Claude Code 的记忆系统远不止“记住用户偏好”这么简单。它是一套精心设计的四层架构——从托管级全局指令到项目私有本地配置,再到自动化的背景记忆提取和语义相关性召回。本文将逐文件解剖这套系统的完整实现:路径解析的安全守卫、提示词构建的行为约束、上下文注入的缓存策略、背景提取的 fork 子代理模式,以及记忆相关性选择的 Sonnet 侧查询机制。
目录
- 概述
- 核心架构
- 2.1 记忆系统整体数据流
- 2.2 关键模块与职责
- 源码分析
- 3.1 路径解析与安全守卫
- 3.2 记忆类型分类
- 3.3 提示词构建器
- 3.4 CLAUDE.md 文件加载
- 3.5 上下文注入管线
- 功能详解
- 4.1 记忆写入:两步法协议
- 4.2 背景记忆提取
- 4.3 记忆相关性选择
- 4.4 Session Memory 与会话连续性
- 技术亮点
- 5.1 安全设计
- 5.2 缓存策略
- 5.3 特征开关体系
- 总结
- 参考文献
1. 概述
1.1 记忆系统的定位
Claude Code 作为一款 AI 编程助手,需要在多轮对话和跨会话场景中保持对用户、项目和团队的持续认知。记忆系统(Memory System)就是实现这一目标的核心基础设施。它解决的问题包括:
- 用户偏好如何跨会话持久化?
- 项目约定如何自动注入每次对话?
- AI 如何自动识别值得长期保存的信息?
- 如何在团队间共享项目知识和最佳实践?
从架构角度看,记忆系统是 Claude Code 上下文工程的核心组件,与系统提示词(System Prompt)和用户上下文(User Context)共同构成每次 API 调用的完整消息载荷。
1.2 四层记忆架构总览
Claude Code 的记忆系统分为四个优先级递进的层次,外加两套自动化记忆机制:
| 层级 |
类型枚举 |
来源路径 |
优先级 |
说明 |
| Managed |
Managed |
/etc/claude-code/CLAUDE.md 及 rules 目录 |
最低 |
管理员全局配置,所有用户生效 |
| User |
User |
~/.claude/CLAUDE.md 及 rules 目录 |
较低 |
用户级私有指令,跨项目生效 |
| Project |
Project |
CLAUDE.md、.claude/CLAUDE.md、.claude/rules/*.md(从 CWD 向上遍历) |
较高 |
随代码仓库版本控制 |
| Local |
Local |
CLAUDE.local.md(从 CWD 向上遍历) |
最高 |
本地私有,不加入版本控制 |
在此之上,还有两套自动化记忆:
- Auto Memory(
AutoMem):AI 自动从对话中提取并写入 <memoryBase>/projects/<sanitized-git-root>/memory/ 目录。含四种固定类型:user、feedback、project、reference。
- Team Memory(
TeamMem):存储在 <autoMemPath>/team/,通过 OAuth 服务端同步,支持团队共享。
2. 核心架构
2.1 记忆系统整体数据流
记忆系统的完整生命周期可以分为三个阶段:启动加载、上下文注入、背景提取。
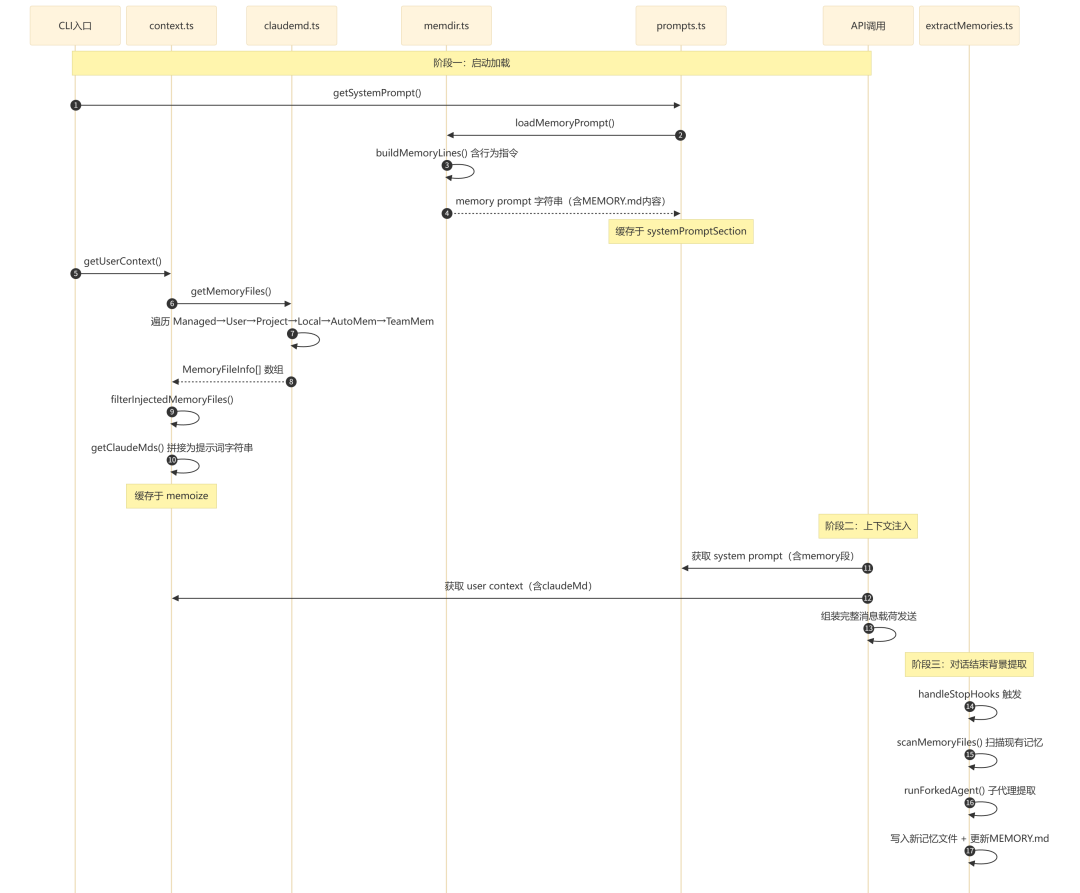
流程执行说明:
- 阶段一(步骤 1-10):启动时加载 memory 提示词和 CLAUDE.md 文件,两者分别走独立路径但都会被缓存。memory 提示词通过
systemPromptSection 缓存至 /clear 或 /compact;CLAUDE.md 通过 memoize 缓存。
