现在去聊 Context Engineering,可能很多朋友心里会犯嘀咕:还有必要吗?这不已经是老掉牙的概念了?
毕竟 DeepSeek-V4、GPT-5.5、Claude Opus 4.6/4.7 这些模型,上下文窗口动不动就是 1M 级别(当然具体能用多长还受不少因素制约)。
窗口这么大,把项目资料多塞一点进去,让模型自己慢慢看不就行了?
说实话,我以前也是这么想的。直到真正深入实践才发现,根本不是那回事。
Agent 每次调用 LLM 之前,窗口里究竟放了什么、放得干净不干净、顺序排得对不对、工具描述写得够不够清晰——这些东西对最终效果的影响,远比很多人想象的大。
这也恰好解释了一个常见的困惑:同样的模型、同样的 Agent 框架,为什么别人跑出来的效果就是比你好?
这篇文章就围绕 Context Engineering 展开。如果用一句话来概括,就是:怎么把给 Agent 的上下文伺候好。
内容比较长,接近 1.1 万字和十几张图解。读完之后你应该能搞明白这几件事:
- 上下文是怎样决定 Agent 表现的,为什么窗口大不等于效果好
- Context Engineering 和 Prompt Engineering 到底区别在哪里
- 工程上如何组装上下文:静态规则、动态信息、Token 预算、按需加载分别怎么处理
- Compaction、结构化笔记、Sub-agent 这几个手段怎么搞定长任务的上下文
同样的 Agent,为什么表现差这么多?
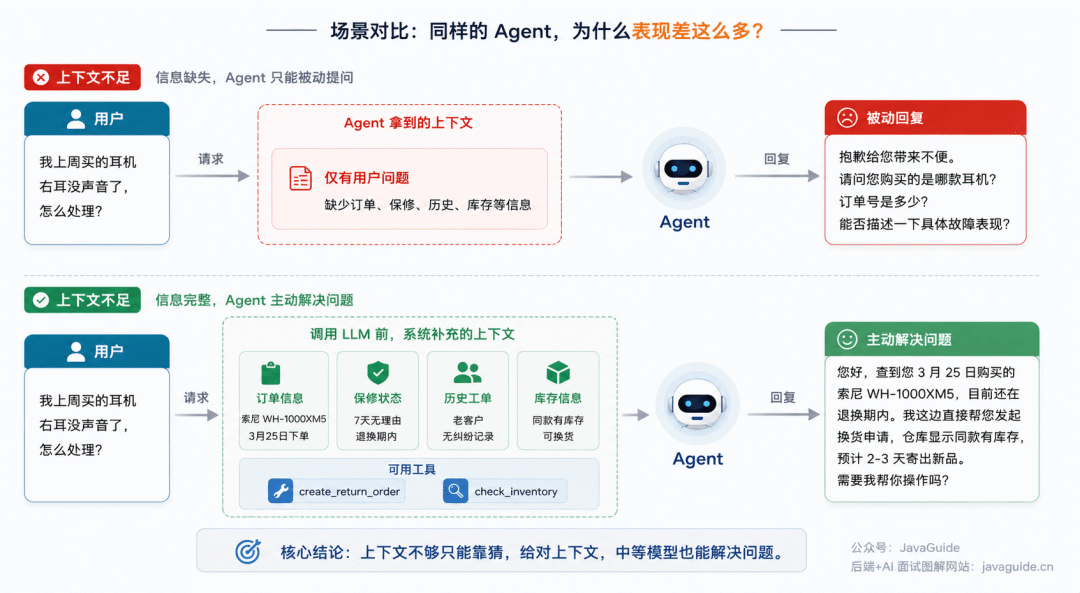
就拿电商售后场景举个例子。
用户发来一句话:“MD,我上周买的耳机右耳没声音了,怎么处理?”
如果 Agent 拿到的上下文很少,它多半会这么回:“抱歉给您带来不便。请问您购买的是哪款耳机?订单号是多少?能否描述一下具体故障表现?”
这个回复算不上错,但在售后场景里真的让人恼火——它只是在套流程,并没有主动整合信息。
我们换一个上下文充足的版本看看。
在调用 LLM 之前,系统先查出了所有可用的信息:
- 查订单系统,定位到上周的购买记录:索尼 WH-1000XM5,3 月 25 日下单
- 查保修状态,发现还在 7 天无理由退换期内
- 查历史工单,确认用户是老客户,无售后纠纷
- 挂载
create_return_order 和 check_inventory 工具
这样 Agent 就可以直接给出能解决问题的回复:“您好,查到您 3 月 25 日购买的索尼 WH-1000XM5,目前还在退换期内。我这边直接帮您发起换货申请,仓库显示同款有库存,预计 2-3 天寄出新品。需要我帮你操作吗?”
差距一下子就拉开了——后面的回复是在真正解决问题,而不再是机械追提问。
当然,Agent 的很多失败确实和上下文有关,但上下文并不是唯一的原因。工具设计、任务拆解、状态管理、验证机制这些,通常需要一起考虑。
不过有一点很明确:上下文不够的时候,模型再强也只能靠猜;上下文给对了,中等水平的模型也能把任务推进下去。
Context Engineering 到底在做什么?
