在李佳琦、罗永浩等头部主播的直播间,同时在线观众可达百万乃至千万级。海量的弹幕互动、高清视频流推送与瞬间爆发的秒杀请求,对后端系统构成了前所未有的超高并发挑战。为此,抖音构建了多层次、分布式的技术架构,综合运用长连接推送、CDN加速、消息队列解耦、限流熔断及缓存分片等多种策略,以保障服务的实时性与稳定性。本文将深入剖析抖音直播在各关键环节应对高并发的核心机制与架构设计。
1. 实时弹幕系统的高并发处理机制
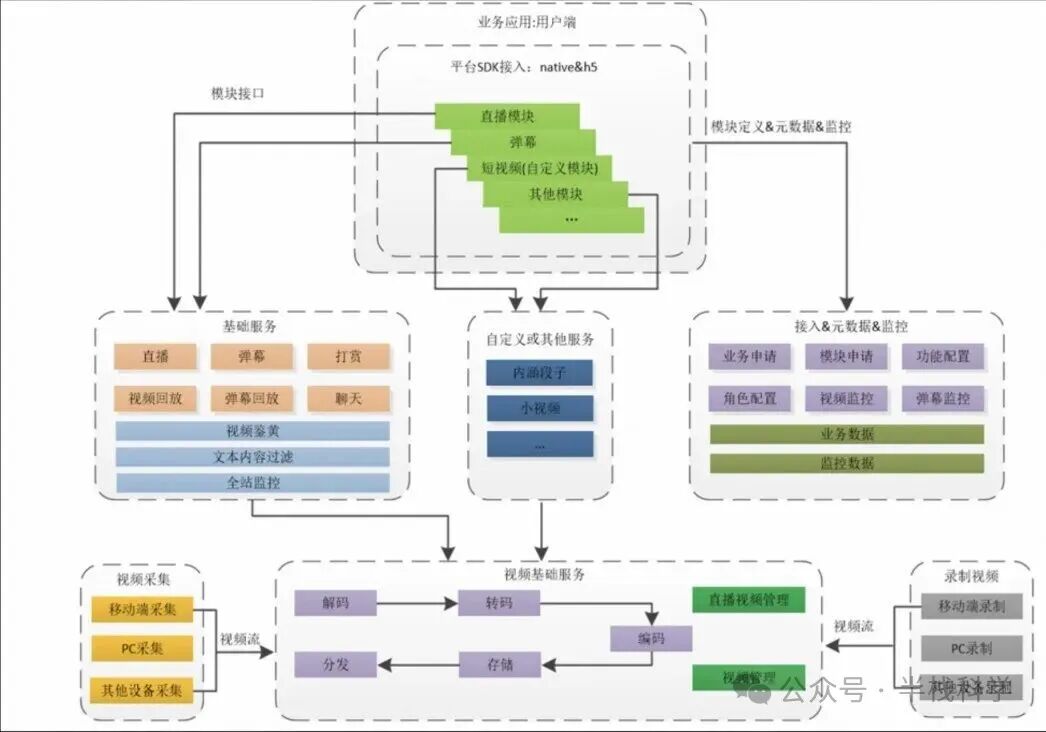
直播弹幕是用户互动的核心。为支撑百万级用户同时在线,抖音的弹幕系统采用了推送层与连接层解耦的设计。推送层负责维护用户与直播间的订阅关系并生成新消息通知,连接层则专职与客户端保持长连接并进行消息下发。
具体流程如下:当直播间A产生新弹幕时,推送层会根据订阅列表,找出所有在该直播间的用户所连接的服务器节点,并发出新消息通知。随后,各连接服务器节点从后端的消息存储(如Redis)中拉取该消息,并推送给相应用户。
若某个直播间的订阅用户过多,系统会自动将“通知+拉取”模型降级为纯广播模式:推送层直接向所有连接节点广播该直播间的新消息。这种订阅与广播相结合的混合模型,既保证了普通直播间消息的精准送达,又能应对头部主播间瞬时海量消息分发的效率需求。
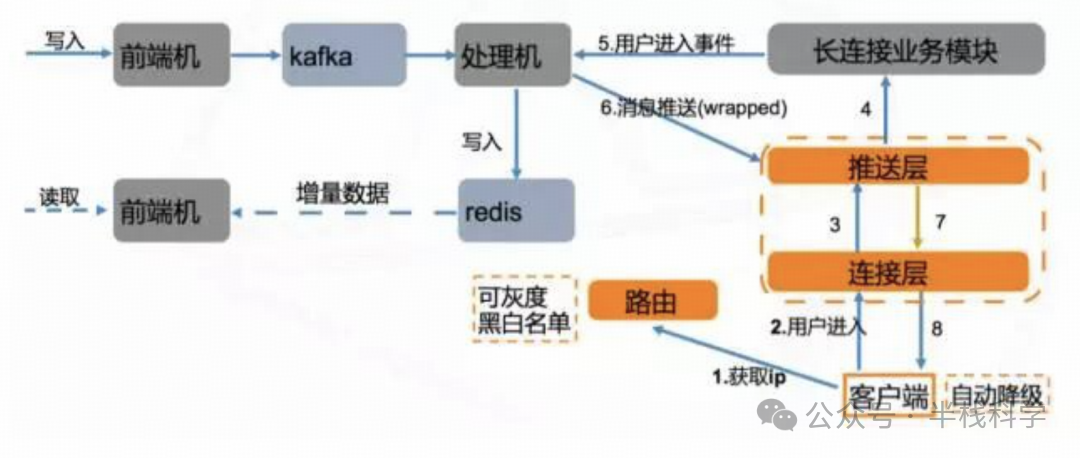
消息队列在此系统中扮演了至关重要的解耦与削峰角色。典型流程是:前端接入机收到客户端的弹幕发送请求后,将消息写入如Kafka等消息队列;后台的多个处理节点从队列消费消息,按直播间和消息类型归类,最后写入Redis缓存。客户端拉取弹幕列表时,直接查询Redis中对应直播间的最新消息即可。
