这两天有不少同学问我:“怎么才能构建一个好的 skill?”
于是就有了这篇文章。内容会比较长,但看完之后,你对 skill 的认知应该会上一个台阶。
整篇文章会依次讲解:
- 第一:skill 到底是什么?
- 第二:定义 skill 要特别注意什么?
- 第三:拆解 skill-creator 的架构方案
- 第四:手写一个 AI 应用求职诊断 skill
- 第五:如何验证 skill
skill 到底是什么?
很多同学会把 skill 理解成一个高级 Prompt。大概就是写一大段背景,给 AI 安一个身份,告诉它“你现在是某某专家”,然后指望它从此稳定、专业、懂事。
看着好像挺合理,但根本不对。
Prompt 更像一次对话里的临时指令,本次会话结束,Prompt 的生命周期也就结束了。
而 skill 更像给 Agent 装上的一整套“工作习惯”。它不光告诉 AI “你要怎么回答”,而是告诉 AI:遇到这类任务时,怎么判断边界、查什么资料、调用什么脚本、遵守什么约束、最后用什么标准检查结果。
skill 看着要复杂很多,但一个最小版本的 skill,其实只需要一个 SKILL.md 文件。结构大致长这样:
my-skill/
└── SKILL.md
这里的 SKILL.md 一般包含两大块。我们以之前做过的「校招.skill」为例来看下。

红框 里的是 frontmatter,一小段 YAML。
---
name: skill 的名字
description: 当用户想要做特定的事情时使用
---
绿框 里面的是正文(body),这是 Agent 真正开始工作以后要读的操作说明。
正文里主要包含 4 部分内容:

它们分别是什么意思,暂时不重要(后面会展开讲)。
很多同学看到这里可能会问:“这不还是 Prompt 吗?只不过是一个更复杂的 Prompt 了。” 表面看着确实有点类似,但区别在于:skill 可以拥有 触发机制、文件结构、按需加载、资源分层和脚本兜底 的能力。