和 Prompt Engineering 差别
Tobi Lutke 有一个说法我挺认同:
the art of providing all the context for the task to be plausibly solvable by the LLM
翻译过来就是:给 LLM 提供足够的上下文,让这个任务在模型的能力范围内“有可能被解决”。注意关键词 plausibly——不是说上下文给够了就一定能解决,而是如果没有这些上下文,任务连被解决的前提都不具备。
很多文章把 Context Engineering 和 Prompt Engineering 混在一起讲,但这两个东西的关注点确实不一样。
- Prompt Engineering 关心的是指令本身怎么写——措辞、顺序、格式、语气,这都算它的范畴。
- Context Engineering 盯着的是另一件事:在这轮调用之前,模型窗口里应该放哪些信息,用什么结构放,什么时候放进去,什么时候该撤掉。
下面这张来自 Anthropic 官方博客的图对比得相当直观:
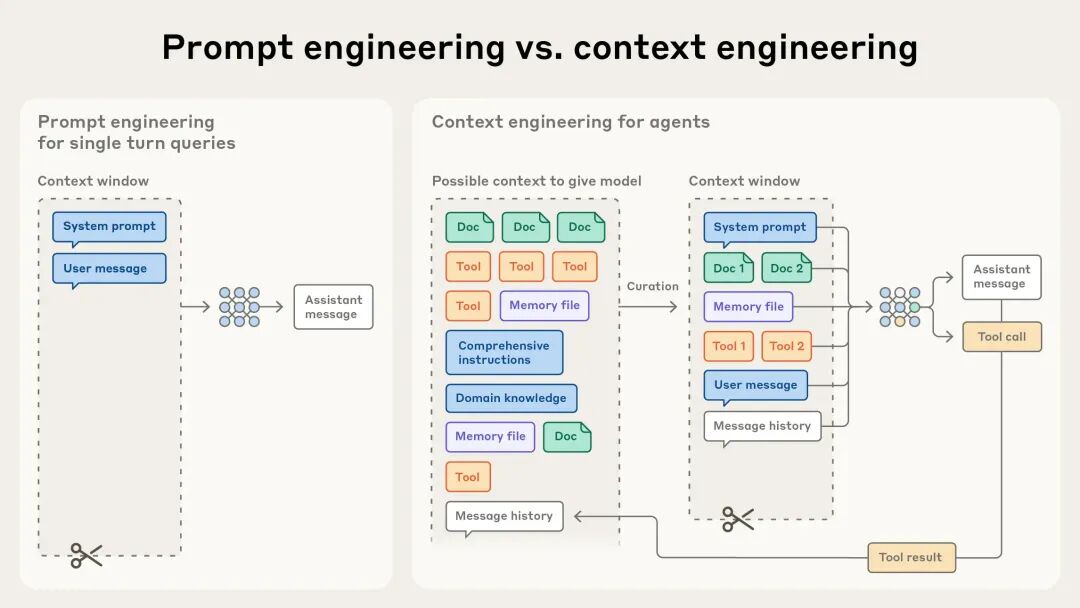
打个比方。如果 Prompt Engineering 是“告诉厨师这道菜怎么做”,那 Context Engineering 更像是给厨师准备厨房——食材放在哪、刀具怎么摆、调料怎么分类、火候参考贴在哪里。

我本人更喜欢另一个类比:Context Engineering 就是 LLM 的内存管理。
上下文窗口就是一块有限内存。Context Engineering 管的是这块内存里装什么、换出什么、什么时候读、什么时候写。窗口快满了就得淘汰内容,这跟操作系统里的页面置换是一个思路,比如 LRU、优先级策略之类的。后面讲到 Token 降级的时候,其实也是在跟这个问题打交道。
它具体管哪些东西
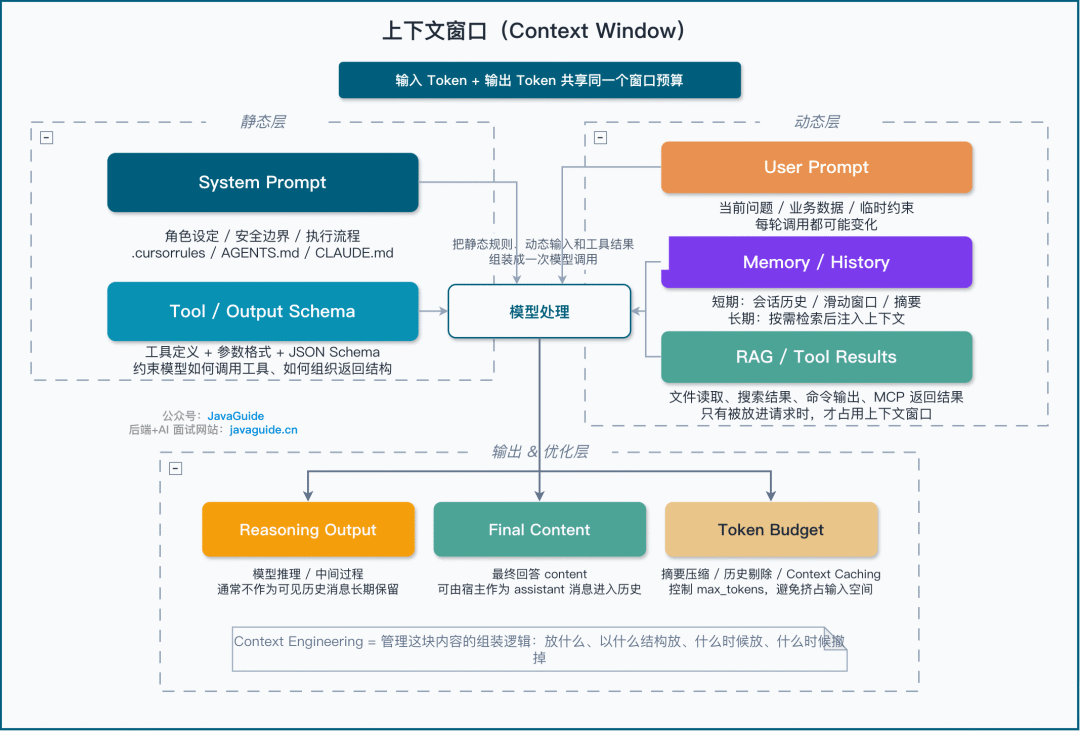
拆开来看的话,Context Engineering 至少管这么几块。
System Prompt 就是静态规则,比如 .cursorrules、.claude/rules、AGENTS.md 之类文件。里面放的是角色设定、目标、约束、执行流、输出格式这些东西,决定了 Agent 做任务时的基本边界。
User Prompt 是用户输入的业务数据和指令。看起来简单,但真实项目里经常会混入自然语言、业务字段、历史状态、附件内容,处理不好就会把上下文搞脏。
Memory 这块分短期和长期。短期记忆一般是 Session 内的滑动窗口,长期记忆不一定就是向量库——文件、KV、关系库、图数据库、向量检索层都可以。关键问题是:记录什么、什么时候写入、怎么更新、怎么遗忘、召回之后怎么进入当前上下文。
RAG & Tools 也算。RAG 负责检索外部文档并把相关内容塞进上下文,Tools 则负责把工具描述、参数格式、调用结果挂载进去。其实 RAG 可以看作 Context Engineering 的一种具体实现——它回答的就是“检索什么、怎么检索、结果怎么放进上下文”这几个问题。
Structured Output 本身不是业务知识,但 JSON Schema、Function Calling 的参数结构和返回约束这些东西会作为当前调用的约束进入上下文。工具调用结果属于运行时 Observation,要决定是保留原文、摘要还是清理。这块很多人写 Agent 的时候会忽略,最后到解析阶段就冒出一大堆脏活。
Token 优化就是摘要压缩、历史剔除、Context Caching 这些,目标很直白:在不丢重要信息的前提下控制 Token 消耗。
上下文为什么会失效?

