在日常的渗透测试中,你是否也经常碰到这种情况——打开目标网站,除了白茫茫一片,什么都没有?很多师傅面对空白页面往往感到无从下手。但空白往往只是表象,背后很可能藏着未被发现的管理后台、API接口,甚至是严重的安全漏洞。下面这七种实战思路,就是为了帮你把“死胡同”变成突破口。
在 云栈社区 的渗透实战板块中,我们也常看到类似的空白页面突破案例,社区师傅们的经验同样印证了这些方法的有效性。
一、目录扫描
当首页一片空白时,不要只盯着首页。使用 dirsearch、Tscan 这类自动化目录扫描工具,系统地遍历网站的目录结构,尝试访问那些可能存在的隐藏目录或文件。
常见的目标路径包括:
- 目录:
/admin, /login, /api, /test
- 文件:
robots.txt, .git/, .env, web.config
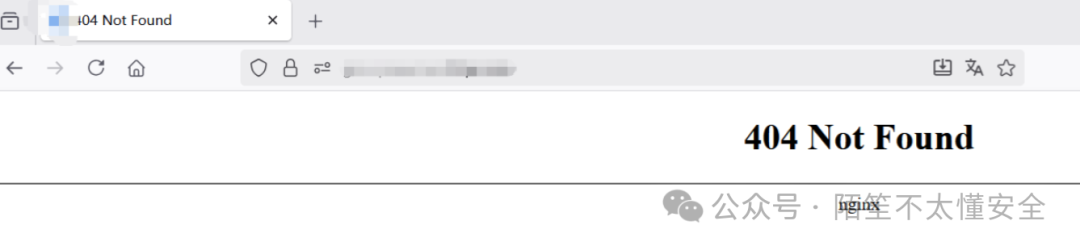
案例
直接访问某网站返回了 404 Not Found,但通过 dirsearch 扫描后,发现了一个 /admin 路径。拼接访问后,成功定位到了后台管理界面。

二、指纹识别