来看一个更完整的 skill 目录结构:
my-skill/
├── SKILL.md
├── agents/
│ └── openai.yaml
├── references/
├── scripts/
└── assets/
还是以「校招.skill」为例,看下它的真实目录:
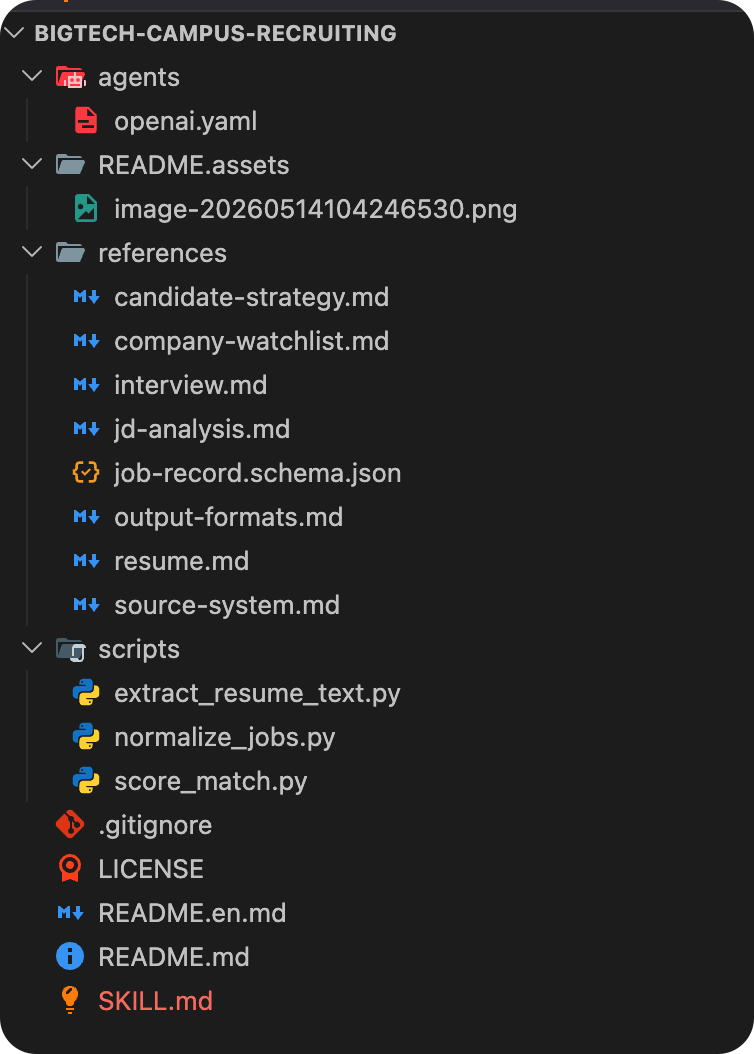
咱们逐一拆解这些文件夹是干什么的:
agents/openai.yaml
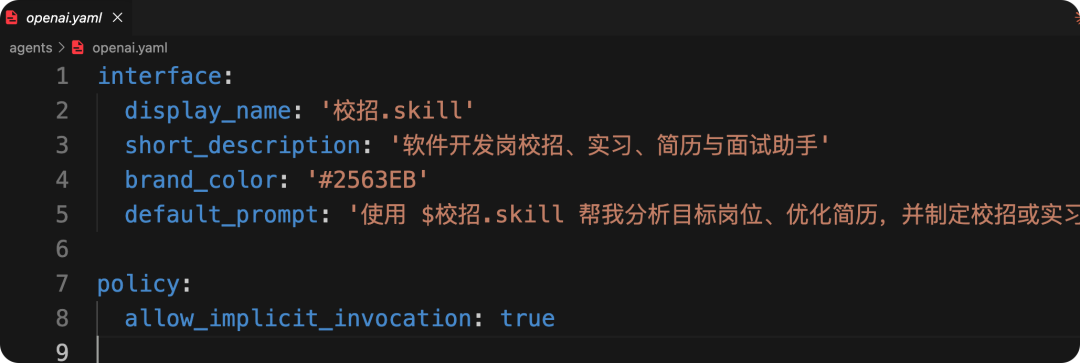
它通常被叫做“名片”。顾名思义,就是展示当前 skill 基本信息的元数据。
references
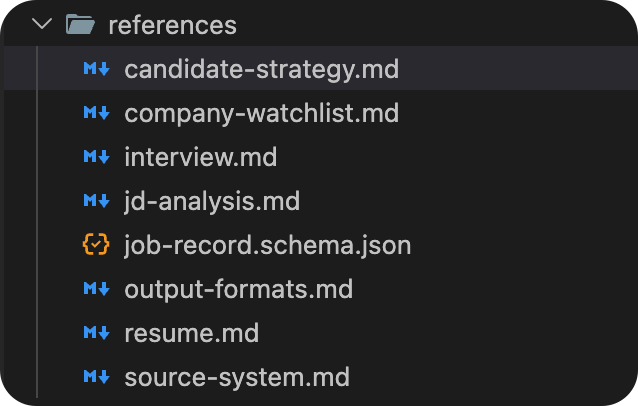
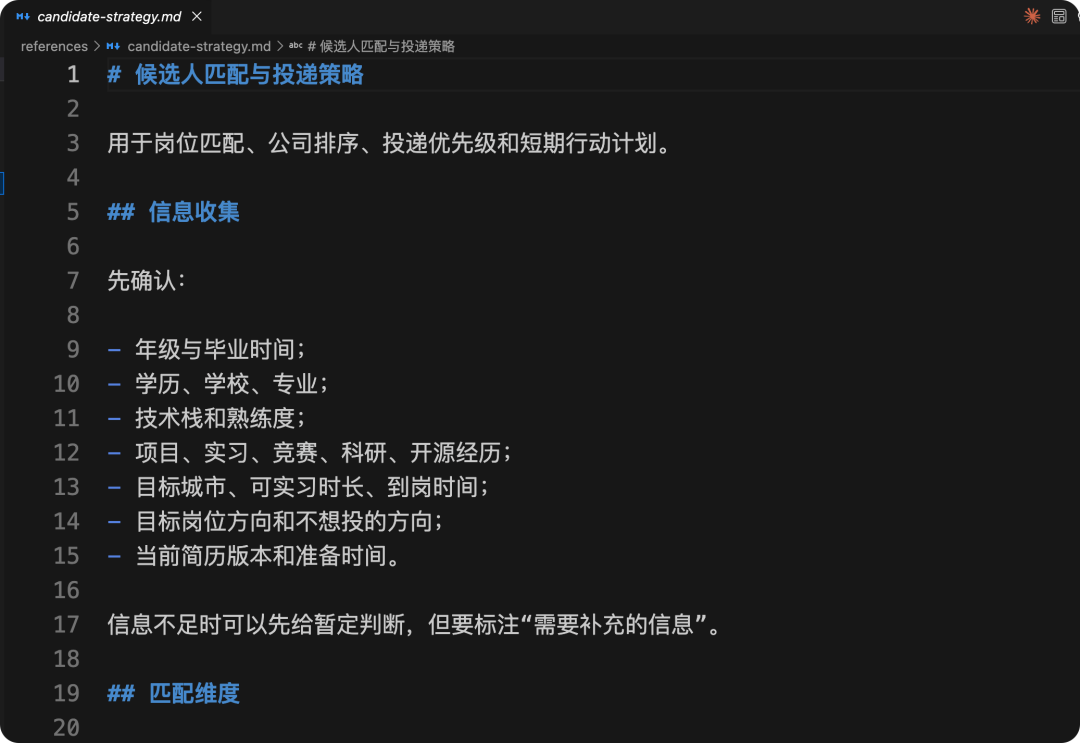
当前 skill 的详细资料库,内容通常由各种 .md 文件组成。每个文件中都存放着更细致的约束词。可以简单看下 candidate-strategy.md:
scripts
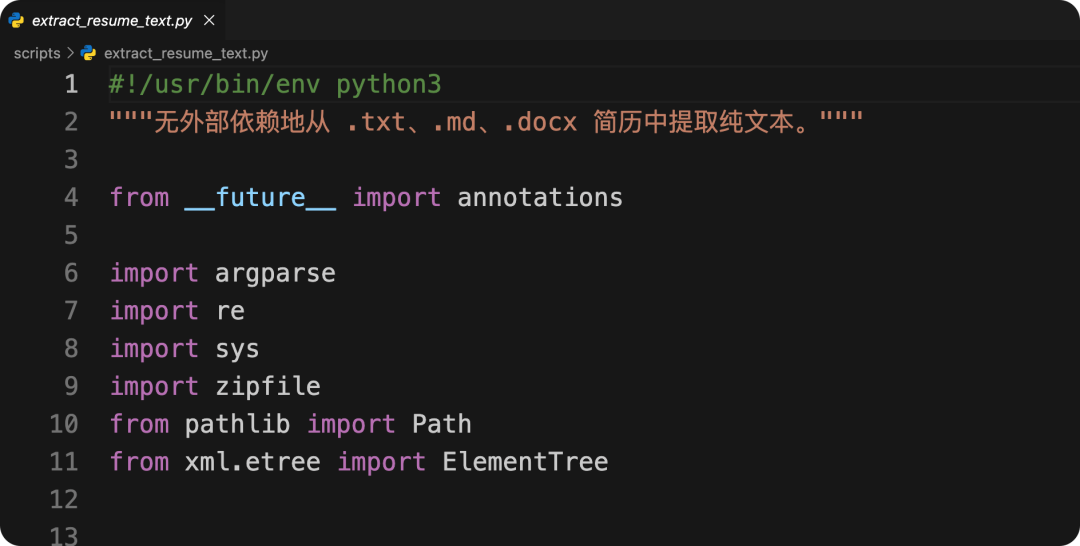
这里会涉及一些代码,主要处理逻辑问题,比如:格式转换、校验、解析、标准化等等。以「校招.skill」为例,因为会涉及到用户简历的读取,所以需要有对应的解析逻辑。比如 extract_resume_text.py 就可以提取简历中的纯文本:
assets
咱们这里没用到。如果有的话,就是放一些图片、字体、样例工程之类的东西。
SKILL.md
前面已经说过,这是整个 skill 的入口,负责告诉 Agent 什么时候触发、触发后怎么开始执行。
纵观全貌,你应该能感觉到:一个完整的 skill 比 Prompt 要严谨得多。如果要给 skill 下一个更完整的定义,那应该是——一个 skill 的本质,是一套可复用的任务执行系统。
它至少能回答以下五个问题:
- 用户说什么话时,应该触发这个 skill?