这种设计通过消息队列吸收了瞬时高并发写入压力,实现了弹幕的写入与查询分离,客户端读操作不直接影响写流程,降低了读写冲突。需要注意的是,如果大量消息都集中写入同一Kafka分区,可能导致处理节点成为瓶颈。对此,可采用动态分区策略:在延迟较低时使用单分区保证顺序,延迟升高时切换到多分区并行处理以提升吞吐。
此外,系统还实施限流控制防止刷屏,并利用消息ID或内容哈希实现幂等去重,确保即使因网络重传导致消息重复,也只在客户端展示一次,避免热点数据膨胀。
综上,抖音弹幕系统融合了消息队列解耦、长连接订阅推送、广播降级、缓存优先读取以及限流去重等策略,实现了高吞吐与高可用。
2. 音视频低延迟传输架构设计
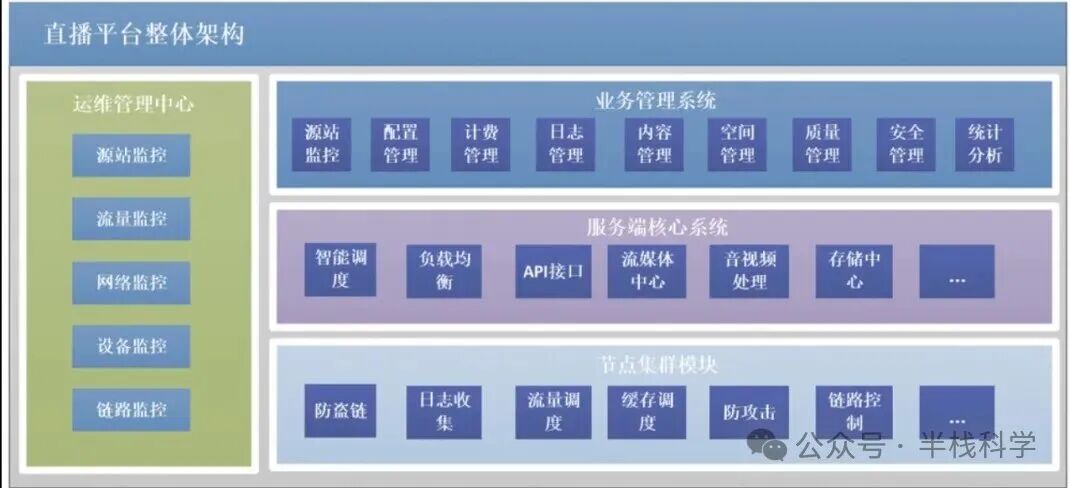
为保障直播的实时互动与流畅体验,抖音在音视频传输上采用了边缘接入与RTC协议栈优化的架构。主播端采集编码后的视频数据,首先被推送到离用户最近的CDN边缘节点(通过DNS解析定位)。边缘节点作为第一层接入点,负责将流媒体数据上行至中心节点,并同时进行下行缓存。

观众拉流时,优先从本地CDN边缘节点获取内容。若边缘节点已缓存该直播流,则直接回传;若未命中(例如观众首次进入),边缘节点会向上一级节点或源站请求数据。
这种多层CDN分发机制极大提升了带宽利用效率和就近访问速度,有效降低了网络延迟。但多层架构也面临节点故障风险:若某一层节点失效,可能影响上行链路。因此,抖音通常采用冗余部署与健康检测机制:由多个边缘节点共同承载流量,当一个节点故障时,流量可自动切换至其他健康节点。
