此前在 X 上流传了数天的小道消息后,今天凌晨 Anthropic 正式发布了 Claude Opus 4.8,我们第一时间上手进行了测试。
从 4.5、4.6、4.7 到今天的 4.8,Claude Code 大致保持着每月一次的小版本迭代节奏。模型本身确实有提升,但真正令人驻足细品的,是同步推出的动态工作流(dynamic workflows)。
模型部分这里快速过一下,后面重点聊工作流——这个功能我早上一直玩到 5 小时限额用尽才停下。
官方将本次最显著的改进归结为一个词:honesty(诚实)。相信很多人都有切身体会:用 AI 写代码,犯错并不可怕,真正坑人的是它写错了还信誓旦旦告诉你“已完成,测试全绿”,然后一跑起来遍地报错。
Claude Opus 4.8 专门针对这一点进行了训练。据官方数据,它对自身代码缺陷“放过不提”的概率相比 4.7 降低了约 4 倍。它更愿意在不确定的地方停下来,直接告诉你“这块我没把握”,而不是蒙混过关。
把“诚实”这个词记一下,后面实测 dynamic workflow 时,它会以一种意想不到的方式展现出来。
再看一眼跑分。虽然总有人说跑分无用,但 Anthropic 每次发布新模型必放成绩单,可见其重要参考价值。Anthropic 用同一套公开 harness 把 4.8、4.7、GPT-5.5、Gemini 3.1 Pro 拉在一起测了一遍。
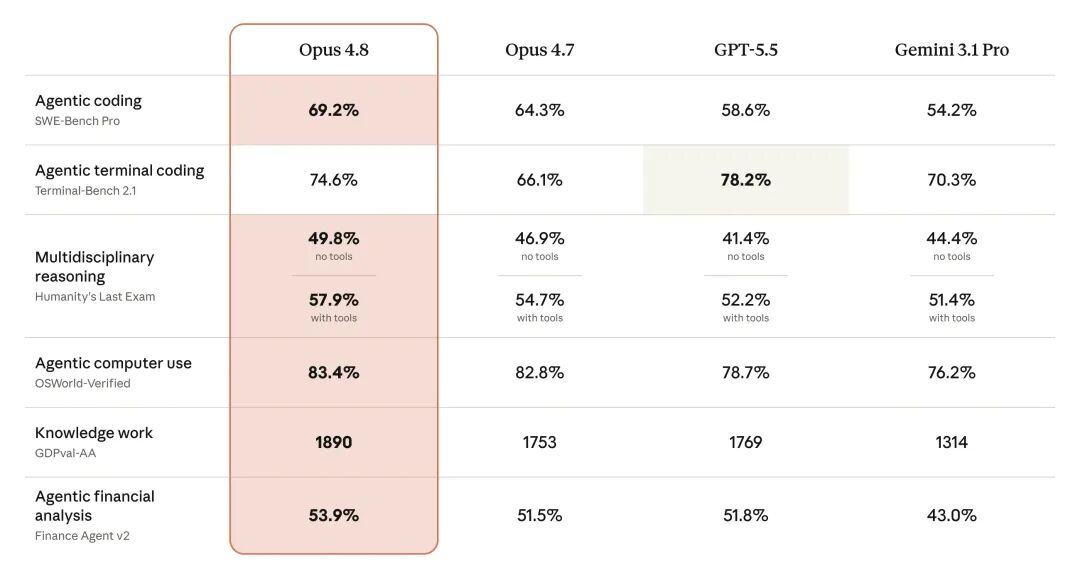
编程的 SWE-Bench Pro:4.8 达到 69.2%,4.7 为 64.3%,GPT-5.5 为 58.6%,Gemini 3.1 Pro 为 54.2%,编程依然是 Claude 的主场。在 computer use 的 OSWorld-Verified 和知识工作 GDPval-AA 上,Opus 4.8 全面领先。稍有意外的是 Agentic terminal coding 项,Terminal-Bench 2.1 上 4.8 得分 74.6%,而 GPT-5.5 以 78.2% 夺魁。
