前言
有人问我:Redis 为什么单线程能跑出 10 万 QPS?Nginx 为什么比 Apache 快那么多?
这些问题的答案,藏在服务器架构三十年的演进史里。
从最早的“来一个请求开一个进程”,到今天的协程,每一次架构升级都是被现实逼出来的。理解这个演进过程,你就真正理解了高性能服务器的本质。
想深入探究后端 & 架构的核心设计思想,不妨先从这条进化之路开始。
我们从头说起。
一、单线程模型:能跑,但只能同时接一个人
最原始的服务器长这样:
int server_fd = create_listen_socket(8080);
while (1) {
int client_fd = accept(server_fd, NULL, NULL);
handle_request(client_fd); // 处理完才能接下一个
close(client_fd);
}
逻辑清晰,代码简单,但有个致命缺陷:handle_request 是阻塞的。
一个客户端在传文件,后面 999 个连接只能排队等。并发数=1,这不是服务器,是单人窗口排号机。
二、多进程模型:来一个客户,fork 一个儿子
为了解决并发,最直观的思路是:来一个连接,开一个进程处理它。
Apache 早期就是这么干的,叫 prefork 模型。
while (1) {
int client_fd = accept(server_fd, NULL, NULL);
if (fork() == 0) {
// 子进程:处理这个连接
close(server_fd);
handle_request(client_fd);
exit(0);
}
// 父进程:继续等下一个连接
close(client_fd);
}
并发问题解决了,但新问题来了:
进程太重了。每个进程独立的地址空间、文件描述符表、页表……光是 fork 一次的开销就不小,1000 个并发就是 1000 个进程。内存和 CPU 上下文切换的代价,随并发数线性膨胀。
这就是著名的 C10K 问题的根源之一——想撑住一万个并发连接,靠进程根本扛不住。
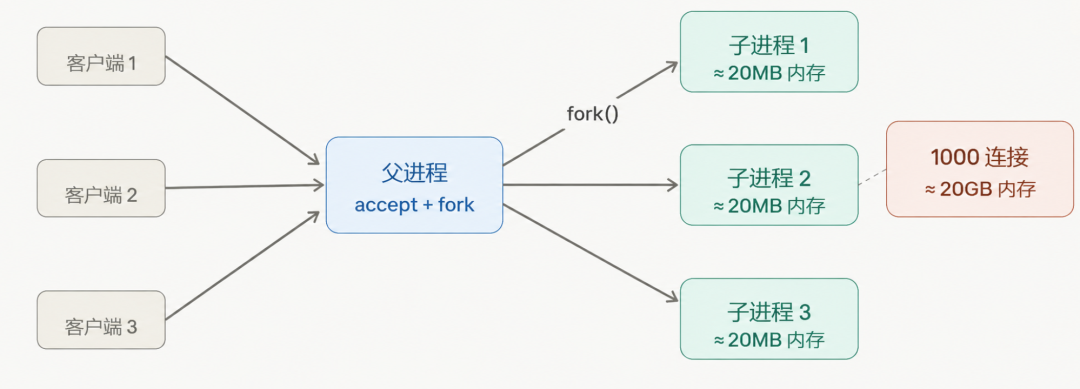
三、多线程模型:同一屋檐下,共享内存
既然进程太重,换成线程怎么样?