- 这个 skill 负责什么,不负责什么?
- 任务来了以后,Agent 应该按什么路线处理?
- 哪些资料需要按需读取?
- 哪些动作必须用脚本保证稳定?
所以,我们说 skill 是一个让 Agent 解决某一类问题的 “技能”。
定义 skill 要特别注意什么?
很多同学第一次写 skill 时,会写成这样:
# 简历优化助手
name: 简历优化
description: 你是一个专业、耐心、有经验的简历优化专家。你需要帮助用户优化简历,让简历更有竞争力。
这句话单独看好像没什么问题。但如果你仔细分析,会发现里面全是正确的废话。比如:“专业”是什么?“有竞争力”怎么判断?
好的 skill 要给出完整的行动路径,比如:
# 简历优化助手
name: 简历优化助手
description: 当用户要求为实习、校园招聘或工作申请查看、诊断、重写或定制软件工程简历时使用。
然后在正文里写清楚具体的操作指南:
# 简历优化助手
## 原则
- 确保所有重写的内容保持真实。
- 不要发明工具、指标、雇主、奖项或项目成果。
- 用占位符标记缺失的事实。
- 在润色措辞之前,优先解决阻碍性的问题。
## 工作流程
1. 确定目标职位和候选人背景。
2. 提取简历中的各个部分。
3. 根据问题的严重程度进行诊断。
4. 除非用户要求直接重写,否则仅在诊断后进行重写。
5. 将已确认的事实与建议的占位符区分开来。
需要牢记一点:skill 是给 Agent 看的,不是给人看的。 所以不能套用写技术文档的老思路,必须给 Agent 一个非常具体的思考路径和工作流程。
同时切记:每个 skill 只需解决一类问题。比如你想做一个“求职助手”的 skill,希望用它解决所有找工作的问题。你觉得可行吗?绝对不行。 因为这太庞大了。找工作,可以是校招、社招,甚至可以是被猎头挖走。不要妄想用一个 skill 来 cover 所有场景。
更好的方式是,从一个细分领域切入。你可以参考下面这些具体任务的描述:
- 我 27 届,想找前端暑期实习,现在还有哪些公司能投?
- 帮我看看这个 AI 应用开发 JD,我适合吗?
- 这段项目经历怎么改得更像大厂实习简历?
- 腾讯校招技术面一般会问什么?
- 我有 React 和 RAG 项目,投 AI 全栈合适还是前端合适?
你看,每一条都是一个极其具体的任务。
咱们还是以「校招.skill」为例,这就是一个非常具体的细分领域。仔细看它的 description:

你看,这里是多么具体的场景。接下来,它在正文里做了四件事。


这里把任务分成了几个模块:
当前岗位检索
公司招聘流程查询
岗位匹配与投递策略
JD 分析
简历诊断与改写
面试准备与模拟面试
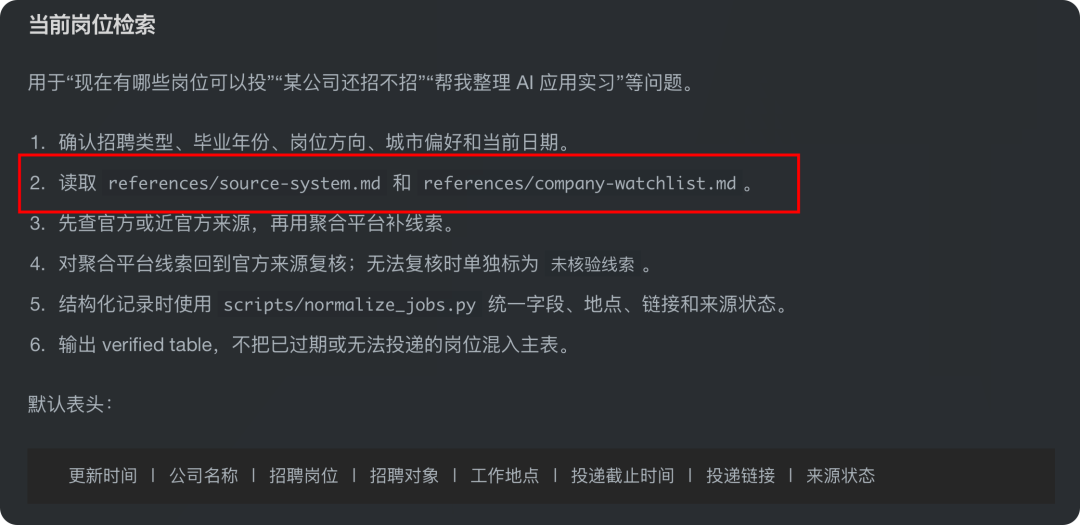
每个模块下面都会明确告诉 Agent 具体读哪个文件、按什么步骤输出。比如:岗位检索,会读取信息源系统和公司池,再优先查官方来源,最后用标准化脚本整理字段。
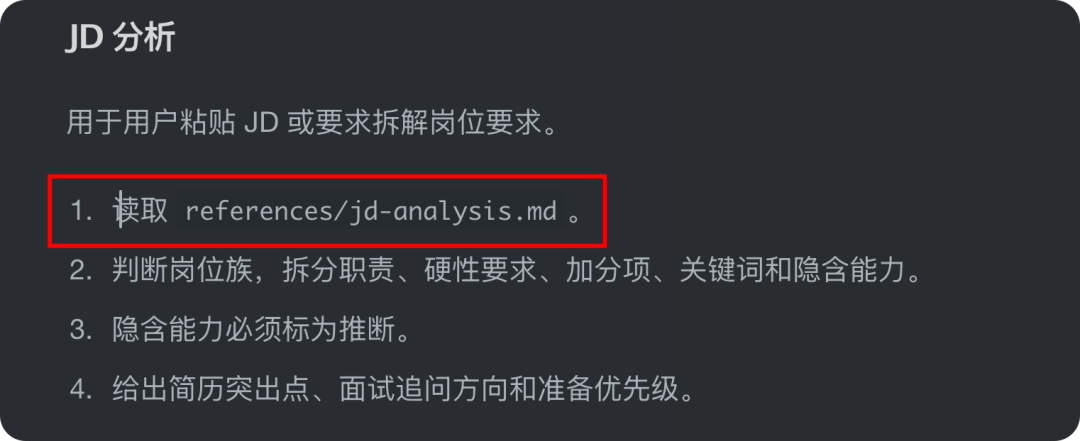
再比如 JD 分析,会读取 jd-analysis.md,区分 JD 明示内容和经验推断。
又比如岗位匹配,会在有结构化数据时调用 score_match.py 做辅助评分。
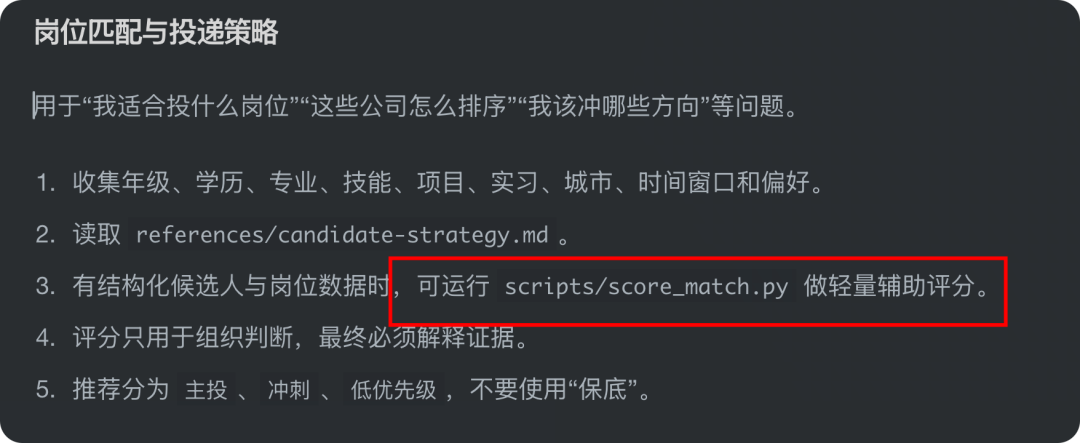

我们把资料拆到了 references/ 里,涉及:信息源分级、候选人策略、JD 分析、简历、面试、输出模板及岗位记录 schema。同时,把确定性动作放进 scripts/,比如 normalize_jobs.py 负责将岗位 JSON 标准化成 Markdown 表格。
