开发应用程序越久,就越容易对某些“标准答案”式的技术问题产生刨根问底的冲动。比如:“数据库连接为什么很消耗资源?”
这个问题,好像人人都能说上几句,但要真追根究底,用数据说话,可能很多人都解释不清。本文就来深入探究一下,尤其在 Web 应用中,为什么强烈建议使用数据库连接池——毕竟,我们都不希望每次请求都从头建立连接。理论上,大家认同“建立连接很耗时”,但这个耗时究竟是多久?时间都花在了网络、认证,还是其他环节?
为了量化这个问题,我们以开源且通信协议公开的 MySQL 数据库为例,利用 Java 语言进行一次抓包分析。本文的资源消耗分析将主要集中在网络交互层面,当然,内存与CPU等计算资源也在消耗之列,但网络的往返延迟往往是最显而易见的瓶颈。
下面这段极其简单的 Java 代码,是我们分析的基础。它完成的功能仅仅是建立一个数据库连接,随后程序退出,连接被强制断开。
Class.forName("com.mysql.jdbc.Driver");
String name = "xttblog2";
String password = "123456";
String url = "jdbc:mysql://172.16.100.131:3306/xttblog2";
Connection conn = DriverManager.getConnection(url, name, password);
// 之后程序终止,连接被强制关闭
接下来,我们用 Wireshark 对这次简短的连接过程进行抓包,来揭示其背后的交互细节。
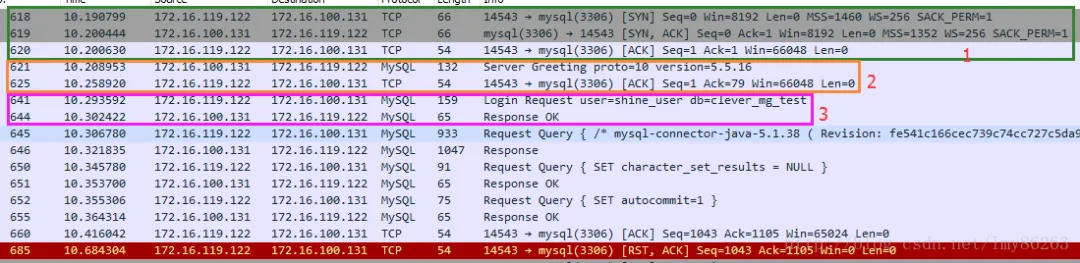
从上图可以清晰地看到,MySQL 的通信协议是基于 TCP 的二进制协议,而非像 HTTP 那样的文本协议。建立连接的过程可以拆解为三个关键阶段:
- 第一步:TCP三次握手。这是所有基于
TCP 协议通信的基石,用于在客户端和服务器之间建立一个可靠的传输通道。
- 第二步:握手与认证协商。服务器主动向客户端发送“握手信息”,客户端收到后必须做出响应。
- 第三步:客户端发送认证包。客户端将用户名、密码等信息打包发送给服务器进行验证。验证成功后,服务器返回OK响应。至此,连接才算真正建立。
在用户验证成功后,客户端和服务器还会有几次交互,用于设置一些连接变量,比如字符集、是否自动提交事务等。这些步骤全部完成后,你的 SQL 语句才能被真正执行。
在我们的测试代码中,并没有通过这个连接执行任何业务操作。程序跑完几行代码就结束了,连接不是由 Connection.close() 优雅关闭的,而是进程终止导致的异常断开,因此在抓包末尾会看到一个 TCP 的 RST 报文。好消息是,由于我们没有设置任何额外的连接属性(虽然驱动仍会默认设置一些,但这已基本是最小开销),这次连接所消耗的时间可以认为是最少的“裸”连接耗时。
分析统计数据可以发现,即便在最快的情况下,要完成一次连接(不包括最后的 RST 报文),客户端和服务器之间的数据包也要 至少往返7次。从时间戳上看,从 TCP 第一次握手到连接被强制关闭,总耗时:
10.416042 - 10.190799 = 0.225243s = 225.243ms
仅建立一次数据库连接,就花掉了超过225毫秒! 当然,这个时间会受到网络状况、数据库服务器性能以及应用代码效率的影响,但它已经足够说明问题。
上面的例子属于进程异常终止。在正常的应用程序中,我们通常用 Connection.close() 来关闭连接,代码如下:
Class.forName("com.mysql.jdbc.Driver");
String name = "shine_user";
String password = "123";
String url = "jdbc:mysql://172.16.100.131:3306/clever_mg_test";
Connection conn = DriverManager.getConnection(url, name, password);
conn.close();
在优雅关闭的场景下,断开过程发生了变化,主要体现在与 数据库 的通信上,如抓包图所示:
客户端在 MySQL 协议层首先发出 Quit 请求,并无需等待服务端响应,随后立即进入 TCP 的四次挥手阶段,来完成连接的断开。
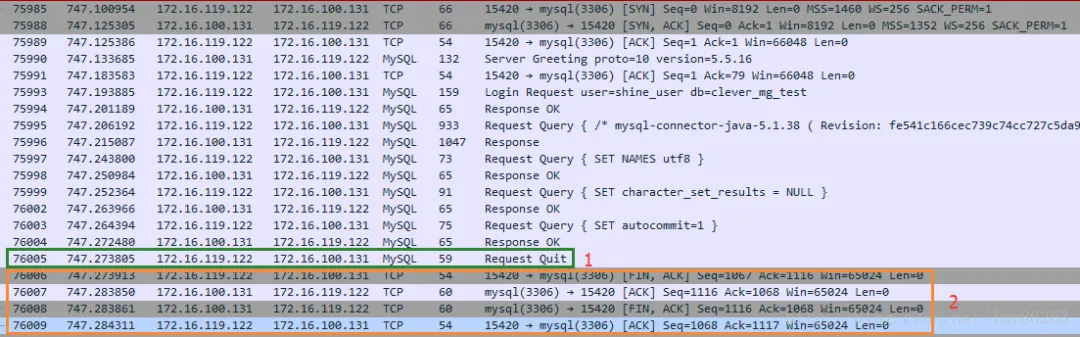
这次完整经历了从连接建立到优雅关闭的全过程,总耗时计算如下:
747.284311 - 747.100954 = 0.183357s = 183.357ms
此次耗时约183ms,虽然比上面异常终止的225ms稍短一些(可能受网络波动影响),但依然接近200毫秒的量级。现在,我们来想象一个业务场景:假设你开发的一个网站日活跃用户达到了2万,每个用户平均发起5次请求,那么一天就是10万个请求。我们乐观地取150毫秒作为一次连接的耗时,那一天下来,光是花在建立数据库连接上的时间就是:
100000 * 150ms = 15,000,000 ms = 15,000 s = 250 min ≈ 4.17 h
每天竟然有 超过4个小时 的时间仅仅消耗在了建立连接这种“重复劳动”上!这还完全没有计算执行查询和更新操作的时间。随着日活量的增加,这无疑是系统吞吐量的一大杀手。这也解释了为什么在后端架构设计中,连接池是必不可少的。当然,单一的连接池也并非银弹,当流量继续增长时,我们还需要考虑缓存、SQL 预编译、负载均衡等一系列综合优化手段,才能确保服务的稳定运行。
回到最初的问题,为什么连接数据库如此消耗资源?核心就在于 网络往返的次数与延迟。每一次 TCP 握手、每一次协议层的认证与变量设置,都在物理网络上产生了实实在在的时间开销。理解这一点,我们才能在设计高并发系统时,真正发自内心地重视连接池、做好本地缓存,并审慎地规划每一次网络I/O。
 发表于 2026-5-4 17:38:17
|
查看: 104|
回复: 0
发表于 2026-5-4 17:38:17
|
查看: 104|
回复: 0