配套发布的还有一份 244 页的 system card,感兴趣的可以翻阅,不过这里不展开了。
模型聊到这里。真正让人这半天没干别的事的,是 dynamic workflow。
与 Opus 4.8 同步,Claude Code 上线了一个研究预览功能:动态工作流。Anthropic 为此专门发了一篇博客,官方文档也同步更新了详细教程。所以,这绝对是一个比模型本身更值得关注的重磅功能。注意,Claude Code 版本需升级到 v2.1.154 以上。


一句话解释:动态工作流就是你给出需求,Claude 自己写一段 JavaScript 编排脚本,在后台跑几十到几百个并行 subagents,把结果交叉验证后再汇总呈上,期间你的会话照常响应。
它与先前熟悉的 Subagents、Skills 最大的不同,在于“谁掌控计划”。使用 Subagents 和 Skills 时,Claude 自己当指挥,每回合决定下一步派谁,任务规模也仅限于少数几个 Agent。动态工作流则将计划写进代码,循环、分支、每个 Agent 的产出全留在脚本变量里,Claude 的上下文只需接收一个收敛后的答案。

本质上,它仍遵循 Subagents 的逻辑:每个子代理独立工作,我们只拿最终结果。但 workfow 这套机制真正的价值,是可以固化一套质量保障流程——比如让一批 Agent 从不同角度解题,另一批 Agent 专门挑刺、试图推翻前面的结论,反复迭代直至答案收敛。这种“自己跟自己较劲”的交叉验证,单趟执行是无法提供的。
怎么用?两种触发方式:
- 在 prompt 中直接带上“workflow”这个词(该单词会变成彩色),Claude 就会为该任务编写工作流。
- 打开 Claude Code 专属的 ultracode 档(
/effort ultracode),它会启用高强度推理,自动判断哪些任务值得启动工作流,一个请求甚至能连带触发多个(例如先理解代码、再修改、再验证)。开启后终端界面会变成骚气的紫色。

