原文:A harness for every task: dynamic workflows in Claude Code
发布日期:2026 年 6 月 2 日 | 作者:Thariq Shihipar & Sid Bidasaria(Anthropic)
一、这篇文章在说什么?
Anthropic 为 Claude Code 推出了一项新能力,叫做动态工作流(Dynamic Workflows)。
用一句话概括:Claude 现在可以自己给自己搭脚手架——根据任务的具体情况,即兴设计一套多智能体协作方案,然后执行它。
这听起来像一个技术细节,但背后解决的是一个根本性问题:单个 AI 实例在处理复杂任务时,天然存在无法克服的局限。
二、过去的问题:单窗口作战的三个死穴
Claude Code 的默认工作方式是:在一个对话窗口里,既规划任务,又执行任务。对于普通的编码工作,这很高效。但一旦任务变得复杂、漫长、需要多角度验证,就会暴露三个典型失败:
1. 智能体懒惰(Agentic Laziness)
任务做到一半就宣告完成。比如安全审查要处理 50 个问题,Claude 处理了 35 个后说“完成了”。不是故意偷懒,而是随着上下文越来越长,注意力开始漂移。
2. 自我偏好偏差(Self-preferential Bias)
让同一个 Claude 既写答案又验证答案,它会不自觉地偏袒自己的结论。就像让一个人既当运动员又当裁判,结果是可以预见的。
3. 目标漂移(Goal Drift)
对话越来越长,早期设定的细节要求——“不要动 X 模块”、“边缘情况要特别处理”——会随着上下文压缩逐渐丢失。每一次内容摘要都是有损的。
这三个问题的共同根源:单一上下文窗口既是规划空间,也是执行空间,两者互相污染。
三、动态工作流的核心思路
解决方案很直接:别让一个 Claude 干所有事。
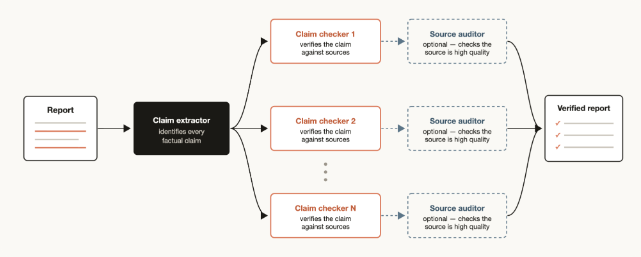
动态工作流让 Claude 先扮演“架构师”的角色——分析任务,设计分工方案,生成一个 JavaScript 编排脚本——然后这个脚本负责派发多个子智能体(Subagents)分头干活。
每个子智能体都有:
- 独立的上下文窗口,专注于自己的子任务,不受其他部分干扰
- 隔离的代码工作区(worktree),操作互不污染
- 可以独立指定的模型,简单任务用轻量模型,复杂任务用强模型
如果任务中途被打断,恢复会话后工作流可以从中断处继续,不需要从头开始。
四、Claude 是怎么“搭”这个脚手架的?
这是理解动态工作流最关键的部分。
Claude 不是套模板,而是根据具体任务即兴生成编排逻辑。
以一个真实场景为例:
“这个测试大概 1/50 概率失败,帮我找出 bug。”
Claude 会这样处理:
第一步:分析阶段(1 个主智能体)
读取代码,列出所有可能导致概率性失败的假说——竞态条件、随机数种子、网络超时、内存泄漏……假设生成了 5 个候选假说。
第二步:扇出阶段(5 个并行子智能体)
每个子智能体负责验证一个假说,在独立的工作区里反复触发测试、插入日志、收集证据,互不干扰地同时运行。
第三步:对抗验证(5 个挑刺智能体)
针对每个子智能体的结论,再派一个专门“找漏洞”的智能体质疑它——“你说是竞态条件,但你有没有排除 X 的可能?”
第四步:汇总(1 个合成智能体)
收集所有经过质疑仍然成立的假说,输出最终结论:最可能的原因、证据链、修复建议。
整个过程是 Claude 在理解任务后即兴设计的,任务不同,结构就不同。调试 bug 和筛选简历会生成完全不同的编排方案。
五、文章介绍的几种核心模式
这些模式是 Claude 在搭工作流时会使用的“基础积木”,可以自由组合:
| 模式 |
通俗理解 |
典型场景 |
| 扇出-合成 |
把任务拆成 N 份同时干,最后汇总 |
批量处理文件、并行研究 |
| 对抗验证 |
一个智能体输出,另一个专门挑毛病 |
代码审查、事实核查 |
| 锦标赛 |
N 个智能体各自提方案,裁判两两 PK |
命名、设计选型、方案比较 |
| 分类-路由 |
先判断任务类型,再路由到专门的智能体 |
工单分类、模型路由 |
| 生成-过滤 |
大量生成后按标准筛选 |
头脑风暴、候选方案生成 |
| 循环直到完成 |
不限轮次,直到满足停止条件 |
工作量未知的重构、迁移 |
六、适合用动态工作流的场景
文章给出了大量实际案例,归纳起来有几类:
大规模代码迁移
Bun 就是用工作流从 Zig 重写到 Rust 的。关键是把迁移拆成原子级的子任务,并行处理,每个修改都有独立的对抗验证。
概率性 Bug 调试
对于难以稳定复现的问题,工作流可以并行测试多个假说,而不是串行逐一排查,大幅提升效率。
大规模内容处理
批量处理简历、工单、日志、代码注释——扇出让每个条目都有独立的评估上下文,结果更可靠。
深度研究与报告生成
多个智能体分别搜索不同方向,再汇总合成带引用的报告,同时有验证智能体检查每一条事实声明。
经验沉淀
从历史对话中挖掘反复出现的修正意见,聚类后提炼成规则写入 CLAUDE.md——用机器挖掘机器的使用规律。
七、对开发者的实际意义
1. 省去了编排层的工程工作
以前要实现多 Agent 并行,需要自己设计数据流、写编排代码、处理失败重试。现在这层工作由 Claude 代劳,描述任务就够了。
2. 真正能接“大块头”任务了
过去靠单次对话无法可靠完成的任务,现在有了结构性保障。不是“试试看”,而是系统性地拆解和验证。
3. 算力变成可控的旋钮
可以明确指定模型选择、并行数量、token 预算——像调参一样控制任务深度和成本。
4. 工作流可以沉淀和复用
写好的工作流保存在 ~/.claude/workflows,可以打包进 Skill 分发给团队。组织的最佳实践第一次有了可传播的载体。
八、什么时候不该用?
文章对此很坦诚:动态工作流会消耗显著更多的 token,成本更高。
判断标准很简单:一个 Claude、一个对话窗口能可靠完成的事,就不用工作流。
它的价值在于突破单窗口的天花板,而不是替代日常的简单任务。用不对场景,只是在浪费算力。
九、一句话总结
动态工作流的本质是:把 Claude 从一个“单打独斗的执行者”变成一个“能设计团队协作方案的架构师”。它的价值不在于让 Claude 变得更聪明,而在于让 Claude 能够组织多个“自己”,通过结构性的分工和对抗,去完成那些单个实例天然无法可靠完成的复杂任务。
claudecode
由云栈社区整理发布,追踪前沿 AI 开发实践。
 发表于 2026-6-5 00:31:48
|
查看: 218|
回复: 0
发表于 2026-6-5 00:31:48
|
查看: 218|
回复: 0
