在供应链领域,准确的需求预测是一切计划的源头。传统方法长期受困于多变量耦合、非平稳波动和多模态数据融合的三重挑战,而大型深度学习模型又因体积庞大难以在边缘设备部署。
顺丰科技联合浙江大学、浙江工业大学在论文中提出的创新模型 Li-Net,以仅 0.5MB 的极致轻量化设计,在 24 项学术 Benchmark 测试中拿下 20 项第一,平均绝对误差(MAE)降低 15.3%。该成果正式发表于数据工程领域顶级会议 ICDE 2026,并在快消行业落地中实现预测效率提升 14 倍、训练效率提升 120 倍。本文将系统拆解 Li-Net 的架构设计与三大创新机制。
以下围绕六个方面展开:
- 供应链预测的价值与现实困境
- 技术演进:从统计规则到深度融合
- 核心技术:Li-Net 架构与三大创新机制
- 可解释性与长期稳定性
- 总结与展望
- Q&A
01 供应链预测的价值与现实困境

ICDE(IEEE International Conference on Data Engineering)是与 KDD、SIGMOD 并列的数据工程三大顶会之一,自 1984 年创办以来已成功举办 42 届,每年吸引 500 余名学术界与工业界研究者参与。Li-Net 的论文在工业与应用赛道获得直接接收,标志着该技术兼具顶级学术创新与真实业务落地价值。
在供应链场景中,预测需求贯穿四类核心应用:商超零售预测关注库存周转率与缺货率,运输网络流量预测优化运力利用率与准时送达率,生鲜品类预测聚焦售罄率与损耗率,站点仓储运营预测则提升人效与设备利用率。