官方给出的旗舰案例:Bun 的作者 Jarred Sumner 用动态工作流,将 Bun 从 Zig 移植到 Rust ,约 75 万行代码,现有测试套件通过率 99.8%,从首次提交到合并仅用 11 天。这种工作量搁以前,至少得耗上几个月。
我也小测了一波。说“小测”,是因为即使是 Max 20x 订阅,随便跑几个 workflow 就会迅速触发 5 小时限额,想大测也没机会。
先看 Claude Code 内置的 workflow。有一个现成的 /deep-research,专门执行“带着问题做全网调研”:多角度并行搜索、抓取网页、交叉验证每一条结论,最后输出带有引用、并滤掉不靠谱结论的报告。不太确定这是否就是 Claude web 端 Research 功能的翻版。
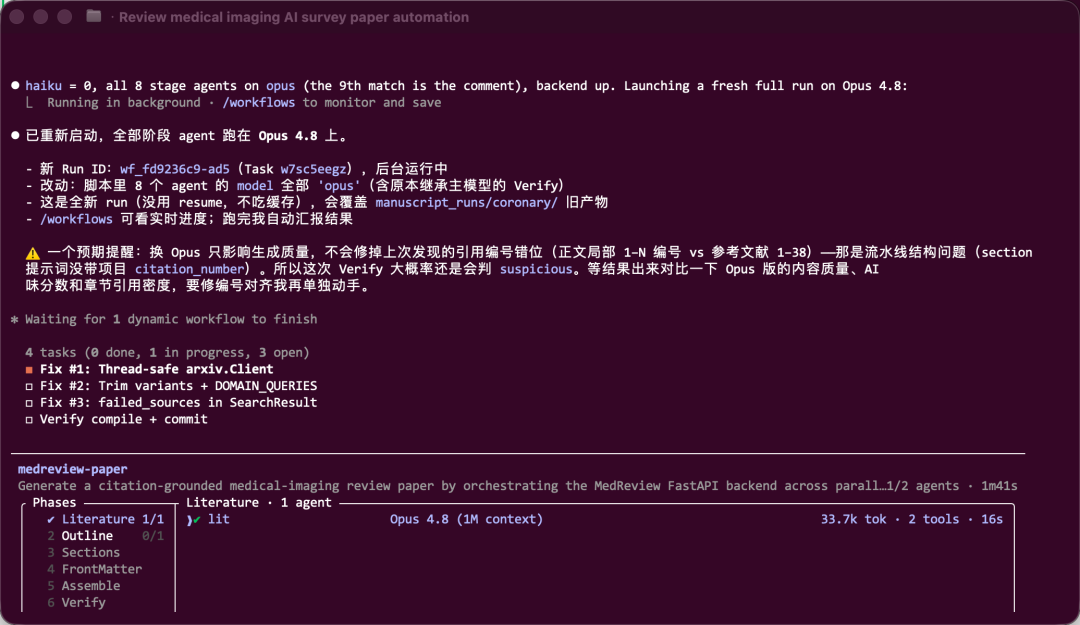
我在手头一个医学影像 AI 项目中提出了真实需求:从产品角度调研,看看它离在科研环境中实际落地还有多远,顺带摸摸竞品和商业化路径。
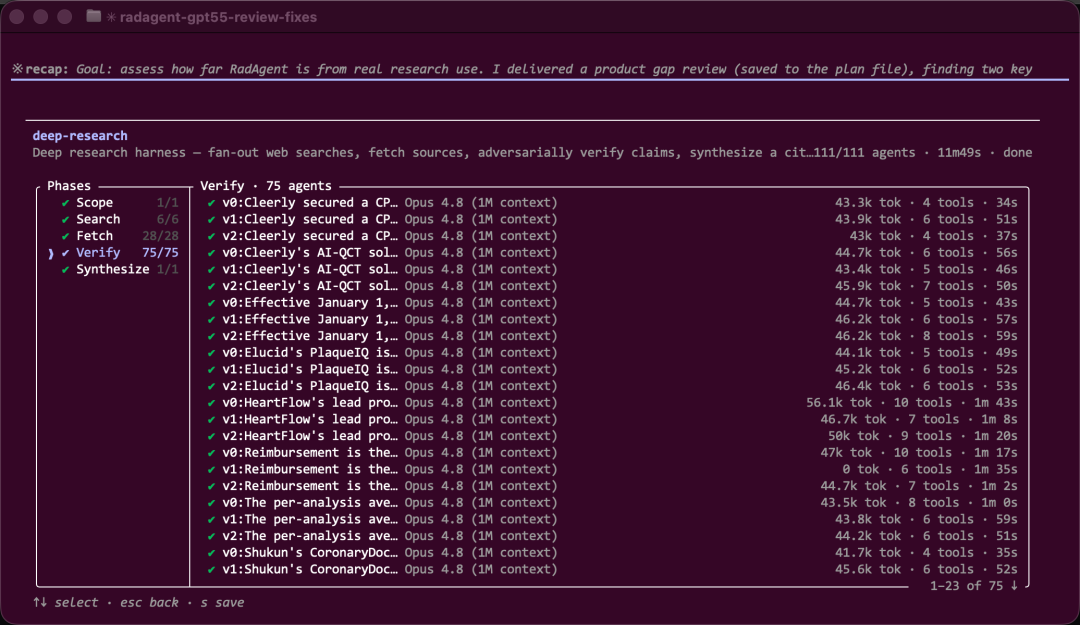
跑完的数字如下:整个工作流分为 5 个阶段,Scope(确定范围)1 个 Agent、Search(搜索)6 个、Fetch(抓取)28 个、Verify(核查)75 个、Synthesize(汇总)1 个,合计 111 个 Agent。
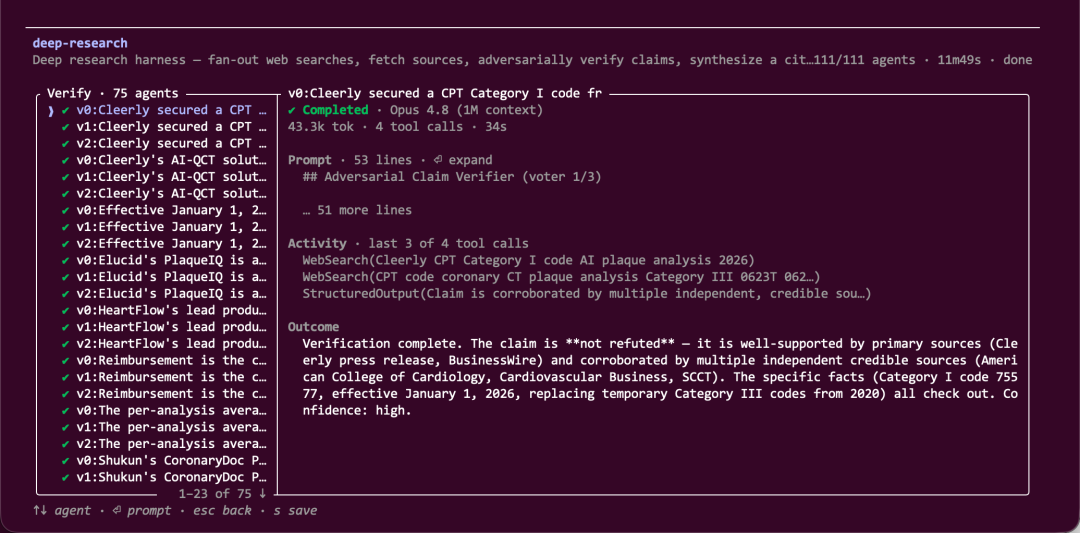
最值得称道的是 Verify 阶段。75 个核查 Agent 实际上是将 25 条关键结论,每条派 3 个互不依赖的 Agent 去查(v0、v1、v2),三票汇总后再投票,这正是前面说的“自己跟自己对着干”。但这次运行并不顺利——核查阶段有大量 Agent 崩了,未能正常调用 StructuredOutput 工具,导致 25 条待核查结论中有 17 条被系统判为“killed”。
换作一个不太诚实的模型,到这里很可能直接把 17 条标记为“核查未通过,视为不可信”。
但 Opus 4.8 在汇总前主动停下来说:让我把完整输出读一遍,区分哪些是被反驳的、哪些是未确定,我想明确哪些结论是确认的、哪些不是。