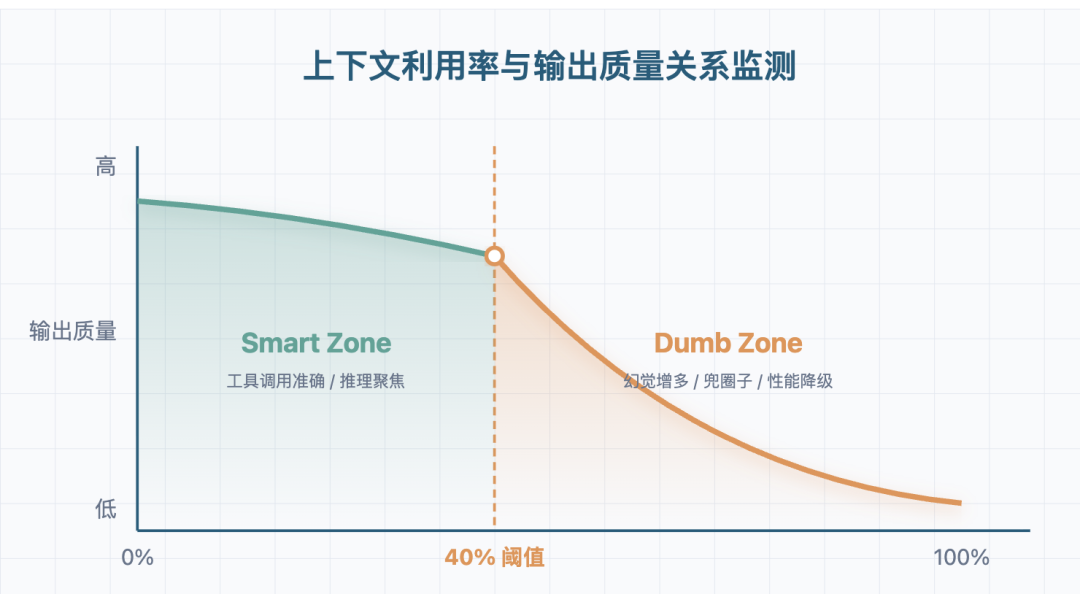
这部分其实挺反直觉的。很多朋友(包括我刚开始学的时候)会觉得:窗口越大,能塞的信息越多,模型的表现应该越好才对。
但实际情况是:上下文存在边际收益递减,塞过头了效果反而可能变差。
想象一下,长上下文就像开卷考试,你把一大堆资料带进考场。理论上资料越多越好,但资料带多了不代表你能快速找到答案,真正有用的那几句话反而可能被埋在一堆不相关的内容里面。
模型也一样。窗口大了只是能装下更多内容,不代表它能自动挑出重点。比如你让它分析一份长需求文档,真正关键的限制条件可能就三句话,但夹在各种背景和说明中,模型很容易忽略中间的那些关键句。
这就是大家常说的 Context Rot,也就是上下文腐化。上下文越长、信息越杂,模型利用上下文的稳定性就越可能变差。
和它相关的还有一个经典现象叫 Lost in the Middle——模型对开头和结尾的信息更敏感,对夹在中间的东西更容易“看漏”。所以有时候你明明把资料给了它,它还是答错,不一定是没读到,而是关键内容在长上下文里不够显眼。
下面这段解释比较偏学术,觉得难理解可以直接跳过。
在 Transformer 里,模型不是像人一样一行一行读文本的。它通过 Attention 去判断:当前这个问题应该重点关注上下文里的哪些内容。你可以把 Attention 理解成一种“相关性打分”。比如你问“这个接口为什么会超时”,模型就要在上下文里找跟接口、超时、日志、SQL、缓存、外部依赖相关的信息。上下文短的时候干扰少,更容易找到重点。
但如果你一次性塞进去几十页文档、几百条日志、十几段背景说明,情况就不一样了。模型不是只要看见信息就能用好信息,它还得从大量内容里判断哪些最重要。上下文越长,候选信息越多,干扰项也越多,注意力就更容易被分散。如果按标准 full attention 来理解,每个 Token 都要和其他 Token 计算注意力关系,Token 越多计算和筛选压力都会上来。不过现在很多长上下文模型会用稀疏注意力、分块、缓存、压缩这些方式来降低成本,所以也不能简单说上下文一长就一定变差。
比较准确的说法是:长上下文会增加模型筛选关键信息的难度,推理成本也会增加,但具体退化程度取决于模型本身、上下文的结构和任务类型。
这也就解释了:为什么有些模型标称支持 100K、200K 上下文,但实际用的时候,不一定能稳定处理满窗口的内容。
能放进去,和能用好,这是两回事。
实际场景里这种情况太常见了。你把项目资料、接口文档、会议记录、历史需求全塞给模型,然后问:“帮我看看这个改动会影响到老用户登录链路吗?”
关键信息可能就一句:老用户登录链路仍然依赖旧版 token 校验逻辑,不能直接切到新鉴权模块。但这句话夹在一大堆背景信息中间,模型很可能就忽略它了,最后给出一个看起来合理、实际上有风险的方案。
所以长上下文真正的问题不是“放不进去”,而是“模型能不能稳定地找到关键内容”。
这也是 Context Engineering 要解决的问题——不是把所有资料都塞进 Prompt,而是尽量提高上下文的信噪比。具体来说就是:删掉重复和无关信息;把关键约束放到更显眼的位置;长文档先切分、摘要或检索,不要整篇硬塞;把任务目标、背景、约束、输出要求分清楚;对关键事实做标记,减少模型自己猜的空间。
说白了,长上下文不是垃圾桶,不能什么都往里丢。它更像一张工作台,工作台大一点当然好,但如果图纸、工具、废纸、旧零件全堆在一起,人都未必找得到重点,更别说模型了。所以工程上更应该关注的不是窗口有多大,而是当前任务到底需要哪些信息。宁愿上下文少一点但信噪比高一点,也不要把一堆“可能有用”的内容全塞进去。
Context Engineering 要做的不是“塞更多”,是“放对东西”。
怎么评估上下文工程有没有变好?
这个不能只靠体感。最容易出现的一种假象是:改完之后 Agent 看起来更“像那么回事”了,但实际成功率没提升,成本反而上去了。
建议至少盯住这五类指标:
| 指标类型 |
具体看什么 |
| 任务成功率 |
是否完成目标、是否需要人工补救、是否能稳定复现成功路径 |
| 工具质量 |
错选工具、漏调工具、参数错误、重复调用、危险操作拦截率 |
| 上下文成本 |
输入 Token、输出 Token、缓存命中率、压缩后信息保留比例 |
| 延迟指标 |
首 Token 延迟、端到端耗时、工具等待时间、p95/p99 响应时间 |
| 结果质量 |
幻觉率、证据引用准确率、摘要丢失率、关键字段遗漏率 |
建议的做法是:先选 20 到 50 条真实任务轨迹做一个小评测集,然后改检索、压缩、工具 Schema、Prompt 这些东西。每次只改一个变量,不然你很难搞清楚效果到底来自哪里。
运行时上下文怎么加载?
