当地时间5月14日,Anthropic以中美AI竞争为由发布长文,呼吁进一步收紧芯片出口限制。同一天稍早,路透社报道美国已批准约10家中国公司购买英伟达专为中国市场定制的H200芯片,涉及阿里、腾讯、字节、京东等,但许可尚未转为实际交付。Anthropic直言,训练前沿AI模型最关键的资源就是先进芯片——算力。美国目前的优势建立在NVIDIA、AMD、TSMC等“民主国家产业链”之上,但如果管制不加码,美国可能在2028年前丧失主导权,中国AI实验室的模型能力或许只差美国几个月。
Anthropic还援引数据称,按总处理性能计,华为2026年的算力产出仅相当于英伟达的4%,2027年更降至2%。在其框架中,中美AI竞争被拆为四条线:智能(谁能开发最强模型)、国内采用(谁更有效整合AI)、全球分发(谁能部署全球AI技术栈)和韧性(谁能在AI转型中维持稳定)。模型智能被视为关键支柱,也正是Anthropic收入的基石。它认为中国AI实验室仍能紧随美国,主要依赖世界级人才、先进算力,以及通过大规模“蒸馏攻击”窃取前沿模型能力。Anthropic由此提议将这类攻击非法化、加强情报共享,并推动美国“可信AI技术栈”出口以抢占全球南方市场。一边阻截芯片外流,Anthropic一边却斥千亿美元解算力之渴,同时频繁调价把压力转嫁给用户。
连连调价,开发者炸锅了
算力紧张之下,Anthropic再度调整定价。从6月15日起,程序化Claude使用量将与标准聊天订阅额度分离。开发者通过Agent SDK、GitHub Actions或OpenClaw等第三方智能体框架调用Claude时,不再简单计入原有套餐,而是进入独立月度积分系统,依API式计费。这意味着,许多用Claude Pro或Max套餐低成本跑自动化、智能体脚本、CI流水线和长期编码代理的模式,将面临重新定价。月度积分额度与订阅档位挂钩:Pro用户每月获20美元积分,Max 5x用户100美元,Max 20x用户200美元。
此前,交互聊天与程序化调用共用一个额度池,Claude一度成为智能体开发者的高性价比之选。但今日4月,Anthropic已在X上释放信号,称“不再覆盖OpenClaw等第三方工具使用量”,理由正是算力容量受限。新规下,开发者要么买额外用量包,要么转向API计费。Anthropic CFO Krishna Rao在采访中辩解:“我们的定价一直稳定,很少改价。最大一次调整是Opus 4.5发布时降价,因为Opus能力虽强但用量不匹配,客户总想塞进Sonnet里。模型效率提升后,我们降价让客户更容易用上。”他提到“杰文斯悖论”:降价反而让使用量远超预期,等客户真正融入Opus,再升级到Opus 4.6就无需调价。
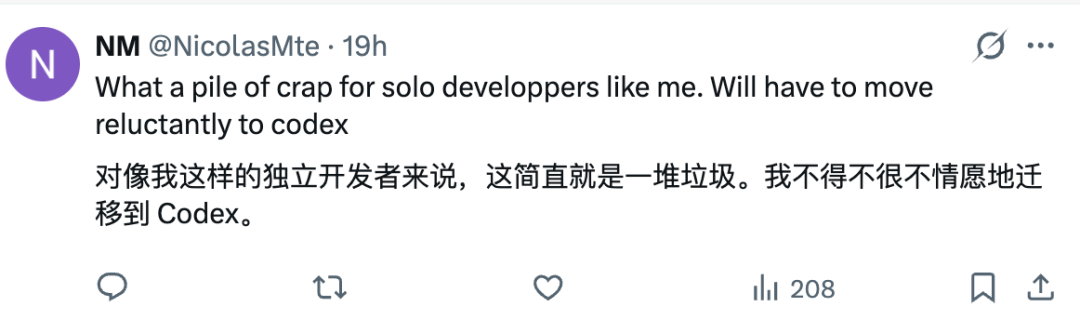
然而,用户对反复调价极为敏感抵触。高级数据科学家Yadesh Salvi在X上批评,提供的月度额度“连一天认真工作都撑不住”,Claude Agent SDK和 claude -p 等高频功能被压缩。Broadcom高级站点可靠性工程师Advait Patel也指出,固定价格套餐的副业项目虽能尝鲜,但一旦智能体频繁运行,就必然进入按量计费模式。重度智能体用户消耗的算力远超20或100美元订阅支撑范围,能跑的自动化任务减少,保持强度就得额外付费。企业同样头疼:过去依赖Claude订阅运行无人值守的CI流水线或长时间编码智能体,新规让使用量更紧密绑定token消耗,预算预测愈发不确定。积分按用户分配,无法团队共享,失控的智能体或一个失当提示词都可能在瞬间烧光额度。
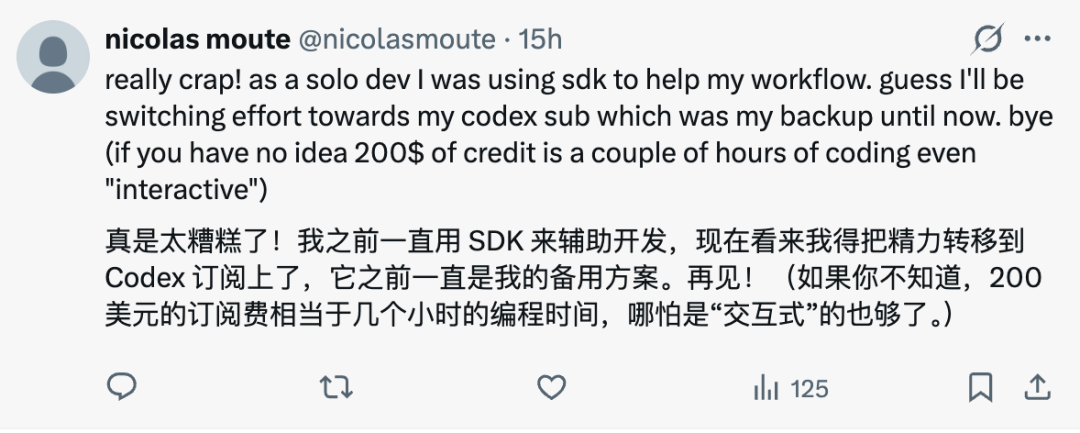
高额费用甚至波及微软。据外媒报道,微软已逐步取消数千名内部开发者的Claude Code授权,转而押注自家的GitHub Copilot CLI。这项过去半年备受欢迎的工具,因接近财年结束被视作省钱的简易切口。近几个月,微软员工更偏爱Claude Code,但过渡到Copilot CLI并非易事,公司一直鼓励无编程经验的员工用它快速构建原型。如今,GitHub团队面临改进压力,这也给Codex、Copilot等竞品带来机会。