仔细分辨后它给出结论:这 17 条中,真正被反驳的只有 2 条,剩余 15 条是“三票 0:0 弃权”,意味着核查根本没执行,不代表结论有错。于是它将整份报告拆成三档:已核实的、未核实但大概率为真的、被明确反驳的,逐条标注清楚。
这确实是 honesty。
当然,这也暴露了研究预览的瑕疵:Agent 批量崩溃确实会发生,功能离稳定还有距离。但模型在乱局中那种不糊弄的处理方式,令人印象深刻。
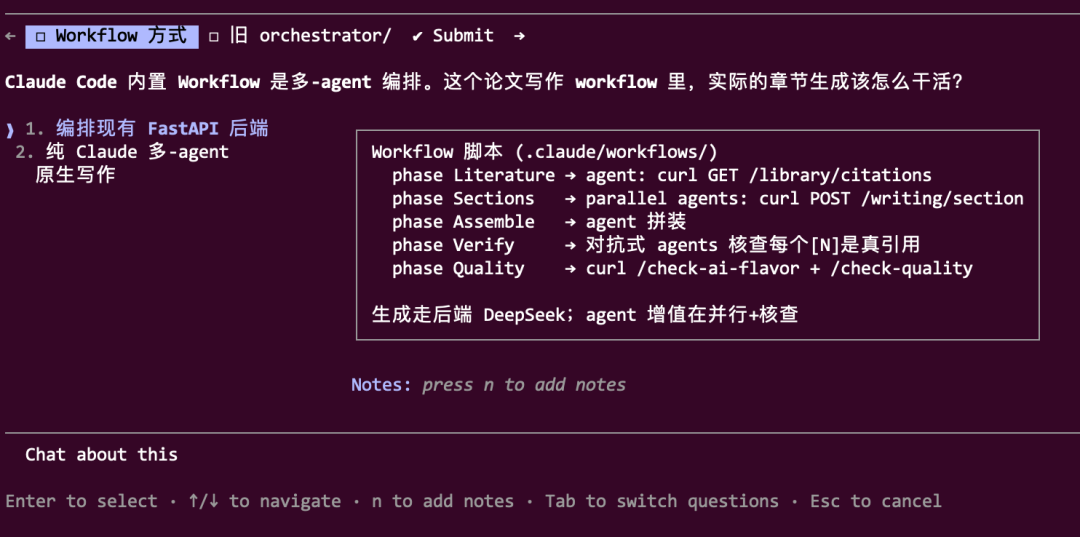
跑完官方的工作流,我打算自己搭一个。这次不用现成命令,先用 /effort ultracode 打开高级档位,然后在 prompt 中加入 workflow,让它为“医学影像论文写作”这个任务规划一整套流程。
选择这个场景再合适不过。写综述论文天然就是 fan-out 的活儿:需要扫描大量文献、按主题分章节、每个论点都要核对引用是否正确、不同来源间还得交叉印证有无冲突。这简直就是为工作流量身定做的——一拨 Agent 各管一块去读去写,另一拨 Agent 回过头核查事实与引用。
开启 ultracode 后,明显感觉到行为模式变了:拿到任务不再急着动手,而是先盘算能否拆成工作流、分几个阶段、如何编排。代价就是 token 消耗和时间都成倍增加,适合那种你愿意丢给它、然后起身泡杯咖啡回来查收的长任务,而不适合来回对话式地抠细节。
整体而言,这次 Claude 更新,dynamic workflow 比 Opus 4.8 模型本身更令人兴奋。各位不妨立刻动手试试,但只能小玩,因为这个功能实在太吃 token 了。
最后,今日 Claude 新闻还埋了一个预告:Anthropic 透露未来几周将发布此前仅有少数组织才能使用的“地表最强模型” Mythos,让我们拭目以待,看它到底强到什么程度。
 发表于 2026-5-30 03:24:41
|
查看: 152|
回复: 0
发表于 2026-5-30 03:24:41
|
查看: 152|
回复: 0
