
距离上一篇桌面版上线已经有一阵子了。这只小怪兽在我的笔记本和台式机之间跑得很顺畅,但一个场景始终让我觉得别扭:不带电脑时,我怎么接着和它聊?
通勤、排队、夜里躺床上、出门买菜——这些时刻我想问“昨天那个事我们聊到哪了”、“帮我搜一下 xxx”、“记一下我刚想到的”,但打开电脑显得过于隆重。手机里能装的 AI 客户端,又都和 Hermes 没关系。它们不知道我的记忆宫殿,不认识我,也读不到我之前的会话。对我来说,它们一点都不了解我。我还是希望和我的 mini Hermes 持续对话,让这个已经很了解我的家伙来解决问题。
所以这次做了第三张脸:把 Hermes 接到微信。
不是套壳,不是另一个 chatbot。它是同一个引擎、同一个记忆库、同一组技能、同一份 ~/.small-rust-hermes/ 的延伸——你在 CLI 里养出来的那个“懂你的 Agent”,现在直接住进你微信的好友列表里。
~/.small-rust-hermes/
├── config.toml # 同一份配置
├── mcp.json # 同一份 MCP
├── skills/ # 同一组技能
├── memories/ # 同一组记忆(记忆宫殿)
├── sessions/
│ ├── 2026-05-23-xxxx.jsonl # CLI / GUI 写进来的
│ └── wechat/
│ └── {user_id}/
│ └── 2026-05-24-xxxx.jsonl # 微信侧写进来的
└── wechat.toml # ← 这次新增:微信登录态(mode 600)
▲ ▲ ▲
│ │ │
hermes-cli hermes-gui hermes wechat
(命令行) (桌面端) (微信桥)
│ │ │
└────────────────┼────────────────┘
│
同一个引擎
hermes-core / -turn / -llm /
-mcp / -store / -skills /
-memory / -reflect / -tools /
-weixin ← 这次的新成员
11 个 crate 变成 12 个。CLI 是第一张脸,GUI 是第二张脸,微信桥是第三张脸。三张脸,一颗心。
给第一次听说 Small Hermes 的朋友
不是所有读者都看过前面五篇,所以把核心价值快速过一遍。
Small Hermes 是一个用纯 Rust 写的、能自我进化的 AI Agent。
它的核心循环和所有 Agent 一样朴素:
用户输入 → LLM 推理 → 工具调用 → 结果反馈 → LLM 继续推理 → ... → 输出
但它在三件事上和市面上 99% 的 Agent 框架不一样:
1. 它是 Rust 写的,所以是真的“轻”。 这一条不是炫技,而是直接决定使用体验的硬指标:
| 指标 |
Small Hermes (Rust) |
主流 Python / JS Agent 框架 |
| 单文件二进制 |
~25 MB(含所有依赖) |
100+ MB venv / node_modules |
| 冷启动到首次响应 |
< 2 秒 |
5-15 秒 |
| 常驻内存 |
~15 MB |
200-500 MB |
| 微信桥每条消息开销 |
< 50ms(不含 LLM) |
数百 ms |
Rust 不只是让它跑得快。更关键的是,它让 Agent 可以在你笔记本背景里常驻一整天,听微信、刷长轮询、监控反思队列,而你几乎察觉不到它的存在。一个吃 500 MB 的 Electron 或 Python 进程,是不可能做到这件事的。
2. 它精打细算每一个 token。 Agent 最贵的不是 CPU,是 LLM API。Small Hermes 在 token 经济性上下了几道硬功夫:
- 微反思限定 500 tokens in / 200 tokens out,而且采用启发式触发——大部分对话不会反思,只有满足条件的轮次才花这笔钱。
- 上下文压缩是 LLM 驱动的有损摘要,目标为“原长度的 1/5”,而非粗暴截断。
- System prompt 缓存友好:基础部分对每个 turn 字节级稳定,可以命中 Anthropic prompt cache,拿到 90% 的折扣。