- 阶段二(步骤 11-13):每次 API 调用时将缓存的两部分注入消息载荷。system prompt 的 memory 段包含行为指令(如何保存、四种类型、注意事项),user context 的 claudeMd 段包含实际文件内容。
- 阶段三(步骤 14-17):每轮对话结束后,背景提取服务检查是否需要提取记忆。如果主代理已在对话中写入记忆文件则跳过;否则启动 fork 子代理扫描并提取。
2.2 关键模块与职责
| 模块文件 |
职责 |
src/memdir/paths.ts |
路径解析与安全验证,定义记忆存储位置 |
src/memdir/memoryTypes.ts |
四种记忆类型定义及对应的提示词模板 |
src/memdir/memdir.ts |
提示词构建器,生成行为指令文本 |
src/memdir/findRelevantMemories.ts |
记忆相关性选择,Sonnet 侧查询 |
src/memdir/memoryScan.ts |
记忆文件扫描与清单格式化 |
src/memdir/memoryAge.ts |
记忆时效性判断 |
src/utils/claudemd.ts |
CLAUDE.md 文件发现、加载、解析(约 1200 行核心模块) |
src/context.ts |
用户上下文构建,调用 claudemd 并注入 claudeMd |
src/constants/prompts.ts |
系统提示词组装,含 memory 段注册 |
src/services/extractMemories/extractMemories.ts |
背景记忆提取服务 |
src/services/SessionMemory/sessionMemory.ts |
会话级记忆(用于压缩后连续性) |
3. 源码分析
3.1 路径解析与安全守卫
路径解析是整个记忆系统的基础,定义在 src/memdir/paths.ts。核心函数 getAutoMemPath() 采用三级优先级解析:
- 第一优先级:
CLAUDE_COWORK_MEMORY_PATH_OVERRIDE 环境变量(Cowork 场景的全路径覆盖)
- 第二优先级:
autoMemoryDirectory 设置项(来自 policySettings、flagSettings、localSettings、userSettings,显式排除了 projectSettings)
- 第三优先级(默认):
<memoryBase>/projects/<sanitized-git-root>/memory/
路径安全由 validateMemoryPath() 函数保障,它实施多层校验:
// src/memdir/paths.ts 第 109-150 行(简化)
function validateMemoryPath(raw: string | undefined, expandTilde: boolean): string | undefined {
if (!raw) return undefined
// ~/ 扩展仅对 settings.json 路径生效,env var 覆盖不扩展
// 拒绝相对路径、根目录、Windows 盘符根、UNC 路径、含 null 字节的路径
const normalized = normalize(candidate).replace(/[/\\]+$/, '')
if (!isAbsolute(normalized) || normalized.length < 3 ||
/^[A-Za-z]:$/.test(normalized) || normalized.startsWith('\\\\') ||
normalized.startsWith('//') || normalized.includes('\0')) {
