上个月有个读者去字节二面,回来跟我复盘了一段对话,挺有意思的。
面试官问他:“你的RAG系统检索召回精度低,你怎么办?”他想都没想就说“调一下Top K”,语气还挺自信。面试官没接话,停顿了两秒,换了个角度问:“那你有没有想过,Top K调大了,噪声也跟着进来了——你的重排能扛住吗?”他愣了一下,说应该可以吧。面试官又问:“那如果问题出在切片阶段呢?你Top K调再大也找不到,因为文档在入库之前就已经碎掉了。”
他沉默了。回来跟我说,他当时脑子里一片空白,因为这些问题他一个都没想过。他以为RAG检索就是“切块→向量化→召回→生成”,调调参数就行了。后来他花了一周时间,把整条检索链路从头到尾拆了一遍,才发现这里的坑远比他想象的多。
今天把他复盘的内容整理出来,从数据接入层到重排过滤层,四层逐个讲清楚。你也可以对照看看,自己有没有踩过类似的坑。
1. 数据接入层:地基不牢,房子不稳
切片这步,多数工程师踩的第一个坑,不是模型选错,也不是架构设计有问题。是什么呢?是文档在进入向量库之前,就已经碎掉了。
这也是面试官追问的第一个点——“如果问题出在切片阶段呢?”很多人没意识到,切片质量直接决定了后续检索的上限。最常见的偷懒做法是固定字符数分块:每隔512个字符截一刀,管它截到句子中间还是段落开头呢,就那么切了。结果呢?语义在切口处断裂,一段本来完整的推理过程被切成两个孤立的碎片。这就很尴尬了。
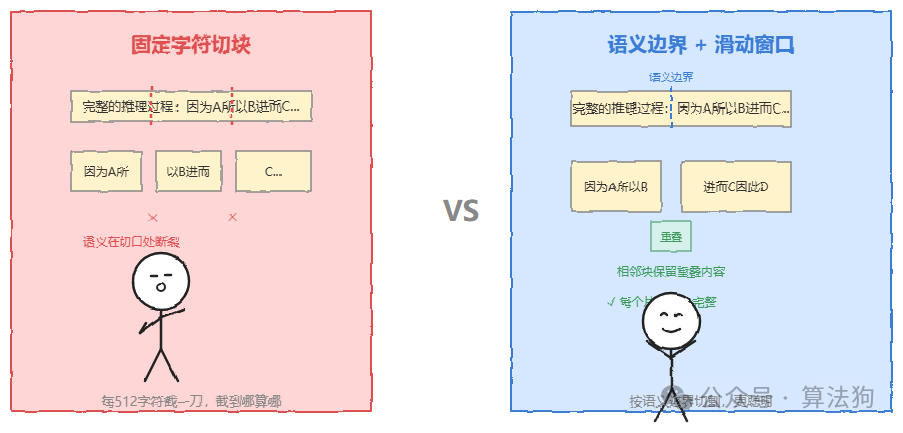
相比之下,按语义边界切块再配合滑动窗口——让相邻块之间保留一段重叠内容,这个方法虽然实现成本稍高一点,但能让每个片段在送入检索之前就保有独立的语义完整性。说白了就是,切得更聪明一些。
值得一提的是,2024年发表的LongRAG研究表明,处理整段文档而不是把内容切成极小碎块,在法律文档分析场景下可以减少大概35%的上下文丢失。这个数字提醒我们一件事:切得越细不等于越好,关键在于切在哪里。
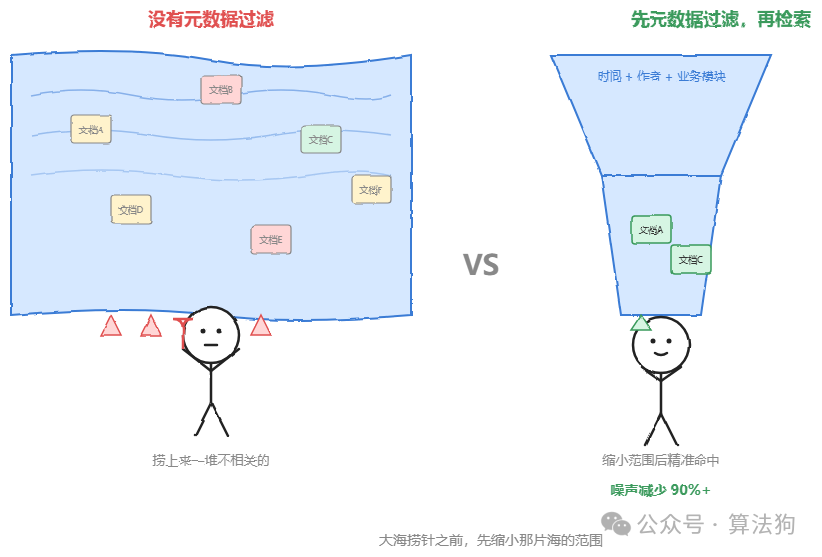
另一个经常被低估的环节是元数据的附加。很多系统的文档入库流程就是把原文转成向量,存进去,完事了。但纯向量检索有个天然的盲区:它只懂“语义像不像”,不懂“这份文档是不是我要找的那个时间段、那个部门发的”。这就很麻烦了。
那怎么办?给每份文档打上时间戳、作者、所属业务模块。检索时先做元数据过滤,再做向量匹配。这就好比大海捞针之前,先缩小了那片海的范围。相关噪声可以减少90%以上,召回率自然就随之提升。
第三个问题其实更根本:向量模型是否真的听得懂你们的话。通用模型在海量通用语料上训练,遇到“DRG付费改革”或者“信创适配方案”这类高度垂直的表达,它很可能无从理解。结果就是检索结果一塌糊涂。
正确的处理方式是用领域语料做对比学习微调(Contrastive Fine‑tuning),让模型学会在你的行业上下文里区分近义词和专有名词。这件事不是可选项,而是垂直场景下的基础设施,必须得做。
