有用。上线前设置明确的置信度阈值。
每一次 tool 调用都应该有明确的失败行为。不是“优雅地处理错误”,而是具体规定:如果返回空,做 X;如果报错,做 Y;如果超时,做 Z。
一个真实的 trace:生产级 agent 内部发生了什么
用户输入:“总结上个月关于欧盟 AI 监管的新闻报道中的关键论点。”
Step 1: Plan created
- Search for EU regulation news (last 30 days)
- Read top 5 results
- Extract argument clusters
- Synthesize into structured summary
Step 2: State check
No existing progress. Step counter initialized to 0.
Step 3: Search tool called
Returns 8 articles. Harness truncates each to 500 tokens → adds to context.
Step 4: fetch_url() called on top 5 results
Full text stored to filesystem. Agent gets summaries + file pointers.
Step 5: Context check
60% capacity. No compaction needed yet.
Step 6: Synthesis
Agent finds 3 major argument clusters → writes to context.
Step 7: Verification
Agent checks article dates. Two are 45 days old. Flags them.
Re-searches with tighter date filter. Adds 2 new articles.
Step 8: Final output
Structured summary with citations. Step counter: 9. MAX_STEPS: 20.
Step 9: State update
Plan file: all steps complete.
Key findings written to memory store for future sessions.
模型写出了总结。Harness 跟踪了 state、管理了 context、执行了验证、应用了步数上限、并写入了 memory。九个步骤,无需人工干预,输出正确。
这才是 harness 真正做的事。它并不光鲜,却决定了工具是“偶尔有效”还是“可靠可用”。
会绊倒你的边界情况
- 有 tools 仍然幻觉(Hallucination despite tools)。Agent 明明有搜索 tool,结果用了训练数据里的老印象来回答。当 tool 描述没有明确说明“哪些问题必须先调用 tool 再回答”时,就会这样。修复:明确指出哪些问题在回答前必须发起 tool 调用。
- 无限循环(Infinite loops)。模型在得到空结果后,带着细微变化反复重试同一个 tool。它把“空”理解成“再试一次”,而不是“思路不对”。修复:检测重复的相同 tool 调用,并用重定向 prompt 打断。
- 上下文溢出(Context overflow)。Agent 在前 30 分钟表现很好,现在开始无视自身指令。Context 慢慢塞满,system prompt 被埋,性能悄然劣化。修复:压缩策略,并强制规则——任务定义必须始终出现在上下文的开头与结尾。
- tool 误用(Tool misuse)。先写后读、删除代替归档。当 tool 描述对使用前置条件含糊时会发生。修复:描述里要写清“什么时候不该用这个 tool”,不只是“什么时候该用”。
- 时延爆炸(Latency explosion)。一串看似合理的 tool 调用导致 45 秒响应。修复:可独立的 tool 调用并发执行,而不是串行。先度量 harness 决策带来的时延,再去动 model。
关于 model–harness 耦合多数工程师不知道的一件事
像 Claude Code 这样的现代 coding agents,是在 model 与 harness 同时运行的情况下进行后训练(post-trained)的。模型之所以会学会 filesystem 操作、bash 执行与规划,部分原因就是它在 harness 中运行、并因这些行为被奖励。
这带来了一个有趣的副作用。
改变 tool 逻辑往往会降低模型性能,即便新逻辑在功能上是等价的。一个在特定 patching 格式上训练过的模型,如果你换了格式(哪怕逻辑等价),表现也会变差。在 harness 环中训练会形成对该 harness 设计的一种“过拟合”。
实际后果:开箱即用的 harness 不一定最适合你的任务。在 Terminal Bench 2.0 排行榜上,放在 Claude Code 里的 Opus 4.6,得分显著低于放在自定义调优 harness 里的 Opus 4.6。相同的模型,不同的 harness,排名可量化不同。
多数团队还从未触碰过 harness 优化。真正的性能潜力就藏在这里。这也是为什么我们常说,与其追逐最新的模型,不如深入 开源实战 社区,看看那些 Star 量高企的 Agent 项目是如何打磨它们的底层架构的。
何时不该用 agents
Agents 往往并不是正确的工具——比人们愿意承认的还要常见。
当相同输入总会经由相同步骤产出相同输出时,用确定性的 pipeline。硬编码。它比任何 agent 都更快、更便宜、更可靠。
当一旦出错就会删掉生产数据、或发错邮件给错误的人时,设置明确的人为关卡。把 agent 的建议与执行分离。Agents 会犯错,确保这些错误不可逆。
当输入是结构化的,处理是基于规则的,干脆别用 agents。往一个表单提交流程里塞个 agent,是过度工程,而不是改进。
“Agent 不是 workflow 的升级版。它是用来解决另一类问题的不同工具。先弄清你手里是哪类问题。”
最清晰的过度工程信号:工作流中每一步都有唯一正确动作,路径完全确定,而你想用 agent 的主要原因,是因为 agent 看起来很酷。确实很酷。但对确定性 pipeline 来说,它就是杀鸡用牛刀。
从零开始时该怎么做
按这个顺序加。每一层都针对该阶段最常见的失败。
- Control loop with a step limit。在有任何 tools 之前。MAX_STEPS = 10 能在事故发生前就避免“通宵计费”。
- State file。一个跟踪已发生与接下来要做什么的 JSON。每次循环开始都读取它。
- Tool set。三到五个,描述要好。只有在发现明确缺口时再加。
- Error handling。每个 tool 在上线前都定义清晰的失败行为。
- Context compaction。只在你看到长会话的性能劣化时再加,不要太早。
- Memory。当用户开始抱怨 agent 在遗忘它本该知道的事时再加。
- Planning。当任务跨越多个会话或超过单个 context window 时再加。
这个顺序不是随意的。没做第 2 步就跳到第 6 步,你会在错误的地方调试。如果想查阅更多避坑指南和架构设计范本,不妨收藏这份 技术文档 集。
最后的想法
一个构建良好的 agent,最棒的地方不在一切顺利时它做了什么,而在出问题时它会怎么做。
随着模型进步,今天部分由 harness 承担的东西会被模型原生吸收。模型在不需要太多 prompt 辅助的情况下,会更擅长规划与自我验证。一些 harness 的复杂度也会真正变得不再必要。
但围绕模型智能的工程——恰当的 tools、持久的 state、上下文管理、验证循环——无论模型能力如何,都会让任何模型更有效。这不是在“打补丁弥补缺陷”,而是系统设计。
模型每隔几个月就会变好。Harness 则有赖于你来打造。
“Model 不是你的 agent,Harness 才是。把投入用在刀刃上。”
 发表于 2026-4-29 07:30:27
|
查看: 244|
回复: 0
发表于 2026-4-29 07:30:27
|
查看: 244|
回复: 0