线程共享同一进程的地址空间,创建和切换比进程轻很多。于是有了“一连接一线程”的方案,后来又演进成线程池——预先创建好一批线程,来了任务往里塞。
// 线程池简化版
ThreadPool pool(100); // 预创建 100 个线程
while (1) {
int client_fd = accept(server_fd, NULL, NULL);
pool.submit([client_fd]() {
handle_request(client_fd);
});
}
比多进程好很多,但本质问题没变:
每个线程在等待 I/O 时是阻塞的。 1000 个连接,哪怕 990 个都在等网络数据,也得占着 990 个线程傻等。线程数一多,内核调度开销就上来了,而且每个线程还有独立的栈(默认 8MB),内存压力依然存在。
多线程模型的瓶颈,本质上是用线程来承载“等待”这件事,太浪费了。
四、Reactor 模型:只干活,不等待
这是高性能服务器真正的革命。
核心思想只有一句话:不要让线程去等 I/O,让 I/O 就绪了再通知线程来处理。
这就是 Reactor 模式,也叫事件驱动模型。
整个模型由三个角色构成:
事件分发器(Dispatcher):用 epoll 监视所有 fd,哪个 fd 有事件就通知对应的 Handler。
Handler:处理具体的业务逻辑,读数据、写响应。
Acceptor:专门处理新连接的到来。
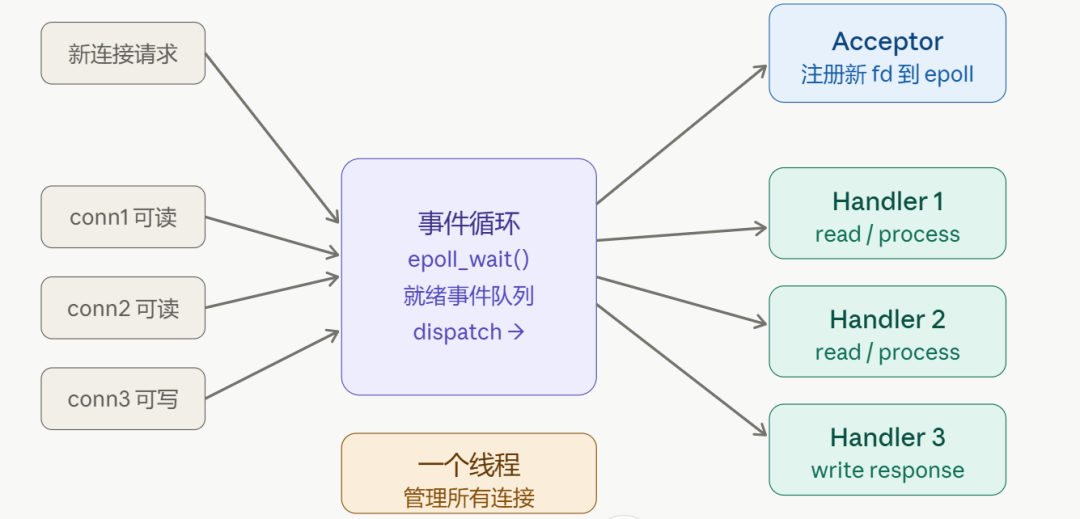
核心骨架代码就是这样:
// Reactor 核心循环(伪代码)
while (1) {
int n = epoll_wait(epfd, events, 64, -1); // 等事件
for (int i = 0; i < n; i++) {
int fd = events[i].data.fd;
if (fd == listen_fd)
acceptor_handle(fd); // 新连接
else
handler_dispatch(fd); // 读写事件
}
}
Nginx 就是这个架构:一个 worker 进程跑一个事件循环,用 epoll 管理数以万计的连接,哪个连接有数据来才去处理它,其余时间全在 epoll_wait 里睡觉——不占 CPU,不浪费线程。
这正是 Nginx 吊打 Apache 的根本原因。
五、Multi-Reactor:多核时代的进化
单个 Reactor 再猛,也只跑在一个 CPU 核上,没有利用多核优势。
于是有了 Multi-Reactor(也叫主从 Reactor):一个 Main Reactor 专门接受新连接,多个 Sub-Reactor 各自跑一个事件循环处理连接的读写。
这就是 Nginx 多 worker 进程、Netty 多 EventLoop 的本质。
Main Reactor(主线程)
└─ epoll 监听 listen_fd
└─ 新连接来了 → 分发给某个 Sub Reactor
Sub Reactor 0(线程0) Sub Reactor 1(线程1)
├─ conn1 ├─ conn3
├─ conn2 └─ conn4
└─ ... ...