return undefined
}
return (normalized + sep).normalize('NFC')
}
关键安全设计点:
projectSettings(.claude/settings.json,会被提交到代码仓库)被显式排除在 autoMemoryDirectory 的来源之外,防止恶意仓库通过设置项将记忆目录指向 ~/.ssh 等敏感路径。~ 扩展只对受信任的设置来源生效,且会拒绝扩展结果为 $HOME 本身或其父目录的裸 ~、~/、~/.、~/..。isAutoMemPath() 函数在每次文件系统工具调用时被调用,用于判断是否允许绕过危险目录保护(写操作 carve-out)。该函数内部做了 normalize() 规范化以防止 .. 路径遍历绕过。
记忆目录的启用/禁用控制链定义在 isAutoMemoryEnabled() 中:
// src/memdir/paths.ts 第 30-55 行(简化)
export function isAutoMemoryEnabled(): boolean {
// 1. CLAUDE_CODE_DISABLE_AUTO_MEMORY 环境变量
if (isEnvTruthy(envVal)) return false
// 2. --bare / SIMPLE 模式
if (isEnvTruthy(process.env.CLAUDE_CODE_SIMPLE)) return false
// 3. 远程模式无持久化存储
if (isEnvTruthy(process.env.CLAUDE_CODE_REMOTE) && !process.env.CLAUDE_CODE_REMOTE_MEMORY_DIR)
return false
// 4. settings.json 中的 autoMemoryEnabled
const settings = getInitialSettings()
if (settings.autoMemoryEnabled !== undefined) return settings.autoMemoryEnabled
// 5. 默认启用
return true
}
3.2 记忆类型分类
src/memdir/memoryTypes.ts 定义了四种封闭的记忆类型,每一种都对应一类“无法从当前项目状态中推导出来”的信息:
| 类型 |
中文含义 |
典型内容 |
user |
用户档案 |
角色、目标、偏好、责任、知识背景 |
feedback |
反馈指导 |
用户给出的工作方法指导,含成功和失败记录 |
project |
项目上下文 |
进行中的工作、目标、Bug、事故等非代码信息 |
reference |
外部引用 |
Linear 项目、Slack 频道、Grafana 面板等外部系统指针 |
类型定义的核心思想是“排除可推导信息”——代码模式、架构、文件结构、Git 历史等都可以通过 grep/git/CLAUDE.md 在运行时获取,不应作为记忆存储。这一约束通过 WHAT_NOT_TO_SAVE_SECTION 提示词强制传达给模型:
- 代码模式、约定、架构、文件路径、项目结构——可从当前项目状态推导
- Git 历史、最近变更——
git log / git blame 是权威来源
- 调试方案或修复步骤——修复方案在代码中,commit message 有上下文
- 已记录在 CLAUDE.md 中的任何内容
- 临时任务细节:进行中的工作、临时状态
其中有一条关键规则:即使当用户明确要求保存时,AI 也应拒绝保存可推导信息——如果用户要求保存 PR 列表或活动摘要,AI 应反问“其中有什么令人惊讶或非显而易见的部分?”
