机器学习模型无法直接处理原始文本或类别标签。无论是线性回归、XGBoost还是复杂的神经网络,面对诸如 "red"、"medium"、"CA" 之类的分类变量时,都要求我们首先将其转换为数值形式,这个过程即为分类编码。
入门时,大家通常接触到的是独热编码或序数编码,但这仅仅是编码技术的冰山一角。实际上,编码方法多种多样。例如目标编码、CatBoost编码、James-Stein编码等高级技术,若能恰当使用,能显著提升模型性能,在处理高基数特征时尤其有效。
编码的重要性
以 "Toyota" 为例,这个字符串本身并不具备数值意义,但模型只能处理数字。我们通常需要将其映射,例如:
{"Toyota": 0, "Ford": 1, "Honda": 2}
或者表示为向量形式:
[0, 1, 0]
更高级的做法是将其编码为与目标变量相关的数值:
Toyota → +0.12 mean adjusted uplift in target
编码方式的选择,直接关系到模型的准确率、可解释性、过拟合风险、训练速度、内存消耗以及对稀有类别的处理能力。
示例代码准备
后续所有编码示例都将基于以下简单的数据集和Python代码框架:
import pandas as pd
from sklearn.model_selection import train_test_split
import category_encoders as ce
from sklearn.linear_model import LogisticRegression
df = pd.DataFrame({
"color": ["red", "blue", "green", "green", "blue", "red"],
"city": ["NY", "LA", "NY", "SF", "LA", "NY"],
"target": [1, 0, 1, 0, 0, 1]
})
X = df.drop("target", axis=1)
y = df["target"]
1、序数编码 Ordinal Encoding
这是最直接的方法,为每个类别分配一个唯一的整数。例如,red->0, blue->1, green->2。
当类别本身存在自然顺序(如 small/medium/large)时,这种方法很合适。对于 XGBoost、LightGBM 等树模型,序数编码通常已足够。
encoder = ce.OrdinalEncoder(cols=["color"])
X_trans = encoder.fit_transform(X, y)
2、独热编码 One-Hot Encoding
每个类别被扩展为一个新的二元特征列,属于该类别则标记为1,否则为0。

线性回归、逻辑回归和神经网络常使用此方法。需注意,若类别数量过多,会导致特征维度急剧膨胀,因此仅适用于低基数特征。
encoder = ce.OneHotEncoder(cols=["color"], use_cat_names=True)
X_trans = encoder.fit_transform(X)
3、二进制编码 Binary Encoding
首先将类别转换为序数索引,然后将该索引转换为二进制数,并将每一位拆分为独立的列。例如,索引5(二进制101)会生成三列。
此方法在类别数量中等(如50到500个)时表现优异,它在保持稀疏性的同时,比独热编码更节省内存。
encoder = ce.BinaryEncoder(cols=["city"])
X_trans = encoder.fit_transform(X)
4、Base-N编码
二进制编码的泛化形式,允许使用任意进制(N)进行编码。例如,设置base=3时,序数索引5会被编码为"12"。可用于精细控制输出特征的维度。
encoder = ce.BaseNEncoder(cols=["city"], base=3)
X_trans = encoder.fit_transform(X)
5、哈希编码 Hashing Encoding
利用哈希函数将类别映射到固定数量的特征列上。优点是速度快,输出维度固定,且无需存储类别映射字典。缺点在于可能存在哈希冲突,且结果难以解释。
encoder = ce.HashingEncoder(cols=["city"], n_components=8)
X_trans = encoder.fit_transform(X)
6、Helmert编码
一种正交对比编码。每个类别的编码值代表该类别的平均值与其后所有类别平均值的比较。常用于统计建模和回归分析中的分类变量处理。
encoder = ce.HelmertEncoder(cols=["color"])
X_trans = encoder.fit_transform(X, y)
7、求和编码 Sum Encoding
也称为偏差编码。每个类别的编码值表示该类别均值与总体均值的偏差,而不是与某个基准类别比较。
encoder = ce.SumEncoder(cols=["color"])
X_trans = encoder.fit_transform(X, y)
8、多项式编码 Polynomial Encoding
为有序类别生成线性、二次、三次等对比项。当怀疑类别对目标存在非线性影响时,可考虑使用。
encoder = ce.PolynomialEncoder(cols=["color"])
X_trans = encoder.fit_transform(X, y)
9、向后差分编码 Backward Difference Encoding
每个类别的编码值代表该类别的平均值与其前面所有类别平均值的比较,与Helmert编码方向相反。
encoder = ce.BackwardDifferenceEncoder(cols=["color"])
X_trans = encoder.fit_transform(X, y)
10、计数编码 Count Encoding