一个典型困境来自蛋糕备货场景。鲜奶油蛋糕仅能保存 1 天,情人节心形蛋糕销量可能暴增 300%,平日却需求低迷。影响销量的因素交织复杂:促销、天气、新品上市、商品下架、新店开业、蚕食效应、节假日、季节性,任何单一变量的忽略都可能导致巨大损耗或缺货。
02 技术演进:从统计规则到深度融合
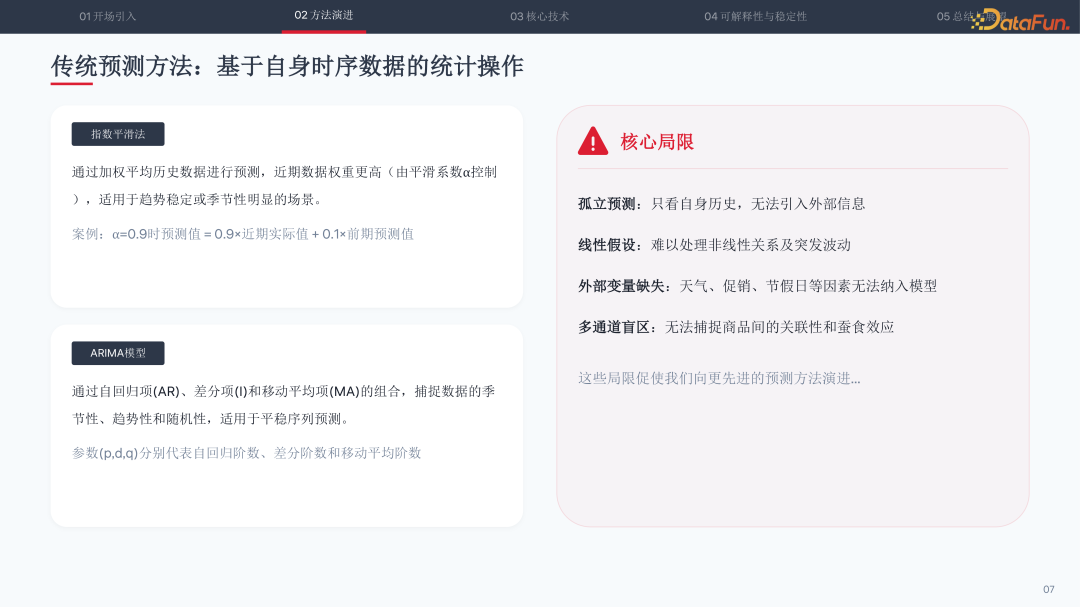
预测方法的演进经历了三个时代。传统统计方法如指数平滑法和 ARIMA 模型,本质上是对自身时序数据的加权统计操作。指数平滑法通过平滑系数 α 控制近期权重,ARIMA 模型通过自回归项、差分项和移动平均项捕捉季节性与趋势性。但这类方法存在四大局限:孤立预测无法引入外部信息、线性假设难以处理突发波动、外部变量(如天气促销)难以纳入、多通道盲区无法捕捉商品间的关联性。
机器学习时代以 XGBoost 和 LightGBM 为代表,通过构造滞后特征(前 1/7/14 天销量)、滚动统计特征(近 7 天均值)和交叉特征(品类×季节)进行预测。这种“数据决定上限,特征工程逼近上限”的思路能有效引入外部变量,但瓶颈在于:特征工程难以穷尽所有影响因素、每个 SKU 需单独建模难以规模化、长期依赖能力不足——滚动预测会产生误差累积的牛鞭效应。