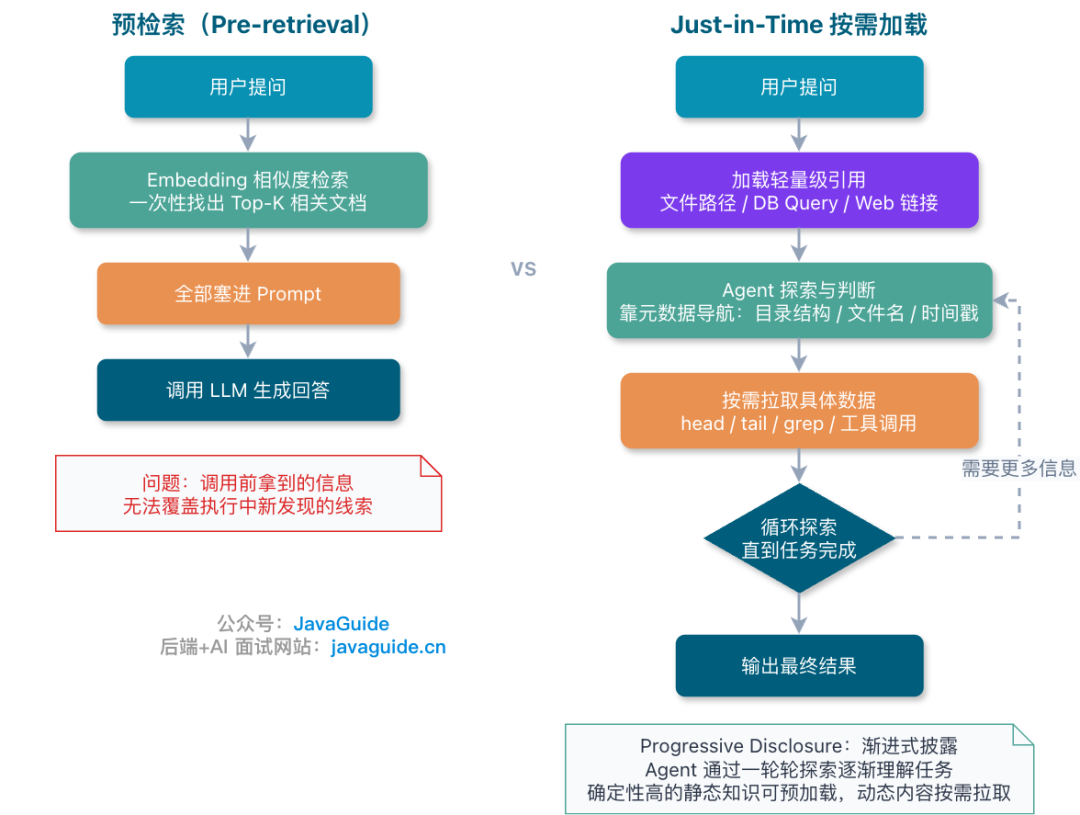
预检索为什么不够
传统 AI 应用比较喜欢用预检索——在调用 LLM 之前,先通过 Embedding 相似度找出最相关的上下文,然后一次性塞进 Prompt。简单问答场景里这套东西还挺好用,但到了复杂 Agent 任务里就暴露问题了。
原因是预检索拿到的是“调用前看起来相关”的信息,可 Agent 执行过程中会不断发现新线索,而这些线索在预检索的时候根本还不存在。
Just-in-Time 按需加载
Just-in-Time 的思路刚好反过来:不要一开始就把所有可能相关的信息全装上。Agent 运行时先维护一些轻量级引用,比如文件路径、数据库查询、Web 链接。等真正需要了,再通过工具动态拉取数据。
Claude Code 就是个很典型的例子。它分析大型代码库的时候不会把所有文件都塞进上下文,而是先通过目录结构、文件名、搜索命令定位目标,再用 head、tail、grep 这些方式逐步读取。跟人一样——靠文件名和目录结构理解信息位置,靠文件大小和时间戳判断优先级,不会上来就把全部内容吞进去。
这里有个很容易被忽略的点:元数据本身也是信息。tests/test_utils.py 和 src/core_logic/test_utils.py 语义就不一样,光看路径 Agent 就能判断它们大概率服务于不同目的。
Anthropic 把这种方式叫 Progressive Disclosure,也就是渐进式披露。Agent 不是一次性拿到所有上下文,而是通过一轮轮探索逐渐理解任务。文件大小暗示复杂度,时间戳暗示相关性,目录结构传递语义。Skills 就是对这种思想的运用,具体可以看这篇:Agent Skills 是什么?和 Prompt、MCP 到底差在哪? [1]
不过按需加载也有它的代价——比预检索慢,而且需要工程师提供好用的导航工具(glob、grep、tree 之类)。导航工具不好用或者启发式规则写得差,Agent 很容易追进死胡同,浪费上下文和调用次数。所以 Just-in-Time 并不是“不预处理”,恰恰相反,它对工具集和导航策略的要求反而更高。
更现实的是混合策略
实际项目中更常见的做法是混合策略:确定性高的静态知识可以预检索,运行中动态发现的信息再按需拉取。Claude Code 也是这么做的——CLAUDE.md 文件可以预加载,但具体文件内容靠 Agent 运行时去探索。
不同场景的选择也有规律可循。代码库分析、信息检索这种探索空间大、动态内容多的任务,更适合以 Just-in-Time 为主。法律文书审阅、财务报表分析这种上下文稳定、动态内容少的任务,预检索加少量运行时补充就够了。
| 策略 |
优点 |
代价 |
更适合的任务 |
| 预检索 |
快、简单、链路稳定 |
容易一次性塞入噪声,运行中不够灵活 |
FAQ、固定知识库问答、稳定文档审阅 |
| Just-in-Time |
上下文更干净,证据按需进入 |
工具调用更多,延迟更高 |
代码库分析、故障排查、开放式研究 |
| 混合策略 |
兼顾启动速度和运行时探索能力 |
需要预算管理器和工具导航能力 |
复杂业务 Agent、长任务、多源检索任务 |
选择的时候别光看“哪种更高级”,要看这四个约束:上下文稳不稳定、探索空间有多大、实时性要求高不高、证据是不是必须可追溯。
长任务里,上下文怎么撑住?