2. Query处理层:用户的问题真的好搜吗?
用户提问的方式往往不适合直接喂给检索系统。几个关键词、半句没说完的问题、甚至明显的表达偏差,这些都是常态。与其苛责用户不会提问,不如在系统层面把这个事情接住。
多路Query改写的思路是,用大模型把用户的原始问题扩写成三到五个语义相近但表述不同的版本,然后并发检索,结果取并集。只要有一路命中了目标文档,整条链路就不会空手而归。直觉上你可能会觉得这会带来更多噪声,但实际上只要加上后续的重排过滤,精度并不会下降。
更进一步的方案是HyDE(假设性文档嵌入,Hypothetical Document Embeddings)。这东西最早出现在2022年普林斯顿的一篇零样本检索论文里,逻辑有点反直觉:不直接用问题去搜答案,而是先让模型针对问题生成一个假设性的回答,再用这个“虚构答案”的向量去检索真实文档。
为什么这样有效?你想,一个短问题的向量表示和一段详细文档的向量表示,在嵌入空间里天然存在形态差异——前者更像问句,后者更像陈述。用假设性答案去搜,就相当于把问句提升成了“文档风格”的表达,两者的向量距离因此显著缩短。研究显示,HyDE在标准检索基准上的表现(如nDCG@10、Recall@K)系统性地优于直接用原始查询检索的基线方法。
不过,HyDE也不是万能的。有研究发现,对于精确的数值类查询,比如查某个财务指标,查询扩展类方法带来的收益其实有限,反而不如直接做混合检索来得稳定。所以,技术选型之前先弄清楚你的查询类型,比盲目堆叠技术重要得多。
对于多跳问题,还需要额外的拆解步骤。比如“某公司的法定代表人是谁”,你得先找公司主体,再找人。怎么处理?就是把一个复合问题拆成有逻辑顺序的子问题,逐步检索,前一步的结果作为下一步的输入条件。这才是对话系统区分“会检索”和“真的能用”的分水岭。
3. 检索策略层:向量检索不是万能的
语义检索的流行让一些工程师产生了一种幻觉——觉得只要向量够好,什么都能搜到。但这个假设遇到特定设备型号、订单编号、专业代码的时候,会直接失效。