深度学习 时代通过 RNN/LSTM 捕捉长期依赖,Transformer 利用自注意力机制并行处理序列。然而标准架构仍面临挑战:多维度融合不足,无法充分利用多通道、多模态信息;计算成本高,需要大量训练数据且推理资源消耗大。
顺丰 Li-Net 要回答的核心命题是:如何在保持预测精度的同时,实现多维度信息的高效融合?如何让模型既能理解商品间的关联(多通道),又能融合不同粒度的信息(多尺度),还能利用文本、图像等异构数据(多模态)?
03 核心技术:Li-Net 架构与三大创新机制
Li-Net 采用编码器-处理器-解码器的流水线架构,核心目标是在低维抽象空间中提取核心模式,重建未来预测。关键原则是将多模态信息智能融合到每一结构层。
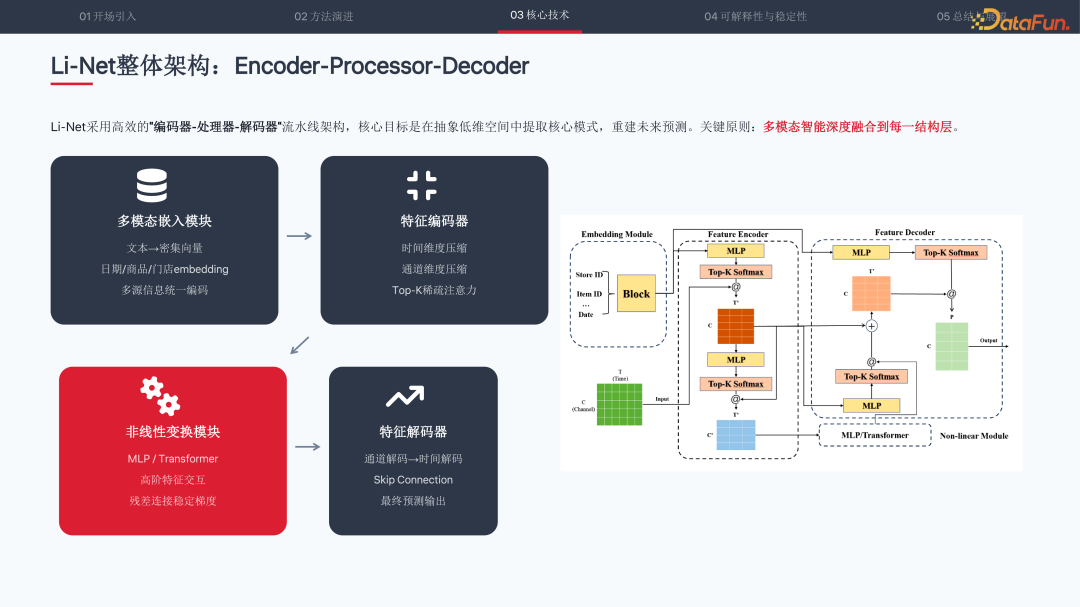
整体架构包含四大模块:多模态嵌入模块将文本、日期、商品、门店等信息统一编码为密集向量;特征编码器对时间和通道维度分别进行压缩,通过 Top-K 稀疏注意力保留最重要的关联;非线性变换模块采用 MLP 或 Transformer 进行高阶特征交互,残差连接确保梯度稳定;特征解码器按通道解码到时间解码的顺序,重建最终预测输出。
数据组织维度包含 B(Batch Size 批次大小)、C(ChannelSize 通道/商品数)、T(Time 过去 N 天时间步)、F(Feature 多目标隐藏空间)。每个通道用时间序列向量表示,协变量(促销、价格等)统一编码引入。
三大创新机制