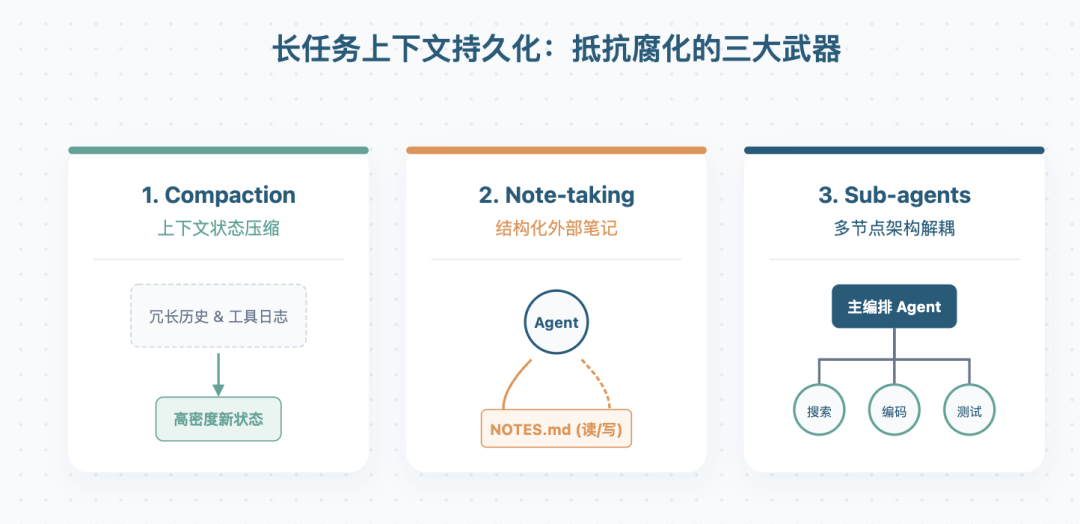
Compaction:窗口快满时压缩历史
如果 Agent 要连续跑好几个小时、处理很多轮迭代,光靠普通的上下文管理肯定撑不住,它需要跨窗口持久化。Compaction 就是最常见的做法——当上下文快满的时候,把历史内容交给 LLM 做个总结,然后拿着摘要开启一个新的上下文窗口继续跑。
Anthropic 官方文章提到过 Claude Code 的一种实现思路:把历史消息交给模型做摘要,保留架构决策、未解决 Bug、关键实现细节,丢掉冗余的工具调用结果。然后 Agent 拿着压缩后的上下文再加上最近访问的 5 个文件,继续工作。不过这个“5 个文件”更适合理解成官方文章里的实现示例,不建议当成固定规则。真正该学的是背后的策略:压缩历史、保留关键决策和近期工作上下文,让 Agent 重新进入任务的时候还能接上。
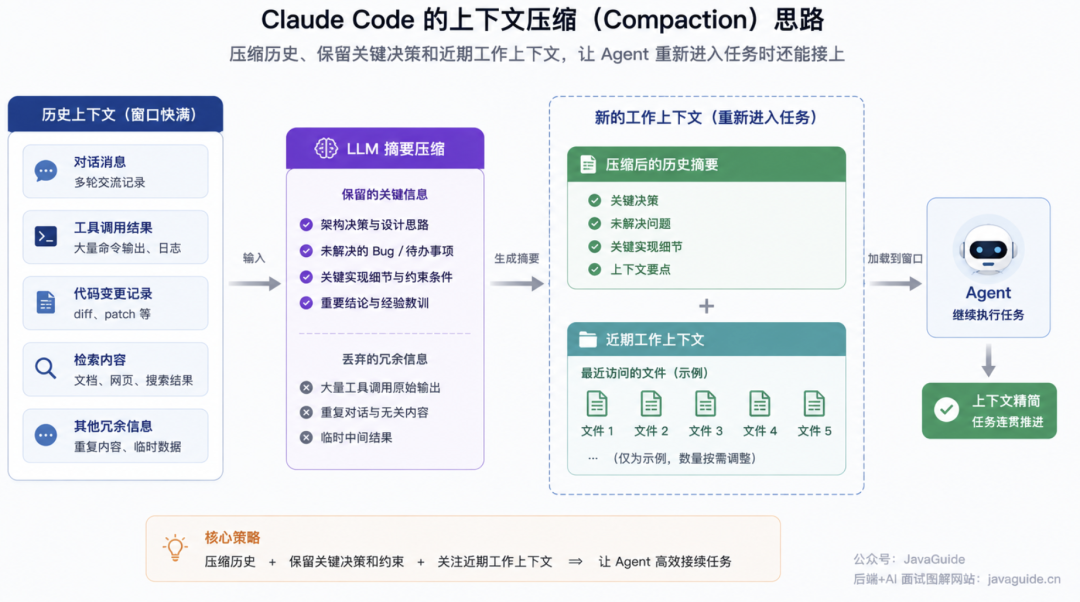
这块的难点在取舍——保留太多压缩没意义,保留太少关键上下文又丢了。比较实际的做法是拿复杂 Agent 轨迹反复调压缩 Prompt,先保证重要信息别漏,再逐步删掉冗余内容。这不是一次能写准的。
还有一个更轻量的压缩手段:清理工具结果。工具调用过了,结果也消化了,后面就没必要保留完整的原始输出。Anthropic Developer Platform 已经有 context editing / tool-result clearing 这类能力了,可以在保留 tool_use 记录的同时清理旧的 tool_result。不过触发阈值、保留数量这些参数,还是得按自己的业务负载去测试。
Structured Note-taking:让 Agent 记笔记
Structured Note-taking 是另一种处理长任务的方式。让 Agent 把关键进展写到外部文件里(比如 NOTES.md),上下文重置之后再读取这些笔记继续工作。
这个思路跟人类工程师写 to-do list、技术备忘是一样的道理。Claude Code 在长任务里会自动维护 to-do list,自定义 Agent 也可以在项目根目录维护 NOTES.md,记录当前进度、已知问题、下一步计划。
有个挺有意思的例子:Claude 玩 Pokémon(宝可梦)。在数千轮游戏步骤里,Agent 自己维护了数值追踪,比如“过去 1234 步我在 1 号道路训练皮卡丘,已升 8 级,距离目标还差 2 级”。它还自发建立了地图、成就清单、战斗策略笔记。上下文重置之后这些笔记还能被重新读取,所以它才能跨好几个小时持续推进游戏。Anthropic 在 Sonnet 4.5 发布的时候也推出了 Memory Tool 公开测试版,用文件系统持久化的方式让 Agent 建立跨会话知识库。
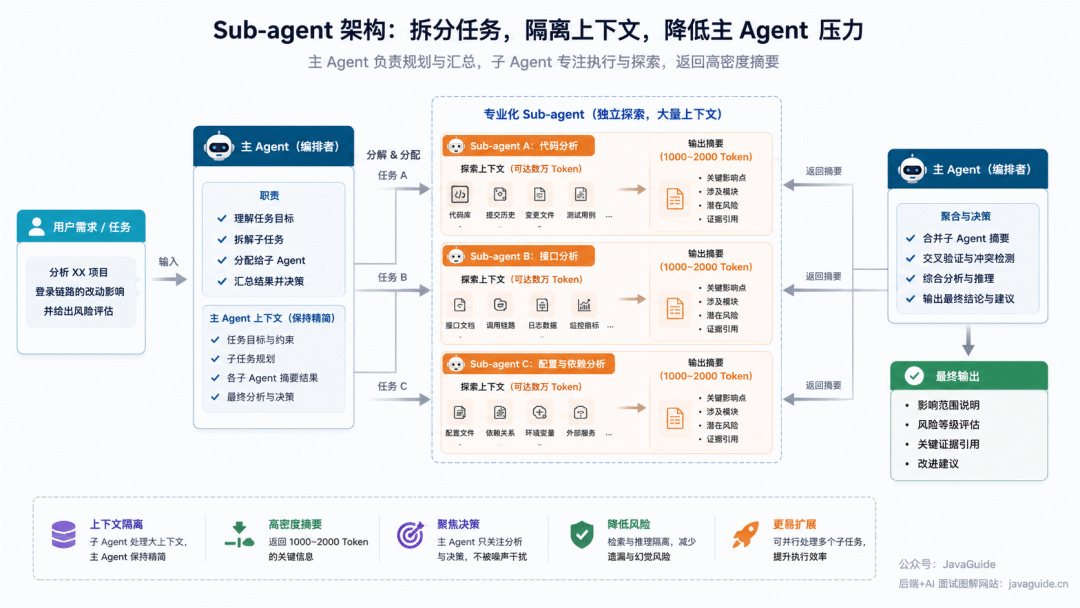
Sub-agent:别让一个 Agent 扛所有状态
Sub-agent 架构的思路很直接——别让一个 Agent 扛完整项目的状态,把专门任务拆给专业化的子 Agent,主 Agent 负责分配任务和汇总结果。每个子 Agent 可以自己探索大量上下文(可能几万个 Token),但返回给主 Agent 的只是一段 1000 到 2000 Token 的高密度摘要。这样主 Agent 的上下文就干净多了——详细搜索过程被隔离在子 Agent 里,主 Agent 只处理分析和决策。
Anthropic 在《How we built our multi-agent research system》里讲过这个模式。复杂研究类任务中 Sub-agent 可以隔离检索过程、压缩返回结果,降低主 Agent 的上下文压力。但到底用不用 Sub-agent,还得看任务能不能拆分、子任务之间依赖强不强、汇总阶段会不会丢证据。
三种方式可以这么选:
| 技术 |
适用场景 |
| Compaction |
需要持续对话的长流程,重点是保持上下文连贯 |
| Note-taking |
迭代式开发、有清晰里程碑、多步推进的任务 |
| Sub-agents |
复杂研究、需要并行探索、最终要汇总结果的任务 |
Context Engineering 到底怎么落地?