- 记忆按相关度注入,不是全量灌:BM25 + effectiveness factor 排序后选 top-N,不让宫殿里几十条记忆把上下文撑爆。
- 工具定义按需暴露:微信桥的工具白名单只有 9 个,CLI 里几十个工具的 schema 不会被无关上下文带进来。
结果:一次典型的“问个问题 + 一两次工具调用”的对话,端到端 token 消耗在 3K~8K 之间。同样的工作量,用一个不精细的 framework 跑下来,10 倍起步。省下来的不只是钱,更是响应延迟。
3. 它真的会变聪明。 每次对话结束(或者满足启发式条件的微反思),系统会让 LLM 复盘对话:有没有值得记住的事实?有没有值得固化的工作流?有没有跟现有记忆冲突的认知?产出的不是模糊的“经验”,而是结构化的候选—— MemoryCandidate / SkillCandidate / ConflictCandidate。每个候选都必须经过你点头才会进入记忆库。
4. 它的“大脑”是 Markdown 文件。 没有向量数据库,没有 Redis,没有 Docker。一条记忆长这样:
---
id: mem_a3f7b2c1
created: 2026-05-01T10:30:00Z
zone: core
tags: [rust, style]
pinned: true
supersedes: [mem_001_older]
---
用户偏好使用 anyhow 处理应用层错误,底层库使用 thiserror。
不要用 unwrap()。
可以 cat 出来读,可以 git diff,可以放进版本控制。Agent 不会偷偷修改自己的“大脑”——所有改动都摊在文件系统上,可见、可审计、可回滚。
整个项目,12 个 crate,约 4500 行核心 Rust 源码。单一二进制,无运行时依赖,冷启动 < 2 秒,常驻 ~15MB。 这些数字是 Rust 直接给的,不需要任何运行时调优。
简单回顾一下底盘
老读者可以跳过这节,新朋友建议读完再看后面——微信桥的所有“魔法”都站在这些设计之上。
记忆是宫殿,不是数据库
记忆按 zone 分区:
core/ 用户身份、偏好、核心原则(几乎不变,永远 pin 到 system prompt)
work/ 当前焦点、近期决策(中频更新)
project:xxx/ 项目级约定和上下文(按项目隔离)
episode/ 会话摘要(高频写入)
general/ 未分类(兜底)
Supersedes 链:Agent 学到新东西时不删除旧记忆,而是写一条新记忆标记 supersedes: [old-id]。list_active() 会自动过滤掉被传递性超越的记忆。这意味着——历史被保留、更新是原子的、最坏情况只是多了一条冗余记忆,不会丢数据。
效果追踪:每条记忆有两个事件—— Loaded(被注入 context)和 Referenced(LLM 回复真的引用了内容)。基于 Referenced / Loaded 比率算出一个 effectiveness factor(0.5 ~ 1.0),低效记忆在检索时会被降权,但永远不会降到 0——它可能只是暂时不相关。
双轨反思
全量反思(Session End)
→ 处理完整对话记录
→ 成本:~2000-5000 tokens in, ~500-1000 tokens out
→ 产出:技能候选 + 记忆候选 + 冲突候选
微反思(Per-Turn,异步)
→ 只看最近一轮,启发式触发,不阻塞用户输入
→ 成本:~500 tokens in, ~200 tokens out
→ 产出:最多 1 个记忆 + 1 个技能,confidence ≤ medium
大部分对话不会触发反思——因为大部分对话确实不会产生新知识。
MCP 让工具生态无限扩展
Small Hermes 实现了完整的 MCP 协议,支持 stdio + Streamable HTTP 两种传输。在 ~/.small-rust-hermes/mcp.json 里加一个 server,Agent 立刻多出一整组工具。Agent 核心循环根本不知道工具是从哪里来的——它只看 trait ToolHost。
终于到主角:第三张脸