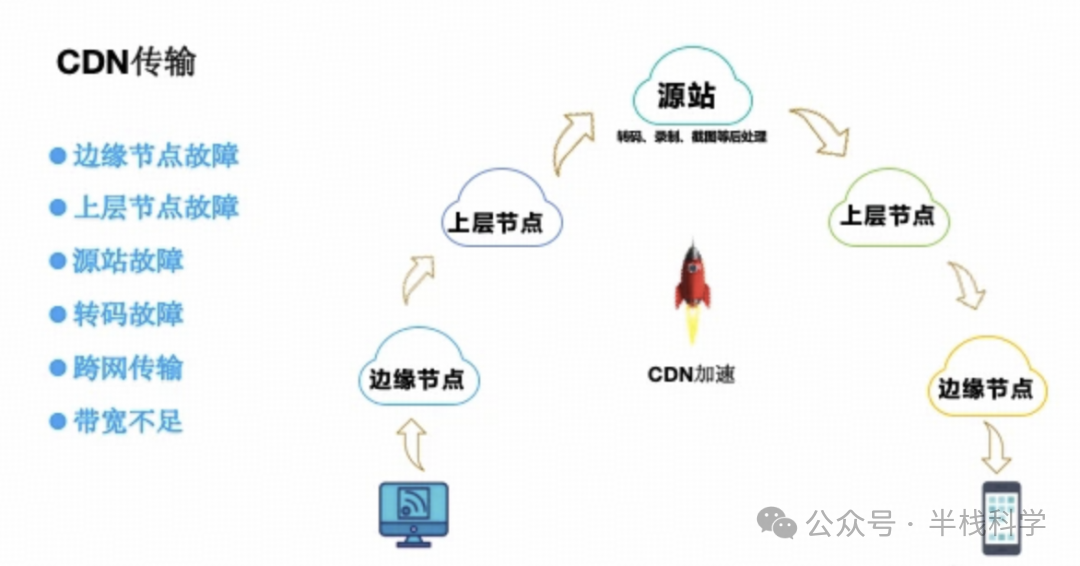
在协议层面,抖音广泛采用基于UDP的实时通信协议(如WebRTC/QUIC),相比传统的基于TCP的RTMP/HLS协议,在降低延迟方面优势显著。其自研的超低延迟RTM功能,通过UDP协议结合深度优化,在千万级并发下可实现毫秒级的端到端延迟。
在实际应用中,抖音电商直播常提供两种模式:标准低延迟FLV与超低延迟RTM。数据显示,FLV模式延迟可控制在2-3秒内,而RTM模式则能将延迟进一步降低至约1秒。
为实现这一目标,抖音在推流与CDN间减少了不必要的转码环节。条件允许时,主播流可“直连”推送到CDN源站,避免产生300毫秒到2秒的转码延迟。必须转码时,则优化编码参数、减少缓存帧数以平衡画质与延迟。多码率自适应也是关键手段:系统根据用户网络状况动态提供不同分辨率或帧率的流,确保弱网环境下仍能流畅播放。此外,先进的视频编码(H.264/H.265/VP9)与音频编码(AAC/Opus)格式,配合黑帧压缩等技术,进一步提升了带宽利用率。
3. 商品秒杀与订单系统的并发控制策略
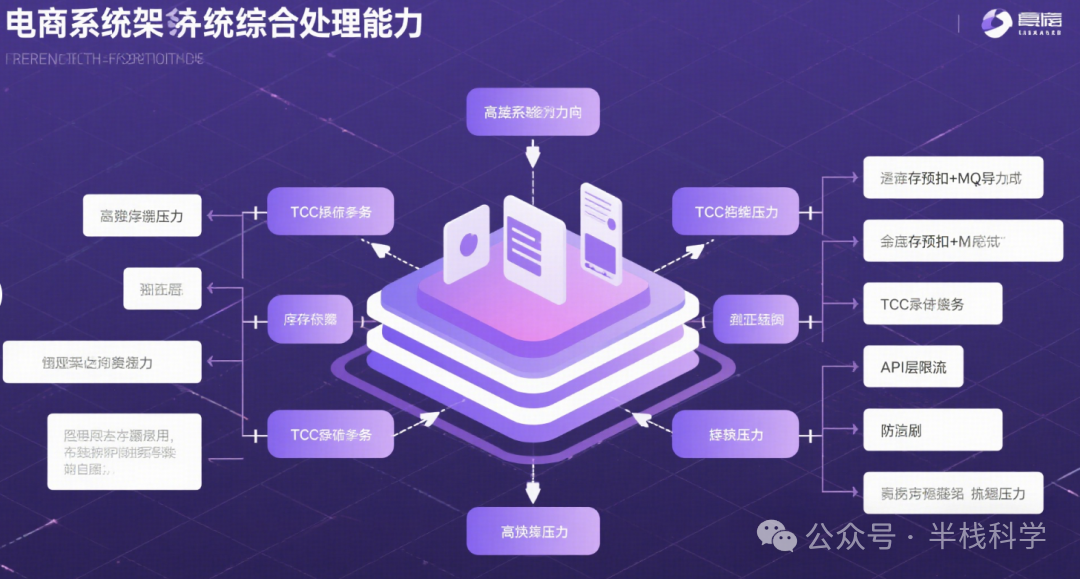
面对直播带货中瞬间爆发的海量下单请求,抖音采用预扣库存+异步落库的核心策略来保证库存不超卖。