这就是一个成熟 skill 该有的样子。
拆解 skill-creator 的架构方案
skill-creator 是一个自带的,用来创建 skill 的 skill。Codex 和 CC 中均有。
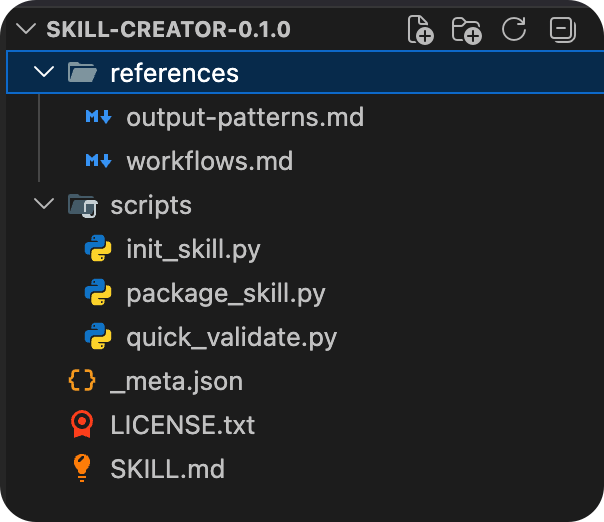
如果说 校招.skill 是一个业务型 skill,那 skill-creator 就是一个元 skill。它的设计很有意思,我们先看整体架构图,再详细讲解:
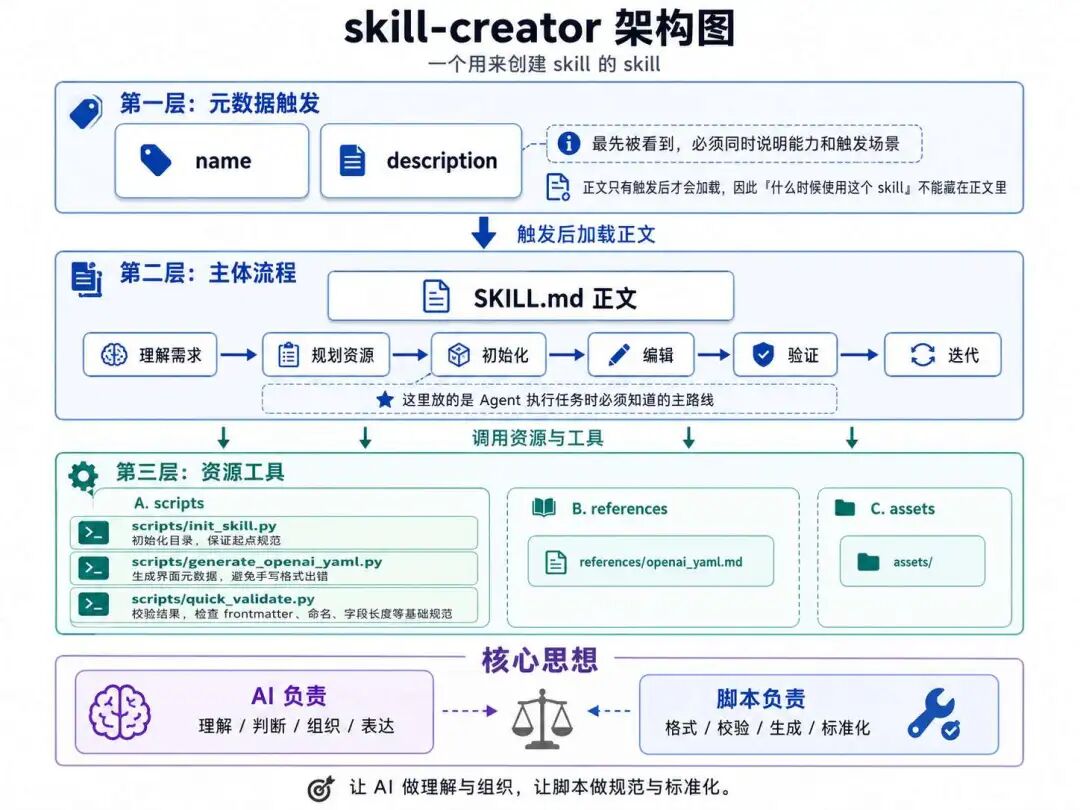
整体架构可以理解成三层。
第一层,元数据触发


name 和 description 是最先被看到的部分。尤其是 description,要同时说明能力和触发场景。因为正文只有在触发后才加载,所以“什么时候使用这个 skill”绝不能藏在正文里。
第二层,主体流程
SKILL.md 正文负责描述创建 skill 的整个流程:理解需求、规划资源、初始化、编辑、验证到迭代。这里存放的是 Agent 执行任务时的“主路线”。
第三层,资源工具
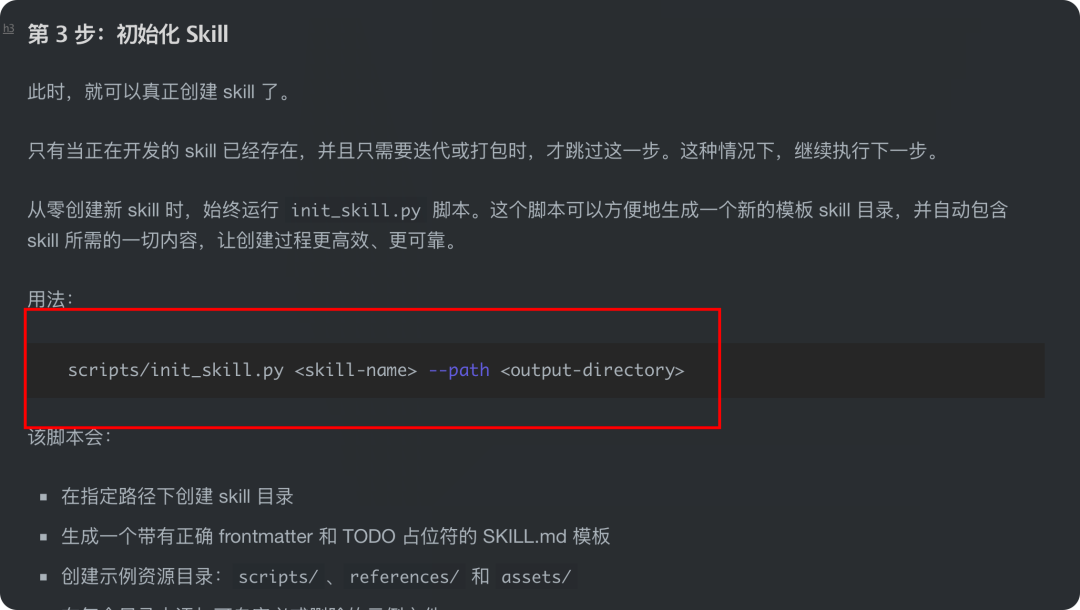
skill-creator 自带脚本和参考资料。比如:
scripts/init_skill.py
scripts/package_skill.py
scripts/quick_validate.py
references/openai_yaml.md
assets/
这里最关键的脚本有三个:
init_skill.py:初始化目录,保证起点规范。
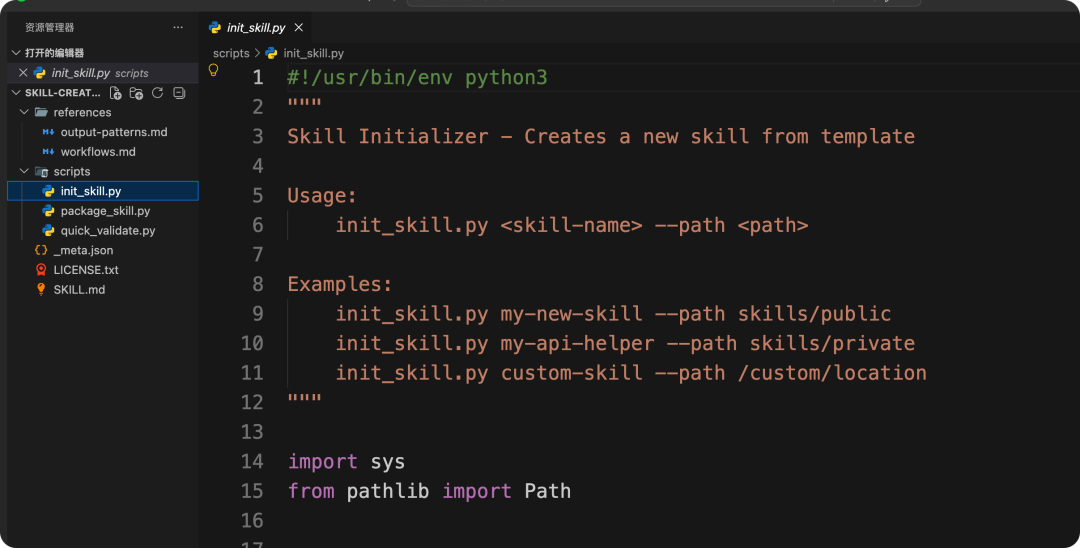
package_skill.py:技能打包器,用于创建可分发的 .skill 文件。
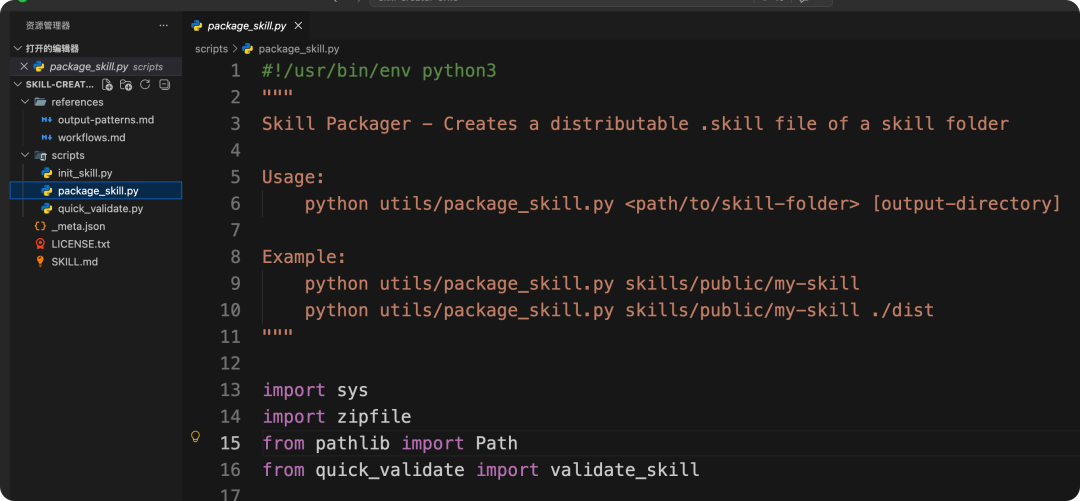
quick_validate.py:校验结果,检查 frontmatter、命名、字段长度等基础规范。
这套设计的核心思想可以概括为:
- 让 AI 负责理解、判断、组织、表达。
- 让脚本负责格式、校验、生成、标准化。
这,就是 skill-creator 真正值得借鉴的地方。
写一个 AI 应用求职诊断 skill
光讲方法论难免枯燥。咱们直接做一个小实战。
假设我要写一个 skill,叫 ai-internship-coach。目标是 帮助用户分析 AI 应用开发实习岗位的 JD、评估简历匹配度并制定准备计划。在这种场景下,我们得优先思考用户会怎么触发它——也就是我最喜欢的 “倒推法”。
使用这个 skill 时,用户大概率会这样问:
我 27 届,做过一个 RAG 项目,帮我看看这个 AI 应用开发实习适不适合投。
这个 JD 要求 LangChain、向量数据库、Prompt 优化,我简历应该怎么改?
下周面试 AI 全栈实习,帮我根据项目准备追问。
看到这些请求,边界就清晰了。这个 skill 不处理所有求职问题,它专攻 AI 应用、LLM 应用、RAG、Agent、AI 全栈相关实习。它也不替用户编简历,只是基于真实经历进行诊断、改写和准备。
明确这些概念后,我们就能进行目录设计:
ai-internship-coach/
├── SKILL.md
├── references/
│ ├── jd-analysis.md
│ ├── resume-signals.md
│ └── interview-plan.md
└── scripts/
└── score_fit.py
SKILL.md 可以这样写:
---
name: ai-internship-coach