利用 ehole、Tscan 等指纹识别工具,探测目标网站的技术栈、中间件、开发框架或 CMS。一旦识别出具体是什么系统,就可以进一步利用已知漏洞(Nday)或者进行代码审计。
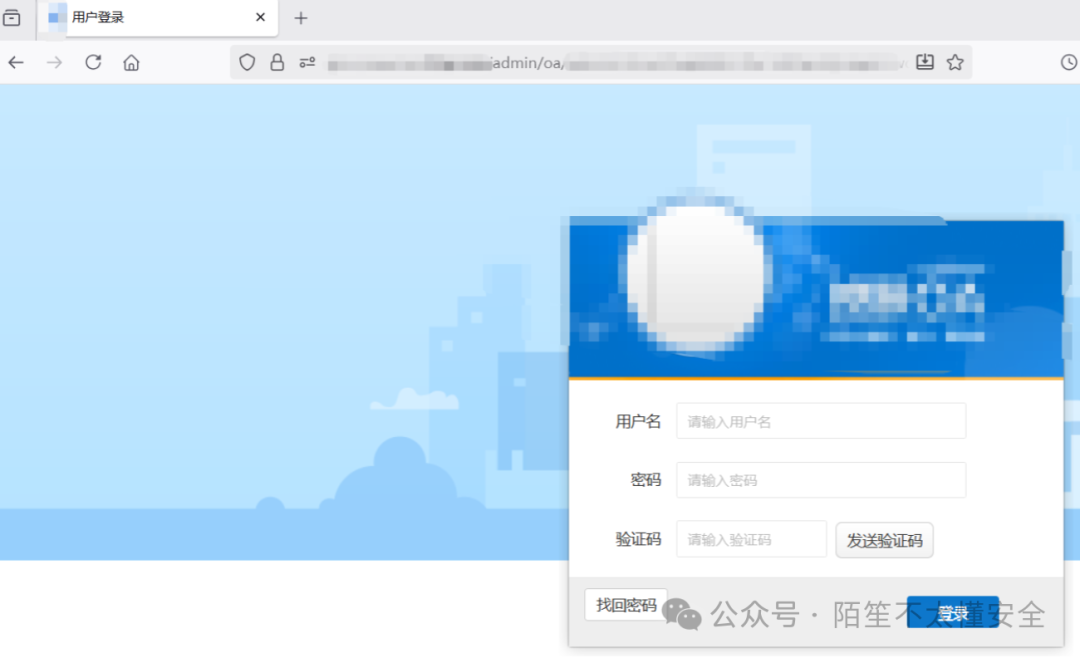
案例
通过 Tscan 的 Web 指纹识别功能,发现某网站实际使用了 XXL-JOB 调度系统。随后拼接 XXL-JOB 的后台地址 /xxl-job-admin/toLogin,直接访问到登录页面。

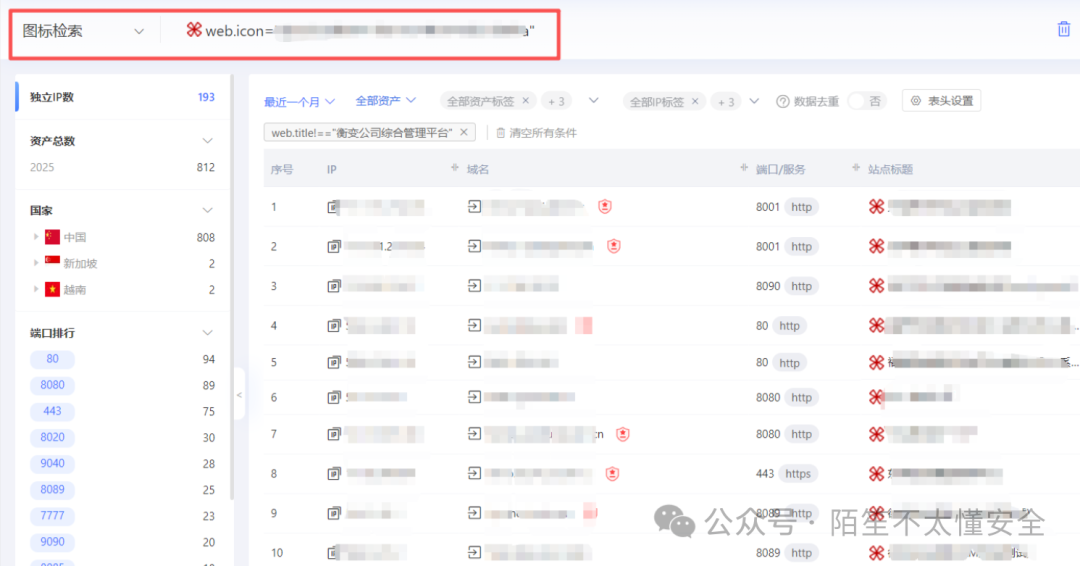
三、icon 搜索
网站的图标文件 favicon.ico 通常位于根目录。即便页面空白,这个文件往往还在。把它下载下来,利用 Hunter、Fofa 等资产测绘平台进行图标哈希搜索,就能找到使用相同图标的站点,从而推断出可能存在相同系统或隐藏路径,扩大攻击面。
案例
下载目标网站的 icon 文件后,在 Hunter 中反向查询图标哈希,发现了大量使用同一套系统的站点。顺藤摸瓜,很快就定位到了隐藏的后台功能页面。
四、域名拼接