具体而言,秒杀开始时,前端接口首先在Redis等缓存中预扣减库存。若扣减成功,立即向用户返回“抢购成功”信号;若库存不足,则提示失败。成功预扣的订单信息会被放入消息队列,由后台订单服务异步消费并创建正式订单。这种异步处理方式将高并发的抢购请求与相对复杂的订单创建过程解耦,实现了请求的快速响应与流量削峰。若订单最终超时未支付,系统会有定时任务执行库存回滚。
为保证在极高并发下的事务一致性,抖音电商引入了TCC(Try-Confirm-Cancel)事务模式。将下单操作拆分为“尝试预留资源(Try)”、“确认提交(Confirm)”和“取消回滚(Cancel)”三个阶段。即使在并发过程中出现偶发超时或故障,Cancel阶段也能确保已预留的库存被正确释放。
此外,秒杀接口层实施了严格的限流削峰与防刷保障。入口网关使用令牌桶或漏桶算法进行全局QPS限制。前端页面增加滑动验证、倒计时按钮等防重复点击策略,请求中携带防重放签名。对于预估流量巨大的活动,会采用灰度发布、请求随机延迟等逐步放量策略。同时,熔断机制会在下游服务异常时快速熔断,给予系统恢复时间。
4. 用户接入层的限流与容灾方案
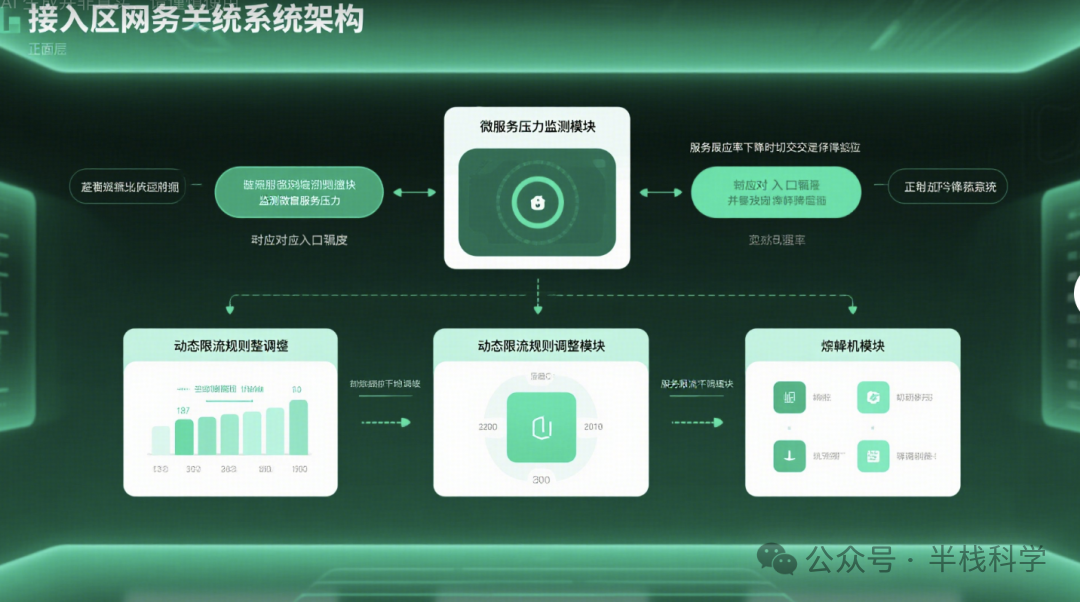
为应对海量用户接入,抖音在网关层部署了高性能网关,负责流量调度、鉴权与保护。核心策略包括全局与单用户限流:系统设置全站QPS阈值,超过则触发熔断或降级;同时对单个用户或IP实施频率限制(如每秒最大请求数),防止恶意行为。这通常基于漏桶或令牌桶算法实现。
抖音的限流规则是动态的。当监控到某个微服务响应时间飙升或错误率增加时,系统会自动调低该服务对应接口的限流阈值,或触发流量降级。结合熔断机制(如Sentinel),当某个服务的失败率达到阈值时,网关会暂时切断对其的调用,直接返回降级响应(如“系统繁忙”),避免故障扩散引发雪崩。