原因在于向量检索的本质是“语义相似”。当用户输入的是一个精确符号而不是一段自然语言描述时,搜出来的可能是一堆“看起来像”但实际完全不同的结果。就像搜“AB‑123‑CD”,搜出来的是一堆关于车辆检验的通用文档,而不是那辆车的具体记录。你说气人不气人。
混合检索的逻辑正是为此而生的。怎么做?用向量检索来理解意图,用BM25来捕获精确关键词。两条路并行,结果通过倒数秩融合(RRF)合并打分。有工程团队在实际案例中记录到,引入BM25加向量混合检索后,召回精度从62%提升到了91%,提升幅度接近50%。现在,混合检索已经被视为企业级RAG系统的生产标配,而不是什么可选优化。
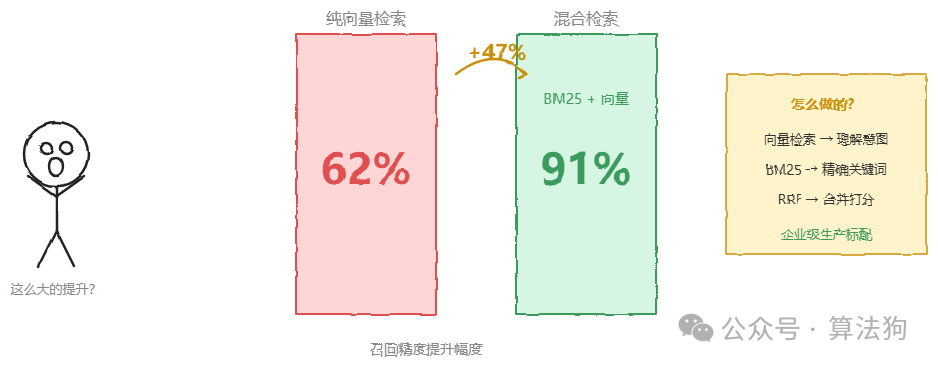
这也是面试官说的“Top K调大了噪声也跟着进来”的真正解法——不是调K,而是换检索策略。
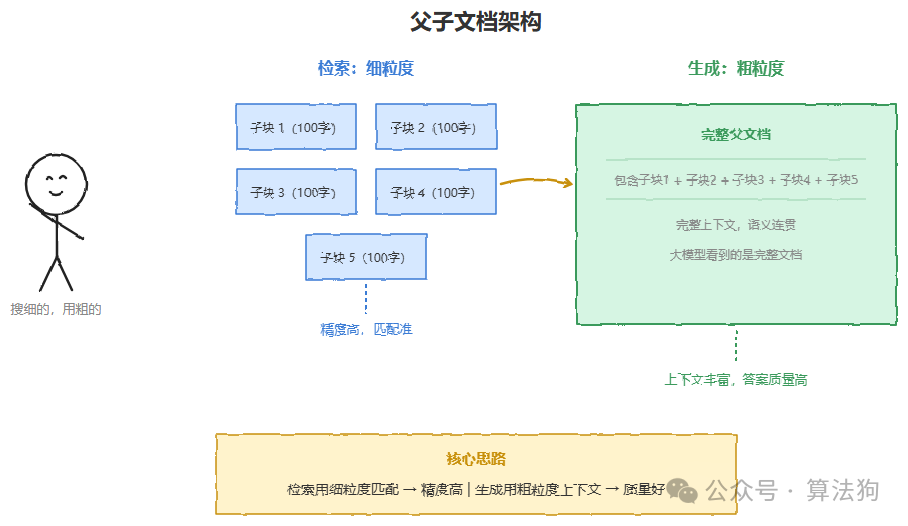
父子文档架构是另一个经过验证的实用方案。具体做法是:切碎的子块(比如100字一段)用于检索匹配,这样精度高;但实际送入大模型的是这些子块对应的完整父文档。检索用细粒度,生成用粗粒度,两者并不矛盾。说白了就是,搜的时候搜细的,用的时候用粗的。
再往上就是GraphRAG。微软研究院在2024年正式提出了这套框架。核心思想是把文档集合不再视为扁平的向量点云,而是一张实体关系网络。当问题涉及多文档、跨主体的关联信息时——比如“我们所有供应商合同里的违约条款风险”——单纯向量检索根本无法应对。但知识图谱可以通过实体和关系的游走,把分散在各处的碎片拼回来。
不过,GraphRAG的代价也是显著的。图谱构建成本大概是基础RAG的3到5倍,还需要引入图数据库、实体抽取流水线等额外组件。它适合关系密集、多跳推理的场景,但未必是每个团队都需要上的选项,得根据实际情况判断。
4. 重排与过滤层:宽进严出的漏斗哲学
到这一层,系统已经尽力把相关文档捞上来了,可能是50个,可能更多,但这些文档的排序未必准确。下面需要的是什么呢?是一次精度更高的重新评估。
