真有员工把话挑明了:建议给P9以上领导做个智力、记忆力筛查,也不是空穴来风。听着像气话,其实憋了一肚子真情实感。
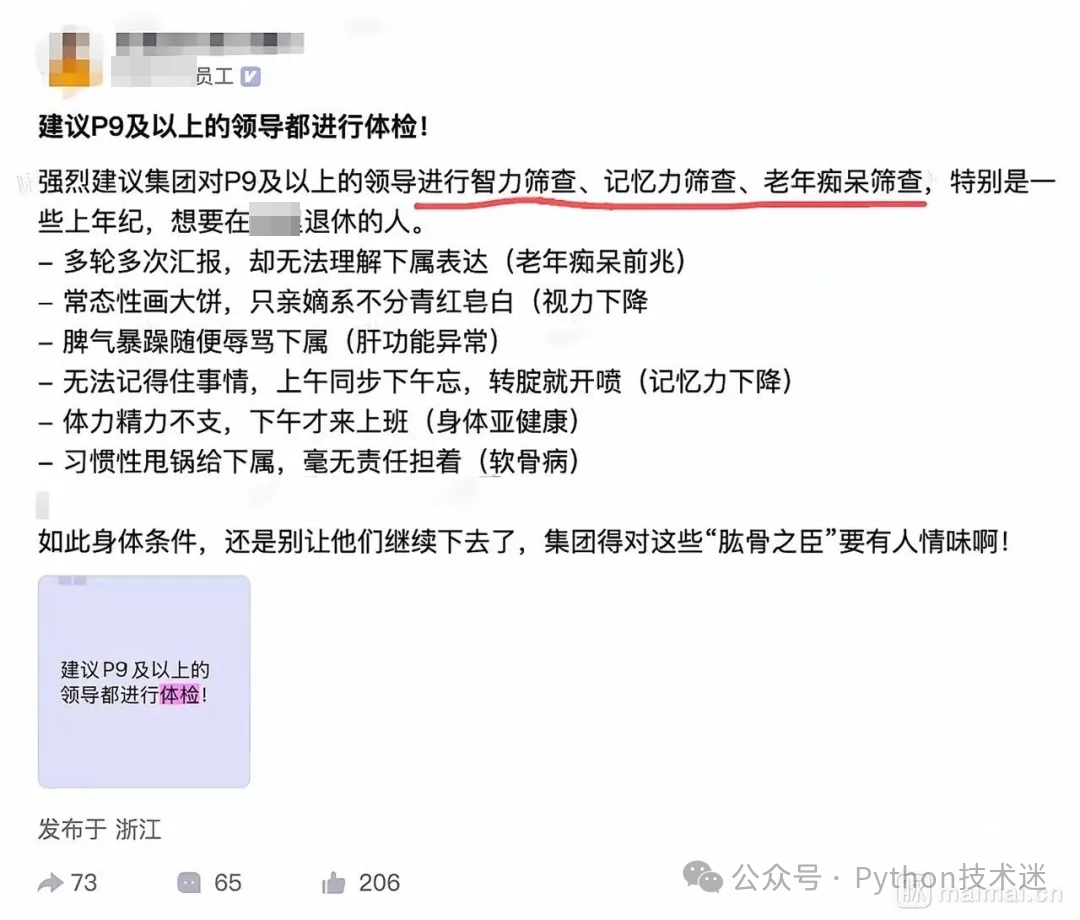
为什么骂到这一步?大家也不是闲得慌。主要是有些老领导反复讲那套东西,会上拍脑袋,会后全忘,流程绕三圈,最后还得下面的人擦屁股。你说他不管吧,他处处要过问;你说他真懂吧,问两句又开始飘。
这话毒,但混过职场的人都懂。很多公司最大的问题不是没人干活,而是上面有些人年纪、位置、惯性全叠满了,还坚信自己一句话能定生死。底下人改方案改到半夜,他第二天来一句“我昨天不是这个意思”。这类事看多了,有时也忍不住去云栈社区瞄一眼,看看大家是不是都在经历同样的剧本。
算法题:数据流的中位数
堆一把数字进来,要求随时给出中位数。这题看着像“查一下数组中间那个数”就完了,可真上手写,很多人第一版就栽在复杂度上。
最直觉的写法,是来一个数就塞进列表,然后排序,再取中间位置。代码不难看懂,可一旦数据流变长,性能就开始发虚。每插一次都全量排序,代价太高。这种代码我一般在面试里看到,第一眼就不太信。题目既然强调“数据流”,意思就不是让你离线算一次,而是边来边维护。这里得换思路。
这题的关键,不在“怎么找中位数”,而在“怎么让中间位置始终稳定”。
我一般会把数据拆成两半:
左边一堆,保存较小的一半;右边一堆,保存较大的一半。
然后保证两个条件:
- 左边所有数都不大于右边所有数
- 两边数量差不超过 1
这样中位数就很好拿了。
如果总数是奇数,中位数就是元素更多那一边的堆顶。
如果总数是偶数,中位数就是两边堆顶的平均值。
Python 里 heapq 只提供小根堆,没有现成大根堆,这也不是什么事,把左边的数取相反数塞进去就行。
代码直接看,别绕概念:
import heapq
class MedianFinder:
def __init__(self):
# left 用负数模拟大根堆,保存较小的一半
self.left = []
# right 是小根堆,保存较大的一半
self.right = []
def add_num(self, num: int) -> None:
# 先往 left 塞,再把 left 最大的挪到 right
heapq.heappush(self.left, -num)
heapq.heappush(self.right, -heapq.heappop(self.left))
# 保证 left 的数量不少于 right
if len(self.right) > len(self.left):
heapq.heappush(self.left, -heapq.heappop(self.right))
def find_median(self) -> float:
if len(self.left) > len(self.right):
return float(-self.left[0])
return (-self.left[0] + self.right[0]) / 2.0
这段代码短,但是味道是对的。
比如数据流依次进来:5, 2, 10, 4
过程大概是这样:
- 来 5:左边
[5],中位数 5
- 来 2:左边
[2],右边 [5],中位数 (2+5)/2 = 3.5
- 来 10:左边
[5,2],右边 [10],中位数 5
- 来 4:左边
[4,2],右边 [5,10],中位数 4.5
可以顺手跑一下:
mf = MedianFinder()
for x in [5, 2, 10, 4]:
mf.add_num(x)
print(f"add {x}, median = {mf.find_median()}")
输出:
add 5, median = 5.0
add 2, median = 3.5
add 10, median = 5.0
add 4, median = 4.5
这个题真正该答出来的,不只是“双堆”三个字,而是你得知道为什么这么维护。
因为堆顶永远是当前这一半里最有代表性的那个数。左边堆顶是“小的一半里最大的”,右边堆顶是“大的一半里最小的”。中位数卡在中间,天然就落在这两个位置附近。这个结构一旦稳定下来,每次插入只需要做有限次堆调整,单次复杂度是 O(log n),取中位数是 O(1)。这就比“每次全排序”的 O(n log n) 靠谱太多了。
再多说一句,这题还有个容易写歪的点:别一会儿比较 left,一会儿比较 right,塞来塞去把自己绕晕。上面这个写法我比较喜欢,顺序固定:
先丢 left,再把 left 最大的挪到 right,最后看数量要不要回调一次。
逻辑很顺,不容易漏边界。写算法题,代码短不是本事,短还不容易错,这才像能交上去的版本。
 发表于 2026-5-7 21:17:53
|
查看: 99|
回复: 0
发表于 2026-5-7 21:17:53
|
查看: 99|
回复: 0