3.3 提示词构建器
src/memdir/memdir.ts 是整个记忆系统的“说明书生成器”。它的 buildMemoryLines() 函数将记忆系统的使用规则编译为模型可理解的提示词文本,包含以下核心段落:
保存协议(两步法):
第一步——将记忆写入独立文件(如 user_role.md),使用 frontmatter 格式,声明 name、description、type 字段。第二步——在 MEMORY.md 中添加一行指针(- [Title](file.md) — one-line hook),约 150 字符以内。MEMORY.md 是指针索引而非记忆本身,绝不直接在其中写入记忆内容。
MEMORY.md 截断机制:
MEMORY.md 在加载时受双重限制——最多 200 行、最多 25KB。超出任一限制时会被截断,并在末尾添加警告信息,指明触发的是行数限制还是字节限制。这迫使索引条目保持简洁,详细内容放入独立文件。
访问与信任指导:
系统提示词明确要求 AI 在以下时机访问记忆:记忆看起来相关时、用户引用之前的工作时、用户明确要求检查/回忆时。同时强调记忆可能过时——“The memory says X exists” 不等于 “X exists now”,在根据记忆做出推荐前必须验证文件和函数的存在性。
调度分发:
loadMemoryPrompt() 是提示词加载的顶层调度函数,根据启用的特性分发到不同路径:
// src/memdir/memdir.ts 第 419-507 行(简化)
export async function loadMemoryPrompt(): Promise<string | null> {
// KAIROS 每日日志模式优先
if (feature('KAIROS') && autoEnabled && getKairosActive()) {
return buildAssistantDailyLogPrompt(skipIndex)
}
// TEAMMEM 组合模式
if (feature('TEAMMEM') && teamMemPaths!.isTeamMemoryEnabled()) {
return teamMemPrompts!.buildCombinedMemoryPrompt(extraGuidelines, skipIndex)
}
// 标准 auto memory 模式
if (autoEnabled) {
return buildMemoryLines('auto memory', autoDir, extraGuidelines, skipIndex).join('\n')
}
// 全部禁用
return null
}
3.4 CLAUDE.md 文件加载
src/utils/claudemd.ts(约 1200 行)是记忆系统中最复杂的模块,负责发现、加载、解析所有指令文件。
加载顺序与优先级:
文件按 Managed → User → Project → Local 的顺序加载,后加载的优先级更高。在 Project 和 Local 层级,文件通过从 CWD 向上遍历到根目录来发现,越靠近 CWD 的目录优先级越高。
在每个目录中,Project 层会检查三个位置:
CLAUDE.md(项目根目录).claude/CLAUDE.md(隐藏目录).claude/rules/*.md(规则目录下的所有 markdown 文件)
文件解析管线:
parseMemoryFileContent() 函数对每个文件执行四步处理:
- Frontmatter 剥离:解析 YAML frontmatter,提取元数据(paths、description 等),将剩余内容作为指令正文。
- HTML 注释剥离:移除块级 HTML 注释(
<!-- ... -->),这些在 CLAUDE.md 中用作作者注释而不应注入模型上下文。
- @include 指令解析:支持
@path、@./relative/path、@~/home/path、@/absolute/path 四种格式。被引用的文件作为独立条目插入到引用文件之前。仅解析叶子文本节点(不在代码块或代码字符串内),并通过 processedPaths Set 防止循环引用。
- 截断处理:对 MEMORY.md 入口文件调用
truncateEntrypointContent() 应用行数和字节数双重限制。
条件规则(Glob 匹配):
CLAUDE.md 文件可以通过 frontmatter 中的 paths 字段声明适用范围。parseFrontmatterPaths() 提取 glob 模式,filterMemoryFileGlobs() 在加载时根据当前工作目录匹配——不匹配的文件被静默排除。这允许项目定义“仅对前端代码生效”或“仅对某子目录生效”的规则。
最终拼接:
getClaudeMds() 将所有 MemoryFileInfo[] 转换为单个提示词字符串,格式为:
Codebase and user instructions are shown below...
