过去半年,AI 编程 Agent 的榜单几乎每天都在刷新:今天是 Claude Code 独领风骚,明天 Cursor 就完成反超,后天 OpenAI Codex 又杀了回来。
那么,究竟谁才是最强的 AI 编程 Agent?
Artificial Analysis 近期公布了一份横向评测报告。不同于单纯比拼分数的榜单,他们从性能、Token 消耗、成本、执行时间四个维度,对 Claude Code、Cursor CLI、OpenAI Codex、Google Gemini CLI 等主流 Agent 做了全面测评。

AI 制作的视频概要,可参考:不写一行代码,Claude Code/Codex 也能出专业视频~
评测体系由三项基准组成:
- 模拟真实 Bug 修复的 SWE-Bench-Pro-Hard-AA
- 考察终端工具链使用的 Terminal-Bench v2
- 测试代码库理解能力的 SWE-Atlas-QnA
1、综合排名
下面是全部 Agent 的综合指数排名,差距并不大,第一名和第三名只差 1 分——三家几乎平手。
继续卷性能分数的意义正在快速递减,真正的竞争已转移到成本、速度和生态上。
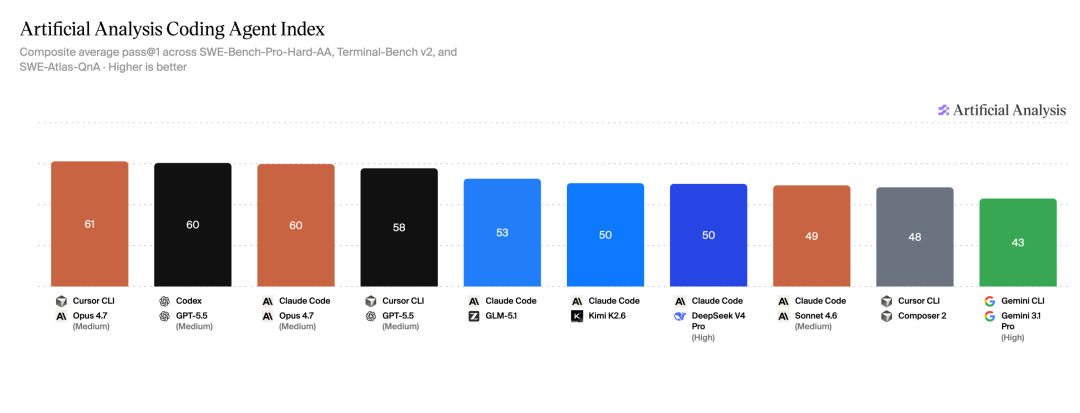
第一名 Cursor CLI + Opus 4.7 以 61 分 领先,但 Codex(GPT-5.5)和 Claude Code(Opus 4.7)均为 60 分,头部格局已经内卷到毫厘之差。
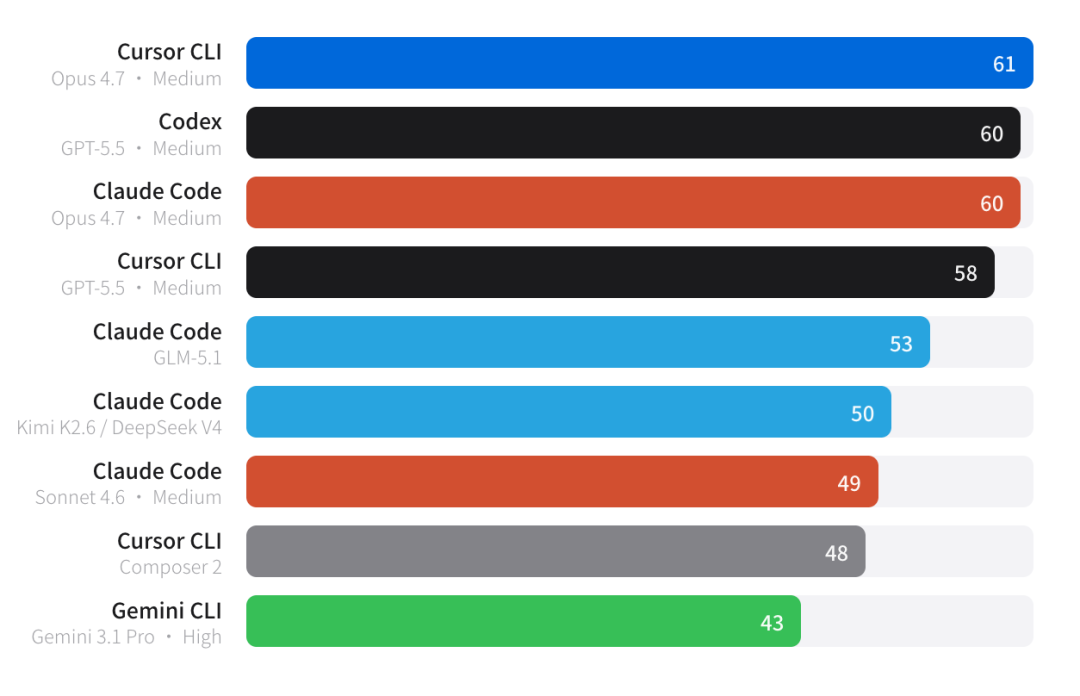
把 Claude Code 底层从 Sonnet 4.6 升级到 Opus 4.7,分数从 49 跳到 60,直接拉升 11 分。
纠结用哪个客户端,不如先想清楚用哪个模型。
2、Token 消耗
Token 用量直接影响成本与速度,绝大多数消耗来自缓存命中(这部分会显著压低实际费用)。
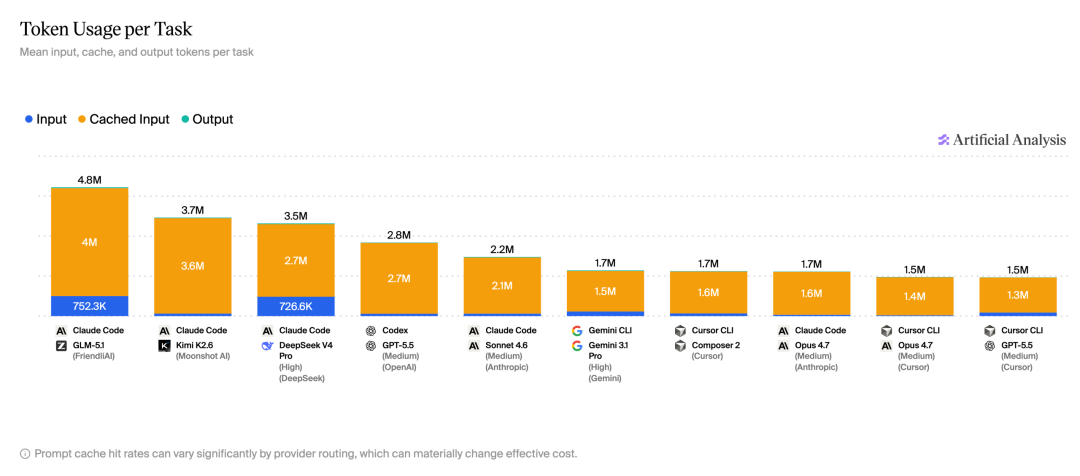
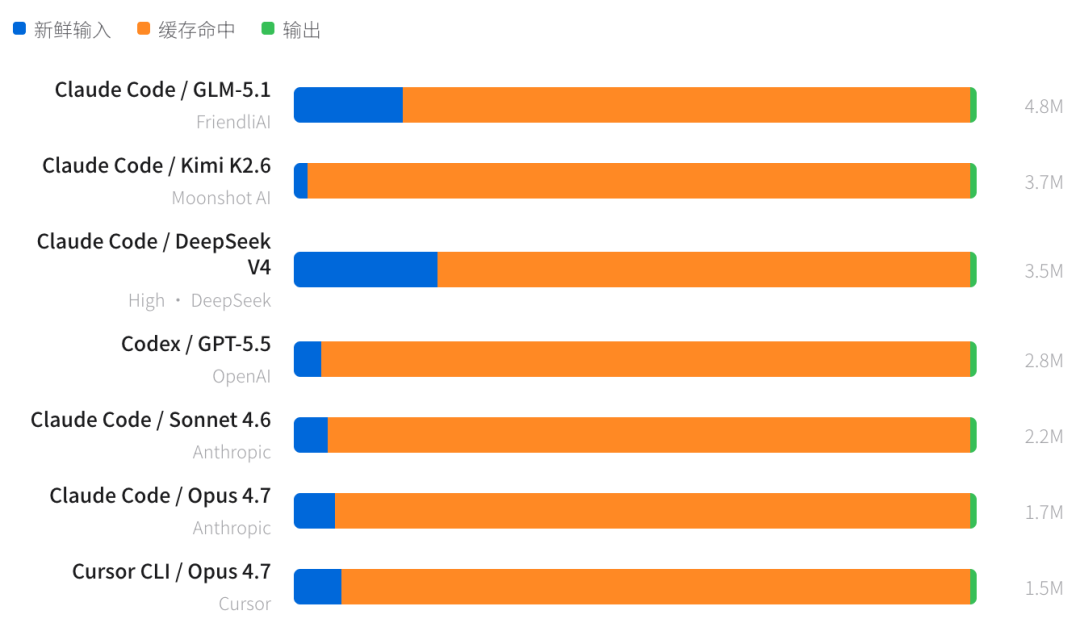