创新一:多通道优化技术
核心洞察来自消费者在替代品间的选择行为:巧克力慕斯促销导致黑森林蛋糕滞销,推出新款芋泥蛋糕后原畅销款芋泥香草杯销量下降 40%。这种蚕食效应在传统模型中被忽略。
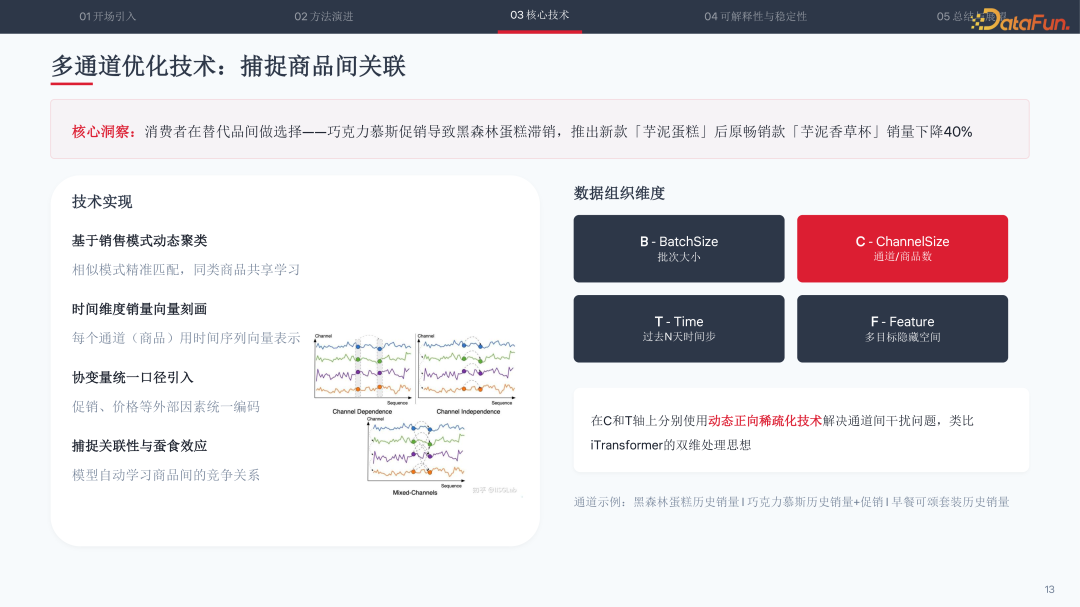
Li-Net 通过三项技术实现多通道捕捉:基于销售模式动态聚类,使相似模式精准匹配;用时间维度销量向量刻画每个通道;协变量统一口径引入。在 C 和 T 轴上分别使用动态正向稀疏化技术,类比 iTransformer 的双维处理思想,模型自动学习商品间的竞争关系与蚕食效应。
创新二:多尺度与多目标技术
Li-Net 通过多尺度聚合实现跨时间粒度的协同预测:日级销量捕捉高频波动,周级销量识别季节性模式,月级销量追踪长期趋势。模型动态调整输入范围,可处理 400 天历史数据与 10000 个通道规模。
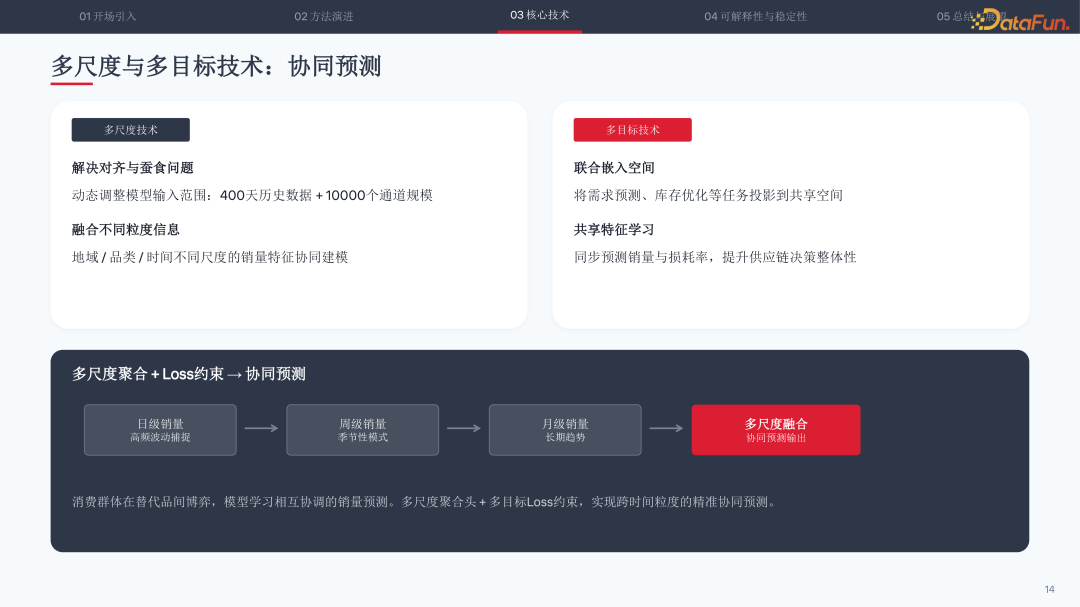
多目标技术则将需求预测、库存优化等任务投影到联合嵌入空间,共享特征学习。通过多尺度聚合头加多目标 Loss 约束,实现销量与损耗率的同步预测,提升供应链决策的整体性。
创新三:多模态导航融合
传统方法简单拼接特征会引入异构噪音,信息互相干扰。Li-Net 创新性地将多模态 Embedding 作为注意力“导航器”:文本通过 BERT 风格预训练转为密集向量,冻结外部数据 Embedding 层权重,多模态向量精准引导模型关注重点,相对距离权重约束(总和为 1)确保分布稳定。