IMPORTANT: These instructions OVERRIDE any default behavior...
Contents of <path> (<description>):
<content>
Contents of <path>:
<content>
内容总量受 MAX_MEMORY_CHARACTER_COUNT(40,000 字符)限制。
3.5 上下文注入管线
记忆内容通过两条独立管道注入 API 调用,分别对应系统提示词和用户上下文:
管道一:系统提示词中的 memory 段
在 src/constants/prompts.ts 中,memory 段通过 systemPromptSection('memory', () => loadMemoryPrompt()) 注册。systemPromptSection 是实现缓存的关键机制——它创建一个惰性求值的缓存段,在 session 生命周期内(直到 /clear 或 /compact)只计算一次。
管道二:用户上下文中的 claudeMd
在 src/context.ts 中,getUserContext() 调用 getMemoryFiles() 获取所有指令文件,经 filterInjectedMemoryFiles() 过滤后通过 getClaudeMds() 拼接,结果存储在 { claudeMd } 键下。该函数通过 memoize 缓存,key 随项目根目录变化。
两条管道的分工:
- memory 段(管道一):包含行为指令——如何保存、四种类型、注意事项、MEMORY.md 内容。这告诉 AI“如何与记忆系统交互”。
- claudeMd 段(管道二):包含实际指令文件内容——用户的 CLAUDE.md 中的编码规范、项目约定。这告诉 AI“应该遵循什么规则”。
两者由 API 调用方(如 src/services/api/claude.ts)组装为最终消息载荷。
4. 功能详解
4.1 记忆写入:两步法协议
记忆写入由系统提示词中的行为指令驱动,AI 被教导遵循严格的两步流程:
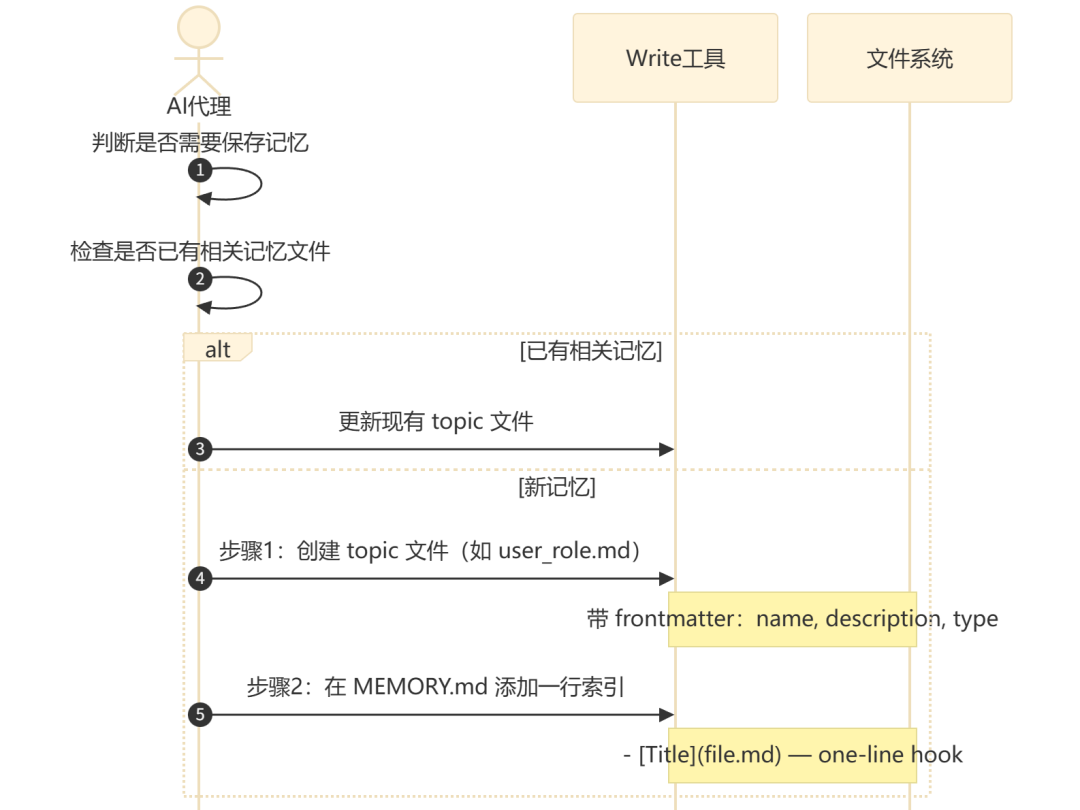
记忆文件的 frontmatter 格式:
---
name: {{kebab-case-slug}}
description: {{用于判断未来相关性的单行描述}}
type: {{user|feedback|project|reference}}
---
反馈类和项目类记忆的结构遵循特定模式:规则/事实陈述,然后跟 **Why:**(原因)和 **How to apply:**(如何应用)行。这种结构化格式使 AI 在未来遇到边界情况时能够做出判断,而非机械执行。
4.2 背景记忆提取