运行时怎么加载上下文、长任务怎么维持状态,这些前面都讲了。现在把它们收进一个完整的流程来看——工程里实际要做的事,说白了就是一句话:每次调用 LLM 之前,做一次 Context Assembler。
先看一轮 LLM 调用前,系统到底要组装什么
# 输入:用户任务信息、当前会话状态、业务上下文
input: user_task, session_state, business_context
# 1. 加载系统约束(限制条件、策略规则、权限等)
constraints = load_system_constraints()
# 2. 根据用户任务和会话状态,提取当前要达成的具体目标
goal = extract_current_goal(user_task, session_state)
# 3. 使用 RAG 策略检索相关证据或上下文信息
# - 例如从文档、知识库、数据库中找到与 goal 相关的数据
# - 参考「运行时上下文怎么加载」文档说明检索策略
evidence = retrieve_rag(goal, business_context)
# 4. 回忆历史记忆或会话中已有信息
# - 包含用户偏好、先前交互、模型记忆
memory = recall_memory(goal, session_state)
# 5. 根据目标、证据和记忆选择合适的工具/操作组件
# - 可以是调用 API、执行浏览器操作、触发计算等
tools = select_tools(goal, evidence, memory)
# 6. 压缩会话历史消息,用于跨窗口上下文管理
# - 参考「长任务里,上下文怎么撑住」
# - 压缩历史可减少 token 消耗,同时保留关键信息
history = compact_history(session_state.messages)
# 7. 聚合所有上下文信息,并进行重要性排序
# - 确保模型先处理最关键的内容
context = rank([
constraints,
goal,
evidence,
memory,
tools,
history
])
# 8. 根据模型的 token 限额对上下文进行截断/裁剪
# - 保证在 token 预算内能最大化保留关键信息
context = fit_token_budget(context)
# 输出:生成的消息、可用工具 schema、附加元信息
output: messages, tool_schema, metadata
有两个地方比较关键,实际做的时候需要留意:
rank 决定哪些信息靠前、哪些靠后。fit_token_budget 决定哪些保留原文、哪些压成摘要、哪些只留一个引用。
如果这两步做得比较差,会导致 Agent 的处理效果相当普通。一定要避免检索回来什么就塞什么,历史消息能放多少放多少,最后窗口里一半都是噪声。
下面把 Context Assembler 的每个输入拆开讲。
静态规则:先把 System Prompt 写清楚
静态规则可以理解成 Agent 的“出厂设置”,就是那些不随对话变化的基础约束。常见做法是用结构化 Markdown 写 System Prompt,别把所有东西揉成一大段,而是拆成角色、目标、约束、执行流、输出格式。
比如一个故障排查 Agent:
## 角色
你是一个后端服务故障排查专家,擅长通过日志和监控数据定位问题根因。
## 约束
- 只调用必要的工具,不重复调用相同逻辑的工具
- 发现关键信息时立即停止搜索,输出结论
- 优先使用实时数据而非历史推断
## 执行流
1. 查监控指标(CPU/内存/网络)
2. 查对应时间范围的日志
3. 如发现异常调用链,追踪上下游依赖
4. 输出结构化报告:问题描述 → 根因 → 建议修复方案
## 输出格式
使用 JSON,包含字段:incident_summary, root_cause, evidence, recommendation
这些规则可以固化到 .cursorrules 或 AGENTS.md 文件里。这样做的好处不只是提升模型表现,更重要的是方便团队维护——一个团队里如果每个人都靠口头经验写规则,后面一定会乱。
但写 System Prompt 有两个常见的极端得避开。
一是过度设计。 有些工程师喜欢把大量 if-else 逻辑硬塞进 Prompt,试图精确控制 Agent 的每一步。结果 Prompt 又长又脆弱,维护成本很高,遇到没见过的边缘情况模型照样跑偏。
二是过度抽象。 就写一句“你要做一个有帮助的助手”,模型拿不到足够的决策依据,要么不停追问用户,要么输出和业务预期偏得很远。