CLI 已经足够强了——能聊天、能写代码、能跑工具、能审批反思。GUI 把这一切包成了顺手的桌面应用。但它们都有同一个前提:你得坐在电脑前。
微信桥要解决的就是这一条。
微信桥怎么用,我设计的其实很简单了
两条命令。
# 1. 终端扫码登录(首次)
hermes wechat login
# 终端里会直接渲染一个二维码,用微信扫一下 → 手机点确认
# token 落到 ~/.small-rust-hermes/wechat.toml(mode 600)
# 2. 启动长轮询,开始接消息
hermes wechat run
# 之后在微信里给这个 bot 发消息,就是在和 Hermes 对话
终端扫码长这样(控制台用 unicode 半块直接画出来的二维码,反色渲染让暗色终端也能扫):
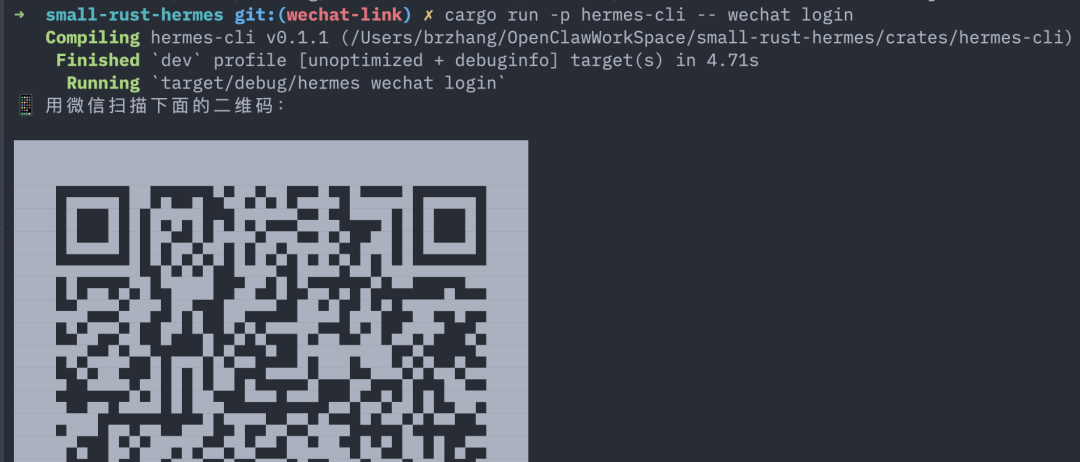
📱 用微信扫描下面的二维码:
如上....
等待确认中… (Ctrl-C 中止)
已扫码,请在手机上确认…
已确认。
✓ 登录成功 (bot_id=xxxx)。Token 已保存到 /Users/you/.small-rust-hermes/wechat.toml
接着执行: hermes wechat run
hermes wechat run 跑起来之后,在微信里给 bot 发任何文本,终端都能看到:
📡 监听中(cursor=0 bytes)。在微信里给 bot 发消息即可对话。
✓ tools ready: 9 whitelisted
memory: 42 active (3 pinned) · profile ✓
skills: 17 loaded
📩 abc123: 我是谁
🤖 → abc123: 你是 brzhang,一位偏好 Rust + anyhow 错误处理的工程师...
微信里则会先看到一条工具调用提示(“🔧 palace_recall: querying core/identity”),然后是 Agent 的正式回答。
工具调用回显,减少等待焦虑,不知道是好是坏
这是一个很关键的细节。
聊天界面(不管是 CLI、GUI 还是微信)的等待焦虑是真实的:你发了一句话,对面“正在输入”了 20 秒,你却不知道它在干什么。CLI 和 GUI 因为是同步可视化的流式输出,Thinking 块和 Tool 调用都展开了让你看,所以焦虑感低。但微信不行——微信只能“一条消息收一条”。

所以微信桥做了工具调用回显:模型每发起一个工具调用,bot 会先发一条 🔧 {summary} 通知到微信,再发最终答案。但工具调用经常一次蹦出来好几个,全发出去就刷屏了,所以又做了 400ms 内的合并:
// crates/hermes-cli/src/commands/wechat.rs
let echo_task = tokio::spawn(async move {
loop {
let Some(first) = tool_rx.recv().await else { break; };
let mut buf = vec![first];
// 400ms 内的工具调用打包成一条 WeChat 消息
let deadline = tokio::time::Instant::now() + Duration::from_millis(400);
while let Ok(Some(more)) = tokio::time::timeout_at(deadline, tool_rx.recv()).await {
buf.push(more);
}
let joined = buf.into_iter()
.map(|s| format!("🔧 {s}"))
.collect::<Vec<_>>()
.join("\n");
let echo = WeixinMessage::reply_text(&inbound_for_echo, joined);
let _ = wx_for_echo.send_message(echo).await;
}
});
效果:典型的“搜索 + 读文件 + 思考”三连,微信里只会蹦一条:
🔧 web_search: "rust 1.84 release date"
🔧 web_fetch: https://blog.rust-lang.org/...