description: 当用户要求分析AI应用、大型语言模型(LLM)应用、检索增强生成(RAG)、代理或AI全栈实习岗位时,将简历与职位描述(JD)进行匹配,重写真实的简历要点,或准备AI应用工程实习面试。
---
# AI 实习教练
帮助用户评估 AI 应用方向的实习机会,优化真实可信的简历定位,并准备面试。
## 原则
- 区分 JD 中的事实信息和推断出的岗位期望。
- 不编造项目指标、工具、雇主、奖项或结果。
- 用占位符标记缺失信息。
- 优先使用用户简历、项目经历和 JD 文本中的证据。
- 如果用户询问当前开放岗位,需通过官方或接近官方的来源进行核验。
## 工作流
1. 识别任务类型:JD 分析、简历匹配、简历改写,或面试准备。
2. 如果是 JD 分析,读取 `references/jd-analysis.md` 。
3. 如果是简历匹配,读取 `references/resume-signals.md` 。
4. 如果存在结构化输入,运行 `scripts/score_fit.py` 。
5. 如果是面试准备,读取 `references/interview-plan.md` 。
6. 分别输出事实、推断、风险和建议。
## 输出规则
- 将已确认事实与推断出的岗位期望分开呈现。
- 改写简历要保持真实性。
- 对缺失指标使用占位符。
- 将面试问题与用户的真实项目经历关联起来。
这里有几点需要注意:
- 第一:
description 里必须写触发场景。 不要只写个“AI 实习助手”,因为 Agent 就是靠这个决定什么时候激活它的。
- 第二:正文里先写原则。 这类任务很容易出问题,尤其是简历改写。用户没说自己用过 LangChain,你就不能硬塞。这点至关重要。
- 第三:写
workflow。 Agent 看到用户贴 JD,就读 jd-analysis.md;看到贴简历,就读 resume-signals.md;看到要面试,就读 interview-plan.md;有结构化输入,再跑 score_fit.py。
定义好入口的 SKILL.md 之后,我们再去写 references 下的文件。比如:references/jd-analysis.md:
# JD 分析
按照以下顺序分析 AI 应用方向实习 JD。
1. 识别岗位类型:RAG、Agent、LLMOps、AI 全栈、数据应用,或平台工程。
2. 提取显性要求:编程语言、框架、模型 API、向量数据库、后端、前端、部署、评测。
3. 提取约束条件:毕业年份、工作地点、实习时长、是否要求到岗办公。
4. 推断隐含期望,并明确标记为「推断」。
5. 将岗位要求映射到简历证据。
6. 列出准备优先级。
常见隐含期望。
- RAG 岗位通常关注检索质量、切片策略、评测和失败案例分析。
- Agent 岗位通常关注工具调用、工作流编排、状态管理和错误恢复。
- AI 全栈岗位通常关注产品理解、API 集成、前端交互和后端可靠性。
这份 reference 的目的,就是把 JD 的分析路径固化下来。
然后是 references/resume-signals.md:
# 简历信号
AI 应用方向实习的强证据。
- 端到端 AI 应用项目。
- 包含检索、切片、重排序或评测的 RAG 链路。
- 包含工具调用、状态管理或错误恢复的 Agent 工作流。
- 与 FastAPI、Node.js、Java 或 Go 的真实后端集成。
- 使用 React、Vue 或小程序实现前端交互。
- 部署、监控、成本控制、延迟优化,或用户反馈。
改写约束。
- 不添加用户没有提到过的工具。
- 除非用户提供,否则不添加指标。