背景记忆提取服务(src/services/extractMemories/extractMemories.ts)是记忆系统的“自动化收割机”。它在每轮对话结束后通过 handleStopHooks 触发。
触发条件:
- 模型产生了最终响应(无工具调用)
- 主代理在本轮对话中未自行写入记忆文件(通过
hasMemoryWritesSince 检测)
- GrowthBook 特性开关
tengu_passport_quail 已启用
- 非交互式会话需要额外开关
tengu_slate_thimble
提取流程:
- 扫描现有记忆文件(
scanMemoryFiles()),构建清单。
- 构建提取提示词——包含当前对话摘要和现有记忆清单,指示子代理提取值得持久化的信息。
- 通过
runForkedAgent() 启动 fork 子代理——这是主对话的完美分支,共享父级的提示词缓存以减少 token 消耗。
- 子代理最多运行 5 轮,使用受限工具集(
createAutoMemCanUseTool),仅允许读写记忆目录内的文件。
- 子代理将新记忆写入 topic 文件并更新
MEMORY.md 索引。
- 通过
createMemorySavedMessage() 在 UI 中显示“Memory updated”通知。
合并机制:
如果新的提取请求到达时已有提取在进行中,系统会暂存新请求的上下文,在当前提取完成后执行一次尾随提取(trailing run),避免并发写入冲突。
4.3 记忆相关性选择
src/memdir/findRelevantMemories.ts 实现了智能记忆召回——不是将所有记忆都加载到上下文,而是根据用户当前查询选择最相关的记忆(最多 5 条)。
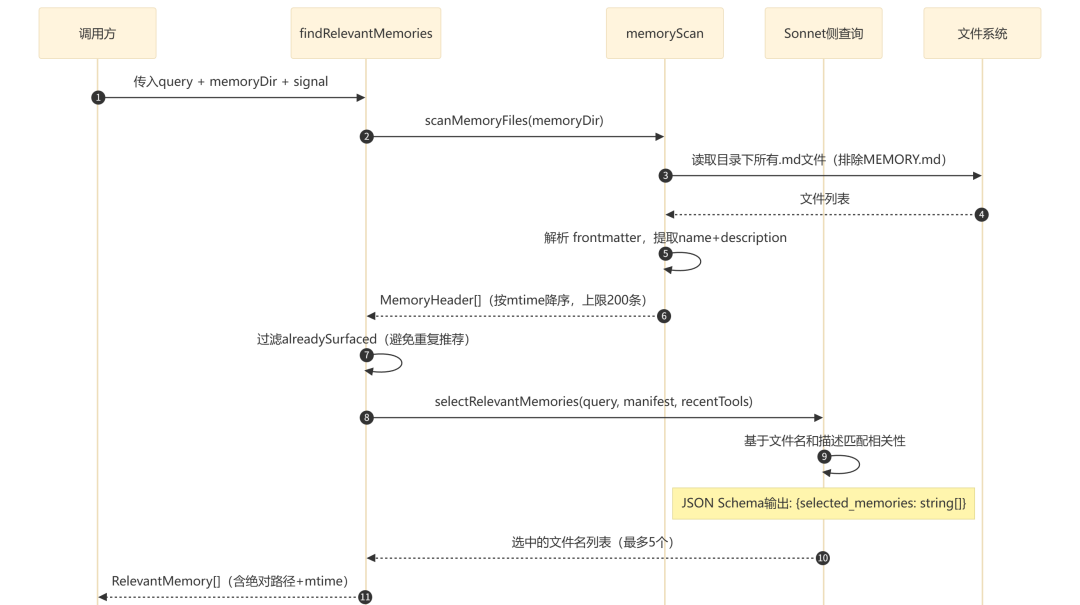
设计细节:
- 排除
MEMORY.md(已在系统提示词中加载)
- 排除
alreadySurfaced 集合中的文件(前几轮已经展示过的记忆)
- 传入
recentTools(最近使用的工具列表),防止 Sonnet 因关键词重叠而错误推荐正在使用中的工具的参考文档
- Sonnet 侧查询使用 JSON Schema 输出格式确保结构化返回
- 整个调用标记为
optional: true——失败时静默降级返回空数组,不阻塞主流程
- 通过
MEMORY_SHAPE_TELEMETRY 特性开关控制匿名统计(选中率、候选数等)
4.4 Session Memory 与会话连续性
Session Memory(src/services/SessionMemory/sessionMemory.ts)是一套独立的会话级记忆系统,与 Auto Memory 互补。
与 Auto Memory 的区别:
- Auto Memory 跨会话持久化,保存的是长期有价值的用户档案、反馈、项目上下文。
- Session Memory 存在于单个会话周期内,保存的是当前任务的进行状态——会话标题、当前状态、任务规格、涉及的文件和函数、工作流、错误与修正记录等。