🔧 think: 整理找到的信息
不刷屏,但也不沉默。
协议层上,这个是12 个 crate 里最薄的那个
hermes-weixin 总共四个文件、约 700 行:
crates/hermes-weixin/src/
├── auth.rs QR 登录 + token 持久化(226 行)
├── client.rs HTTP 客户端 + 长轮询(267 行)
├── types.rs 协议数据结构(184 行)
└── lib.rs re-exports(11 行)
接的是腾讯的 iLink Bot 协议(https://ilinkai.weixin.qq.com)。它是腾讯放出来给个人/小团队做微信 bot 的官方通道,工作方式是:
- QR 登录:服务端给你一个 QR payload,用户扫码 → 手机点确认 → 服务端回吐一个长效
bot_token。
- 长轮询拿消息:
POST /getupdates,带上 cursor,hold 住连接最长 38 秒,期间有新消息就立刻返回。
- REST 回消息:
POST /sendmessage,把回复推回去。
整套就这点东西。没有 WebSocket,没有 webhook,没有签名校验——非常适合本地起进程跑(你电脑能上网就够了,不需要公网域名或 HTTPS 反代)。
工具白名单,聊天界面没有“确认弹窗”
CLI 和 GUI 都有工具确认 UI——bash、write、edit、memory_save 这种危险工具会弹出来让你点 Allow / Always-allow / Deny。微信没有这个能力——一条消息没法带按钮。
所以微信桥用白名单制代替:
let allow_names: &[&str] = &[
"web_search", // 联网搜
"web_fetch", // 取页面
"memory_search", // 查记忆
"memory_save", // 写记忆(trade-off:很想要,但不可逆)
"memory_delete", // 删记忆
"palace_zones", // 列出记忆宫殿 zone
"palace_read_zone", // 读取整个 zone
"palace_recall", // 根据 query 召回相关记忆
"think", // 思考占位
];
let tools: Vec<ToolSpec> = all_tools
.into_iter()
.filter(|t| !t.requires_confirmation && allow_names.contains(&t.name.as_str()))
.collect();
注意这里有两个过滤条件叠加:
!t.requires_confirmation —— 所有声明自己“需要二次确认”的工具一律拒绝。哪怕一个 MCP 工具不小心进了白名单,只要它自己要求确认,仍然过不去。allow_names.contains(...) —— 即使工具不要求确认,也要在白名单里才放行。
意思就是:微信里的 bot 不能 bash,不能改你的代码文件。它能查记忆、能搜网页、能往记忆宫殿写东西,但碰不到你的工作目录和系统状态。
这是个有意识的安全边界——你肯定不希望某个躺床上发出去的消息,让 bot 误删了你 home 目录里的什么东西。
Session 隔离,微信用户不混在一起
每个 from_user_id 在 ~/.small-rust-hermes/sessions/wechat/{user_id}/ 下有自己的 JSONL 会话文件:
~/.small-rust-hermes/sessions/
├── 2026-05-23T14-22-01-abc12345.jsonl # CLI / GUI 会话
└── wechat/
└── ozh_abc123xyz/ # 单个微信 user_id 的目录
├── 2026-05-24T09-12-33-def67890.jsonl
└── 2026-05-24T18-45-02-ghi23456.jsonl
user_id 是微信侧的 opaque 字符串,路径写入前做了字符白名单清洗(只保留 [A-Za-z0-9_-],其他换 _),防止路径注入。
hermes session list 和 hermes session show 这些 CLI 命令对这些文件完全无感——它们扫的是 ~/.small-rust-hermes/sessions/ 整个目录树。这意味着:
- 早上在微信里和 bot 聊的内容,下午在电脑上
hermes session show <path> 能直接回放。