有些站点会基于域名来划分逻辑路径,比如将子域名的一部分作为实际访问路径。分析域名结构,尝试把子域名或其中的关键字段拼接到主域名后面,经常会撞到测试环境、预发布页面或者特定功能入口。
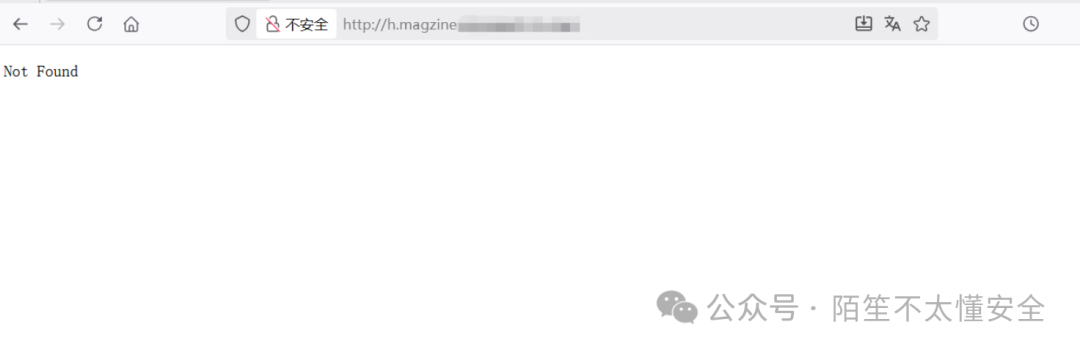
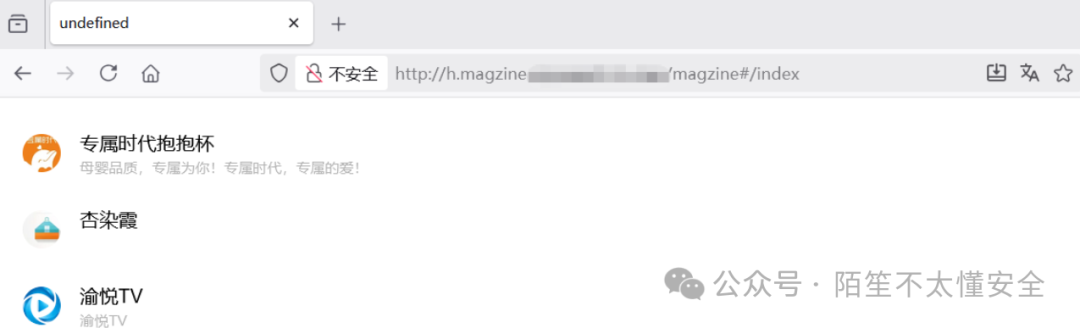
案例
目标域名为 h.magzine.example.com,尝试在 example.com 后面加上 /magzine 路径,结果顺利打开了一个原本空白首页中完全看不到的内容聚合页面。
五、路由拼接
现在很多网站采用 Vue.js、WebPack 等前端框架,路由大多由 # 来管理。即便首页渲染异常,只要能拿到前端 JS 文件(比如 app.js、main.js),分析其中的路由定义,通常能挖出隐藏的功能路径。
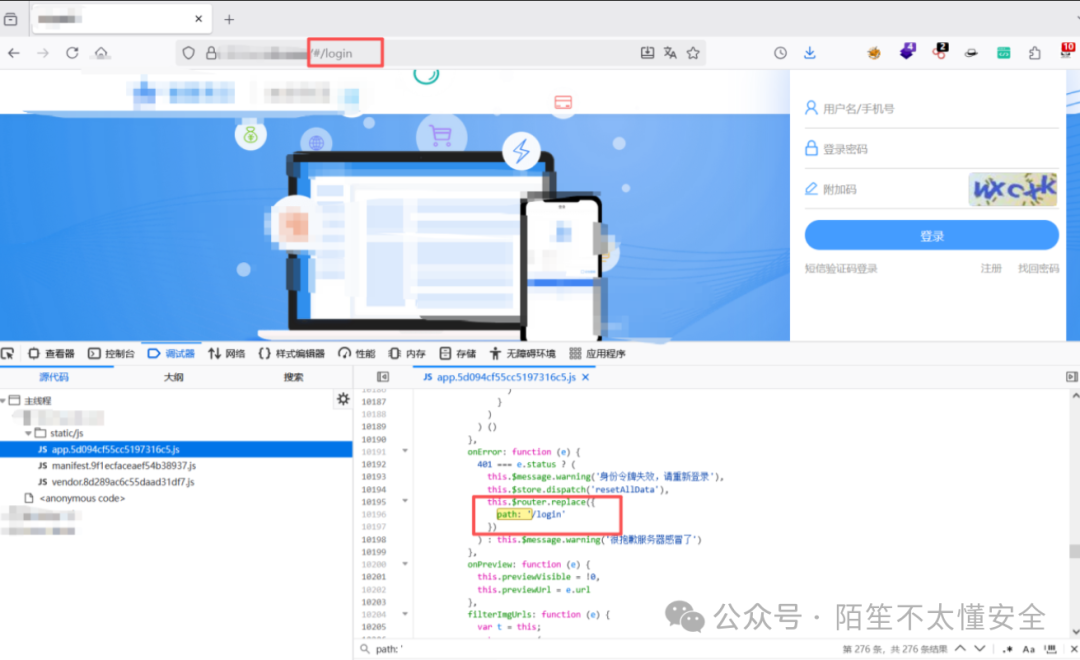
案例
一个看起来空白的页面,检查其引用的 JS 文件,全局搜索 path: 关键字,果然发现了一条路由 path: '/login'。直接在原始 URL 后面加上 #/login,成功跳转到了登录页面。