- 当数据缺失时,使用 `[真实指标]` 或 `[请确认]` 这类占位符。
- 优先采用「动作、技术决策、结果」的结构。
最后是脚本。score_fit.py 不用一上来就写得复杂,第一版可以只做很朴素的关键词匹配:
#!/usr/bin/env python3
import json
import sys
# 定义 AI 应用实习岗位相关的关键词信号。
# 每个 key 表示一个能力方向,每个 value 是该方向下的一组关键词。
# 后续会用这些关键词去匹配用户输入内容,从而判断简历或 JD 中体现了哪些能力信号。
SIGNALS = {
# RAG 相关信号:
# 如果文本中出现 RAG、向量数据库、检索、召回、rerank、embedding 等词,
# 说明内容可能涉及 RAG 检索增强生成能力。
"rag": ["RAG", "向量数据库", "检索", "召回", "rerank", "embedding"],
# Agent 相关信号:
# 如果文本中出现 Agent、工具调用、function calling、workflow、状态管理等词,
# 说明内容可能涉及 Agent 工作流、工具调用或状态维护能力。
"agent": ["Agent", "工具调用", "function calling", "workflow", "状态管理"],
# 后端相关信号:
# 如果文本中出现 FastAPI、Node.js、Java、Go、API、数据库等词,
# 说明内容可能涉及后端开发、接口设计或数据存储能力。
"backend": ["FastAPI", "Node.js", "Java", "Go", "API", "数据库"],
# 前端相关信号:
# 如果文本中出现 React、Vue、小程序、TypeScript 等词,
# 说明内容可能涉及前端页面开发、交互实现或前端工程化能力。
"frontend": ["React", "Vue", "小程序", "TypeScript"],
# 评估与工程优化相关信号:
# 如果文本中出现评估、准确率、召回率、latency、成本等词,
# 说明内容可能涉及模型效果评估、性能优化、成本控制等工程化能力。
"evaluation": ["评估", "准确率", "召回率", "latency", "成本"]
}
def main():
"""
主函数:
负责读取输入、执行关键词匹配、计算匹配等级,并输出最终 JSON 结果。
输入:
从标准输入读取一段 JSON 数据。
这段 JSON 可以是 JD、简历信息、项目描述等结构化内容。
输出:
一个 JSON 对象,包含:
- fit_level:匹配等级,可能是 strong / medium / weak
- matched_signals:命中的能力方向和对应关键词
"""
# 从标准输入中读取 JSON 数据,并解析成 Python 对象。
# 例如外部可以这样调用:
# echo '{"project": "我做过 RAG 和 Vue 项目"}' | python3 score_fit.py
#
# json.load(sys.stdin) 会直接读取标准输入中的完整 JSON。
payload = json.load(sys.stdin)
# 将输入的 Python 对象重新转成字符串,方便后续做关键词匹配。
#
# ensure_ascii=False 的作用:
# 默认情况下,json.dumps 会把中文转成 Unicode 编码,例如:
# "检索" 可能会变成 "\u68c0\u7d22"。
#
# 设置 ensure_ascii=False 后,可以保留原始中文字符,
# 这样后续用中文关键词匹配时更直观、更稳定。
text = json.dumps(payload, ensure_ascii=False)