- 反思系统会读到所有 surface 的会话,提炼出来的技能和记忆,三个 surface 都受益。
Cursor 持久化
长轮询会维护一个 cursor(服务端告诉你“下一次从这里开始拿”)。这个 cursor 在 ~/.small-rust-hermes/wechat-cursor.txt,每次拿完消息就落盘。这样你 Ctrl-C 退出再重启 hermes wechat run,不会重复处理已读消息,也不会丢掉中间到达的消息。
已知不完美,群友反馈的,将继续优化
诚实是好习惯。这次微信桥不是完美的,缺口如下:
- 只支持文本。图片、语音、文件、视频要走 AES-128-ECB + CDN 的另一套流程,单独留 PR。
- 单账号。一台机器只支持一个
wechat login 的登录态——wechat.toml 是单文件结构。多账号需要重新设计存储路径。
- 群聊未接入。
group_id 字段还没处理。
ret=-14 直接退出。token 失效时(一般是 30 天内不用就失效)程序退出并提示重新 login。没做自动 refresh——iLink 的长效 token 协议本身就没设计 refresh 机制。- 工具是白名单而不是确认。前面解释过了。如果你接了一个高价值的 MCP 工具想从微信触发,目前需要手动改白名单代码。
不过,这些都是 polish,不是 blocker。核心闭环——QR 登录、长轮询接消息、工具调用回显、对话持久化、与 CLI / GUI 共享记忆——已经全部跑通。
下个版本会补上这些,但不会为了赶 polish 牺牲“三张脸共用一颗心”的硬约束。
一些数字来说明为什么 mini Hermes 更加轻量
先看微信桥本身的代码量:
hermes-weixin 协议层: 688 行 Rust
hermes-cli/wechat.rs: 510 行 Rust(含 RunCtx 装配、工具回显、长轮询循环)
新增依赖: qrcode + uuid(都是 pure-Rust, 几十 KB)
再看运行时表现——这部分是 Rust 直接送的:
冷启动→可接消息: ~1.5 秒
单条文本消息处理(不含 LLM): <50ms
常驻内存(接收循环空闲态): ~12 MB
常驻内存(处理峰值): ~25 MB
单文件二进制大小: ~25 MB(release 编译,含全部 12 个 crate)
对比一下同类 Python / Node.js 实现(社区里常见的微信 bot 桥):
| 指标 |
Small Hermes (Rust) |
典型 Python / Node 实现 |
| 安装产物 |
1 个二进制 |
venv / node_modules + 解释器 |
| 安装空间 |
25 MB |
300 MB - 1.5 GB |
| 冷启动 |
< 2 秒 |
5-15 秒 |
| 空闲内存 |
~12 MB |
150-400 MB |
| 一台老笔记本能挂多少个 |
一抓一把 |
一个就嫌重 |
这不是为了卷数字。 这直接决定了“我能不能让这玩意儿在我笔记本背景里挂一整天,而不影响我做别的事”。一个吃 400 MB 的 Python 进程,一打开 Chrome 就开始抢内存;而一个吃 12 MB 的 Rust 进程,你根本注意不到它在跑。
Token 经济性这块,我认为 Agent 真正贵的是 LLM 账单
CPU 和内存只是开胃菜。Agent 的运营成本里,99% 在 LLM API 那一栏。Rust 没法直接帮你省 token——但 Rust 的“精确控制”心智模型,让我们在每个会花 token 的地方都做了细致的限额:
全量反思: ~2000-5000 tokens in, ~500-1000 tokens out (每个 session 结束 1 次)
微反思: ~500 tokens in, ~200 tokens out (启发式触发,大部分轮次跳过)
上下文压缩: 触发后压到原长度的 1/5 (LLM 驱动的有损摘要)
记忆注入: BM25 + effectiveness 排序选 top-N (不是全量灌)
工具 schema: 微信白名单只暴露 9 个 (CLI 几十个工具的定义不带进来)
system prompt: 基础部分对每个 turn 字节级稳定 (命中 Anthropic prompt cache 拿 90% 折扣)
实测下来,一次典型的“问一句话 + 1-2 次工具调用”的对话:
- 输入 tokens:3K~8K(含完整的记忆宫殿索引 + 用户 profile + 相关技能 + 历史几轮)。