六、JS 接口
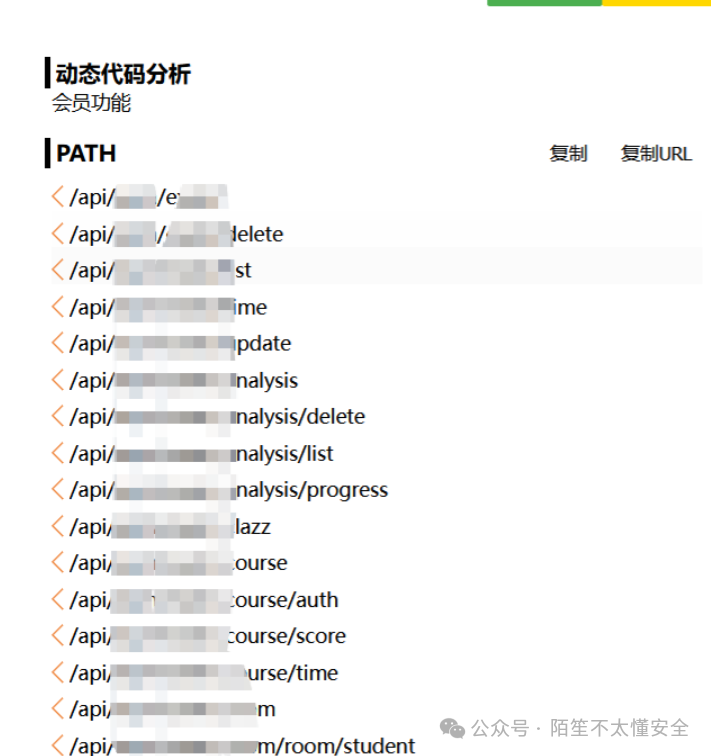
前端 JS 文件里经常硬编码着大量 API 端点、接口密钥之类的敏感信息。使用 findsomething 这类工具可以批量从 JS 中提取出所有接口地址。接着,重点测试这些接口是否存在未授权访问、越权等漏洞,很多时候能直接拿到数据。
案例
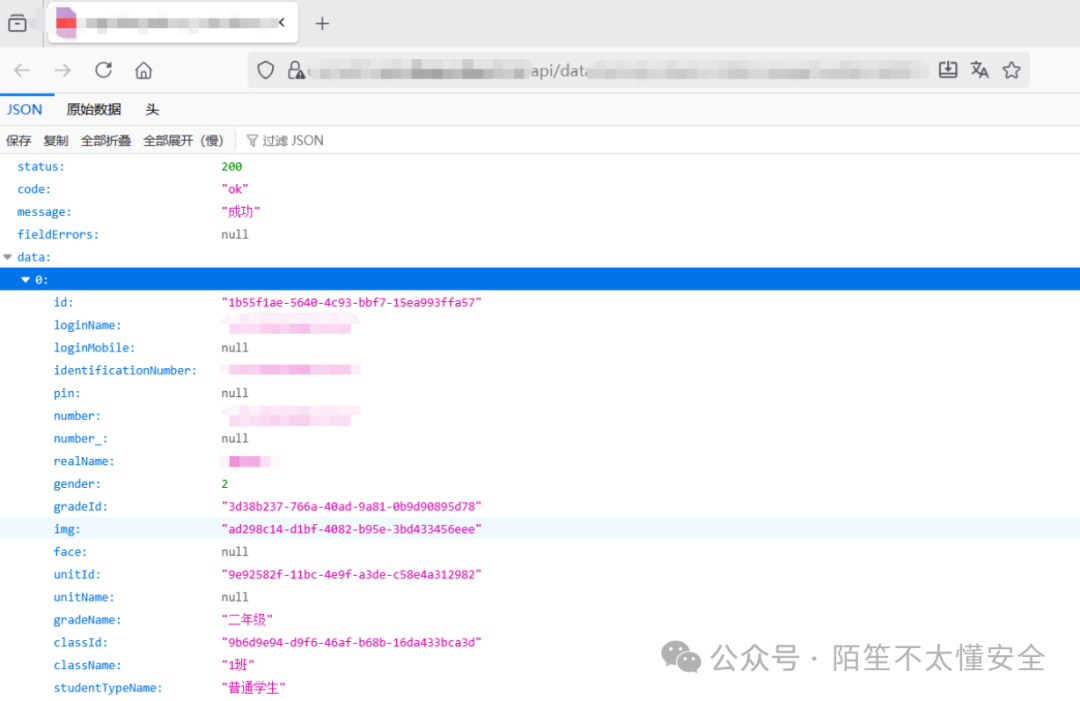
通过 findsomething 提取出完整的 API 列表后,逐个拼接测试,发现某个数据列表接口完全没有做身份验证,未授权就能拿到大量敏感数据。
七、历史记录
搜索引擎和代码仓库的记录里,往往藏着已被删除或隐藏的资产、配置文件甚至明文密码。常见的技巧包括谷歌高级搜索语法和 GitHub 信息收集工具,比如 GitDorker。
常用的谷歌语法:
site: 限定在特定网站或域名搜索,例如 site:example.cominurl: 搜索 URL 中包含特定关键词的页面,例如 inurl:login、inurl:.bash_historyfiletype: 搜索特定文件类型,例如 