最耗 Token 的 Claude Code + GLM-5.1 达到 4.8M / 任务,是 Cursor CLI + Opus 4.7(1.5M)的 3 倍多。
在分数相近的情况下,选对配置,成本可以差出一个量级。
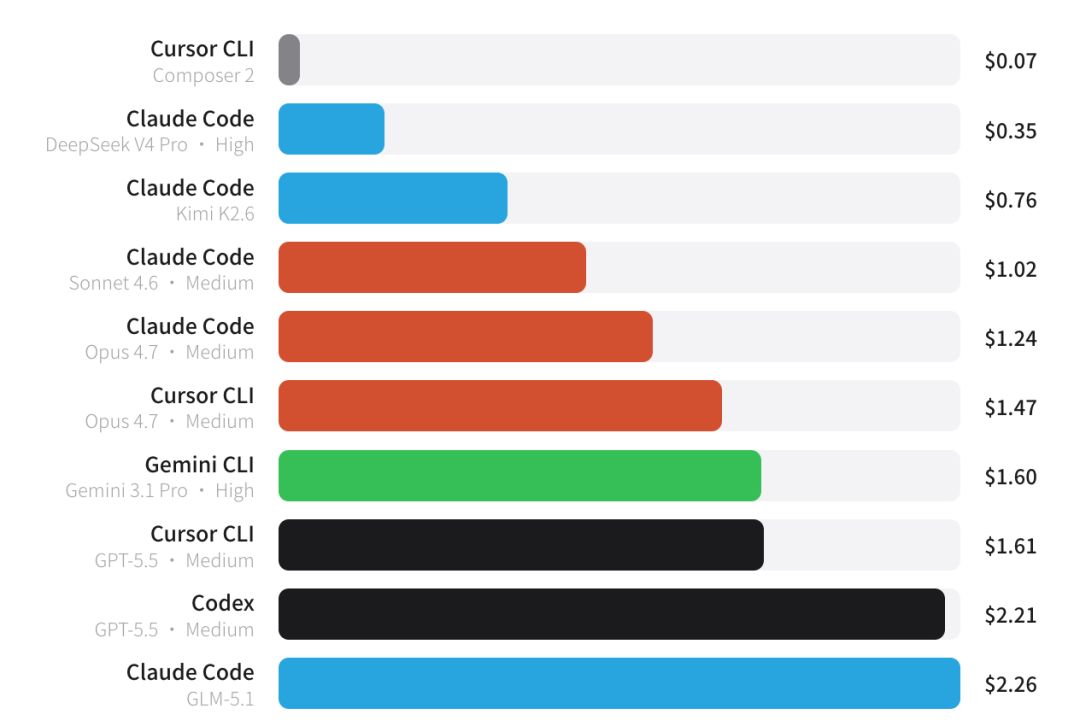
3、每任务成本
最便宜的 Cursor CLI + Composer 2 仅需 $0.07 / 任务,而最贵的 Claude Code + GLM-5.1 高达 $2.26,相差整整 32 倍。
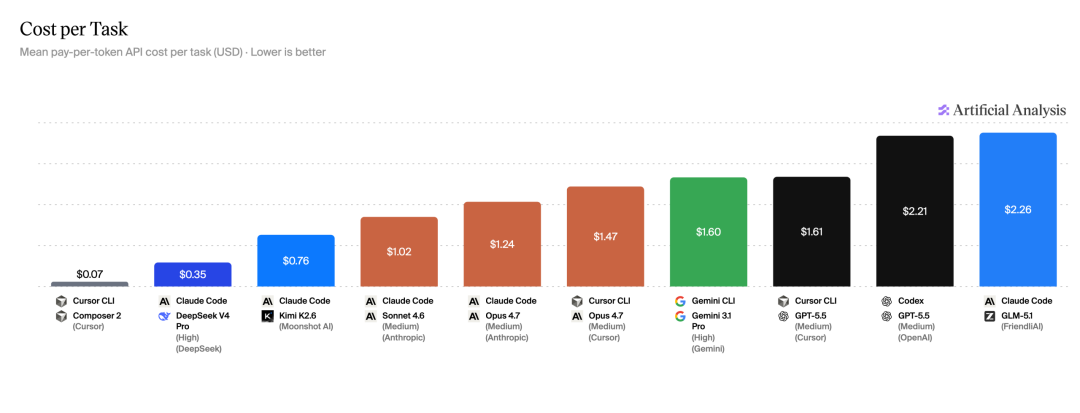
Claude Code + DeepSeek V4 Pro 用 $0.35 拿到 50 分,而 Codex + GPT-5.5 花了 $2.21 才拿到 60 分——前者只花了六分之一的钱,达到了 83% 的性能。
低成本真的可以不低分。