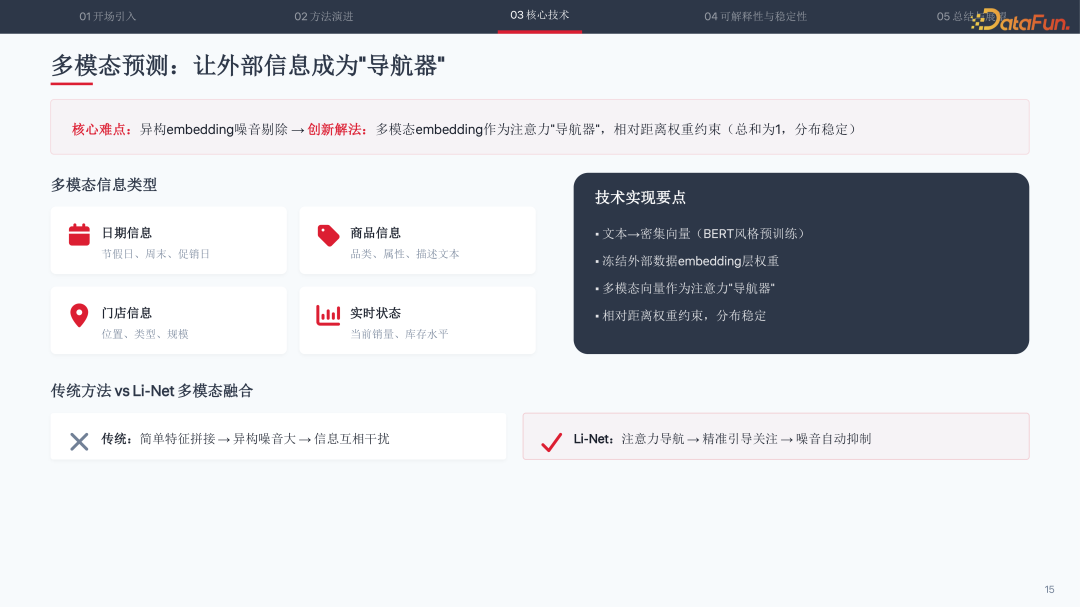
这种设计使得日期信息(节假日、周末、促销日)、商品信息(品类、属性、描述文本)、门店信息(位置、类型、规模)、实时状态(当前销量、库存水平)能够自动抑制噪音,避免互相干扰。
稀疏注意力:统一与提纯
传统注意力机制的 O(n²) 复杂度在大规模多通道场景下难以承受。Li-Net 设计的 Top-K 稀疏注意力统一了时间与通道的计算口径,处理三种相关性矩阵:销量相关性矩阵(商品间历史销量的关联模式)、协变量相关性矩阵(促销价格等外部因素)、多模态向量相关性(文本类别等异构信息)。
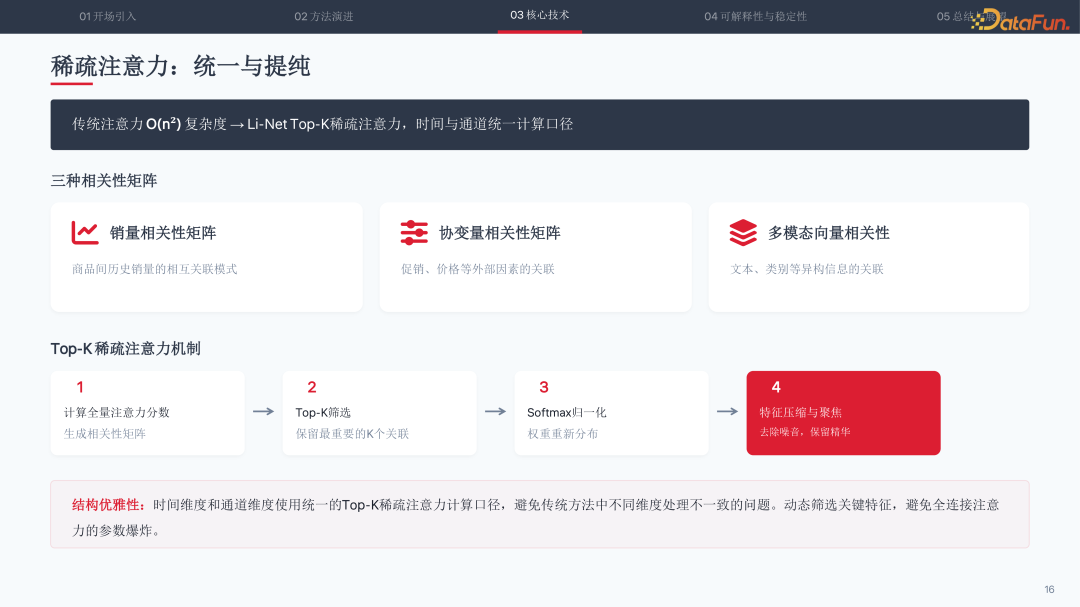
机制分为四步:计算全量注意力分数、生成相关性矩阵、Top-K 筛选保留最重要关联、Softmax 归一化。这种正向稀疏化避免了参数爆炸,同时防止互斥变量干扰。
骨干网络设计极为精简,包含轻量级的 MLP 模块(Linear-ReLU-Linear)和标准 Transformer Encoder。通过残差连接防止信息丢失,双通道处理分别处理 C 和 T 维度,维度保持确保特征空间稳定。仅需在时间轴和通道轴交替进行线性变换与转置,两个线性层即可完成时空信息交换,最终模型大小仅 0.5MB。
实验验证与工业落地