filetype:sql、filetype:log、filetype:bakintitle: 搜索标题中包含特定关键词的页面,例如 intitle:"index of"
GitDorker 是一个利用 GitHub Search API 和大规模 dork 列表的自动化信息收集工具,专门用于挖掘仓库中的敏感信息。
使用方法:
python GitDorker.py -tf ./tf/TOKENSFILE -d ./Dorks/alldorksv3 -q example.com -o example.com
案例
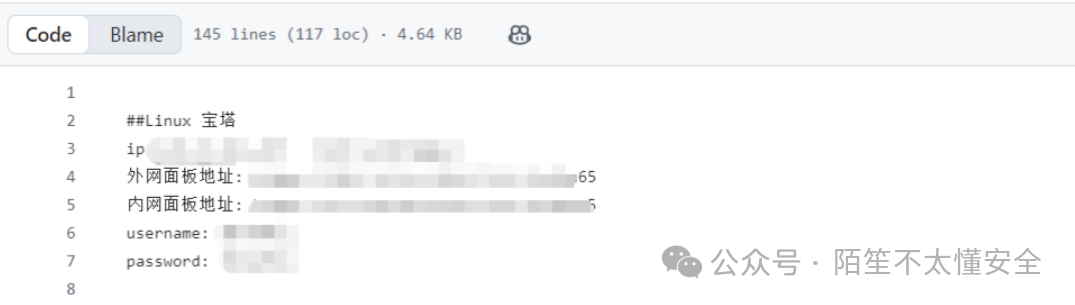
利用 GitDorker 对目标进行信息收集,结果翻出来一份 Linux 宝塔面板的明文账号密码,直接拿下了多个关联网站。
以上七种方法,大多不需要什么高深技巧,但组合起来往往能产生奇效。下一次再碰上空白页面,不妨按这几条思路逐一尝试,说不定突破口就在其中。
 发表于 2026-5-11 19:23:20
|
查看: 100|
回复: 0
发表于 2026-5-11 19:23:20
|
查看: 100|
回复: 0