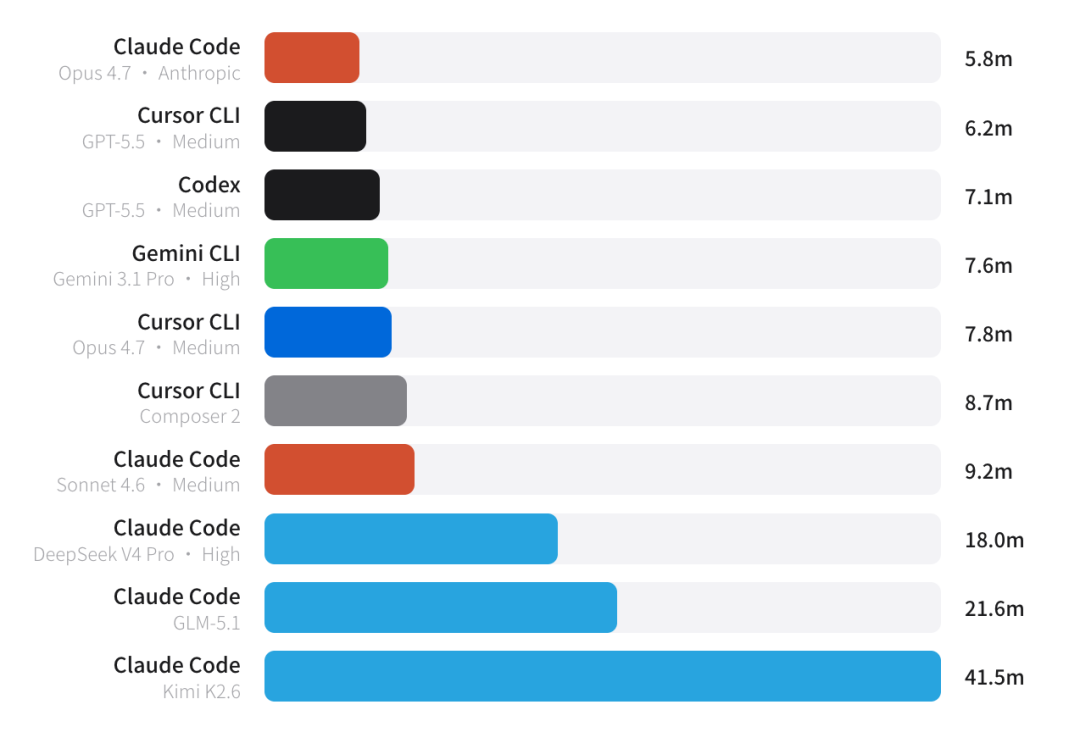
4、执行时间
最快的 Claude Code + Opus 4.7(Anthropic 直连)仅需 5.8 分钟 / 任务,综合指数同时达到 60 分——又快又准。
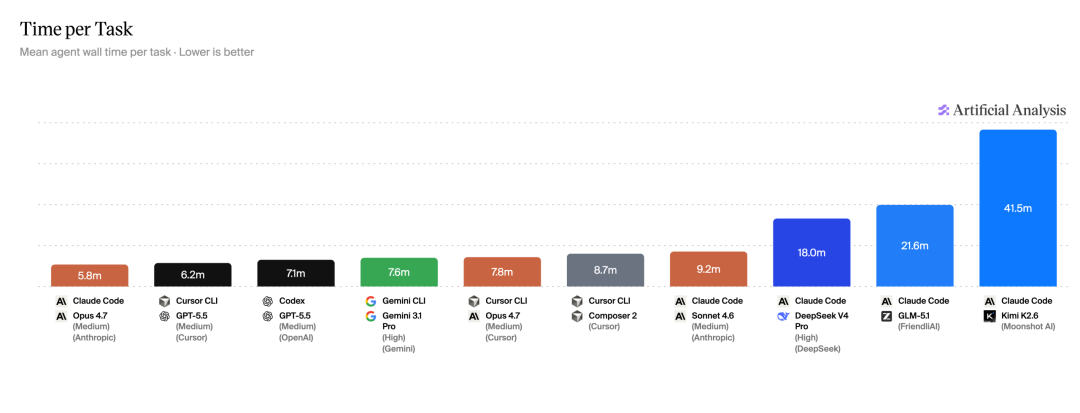
而 Claude Code + Kimi K2.6 需要 41.5 分钟,是前者的 7 倍多,且分数同样是 50 分,性价比明显吃亏。
这背后很可能是推理调用链路较长、API 响应延迟偏高所致。
对于高频迭代场景,等待成本不可忽视。
这次评测最令人惊喜的发现:DeepSeek V4 Pro、Kimi K2.6、GLM-5.1 全部登上了榜单,它们以 Claude Code 为框架底座,在真实软件工程任务上展现出了实战级别的能力。

DeepSeek V4 Pro 用 $0.35 / 任务拿到 50 分,相比 Opus 4.7 方案节省近四分之三费用,性能损耗仅约 17%,在预算敏感的企业或高频调用场景下,这个组合极具竞争力。
现在 AI 编程的头部已内卷到极致,前三名差距只有 1 分,继续卷综合指数意义不大,未来的分水岭也许在成本效率与延迟。
国产模型作为底座潜力可期,但代价不低:Kimi K2.6 和 GLM-5.1 作为 Claude Code 底座,分数达 50-53,不算差——但 Token 消耗最高、耗时最长,实际使用体验需谨慎权衡。
DeepSeek V4 Pro 是最值得关注的性价比选项:$0.35 / 任务,综合指数 50 分——成本只有 Opus 4.7 的三分之一,性能进入第二梯队。
本次评测数据来源于 Artificial Analysis,更多 AI 编程工具测评与深度解析,欢迎访问 云栈社区。
参考:https://artificialanalysis.ai/agents/coding-agents
 发表于 2026-5-25 04:47:33
|
查看: 671|
回复: 0
发表于 2026-5-25 04:47:33
|
查看: 671|
回复: 0