交叉编码器重排模型和向量检索的核心区别在哪?向量检索是用问题和文档分别编码后比较距离,速度快但精度有限。交叉编码器呢,是把问题和候选文档拼在一起,作为整体输入模型。计算量更大,但对相关性的判断精度显著更高。研究显示,两阶段流水线——混合检索加上交叉编码器重排——在标准基准上的Recall@5可以达到0.816,远超任何单一检索方法。
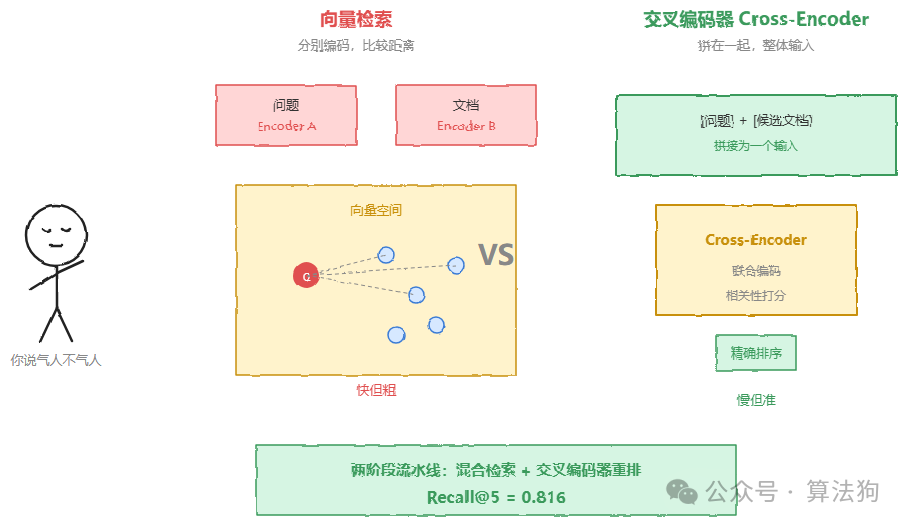
筛出Top 5之后,还有一个容易忽视的陷阱:上下文位置偏差。大模型在处理长文档时,对位于中间段落的内容注意力会明显衰减。这个现象在NLP研究中被称为“迷失在中间”(Lost in the Middle)。因此,把送入模型的文档做动态压缩,剔除噪声、保留与问题直接相关的段落,不是什么锦上添花,而是保住答案质量的必要操作。
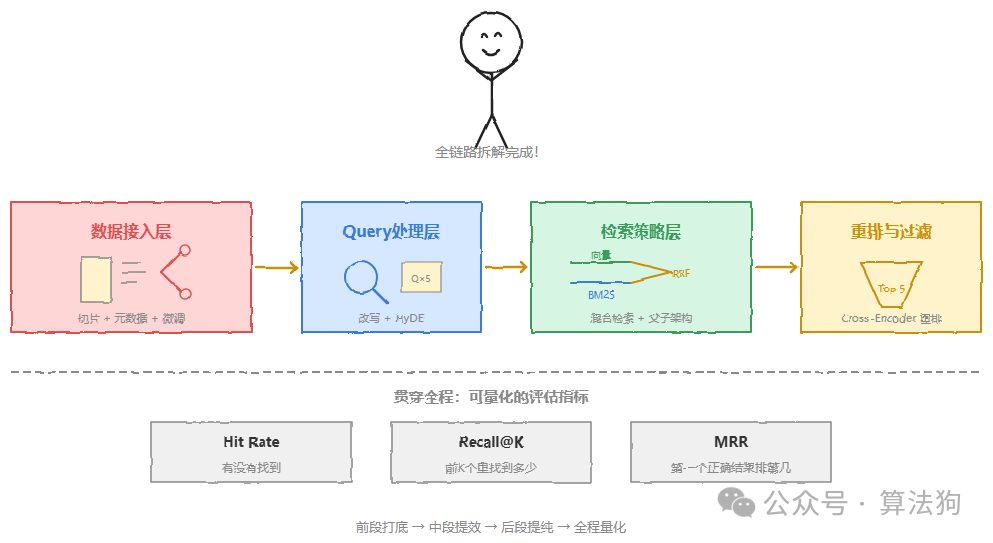
整条链路的最后一环是评估闭环。没有量化指标的优化,本质上就是在做直觉实验。Hit Rate衡量“有没有找到”,Recall@K衡量“在前K个里找到了多少”,MRR反映“第一个正确结果排在第几位”。这三个指标覆盖了不同的失败模式,你应该同时追踪它们,而不是只看其中一个就下结论,得全面地来看。
5. 总结
回到开头那个问题——面试官问“召回率太低怎么办”,最糟糕的回答是什么?是给出单一答案,比如换个更好的模型,或者加上重排,或者像那位读者一样,说“调一下Top K”。这个问题的正确打开方式,是把它看成一道全链路的系统题。怎么拆解呢?前段靠切片质量和查询扩展打底,中段靠混合检索和父子架构提效,后段靠重排模型提纯。贯穿始终的是可量化的评估指标。
每个环节都有自己适用的场景,也有自己的局限边界。GraphRAG不适合所有人,HyDE不适合所有查询类型,元数据过滤在文档标注不规范的时候反而会成为噪声来源。这些都需要去考虑。
真正成熟的工程判断是什么?不是把所有技术都堆上去,而是清楚每一层在做什么、为什么这样做、以及什么时候可以不做。这个才是关键。
先这样…
 发表于 2026-5-29 21:12:15
|
查看: 100|
回复: 0
发表于 2026-5-29 21:12:15
|
查看: 100|
回复: 0