在 24 项学术 Benchmark 测试中,Li-Net 有 20 项取得 SOTA 第一,平均 MAE 为 0.3443。与 iTransformer 相比 MAE 降低 15.3%(从 0.4064 降至 0.3443),与 PatchTST 相比 MAE 降低 6.3%(从 0.3673 降至 0.3443),覆盖 ETTh2、ETTm2、Electricity、Weather、Traffic、M5 等数据集。
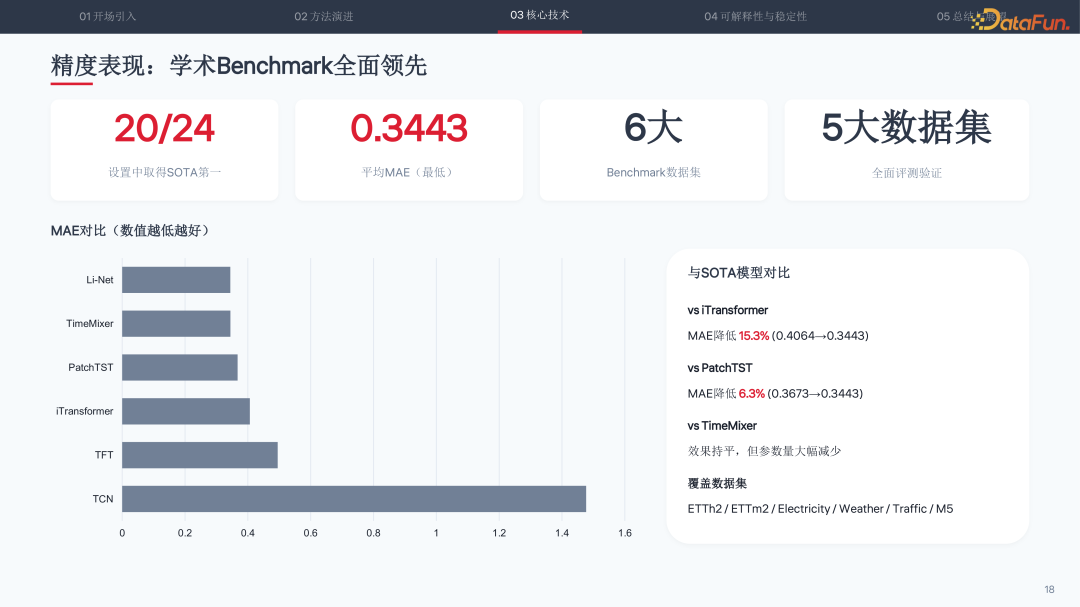
效率指标同样出色:模型体积 0.5MB,相比 TFT 的 26.8MB 缩减 98%,参数压缩比达到 53 倍;ETTh2 数据集推理时间仅 0.4 秒;Traffic 大数据集训练内存仅需 41-167MB。
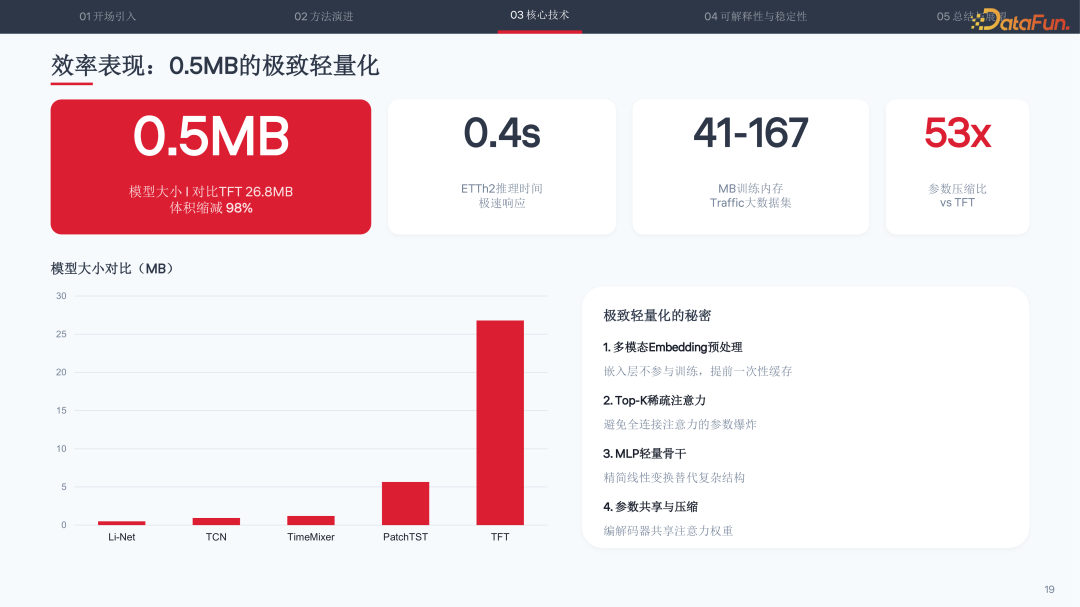
在快消客户的实际落地中,十亿级件量预测效率提升 14 倍(从 151 分钟降至 11 分钟),训练效率提升 120 倍(20 小时降至 10 分钟),计算资源成本节约 46 倍,服务器投入减少 5 倍,准确率提升 5% 以上。内部应用覆盖件量预测、分拨流量调度、运力优化等场景。

04 可解释性与长期稳定性
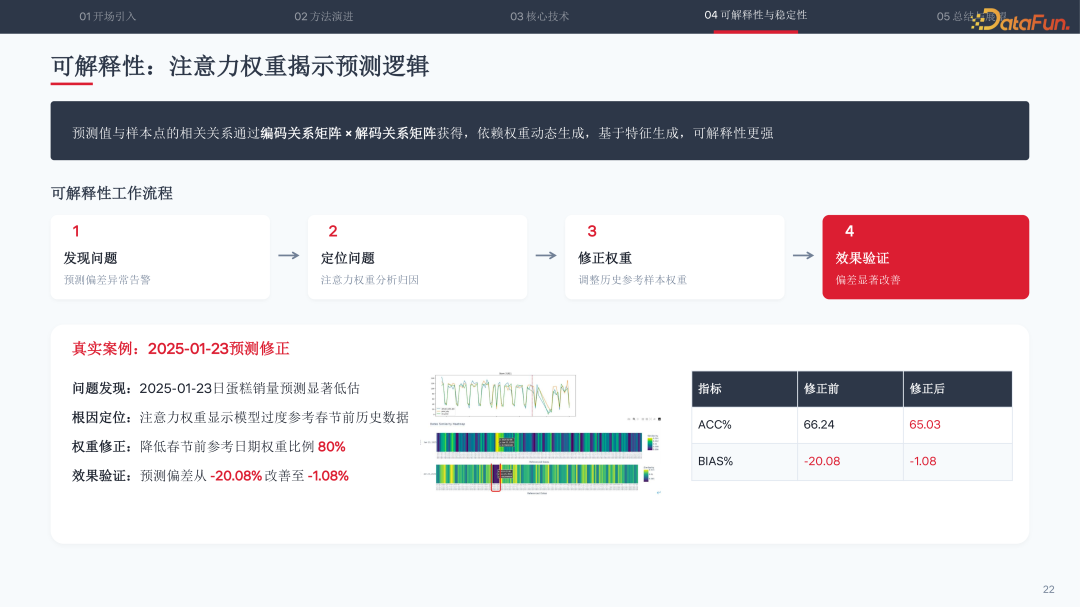