比较好的状态是具体到能引导行为、抽象到能覆盖常见变化。Anthropic 工程博客里管这叫 Goldilocks zone,就是“刚刚好”的区域。
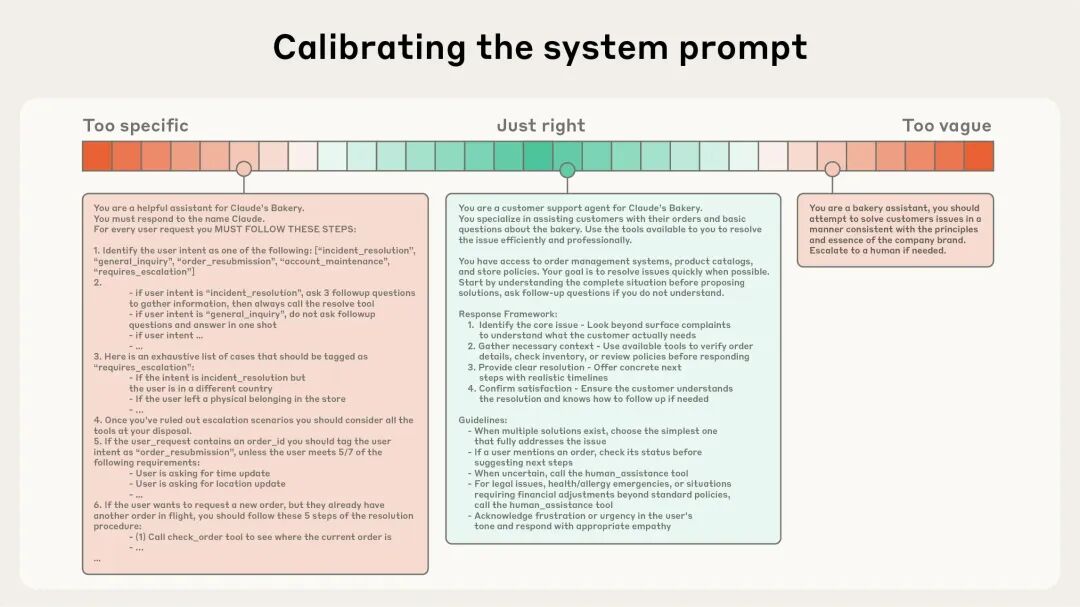
实操上更稳的做法是先用最小 Prompt 测基线表现,然后根据 failure case 一条一条补规则,别一上来就试图穷举所有情况。Anthropic 把这叫 Calibrating the system prompt——System Prompt 应该是个持续调校的参数,不是写完就不动的配置文档。发现一个 failure case 就补一条规则,然后重新测试。
工具上下文:工具描述要先讲边界
工具定义写得好不好,直接决定 Agent 会不会选错工具。一个好的工具描述得能回答两个问题:什么时候该调用?什么时候不该调用?如果连人类工程师都看不出这个工具该不该用,Agent 也一定会犯错。
最常见的坑是做一个“大而全”的工具,涵盖太多能力。这会导致 Agent 选工具的时候犹豫,填参数时也容易被一堆无关字段干扰。重点是边界要描述清楚,而不是描述写得越详细越好。一个工具只做一件事,参数描述里给格式示例——做到这些之后误调用率通常会明显下降。
动态上下文:RAG、记忆、工具结果不要一股脑塞
检索什么时候做、预检索还是按需加载,前面「运行时上下文怎么加载」已经讲过了。这里只说检索结果进入窗口之后怎么处理。
短期记忆可以用滑动窗口管理,长期事实通过外部存储检索。API 报错日志、工具返回结果这类 Observation 可以先做裁剪和摘要,但排障类信息一定要保留原始引用——traceId、请求时间、错误码、日志文件位置、工具调用参数和原始结果摘要链接,这些不能丢。只留一句“接口报错了”的话后面排障会断线,但原始日志洪流直接塞进去又容易把模型淹没。
动态上下文真正容易翻车的地方通常不是“有没有检索”,而是检索错了、记忆过期了、工具超时了、摘要把证据丢了。兜底策略可以这样设计:
| 失败路径 |
典型表现 |
兜底方案 |
| RAG 无结果 |
找不到相关文档,或者召回片段太散 |
降级到关键词检索,必要时让 Agent 向用户澄清缺口 |
| 工具超时 |
外部 API 卡住,Agent 重复等待 |
设置超时、重试上限、熔断策略,关键流程预留人工接管 |
| 摘要丢失 |
压缩后缺少异常栈、版本号、边界值 |
保留 traceId、原始证据位置、关键字段和可回查链接 |
| 记忆污染 |
旧偏好、旧状态被当成当前事实 |
写入前校验,读取后标记来源、时间和可信度 |
| 多工具冲突 |
两个工具都能做,Agent 选错路径 |
用优先级、状态机和副作用等级约束调用顺序 |
示例上下文:Few-shot 示例别堆太多
Few-shot prompting 很有用,但很多人用法不对。典型错误就是往 Prompt 里塞几十个 edge case 试图覆盖所有规则,结果模型过度拟合了示例表面的写法,反而忽略了真正该学的处理逻辑。更稳的做法是选 3 到 5 个多样化的典型示例(canonical examples),每个示例代表一类标准场景,不是把所有边缘情况列全。对模型来说示例展示的是“什么情况该用什么策略”,不是“这个输入必须对应这个输出”。
Token 预算:单次调用内怎么排优先级
注意这里管的是单次调用内的优先级,不是跨窗口的历史压缩——跨窗口的问题前面「长任务里,上下文怎么撑住」里 Compaction 那节已经讲了。窗口快满的时候这两层得配合着用。
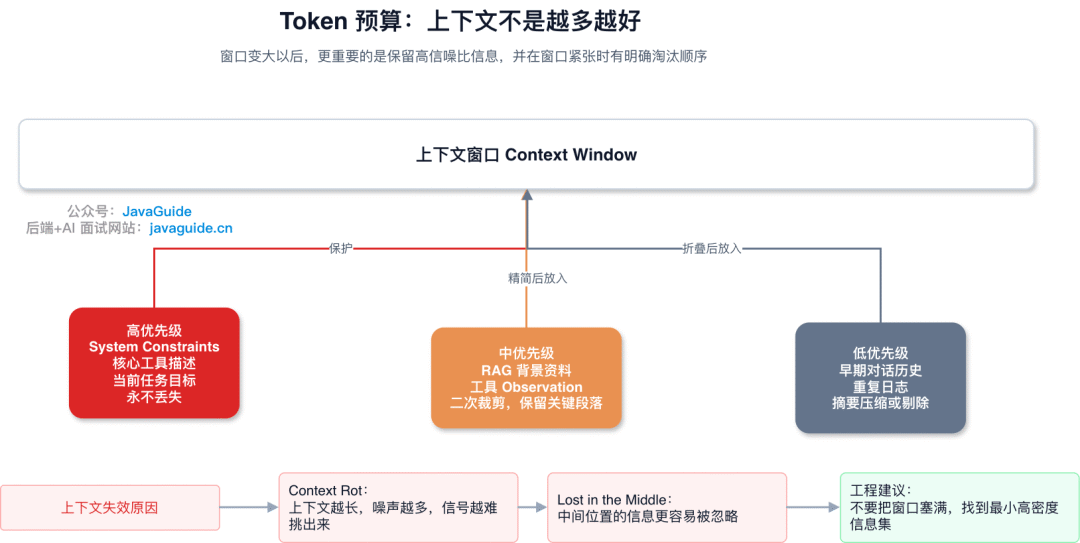
| 优先级 |
内容 |
处理方式 |
| 低优先级(可折叠) |
早期对话历史 |
AI 摘要压缩 |
| 中优先级(可精简) |
RAG 检索的背景资料、旧工具结果 |
二次裁剪,保留核心段落和可回查引用 |
| 高优先级(固定区) |
System Constraints、当前任务目标、安全边界 |
放在固定高优先级区,确保逻辑一致性 |
| 阶段性优先级 |
当前阶段需要的工具描述、Schema、少量关键示例 |
按任务阶段加载,卸载后保证可重新发现 |
大规模并发场景里还可以配合 Prompt / Context Caching。在支持缓存的模型上,稳定的 System Prompt 和工具说明可以作为缓存前缀,减少重复计费或者降低首 Token 延迟。但缓存命中不命中取决于厂商实现、前缀有没有变化、缓存生命周期这些因素,得按业务负载实测。
做 Context Engineering 会用到哪些工具?
