在实际的交易中,每一毫秒都至关重要。直接使用传统的 LLM 智能体进行交易,当市场出现剧烈波动,它可能还在忙着解析复杂的 JSON 字符串、在不同角色间进行多轮对话,或者等待云端 API 的响应。当大模型终于给出交易决策时,滑点已经吃掉了全部的利润空间。这种试图模仿人类“角色扮演”的智能体设计,不仅引入了滞后的舆情噪音,也违背了量化交易的核心要素:速度、精度与客观理性。
针对实盘交易中大模型高延迟与参数漂移的痛点,ICLR 2026 收录的一篇论文提出了 TiMi (Trade in Minutes) 系统。该系统提供了一条切实可行的工业落地路径:离线利用大模型的逻辑推理与代码生成能力构建并调优交易机器人,在线则采用轻量、无状态代码在 CPU 上进行毫秒级执行。
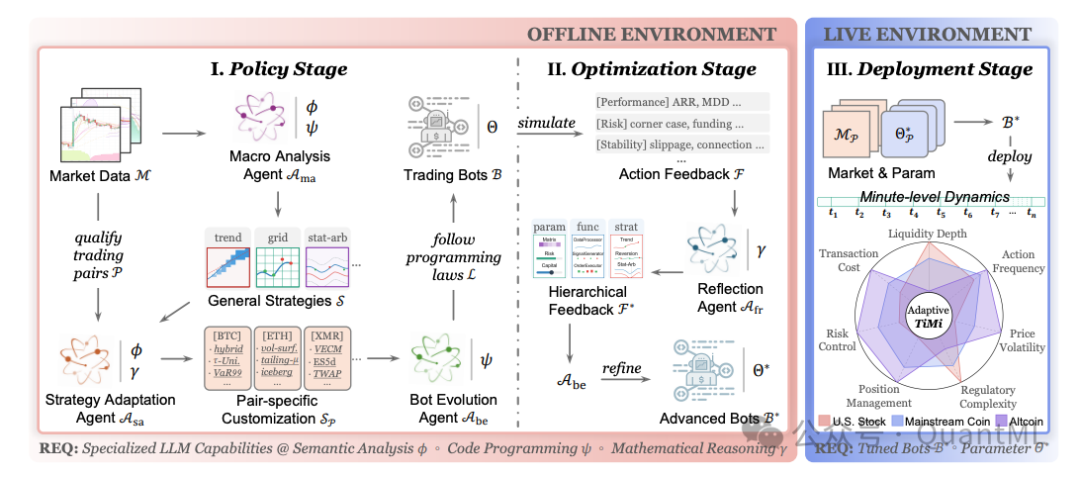
它巧妙地避开了在实盘执行阶段直接调用大模型 API 的高延迟瓶颈,提供了一种从“宏观分析 -> 策略微调 -> 自动代码生成 -> 约束条件数学求解”的务实落地框架。
1. 问题
在传统的金融 AI 研究中,强化学习虽然能在特定回测周期内获得不错的收益,但在面临市场机制漂移(Regime Shift)或“黑天鹅”事件时极易崩溃。而现有的金融智能体系统虽然具备更强的语义理解和逻辑推理能力,却被以下三个真实量化问题限制了上限:
- 实盘部署的效率极低(System Deployment Efficiency):多智能体之间冗长的推理、工具调用和多轮对话,带来了高昂的计算开销。在高波动市场中,这种长延迟会直接转化为灾难性的执行滑点和机会成本。
- 拟人化偏见与低信噪比(Anthropomorphic Bias & Low SNR):许多智能体试图模仿人类交易员的心理,这反而引入了非理性的决策干扰。同时,过于依赖新闻或社交舆情等边缘非结构化数据,由于时滞和伪信号泛滥,容易让模型在关键时刻做出错误判断。
- 策略缺乏机械理性(Lack of Mechanical Rationality):传统智能体客观上无法做到精密执行,它们擅长文字层面的分析,但在策略代码编写的严谨度、参数边界的数学推导上,缺乏像传统量化策略那样的精准控制。
TiMi 的核心解决思路非常清晰:将复杂的逻辑推理与时间敏感的执行逻辑在空间和时间上进行彻底解耦。
2. TiMi 核心方法
TiMi 整个框架由 策略阶段(Policy Stage)、优化阶段(Optimization Stage) 和 部署阶段(Deployment Stage) 三部分组成。
2.1 从宏观到微观
系统首先通过两个专门的智能体来构建交易策略:
-
宏观分析智能体 ($A_{ma}$):该智能体基于 DeepSeek-V3,主要负责从宏观技术指标中识别周期性市场模式,并输出通用策略集 $S$。其工作过程可以形式化为:
$A_{ma}: \{M, \tau, I_T\} \xrightarrow{\phi, \psi} S$
其中 $M$ 为市场数据,$\tau$ 为时间窗口,$I_T$ 为技术指标,$\phi$ 为语义分析,$\psi$ 为提取有用特征的程序代码。
-
策略适配智能体 ($A_{sa}$):通用策略难以直接应用到所有品种上。$A_{sa}$ 针对具体的交易对 $p$(如 BTC 或山寨币)进行微调,通过语义分析 $\phi$ 和数学推理 $\gamma$,生成特定资产的候选策略规则 $S_p$ 和初始参数 $\theta_p$。这一步涵盖了策略优先级的排列以及基于资产历史波动的参数微调。
2.2 自动代码生成与“编程三定律”
在确定了策略逻辑后,机器人进化智能体 ($A_{be}$)(采用 Qwen2.5-Coder-32B)负责将策略转换为可执行的 Python 交易机器人 $B$。为了保证生成的代码具有极高的模块化和可维护性,便于后续的自动化调参,论文提出了三条编程定律(Programming Laws):
- 功能内聚定律(Functional Cohesion Law):每个功能模块(如信号计算、仓位控制、订单执行)必须且仅负责单一职责。
- 单向依赖定律(Unidirectional Dependency Law):依赖关系必须严格从高层向底层流动(策略层 $\rightarrow$ 功能层 $\rightarrow$ 参数层),严禁循环依赖。
- 参数外部化定律(Parameter Externalization Law):所有可调的阈值、参数必须从执行代码中剥离,集中在独立的配置文件中进行管理。
2.3 基于数学反思的闭环参数优化
这是 TiMi 系统中我认为最具量化专业度、最值得借鉴的设计。当生成的交易机器人在模拟或历史市场中运行后,会收集包含收益、最大回撤(MDD)、风险边界事件等在内的反馈数据 $F$。
反馈反思智能体 ($A_{fr}$)(采用专注于推理的 DeepSeek-R1)并不会像常规智能体那样仅给出一堆泛泛的文字修改建议,实际是将观察到的交易逻辑漏洞转化为数学约束问题(如线性规划):
其中 $\mathbf{A}_f$ 和 $\mathbf{b}_f$ 是从风险事件 $\mathcal{E}$ 中推导出的约束矩阵和阈值向量。
论文在附录中给出了三个极为真实的量化反思求解案例,展现了这种“数学理性”的工程落地:
-
案例 1:高波动下的仓位规模控制(Case #1: Position Size Control)
- 病态交易表现:机器人在 OM/USDT 的暴跌行情中执行了过于密集的买入订单,导致仓位过载并出现严重浮亏。