直接用该类别在整个数据集中出现的频次替换原始类别值。
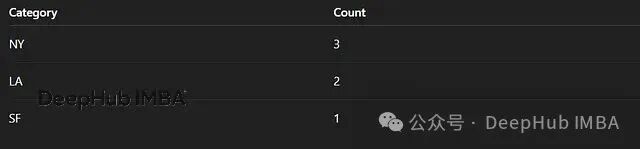
对高基数特征效果良好,计算快速且结果稳定。只要编码器仅在训练集上拟合,即可避免数据泄露。
encoder = ce.CountEncoder(cols=["city"])
X_trans = encoder.fit_transform(X)
11. 目标编码 Target Encoding
将每个类别替换为该类别下目标变量的平均值(回归问题)或正例概率(分类问题)。
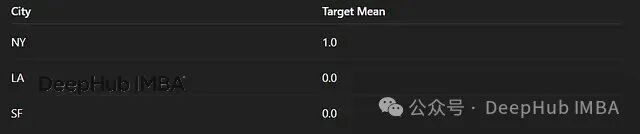
效果强大但易导致目标泄露,必须结合平滑处理或交叉验证技术来使用。
encoder = ce.TargetEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
12、CatBoost编码
目标编码的一种改进版本。在编码每一行数据时,仅使用该行之前(按时间或数据顺序)的观测值来计算目标统计量,极大地降低了数据泄露的风险。
这是目前最安全的目标编码方案之一,尤其适用于高基数特征和时间序列数据。
encoder = ce.CatBoostEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
13、留一法编码 Leave-One-Out Encoding
计算某个类别的目标统计量时,将当前行排除在外。它在保留目标编码信息量的同时,进一步减轻了过拟合风险。
encoder = ce.LeaveOneOutEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
14、M估计编码 M-Estimate Encoding
应用贝叶斯思想对目标编码进行平滑,使用全局平均值作为先验。
在处理高基数特征或目标变量噪声较大的场景下表现稳健。
encoder = ce.MEstimateEncoder(cols=["city"], m=5)
X_trans = encoder.fit_transform(X, y)
15、WOE证据权重编码
信用评分领域的经典方法,衡量某个类别对目标事件(如违约)的预测能力。
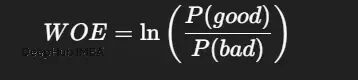
逻辑回归模型与WOE编码结合是经典范式,具有极强的可解释性。
encoder = ce.WOEEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
16、James-Stein编码
基于James-Stein估计量的收缩编码器。它通过向全局平均值收缩来减少方差,在处理分类变量的回归问题时效果显著。
encoder = ce.JamesSteinEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
17、GLMM编码
使用广义线性混合模型进行编码。特别适用于处理具有层次结构或组别效应的数据。
encoder = ce.GLMMEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
18、分位数编码 Quantile Encoding
不使用目标均值,而是使用目标变量在该类别下的特定分位数(如中位数)进行编码。
encoder = ce.QuantileEncoder(cols=["city"], quantile=0.5)
X_trans = encoder.fit_transform(X, y)
19、RankHot编码
独热编码的一种变体,其列的顺序按照类别频率排序。这种结构对树模型更为友好。
encoder = ce.RankHotEncoder(cols=["city"])
X_trans = encoder.fit_transform(X)
20、格雷编码 Gray Encoding
使用格雷码(相邻两个编码只有一位不同)来表示类别序数索引。
encoder = ce.GrayEncoder(cols=["city"])
X_trans = encoder.fit_transform(X)
如何选择合适的编码器
低基数特征(<10个类别):
- 通用选择:独热编码、二进制编码、序数编码。
- 统计模型:可考虑求和编码、Helmert编码、多项式编码。
中等基数特征(10-100个类别):
- 二进制编码、Base-N编码。
- CatBoost编码、带有平滑处理的M估计或目标编码。
高基数特征(100-50000个类别):
- 首选方案:CatBoost编码、留一法编码。
- 稳健方案:计数编码、M估计编码、使用交叉验证的目标编码。
- 内存敏感场景:哈希编码。
常见陷阱与规避方法
- 目标编码数据泄露:使用CatBoost编码、留一法编码或在交叉验证循环内进行目标编码来规避。
- 树模型对序数编码的误读:树模型可能将序数编码的整数视为连续变量,导致非最优分割。对于无序类别,考虑使用独热编码或目标编码。
- 独热编码维度爆炸:当类别数量巨大时,避免使用独热编码,转而采用二进制编码、Base-N编码或哈希编码。
- 稀有类别引入噪声:使用M估计编码、James-Stein编码或带有强平滑的目标编码来缓解稀有类别带来的噪声问题。
总结
分类变量编码是特征工程中一个至关重要且极具潜力的环节。scikit-learn 提供的基础编码器仅是入门工具,而 category_encoders 库则为我们打开了一扇大门,其中包含了统计编码、贝叶斯收缩编码、哈希编码以及各种对比编码等丰富的高级方法。熟练掌握并合理运用这些编码技术,能够有效提升机器学习模型的性能上限。
 发表于 2025-12-13 02:07:55
|
查看: 215|
回复: 0
发表于 2025-12-13 02:07:55
|
查看: 215|
回复: 0