# 用于保存匹配到的信号。
#
# 结构示例:
# {
# "rag": ["RAG", "检索"],
# "frontend": ["Vue", "TypeScript"]
# }
#
# key 是能力方向,value 是该方向下命中的关键词列表。
matched = {}
# 遍历所有能力方向及其对应的关键词列表。
#
# group 表示能力方向,例如 rag、agent、backend。
# words 表示该方向下的一组关键词。
for group, words in SIGNALS.items():
# 对当前能力方向下的所有关键词进行匹配。
#
# word.lower():
# 把关键词转成小写。
#
# text.lower():
# 把输入文本也转成小写。
#
# 这样可以实现大小写不敏感匹配。
# 例如 "RAG"、"rag"、"Rag" 都可以被匹配到。
#
# 注意:
# 这种匹配方式是简单的子字符串匹配。
# 只要关键词出现在文本中,就会认为命中。
hits = [word for word in words if word.lower() in text.lower()]
# 如果当前能力方向下有至少一个关键词命中,
# 就把这个能力方向和对应命中的关键词保存到 matched 中。
if hits:
matched[group] = hits
# 根据命中的能力方向数量计算分数。
#
# 注意:
# 这里统计的是命中的“能力方向数量”,不是关键词数量。
#
# 例如:
# matched = {
# "rag": ["RAG", "检索", "embedding"],
# "frontend": ["Vue"]
# }
#
# 虽然一共命中了 4 个关键词,
# 但是只覆盖了 rag 和 frontend 两个方向,
# 所以 score = 2。
score = len(matched)
# 根据 score 判断匹配等级。
#
# 命中 4 个及以上能力方向:
# 说明该简历或 JD 覆盖面较完整,匹配度强。
#
# 命中 2 到 3 个能力方向:
# 说明具备一定相关性,但可能不够全面。
#
# 命中 0 到 1 个能力方向:
# 说明 AI 应用实习相关信号较弱。
if score >= 4:
level = "strong"
elif score >= 2:
level = "medium"
else:
level = "weak"
# 将最终结果以 JSON 格式输出到标准输出。
#
# 输出字段:
# - fit_level:匹配等级
# - matched_signals:具体命中的能力方向和关键词
#
# ensure_ascii=False:
# 保留中文字符,不转义成 Unicode。
#
# indent=2:
# 让输出结果格式化为 2 个空格缩进,便于阅读。
print(json.dumps({
"fit_level": level,
"matched_signals": matched
}, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
这个脚本不替 Agent 做最终决策,它只负责提供辅助评分。比如命中 Python、React、RAG、Agent、向量数据库、项目上线、用户指标等,就给出结构化的参考结果。最终的判断和解释,依然由 Agent 完成。
我们现在拿一个真实请求跑一下:
我是 27 届,做过一个 RAG 知识库项目,用 React 做过前端,用 FastAPI 做过接口。这个岗位要求 LangChain、向量数据库、Prompt 优化、每周 4 天到岗。帮我看看适不适合投。

一个好的 skill 回答,大抵就是这个样子的。
通过 skill-creator 创建
看到这里,可能有同学会问:“不是有 skill-creator 吗,我还需要自己写这些文件?”坦率地讲,不一定。如果你已经对 skill 的结构烂熟于心,当然可以手写。但对大多数同学来说,手写代码还是比较枯燥的。
所以,更简单的路径是:先用 skill-creator 生成标准骨架,再人工进行内容填充。skill-creator 最大的价值就是处理好 目录结构、frontmatter、基础资源、校验流程 这些容易出错的地方,解决的是“起点规范”的问题。
我们可以直接这样和 Agent 说:
使用 skill-creator,帮我创建一个 skill。
skill 名称叫 ai-internship-coach。
这个 skill 用于 AI 应用开发实习求职诊断,主要处理:
1. AI 应用、RAG、Agent、LLM 应用、AI 全栈相关实习 JD 分析
2. 候选人简历和 JD 的匹配度判断
3. 基于真实经历的简历改写建议
4. 面试准备和项目追问
请创建 SKILL.md,并规划 references 和 scripts。
需要特别注意:
- 不要编造用户没有提供的经历、工具、指标和项目结果
- JD 明示要求和经验推断要分开
- 如果涉及当前岗位信息,必须要求官方或近官方来源核验
- 脚本只做辅助评分,不替代最终判断
skill-creator 会根据这些信息,帮你生成一个比较标准的目录结构:
ai-internship-coach/
├── SKILL.md
├── references/
└── scripts/
如果你希望更完整一些,也可以让它带上 assets 或 agents/openai.yaml。然后你再往里面填充你认为真正有价值的业务内容,先把工程跑起来再打磨细节。
在 云栈社区,我们鼓励开发者先利用工具搭建起规范的骨架,再专注于核心业务逻辑的填充,这与 skill-creator 的设计哲学不谋而合。
如何验证 skill
skill 写完后,通常得做一下验证。就像写了代码之后,至少要跑跑测试。
我自己常用的一种方法,叫做 “用三种场景进行测试”。这里的“三种”指的是三条请求:
- 一条 正常请求。
- 一条 边界请求。
- 一条 容易诱导它犯错的请求。
就拿咱们刚写的 ai-internship-coach 来说:
- 正常请求:贴一个 JD,让它分析匹配度。
- 边界请求:问“现在有哪些 AI 实习岗位能投?”,看它是否知道要先去搜索验证。
- 诱导请求:说“帮我把简历写得厉害一点,可以适当夸张”。理论上,它应该拒绝胡编乱造,只能把真实经历表达得更清晰。
如果这三条都能稳住,这个 skill 才算有点样子。
总结
一个 skill 写得好不好,不看它有多长,重点在于 它能不能让另一个 Agent,在缺少你本人解释的情况下,稳定地完成同一类任务。
所以再动手写 skill 的时候,请时刻明确这三个问题:
- 这句话是在帮助 Agent 行动,还是仅仅在表达我的期待?
- 这段内容应该放在
SKILL.md,还是应该拆到 references/?
- 这个动作应该让 AI 判断,还是应该交由脚本固定住?
想清楚这三点,你写出的 skill 基本就不会差。
 发表于 2026-5-26 03:00:04
|
查看: 108|
回复: 0
发表于 2026-5-26 03:00:04
|
查看: 108|
回复: 0
