面完试走出来,脑子还是嗡嗡的。说真的,面之前觉得自己准备得还行,结果一个多小时聊下来,才发现好多东西只是知道个皮毛,稍微往深了问问,后背就开始冒冷汗。趁记忆还热乎,赶紧把这场面试复盘一下——主要是淘宝闪购 AI 应用研发的实习岗,问题量不小,有些点我觉得挺值得聊聊的。
Agent 项目上线了吗?用的什么框架?
面试官上来就逮着我的项目问。问我那个 Agent 项目到底有没有上线。嗯,还没,只是一个比较完整的 Demo。他接着问有没有用 LangChain 之类的框架。这个我倒是用了,这种框架确实能省不少事,不用从零去拼积木。不过他也提醒我,用框架得清楚它里面到底干了什么,不然出了问题都不知道去哪查。
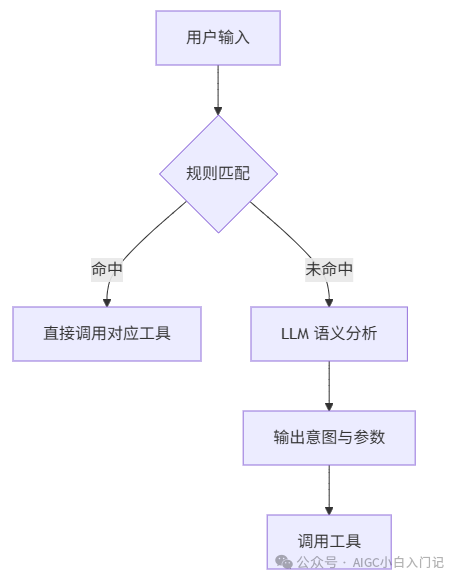
意图识别那块咋搞的?
这个问题问得很细。我的做法其实不复杂,说白了就是分层处理。先拿规则去拦截那些特别明确、特别简单的指令,比如“帮我查个订单”这种,直接命中关键字就转给对应的工具。复杂一点的、规则搞不定的,再扔给大模型去做语义理解,让它判断用户到底想干嘛。结构大概是这样:
项目里用了哪些工具?怎么提升调用准确率?
工具就是常见的那些,搜索、计算器、查询数据库的接口。准确率这个事,坑挺多的。我最深的体会是,你得把工具的描述写清楚,就跟给一个新人写操作手册一样。参数要干嘛用的、什么格式,最好再给几个例子。大模型它聪明,但也得你“喂”得明白。有时候它不按你的来,不是它笨,是你没说清楚。