“算力是我们业务的生命线”
拥有更多算力是Anthropic最直接的出路。Krishna在播客中坦言:“采购的算力就是整个业务的生命线。”公司近期大规模行动:独家租用SpaceX Colossus 1超算中心;与AWS长期合作,锁定5GW Trainium算力,10年投入超1000亿美元;签约Google与Broadcom的下一代TPU长单,3.5GW算力2027年起交付;去年还宣布投入500亿美元自建美国AI基础设施。Krishna明确表示,公司内部未看到scaling laws放缓迹象,模型开发各阶段都印证这点,客户痛点也会成为训练目标,形成研发循环。Anthropic创始人不乏scaling laws论文作者,但仍带怀疑精神审视,目前趋势未减。
克制采购,异构算力快速消化
算力采购是Anthropic最关键也最难的决策,多则成本拖垮公司,少则难以服务客户和维持前沿。Krishna介绍,公司从需求出发建模型预测,尽量保持合同与使用方式的灵活性。他现任CFO仍将30%到40%时间花在算力上。Anthropic不押注单一芯片,而是同时使用Amazon Trainium、Google TPU和Nvidia GPU,不同场景灵活调度。这并非一蹴而就,从早期TPU 3e遭质疑到搭建编排层,公司花多年优化调度。他们贴近底层硬件做优化、与Annapurna Labs团队协作,甚至影响芯片路线图,致力于让每美元算力产出最高价值。如今,Anthropic已能快速部署任何类型算力,若获得更多即可迅速分配至模型开发、内部使用和客户服务。
性价比决定算力分配
Anthropic评估算力有一套动s态流程。以与SpaceX在Memphis的Colossus合作为例,近期算力能否有效部署是关键,公司考量价格、期限、位置和类型。这套流程也用于长期交易,例如与Google的5GW TPU合作、与Amazon高达5GW的Trainium“算力蛋糕”。不同芯片在不同时间启动,Anthropic比较性价比、交付时间和业务角色,从每token成本到吞吐量。算力团队主导讨论,全公司配合判断需求,如CPU用于强化学习、前沿算力运行最快模型。
模型开发有保底,内部也要喂饱
Anthropic追求的状态是:维持前沿地位、服务客户,并以足够内部算力加速员工工作。公司文化强调协作,算力分配讨论非零和博弈。但模型开发设硬性底线,即便让服务客户更难也坚持投入,因前沿智能回报极高,尤其在企业领域。内部团队也分走可观算力——若禁用内部模型,释放的算力可支撑数十亿美元收入。实际上,Anthropic 90%以上代码由Claude Code编写,许多Claude Code自身也用Claude Code辅助完成。这让模型成为构建下一代模型的放大器。
Krishna强调,人才密度比规模更重要。Anthropic不太分“闭源”“开源”,只按“前沿”与“非前沿”区分。公司持续围绕前沿模型加大投入,既投算力也投能利用算力的人才。一月份发布三十个产品和功能,产品节奏加快,核心仍是研究实验室,由最优秀的人才设定方向,再由模型放大其能力。
算力投入不是单项成本
Anthropic看算力回报不盯单项支出,而是整池回报:推理直接支撑今日收入,模型开发打开未来市场,内部提效加速产品推出。第一季度收入激增并非突然上线新算力,而是按早前节奏逐步落地。Krishna认为,把服务每位客户视为“新增变量成本”不合适,算力同时支撑客户服务、模型研发和内部提效。公司视现有算力池为关键约束,决定短期服务量、长期能力扩展和收入潜力。Anthropic是唯一同时出现在三大云且使用三种芯片平台的实验室,与Amazon的Annapurna Labs深度绑定,合作涵盖芯片开发、容量规划、服务交付和分发,远超普通采购。
 发表于 2026-5-17 04:41:53
|
查看: 115|
回复: 0
发表于 2026-5-17 04:41:53
|
查看: 115|
回复: 0