“冷静机制”也是重要的容灾手段。当系统压力过大时,会对部分用户请求返回一个重试等待时间(如“请3秒后重试”),或将其置于队列中延迟处理。这为系统争取了宝贵的缓解时间窗口,在秒杀、抢票等场景下效果显著。此外,网关层还运用黑白名单技术,保障内部核心用户的访问,同时阻断异常IP和爬虫请求。
5. 分布式数据库与多级缓存优化方案
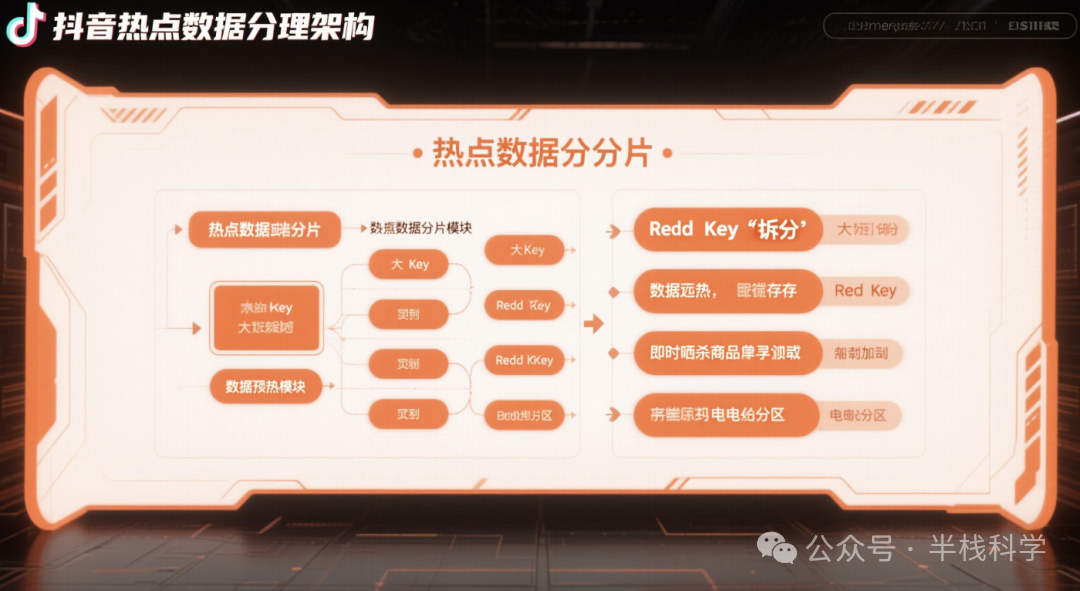
为满足海量数据存储与高速访问需求,抖音后端采用了分布式数据库与多级缓存结合的架构。
在数据库层面,对于需要高可用、最终一致性的场景,会使用如Apache Cassandra这类分布式NoSQL数据库,其去中心化的架构支持全球范围的数据复制,容忍节点或机房故障。对于强一致性要求较高的关系型数据(如用户关系、商品信息),则采用分库分表的MySQL集群或分布式数据库如TiDB。
缓存体系构建了多层次防线。首先,业务服务内部使用本地缓存(如Caffeine)存储极热数据,实现纳秒级访问。其次,在服务集群前部署Redis集群作为分布式共享缓存层。用户数据、商品详情等查询请求优先访问Redis,未命中时才查询数据库,极大减轻了数据库压力。针对可能出现的“热点Key”问题,抖音采用数据分片与预热策略,例如将一个热门商品的库存信息拆分到多个Redis Key中,分散到不同实例,或在活动开始前提前将数据加载至缓存。
此外,CDN缓存、应用层缓存等共同构成了完整的多级缓存体系。例如,弹幕消息的最新列表可以缓存在Redis的有序集合中,仅保留最近的几百条。通过读写分离与多级缓存,系统能够从容应对亿级流量的数据访问。