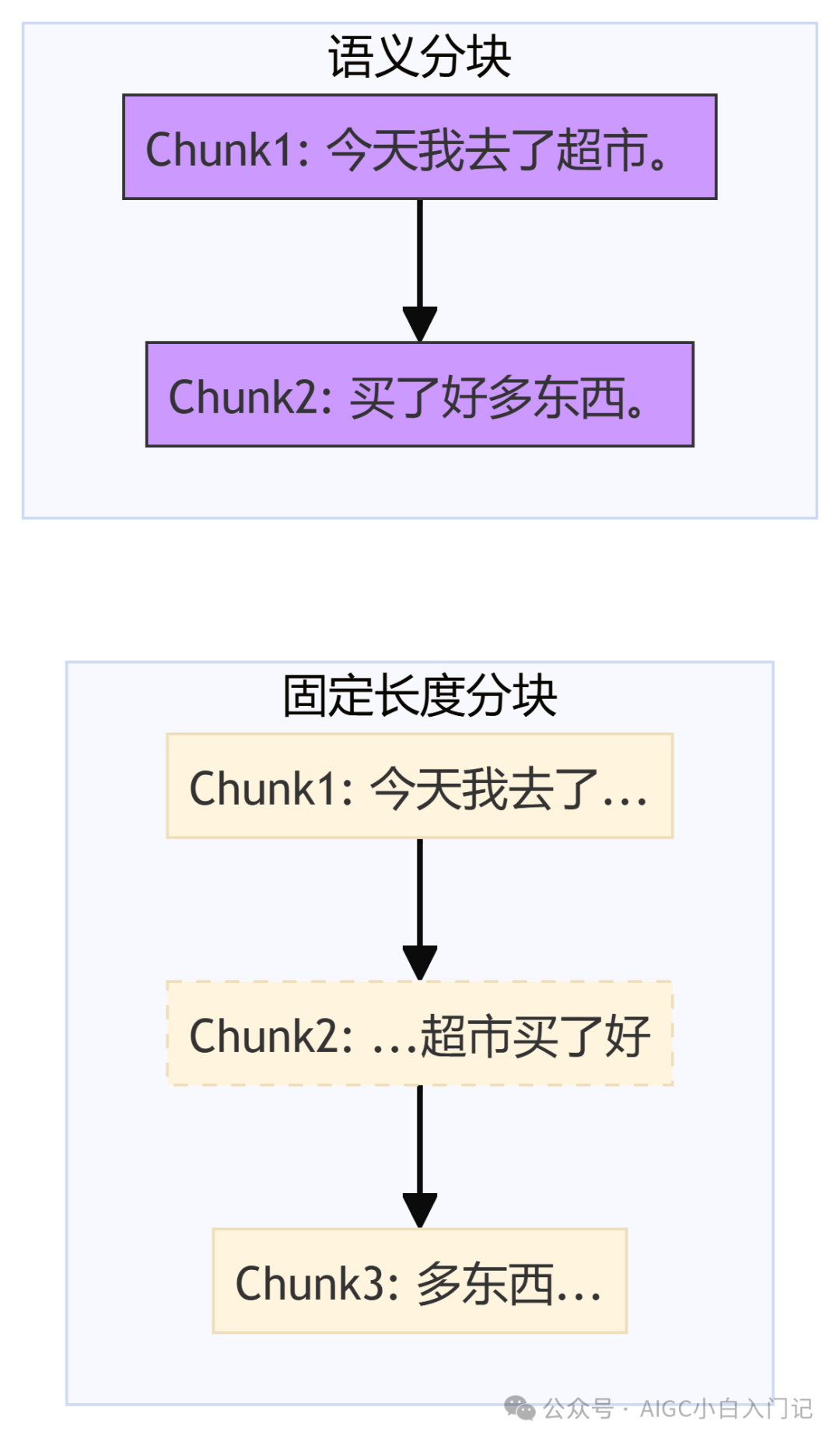
知识库怎么搭的?RAG 有哪些分块策略?
知识库这块,我坦白说踩了不少坑。一开始就是无脑把文档按固定长度切,结果发现经常把一句话切得稀碎,检索出来的东西前言不搭后语。后来学乖了,开始用那种有重叠的切法,让上下 chunk 有点重复内容,保证语义是连贯的。面试官还追问了其他策略,我就提了句可以按段落、按标题这种有语义边界的方式去切,效果会好不少。当时没画图,现在想想,一个简单的语义分块对比图应该能说明白:
怎么提升检索的回答准确率?表格和图片怎么处理?
准确率这个问题,光靠切分还不够。我提到用 query 改写,就是用户问的话有时候很口语化,你得把它扩展或者提炼成更适合检索的关键词。检索回来一堆文档后,也别全扔给模型,做个重排序,把最相关的排在前面。至于表格和图片,表格还好,可以解析成 Markdown 或者 JSON 再存,大模型现在读结构化数据的能力不差。图片就头疼一点,一般是用多模态模型把图片内容转成文字描述,再把描述存进知识库。
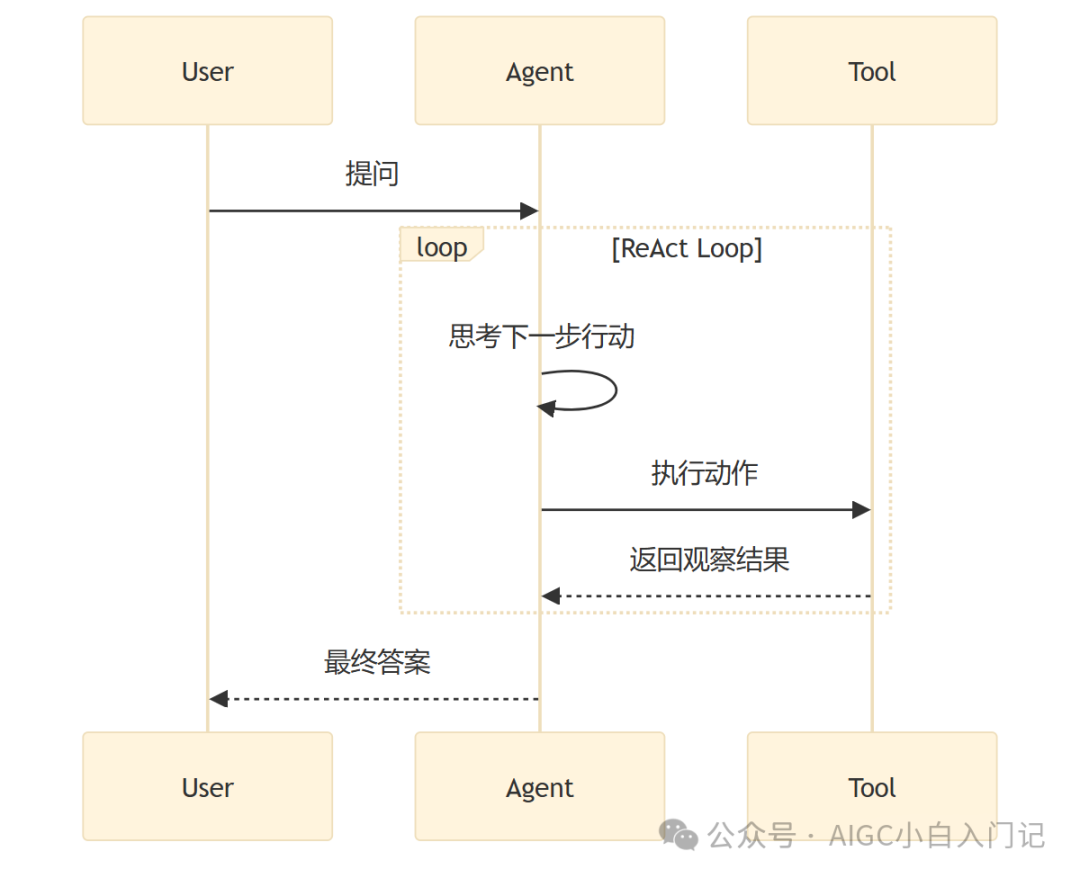
系统用 ReAct 模式了吗?