- 数学约束转化:$A_{fr}$ 分析回测日志后,设定总持仓规模不能超过最大限制 $C_{max}$。由于单次订单量 $q_i = f(w_i, P_i)$(其中 $w_i$ 为分配资金,$P_i$ 为数量控制矩阵),由此推导出参数 $w_i$ 的线性不等式约束:$\sum_i q_i \cdot p_i \le C_{max}$,以此约束限制机器人在高波动下无限抄底。
-
案例 2:暴涨行情下的挂单边界校准(Case #2: Order Boundary Calibration)
- 病态交易表现:在 DOGE 暴涨行情中,机器人的空头网格(Sell Orders)最高档位过早被触发,导致在价格继续飙升时空头仓位被动迅速积累,发生严重亏损。
- 数学约束转化:$A_{fr}$ 引入当前绝对峰值价格 $P_{peak}$ 与起步价格 $P_{start}$,对网格最大价格指数参数 $K_{max}$ 进行对数约束推导,建立安全下限:$K_{max} \ge \frac{P_{peak}}{P_{start}}$,以此强制提高网格的覆盖宽度,避免被单边行情瞬间“打穿”。
-
案例 3:趋势行情下的自适应止盈(Case #3: Adaptive Profit-Taking)
- 病态交易表现:机器人在美股纳指期货(NQ)的持续单边多头行情中,由于止盈设置过于保守,过早平仓,大幅输给了 Buy-and-Hold 表现。
- 数学约束转化:$A_{fr}$ 分析趋势指标后,设定第一档止盈价格 $TP_{1}$ 必须能够覆盖趋势行情的平均涨幅 $\mu_{trend}$,进而推导出止盈参数 $TP$ 的下界:$TP_{1} \ge \mu_{trend}$,在强趋势行情中自适应拓宽止盈空间。
2.4 部署阶段:无模型运行(Stateless & Light CPU Deployment)
当优化迭代完成并产出最佳参数 $\sigma^*$ 后,生成的交易机器人会被部署到实盘环境中。
需要注意的是,实盘部署环境不需要配备昂贵的 GPU 显卡,也完全不需要在每次分钟级调仓时调用大模型 API。在线运行的实际是纯粹由智能体离线“编译”生成的 Python 策略代码(主要是一套经过优化的网格/限价单动态执行逻辑)。
通过这种离线策略生成与在线代码执行的彻底分离,TiMi 实盘中的内部逻辑计算延迟被压缩到了 5ms 以内,加上外围的市场数据获取和交易接口往返(RTT),整体延迟也仅为 137ms。这彻底解决了传统 LLM 智能体动辄数秒的延迟问题。
3. 实盘
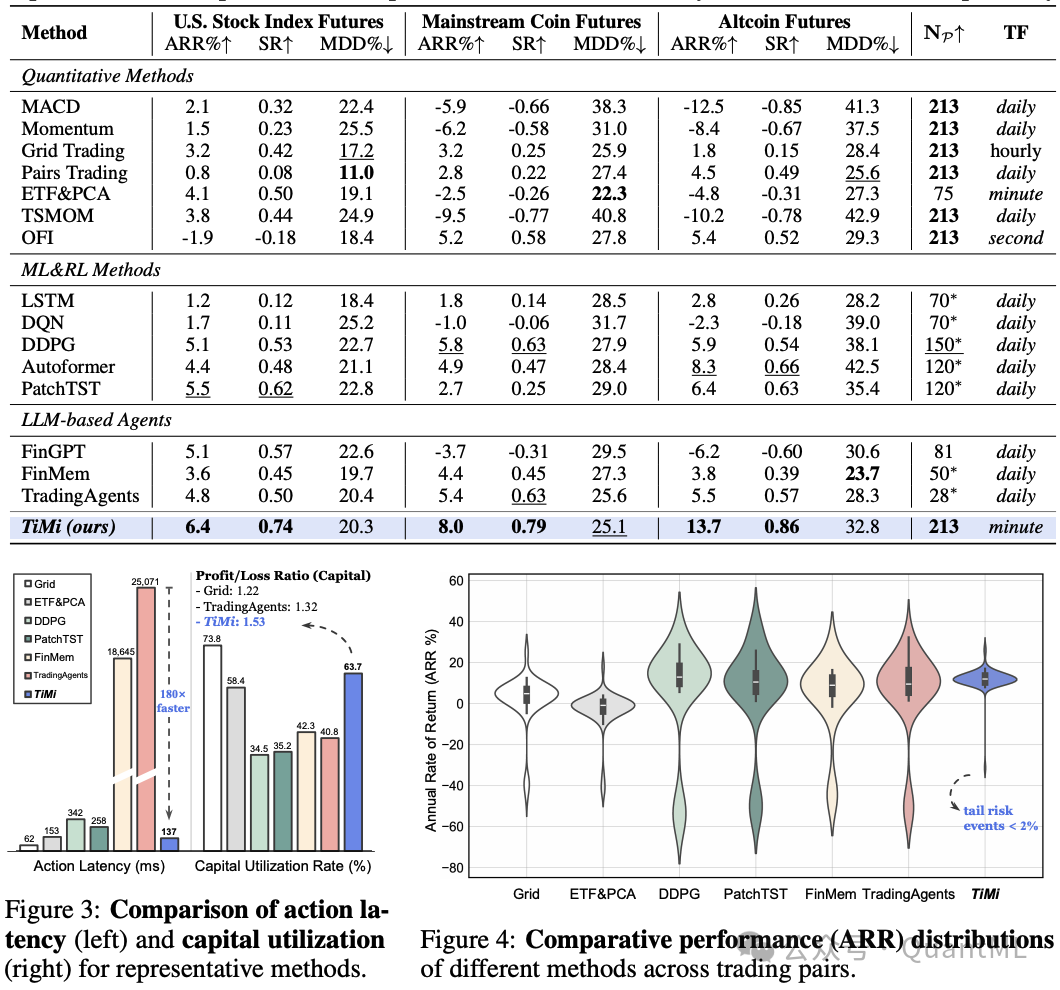
论文在 2024 年的历史数据上进行了离线回测,并在 2025 年 1 月至 4 月期间在美股指数期货、主流加密货币以及山寨币市场开展了实盘交易(Live Trading)。其对比的 Baseline 覆盖了三大阵营:传统量化方法、深度学习与强化学习模型,以及已有的 LLM 智能体。