6. 服务容器化部署与自动扩缩容能力
抖音后端服务全面拥抱云原生,实现了高度的容器化。字节跳动内部构建了统一的容器云平台,用于管理所有微服务的生命周期。
每个服务组件(弹幕推送、流媒体处理、订单服务等)都被打包为独立的容器,部署在基于Kubernetes的集群上。借助Kubernetes的Horizontal Pod Autoscaler (HPA),平台可以根据CPU/内存使用率或自定义的业务指标(如QPS)实现自动弹性扩缩容。例如,在大型直播活动开始前,系统可依据历史数据预测流量,提前扩容相关服务实例;在直播过程中实时监测流量,动态增加或减少Pod副本;在流量低谷期则自动缩容以节约资源。
为了提升整体可用性,系统支持多集群与跨机房部署。即使单个集群或机房发生故障,业务Pod也能在其他可用区的节点上快速重建并接管流量。通过微服务拆分、容器化编排与智能弹性伸缩,抖音直播系统具备了快速响应流量变化的能力,确保在多云混合环境下的高可用与高弹性。
总结
综上所述,抖音直播通过分层解耦、异步削峰、链路冗余与智能弹性等综合策略,成功应对了电商场景下的千万级并发挑战。从实时弹幕推送、超低延迟视频分发,到秒杀订单的精准控制,再到接入层的立体防护与数据层的缓存优化,每一环节都经过精心设计与持续优化。正是这套完整且高效的技术体系,支撑了抖音在顶级流量冲击下依然稳定、流畅的用户体验。
 发表于 2025-12-13 02:22:01
|
查看: 261|
回复: 0
发表于 2025-12-13 02:22:01
|
查看: 261|
回复: 0