工业应用要求模型不仅精准,还需透明可控。Li-Net 通过注意力权重矩阵生成相关性热力图,直接定位预测依据。在一个真实案例中,2025 年 1 月 23 日蛋糕销量预测出现 -20.08% 的偏差,通过权重图发现模型过度参考了去年同期春节的异常销量。修正权重后,偏差显著改善至 -1.08%。
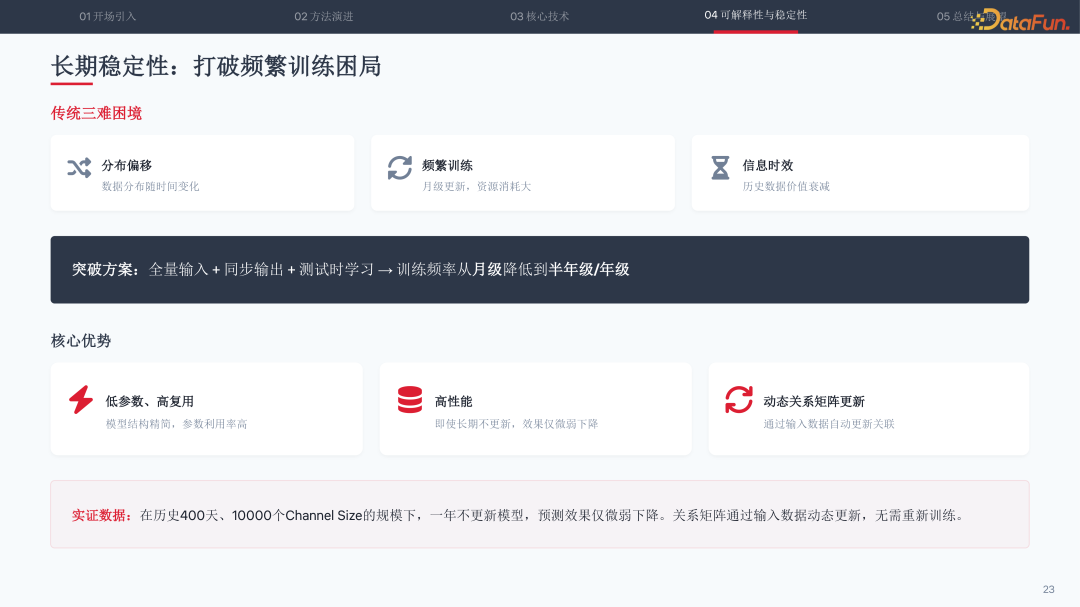
长期稳定性方面,Li-Net 采用“输入侧补偿”策略应对时序分布偏移:不频繁更新参数,而是将最近一年的完整历史数据作为输入窗口。模型通过正向推理动态计算相关性矩阵,利用最新数据驱动预测。实证显示,模型即使一年不更新,预测效果仅有微弱下降,训练频率从月级降至年级。
05 总结与展望
Li-Net 通过三大核心创新,破解了供应链预测的工业级难题:可学习的稀疏注意力机制统一了时空维度处理并降低复杂度,多模态导航融合以“注意力导航器”方式精准引入异构信息,轻量化 MLP 骨干网络实现 0.5MB 的极致压缩。在保持学术 SOTA 精度的同时,推理效率提升 14 倍、训练效率提升 120 倍、成本节约 46 倍,真正实现了从技术创新到业务价值的完整闭环。
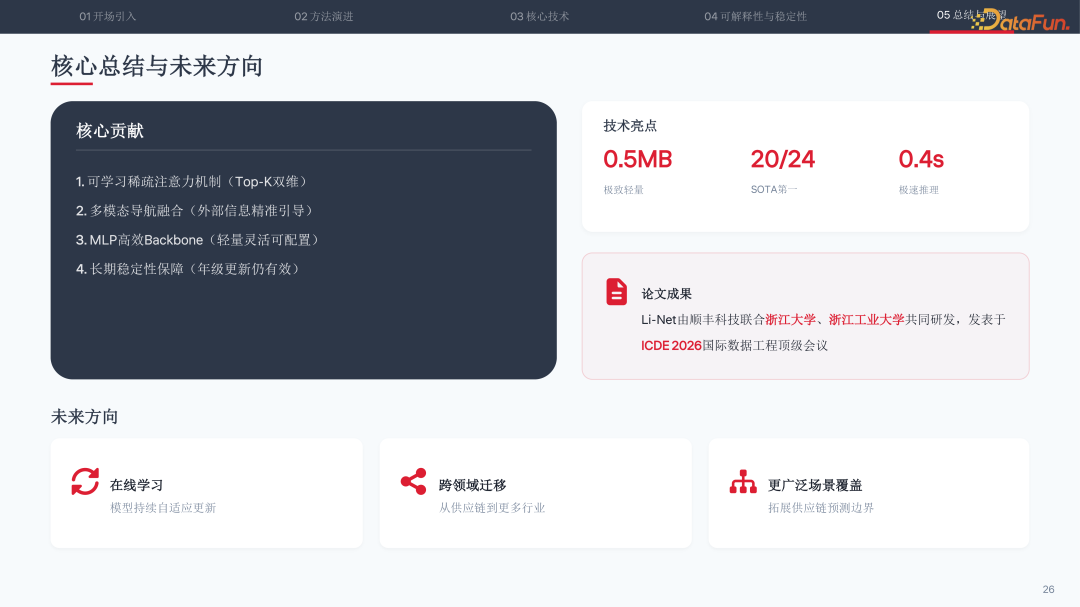
未来,顺丰团队将探索在线学习、跨领域迁移以及更广泛的供应链场景覆盖,持续推动时序预测技术在工业领域的深度应用。
06 Q&A
Q1:LightGBM 为什么不能直接进行长期预测?