3.1 离线回测表现
在 2024 年的历史回测中,TiMi 在不同市场的表现如下:
- 美股指数期货:ARR(年化收益率)为 8.9%,夏普比率(SR)为 0.84,最大回撤(MDD)为 10.5%。作为对比,网格交易在此市场中 ARR 为 -2.8%。
- 主流加密货币:ARR 达到 16.5%,SR 为 1.25,MDD 为 12.1%。
- 山寨币期货:ARR 为 23.7%,SR 为 1.27,MDD 为 26.0%。
3.2 实盘运行表现
在 2025 年 1 月至 4 月的实盘测试中,受到市场机制变化和交易摩擦的影响,所有策略的收益表现相比历史回测均有不同程度的下滑,但 TiMi 依然保持了相对稳健的表现:
- 美股期货实盘:ARR 为 6.4%,SR 为 0.74,MDD 为 20.3%。
- 主流币实盘:ARR 为 8.0%,SR 为 0.79,MDD 为 25.1%。
- 山寨币实盘:ARR 为 13.7%,SR 为 0.86,MDD 为 32.8%。
虽然实盘收益有所回落,但在波动极大的山寨币实盘中,TiMi 的夏普比率依然能够维持在 0.86,而作为对比的强化学习策略 DDPG 虽取得了 5.9% 的年化收益,其回撤却高达 38.1%,夏普比率仅为 0.54。这表明了基于反馈约束优化的参数边界在风控上确实起到了一定的屏障作用。
3.3 实盘执行效率与资金利用率
得益于离线编译的优势,TiMi 在执行效率和资金利用上具有明显长处:
- 单次动作延迟:TiMi 的推理执行延迟仅为 137ms(与传统定量方法的数十毫秒处于同一量级),而传统的在线多智能体方法(如 TradingAgents)由于需要实时调用模型,单次决策延迟高达 25071ms,慢了 180 倍以上。
- 资金利用率(Capital Utilization Rate):TiMi 在实盘中达到了 63.7%,显著高于网格交易(15.3%)和 TradingAgents(40.8%)。
- 盈亏比(Profit/Loss Ratio):每单位投资资本产生的盈亏比,TiMi 为 1.53,优于 Grid 的 1.22 和 TradingAgents 的 1.32。
4. 结论
TiMi 摒弃了传统的Agent设计,转而采用一种机械理性的闭环架构,为 LLM 智能体在量化领域的落地指明了一条务实的路径。它通过将复杂的推理过程编译成离线代码,完美地绕过了在线实时推理的延迟深渊。
本文由云栈社区编辑整理,更多量化交易与AI前沿内容,欢迎访问交流。
 发表于 2026-5-23 03:57:36
|
查看: 200|
回复: 0
发表于 2026-5-23 03:57:36
|
查看: 200|
回复: 0