触发逻辑:
Session Memory 提取通过 token 阈值和工具调用次数触发,在对话的自然断点处(如完成一个子任务后)运行。它同样使用 fork 子代理模式,将摘要写入 ~/.claude/projects/<slug>/<sessionId>/session-memory/summary.md。
与压缩系统的协作:
当对话上下文超出 token 预算触发压缩(compaction)时,Session Memory 的摘要文件被注入压缩后的上下文,确保关键状态信息不会因压缩而丢失。
5. 技术亮点
5.1 安全设计
记忆系统的安全设计是其最精心构建的部分:
- 路径遍历防护:
validateMemoryPath() 拒绝相对路径、UNC 路径、null 字节注入和根目录覆盖。
- 项目设置隔离:
projectSettings(.claude/settings.json)被显式排除在 autoMemoryDirectory 的来源之外,防止恶意仓库通过 PR 植入危险路径。
- 写操作 carve-out:只有通过
isAutoMemPath() 验证且非 CLAUDE_COWORK_MEMORY_PATH_OVERRIDE 覆盖的路径才能绕过危险目录保护进行写操作。
- Team Memory 路径校验:
validateTeamMemWritePath() 包含完整的符号链接解析,防止通过符号链接逃逸 team 目录。
- @include 循环引用防护:通过
processedPaths Set 跟踪已处理的引用路径,检测并跳过循环引用。
- 文件扩展名白名单:
TEXT_FILE_EXTENSIONS 集合定义允许的文本文件类型,防止二进制文件(图片、PDF 等)被意外加载到记忆上下文。
5.2 缓存策略
记忆系统在多个层级实施缓存以降低 I/O 开销:
getAutoMemPath() memoize:key 为 getProjectRoot(),避免每次渲染周期都执行 getSettingsForSource × 4 → parseSettingsFile(realpathSync + readFileSync)。getUserContext() memoize:key 为项目目录,CLAUDE.md 文件内容在一次会话中通常不变。systemPromptSection 缓存:memory 段在 session 生命周期内只计算一次,直到 /clear 或 /compact 才失效。getSystemContext() memoize:Git 状态等系统级上下文在一次查询周期内缓存。
5.3 特征开关体系
记忆系统通过多层特征开关实现灵活的功能控制:
| 开关 |
作用 |
CLAUDE_CODE_DISABLE_AUTO_MEMORY |