包恒达:LGB 在做预测的时候,一般有两种方法。比如说我要去预测未来 28 天,第一种方法是针对每一天分别建立独立模型,拿昨天的销量预测今天建一个模型,拿昨天的销量预测后天再建一个模型,因为这些是不同的任务,这样可能需要建 28 个模型,成本非常高。
第二种方法是滚动预测,用昨天的预测值作为今天的特征,进行滚动预测,但这会导致“牛鞭效应”,误差会在迭代过程中逐渐叠加放大,影响长期预测的准确性。
Q2:为什么时序领域的 Transformer 不如 MLP?
包恒达:这主要由时序场景的两个核心特点决定。
第一是学术界的时序数据集普遍较小,大参数模型如 Transformer 容易过拟合,MLP 参数量更少,更适合小数据场景。
第二是时序场景中信息密度极度失衡,最近几天的销量信息权重占比可能达到 80%-90%,绝大部分信息密度集中在自身的时间序列数据上。
Transformer 引入的额外信息(跨通道、长轴关联)带来的噪音往往大于有效信息,导致效果反而变差。
MLP 在处理具有强线性相关性的时序场景时更具性价比,参数量小、训练快、不易过拟合,能够高效捕捉时序数据中的核心模式。这也是为什么 Li-Net 选择轻量化 MLP 作为骨干网络,最终实现 0.5MB 的极致压缩和优异性能的重要原因。
以上就是本次分享的内容,谢谢大家。
 发表于 2026-6-1 02:33:11
|
查看: 136|
回复: 0
发表于 2026-6-1 02:33:11
|
查看: 136|
回复: 0