- 输出 tokens:200-800。
- 走 Anthropic prompt cache 时:从第二轮起,输入实际计费 tokens 降到约 500(90% 的部分被 cache 命中)。
整个项目从 11 个 crate 涨到 12 个,但核心 Agent 的代码一行没动。hermes-core / -turn / -llm / -memory / -skills / -reflect / -store / -tools / -mcp 这九个 crate 完全不知道有微信桥存在——它们只暴露 trait 和数据结构,新的 surface 自己负责把数据接进去。
这就是 Rust workspace + trait 的好处:新增一张脸,不需要改任何旧脸的代码。
怎么自己跑起来
前提:你已经按 README 配好了 ~/.small-rust-hermes/config.toml,CLI 或 GUI 已经能用。
# 1. 拉最新代码
cd small-rust-hermes
git pull
cargo build --release
# 2. 微信扫码登录
./target/release/hermes wechat login
# 终端会渲染一个二维码——
# 用微信扫一下 → 手机点“登录”按钮
# 看到 "✓ 登录成功",wechat.toml 已落盘(mode 600)
# 3. 启动接收循环
./target/release/hermes wechat run
# 现在在微信里给这个 bot 发消息即可对话
# Ctrl-C 优雅退出,cursor 自动保存
第一次发消息时,建议先试这几个:
我是谁? # 验证记忆/技能加载是否生效
今天几号? # 验证时间注入是否生效(应答出真实当天日期)
搜一下 rust 最新版本 # 验证工具调用回显
帮我记一下:偏好用 Helix 编辑器 # 验证 memory_save 走得通
第二次启动 hermes wechat run 时,会看到 cursor=xxx bytes 大于 0,表示中断期间没有消息丢失。
写在最后
做这个微信桥之前,我又问了一遍自己当年做 GUI 的那个问题:Agent 真的需要这第三张脸吗?
CLI 够强了,GUI 也做完了。再加一张微信脸,是不是过度工程?
最后说服自己的理由就一条——Agent 的价值密度,取决于它在多少种场景下能被低成本调用。 通勤路上、午休吃饭、夜里失眠的时候,我打开手机 30 秒就能问出来的东西,如果一定要等到回家开电脑,那这件事 80% 的时候都不会发生。
而这件事能做成,前提是 Rust。 一个吃 500 MB 内存、冷启动 10 秒、随便一条消息就消耗 50K tokens 的 Agent,我不可能让它在笔记本背景里挂一整天等微信消息——电费、API 账单、电脑发热都不允许。但一个吃 12 MB 内存、冷启动 1.5 秒、单次对话 3K~8K tokens(命中 cache 后再砍掉 90%)的 Rust Agent,我可以理直气壮地让它常驻,可以心安理得地随时给它发消息。轻量本身就是一种功能。
CLI 适合“我在写代码”的场景。GUI 适合“我在桌面端深度对话”的场景。微信适合“我在生活里随口想到一件事”的场景。三个场景共享同一份记忆和技能,意味着——我在微信里告诉 bot 的一句“我以后用 Helix 编辑器”,明天在 CLI 里写代码时,它就已经知道了。
这是单一 surface 的 AI 助手做不到的事。
12 个 crate,约 4500 行核心 Rust 源码。单文件 25 MB 二进制。冷启动 < 2 秒,常驻 12 MB。单次对话 3K-8K tokens,cache 命中后降到约 500。三种调用方式。一份记忆宫殿,一份技能库,一份会话历史。
核心理念依然没变:
- 同一个引擎,多张脸
- 所有进化必须人类点头
- 所有状态摊在文件系统上
- 用 Rust,所以“轻”和“省”是默认值,不是优化目标
- 简单到能读完,强大到能用
终端用户、桌面用户、微信用户共享同一个 Agent。它在 CLI 里学到的,在 GUI 里也记得;它在 GUI 里养成的习惯,微信里也带着;它在微信里收到的偏好,下次 CLI 启动时已经在 system prompt 里。
三张脸,一颗心。
项目地址: https://github.com/coder-brzhang/small-rust-hermes
 发表于 2026-5-24 20:50:33
|
查看: 186|
回复: 0
发表于 2026-5-24 20:50:33
|
查看: 186|
回复: 0