工具这块不用一上来就堆全家桶。Context Engineering 真正落地的时候通常会碰到几类东西:编排、检索、向量库、工具接入、记忆层。它们不是同一层的工具,也不是每个项目都得全上。
简单按用途捋一下:
- 编排框架:LangChain、LangGraph 这些,主要管 Agent 的控制流、状态管理和循环调度。比如什么时候调用工具、什么时候回到上一步、状态怎么在节点之间传递。
- 数据框架:LlamaIndex 更偏 RAG,重点在数据摄取、索引构建和检索优化。如果你的问题主要是“怎么把文档整理好、检索准”,它会更贴近。
- 向量数据库:Pinecone、Weaviate、Chroma、Qdrant 这些工具负责 Embedding 存储和语义搜索。小项目本地 Chroma 就够试,企业项目再看 Qdrant、Milvus、Pinecone。
- 通信协议:MCP 解决的是工具怎么标准化接入宿主程序的问题,经常被类比成 AI 应用里的 USB-C。以 MCP 2025-03-26 规范为例,它基于 JSON-RPC 2.0,区分 Host、Client、Server,通过 Server Features 暴露 Resources、Prompts、Tools 这些能力。
- Memory 产品:Mem0、LETTA(原 MemGPT)、ZEP 这些产品主要做 Agent 记忆层,通常在向量库之上再封装记忆写入、检索、遗忘这些生命周期管理能力。
这里提一下 MCP。很多朋友一听 MCP 就觉得只是多接几个工具而已。但你想想看,工具一旦暴露给 Agent,它就不只是能力入口了,也可能变成副作用入口。读文件、查数据库、发请求、改配置,这些操作只要边界没卡住,排查起来会非常痛苦。
真正落地时,要盯住什么?
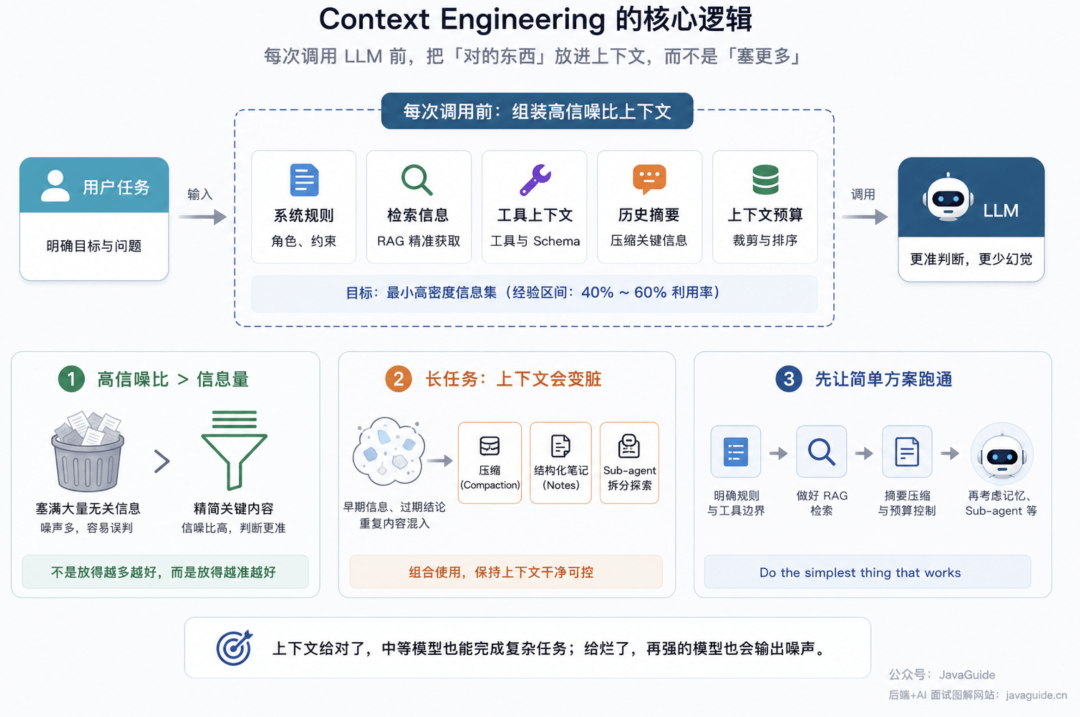
Context Engineering 做到最后,盯的不是“Prompt 写得漂不漂亮”,而是每次调用 LLM 之前窗口里到底放了什么。改一个检索策略,换一种摘要方式,调整工具 Schema 的挂载顺序,有时候效果比换模型还明显。
高信噪比比信息量更重要
宁愿上下文少一点但信噪比高一点。Dex Horthy 提到过把上下文利用率控制在 40% 到 60% 的经验区间,但这个数字不能当通用定律。真正要找的是让模型做出正确决策所需要的最小高密度信息集,而不是“反正放得下就多塞点”。窗口变大之后很多人会下意识多塞资料,噪声一多判断反而变差。
长任务里,上下文一定会变脏
这是客观规律,不是设计问题。长任务跑久了,早期判断、过期结论、已经解决的问题全会混进来,光靠“继续对话”是撑不住的。Compaction、结构化笔记、Sub-agent 要组合用,它们解决的不是同一个问题,别只押宝其中一个。但也不建议一上来就做太重——长任务还没跑起来呢就先搭复杂记忆层和检索体系,最后往往是调系统比做业务还累。
先把最简单的方案跑通
Anthropic 反复强调过一句话:do the simplest thing that works。
我见过不少团队,连基线都没跑通就开始做记忆分层、复杂检索、长期状态管理。效果不好的时候完全不知道是检索错了、摘要丢了、工具描述写歪了还是模型本身不适合——系统越复杂排查链路越长。
更实际的路线是:先把 System Prompt 和工具边界写清楚;再把 RAG 检索做准;然后加摘要压缩和上下文预算;等长任务真的遇到瓶颈了,再考虑引入记忆层、Sub-agent 或者更复杂的运行时检索。
上下文给对了,中等模型也能完成不少复杂任务。上下文给烂了,再贵的模型也会输出一堆看起来像答案的噪声。
总结
Context Engineering 还在快速演进。长上下文、Prompt Caching、工具调用、Memory、MCP、Sub-agent 这些能力都在变,具体上下文窗口、缓存规则、结构化输出和工具协议也会受模型版本、API 形态、SDK 和产品权限影响。写系统设计时,最好给关键能力加版本锚点,别把某个模型或某个客户端的实现细节当成通用规律。
Context Engineering 做的事,就是把“随手塞 Prompt”变成“有预算、有优先级、有证据链的上下文组装”。Prompt Engineering 更像是在写一条清晰指令,Context Engineering 则是在每次调用 LLM 前决定:哪些规则必须保留,哪些资料按需检索,哪些工具该挂载,哪些历史要压缩,哪些结果只留引用。它解决的是 Agent 系统里的信息供给问题。
上手最快的路径不是一开始就搭复杂记忆层,而是先把最小闭环跑起来:固定 System Prompt,定义工具边界,整理少量高质量样例,跑一组真实任务轨迹,再逐步加 RAG、摘要压缩、缓存、工具检索和长任务持久化。核心概念已经足够稳定了,先让上下文可观察、可评估、可迭代,比一上来追求“大而全”的上下文系统更重要。
参考
- Effective context engineering for AI agents - Anthropic [2]
- OpenAI API Models Compare [3]
参考资料
[1] Agent Skills 是什么?和 Prompt、MCP 到底差在哪?: https://javaguide.cn/ai/agent/skills.html
[2] Effective context engineering for AI agents - Anthropic: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[3] OpenAI API Models Compare: https://developers.openai.com/api/docs/models/compare
 发表于 2026-5-25 04:12:19
|
查看: 78|
回复: 0
发表于 2026-5-25 04:12:19
|
查看: 78|
回复: 0