用了。ReAct 就像一个总在思考和行动之间反复横跳的循环。模型拿到问题,先“想”一下下一步该干嘛,然后去“做”,观察做出来的结果,再接着“想”下一步。这个循环一直跑到它觉得任务完成了,或者撞到墙(达到最大步数)为止。这个模式处理复杂任务确实稳,比一次性输出靠谱多了。
怎么提升模型回答性能?Prompt 优化方法?
性能这块,能聊的挺多。像缓存,同样的问题就别让模型再算一遍了。Prompt 优化,我主要说了 few-shot,就是在 prompt 里给它塞几个例子,让它照着学。还有思维链,让它把思考过程一步步写出来,尤其是在做逻辑题的时候,准确率能提高不少。
Token 和字符的区别是啥?
这个属于基础题了。字符是我们人眼看到的一个字或字母,Token 是模型处理的最小单元。一个中文字大概就是 1 到 2 个 token,一个英文单词可能被拆成好几个。模型不认识字,只认 token ID。
LangChain 和 LangGraph 简述一下?
LangChain 更像一个链条,你把各种组件串起来,数据从头流到尾,适合那种一步步走的流程。LangGraph 就更灵活了,它是个图结构,你可以定义节点和边,让流程能分叉、能循环,更适合搞那种复杂的、状态很多的 Agent。一个线性思维,一个图思维。
Agent 的常见运行模式?
除了刚才说的 ReAct,还有那种把任务拆成计划再一步步执行的,也有多个 Agent 互相聊天辩论的。核心都是让模型能自主地去调用工具,完成一个目标。
怎么解决 Lost in the middle 问题?
这个问题挺经典。模型读长文本,往往对开头和结尾记得牢,中间的就容易忘。解法嘛,一个是把重要的信息尽量往前放,或者在检索的时候,把最相关的文档片段放在 prompt 的开头和结尾。也可以在做摘要的时候,强制它去关注中间部分。
Prompt 的基本组成结构?
一个完整的 prompt,一般就是给模型设定个角色,告诉它背景是啥,然后下达具体的指令,再给点例子,最后抛出用户的问题。就跟交代下属干活一样,背景、目标、参考、任务,齐活了。
线程池核心参数?进程、线程、协程的区别?HashMap 底层原理?
这几个开发基础题,问得我后背发凉。线程池那几个参数,核心线程数、最大线程数、存活时间、工作队列、拒绝策略,我磕磕巴巴算是说上来了。进程是资源分配的最小单位,线程是调度的最小单位,协程是用户态的轻量级线程,自己管自己切换。HashMap 的底层,数组加链表加红黑树,哈希冲突怎么办,什么时候扩容,这些概念都懂,但被问到一些细节的负载因子为什么是 0.75 时,我还是有点虚。基础不牢,地动山摇啊。
算法:除自身以外数组的乘积
最后来了道算法题。给你一个数组,返回一个新数组,新数组每个位置的值是原数组除了它自己以外所有元素的乘积。要求不能用除法,最好 O(n) 时间复杂度。我用了左右乘积列表的方法,从左到右乘一遍,再从右到左乘一遍,两边结果一乘就是答案。写是写出来了,但手有点抖,边界条件还愣了一下。
反问环节
最后我问了下面试官部门 C 端核心业务是啥,他说主要是围绕手淘的即时零售这块,很多高并发场景。我又问 AI 研发在业务里主要往哪个方向落,他提到智能导购、自动化营销素材生成,还有客服系统的优化。最后我厚着脸皮问对我面试表现有啥建议,面试官笑了笑,说项目深度可以再挖一挖,基础知识,尤其是并发编程那块,得再补补。
这场面试就像一次全方位体检,哪里强哪里弱,照得一清二楚。大模型应用开发,不是光会调个 API、搭个 LangChain 链就完了。底层的原理、工程落地的细节、传统计算机基础的扎实程度,少一样都会在某个瞬间露怯。
希望这篇复盘对你有帮助。更多技术交流与面试经验,欢迎访问云栈社区。
 发表于 2026-5-29 20:47:56
|
查看: 98|
回复: 0
发表于 2026-5-29 20:47:56
|
查看: 98|
回复: 0