完全禁用 auto memory |
CLAUDE_CODE_SIMPLE |
bare 模式,跳过所有记忆 |
tengu_passport_quail |
启用背景记忆提取 |
tengu_slate_thimble |
允许非交互式会话的背景提取 |
tengu_moth_copse |
跳过系统提示词中的 MEMORY.md 索引(改用附件注入) |
tengu_herring_clock |
启用 team memory |
tengu_coral_fern |
启用“Searching past context”搜索指导段落 |
tengu_session_memory |
启用 session memory 提取 |
KAIROS |
每日日志模式(assistant 长会话) |
TEAMMEM |
编译时开关,控制 team memory 代码是否打入构建产物 |
6. 总结
Claude Code 的记忆系统展示了一套工程化程度极高的 AI 上下文管理方案:
- 分层架构:Managed → User → Project → Local 四级优先级,外加 AutoMem 和 TeamMem 两套自动化机制,形成完整的信息层次。
- 安全优先:路径验证、设置隔离、符号链接解析、扩展名白名单贯穿全链路,每一处外部输入都有对应的安全守卫。
- 自动化闭环:背景记忆提取 + SideQuery 相关性选择,实现了“写入自动化 + 召回智能化”的完整闭环,主代理只需遵循协议即可持久化知识。
- 缓存优化:memoize、systemPromptSection 缓存等多层缓存策略确保即使记忆文件数量庞大,I/O 开销也控制在可接受范围内。
- 灵活开关:通过环境变量、settings.json、编译时 define 和 GrowthBook 远程开关四级控制,既能细粒度调试又能全局一键关闭。
对于构建 AI 编程助手的团队来说,这套记忆系统提供了可复用的设计范式:用封闭类型分类约束信息熵、用两步法写入协议解耦索引与内容、用 fork 子代理实现非侵入式背景提取、用侧查询实现轻量级记忆召回。这些模式不限于 Claude Code,对于任何需要长期记忆的 AI Agent 系统,都具有极强的参考价值。想要深入探索更多此类前沿架构的设计哲学,在 云栈社区 能找到大量深度技术解析与同行的思想碰撞。
参考文献
[1] Claude Code 源码仓库: https://github.com/claude-code-best/claude-code
[2] Claude Code 官方文档: https://docs.anthropic.com/en/docs/claude-code
 发表于 2026-6-1 04:04:23
|
查看: 142|
回复: 0
发表于 2026-6-1 04:04:23
|
查看: 142|
回复: 0