负载均衡、多核并行,连接数到百万级也能扛。
六、Reactor 的隐痛:回调地狱
Reactor 模型有个绕不开的痛点:业务逻辑被打碎成一堆回调函数。
想象一个请求要做三件事:读请求 → 查数据库 → 写响应。
在多线程里,直来直去:
// 多线程:直线逻辑,清晰
read(fd, buf);
result = db_query(buf);
write(fd, result);
在 Reactor 里,就变成了这样:
// Reactor:逻辑被拆散成回调
on_readable(fd, [](fd) {
read(fd, buf);
db_query_async(buf, [](result) {
write(fd, result);
// 还有更多嵌套...
});
});
嵌套层数一多,就是臭名昭著的“回调地狱”——代码难以维护,调试更是噩梦。
这个问题,协程来解决。
七、协程:鱼和熊掌都要
协程的终极目标是:用同步的写法,达到异步的性能。
原理只有一句话:遇到 I/O 等待时,不阻塞线程,而是“挂起”当前协程,把 CPU 让出去执行其他协程;I/O 就绪后再“恢复”回来继续跑。
这个挂起和恢复,发生在用户态,不需要内核介入,开销极低。
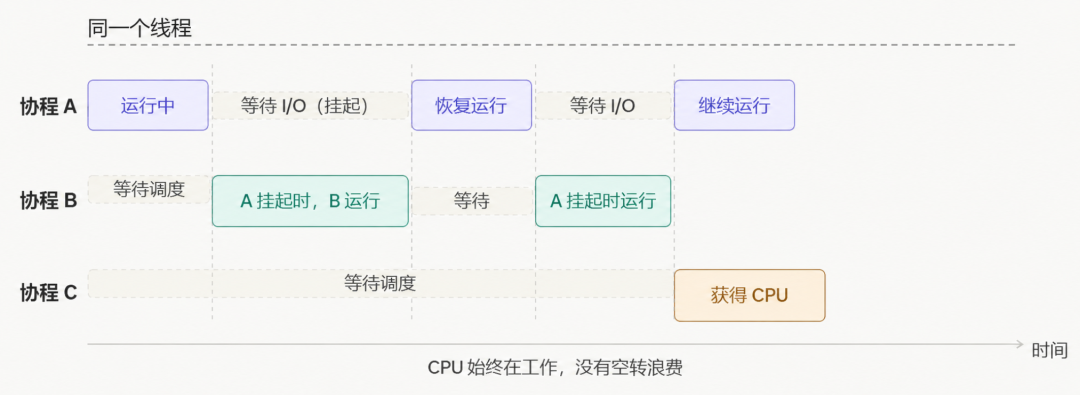
用协程写服务器,业务代码能保持多线程的直线逻辑,但底层自动做协程切换:
// 协程风格:看起来是阻塞的,底层是非阻塞的
co_await read(fd, buf); // 挂起,让出 CPU
result = co_await db_query(buf); // 挂起,让出 CPU
co_await write(fd, result); // 挂起,让出 CPU
// 代码像同步,性能像异步
这就是为什么 Go 语言的 goroutine 能让程序员用同步的写法写出高并发的程序——底层正是协程调度的功劳。微信的 libco、腾讯的 fiber,也都是基于这个原理。
八、五代架构终极对比
| 架构 |
并发能力 |
内存开销 |
代码复杂度 |
代表项目 |
| 单线程 |
1 |
极低 |
最简单 |
脚本服务 |
| 多进程 |
百级 |
极高(8MB/进程) |
简单 |
Apache prefork |
| 多线程池 |
千级 |
高(8MB/线程) |
中等 |
Apache worker |
| Reactor |
万~百万级 |
极低 |
高(回调) |
Nginx, Redis |
| 协程 |
万~百万级 |
极低(KB级/协程) |
中等 |
Go, libco |
九、高频面试题精析
Q:Redis 单线程为什么这么快?
数据库/中间件/技术栈 里的 Redis,其网络层就是单线程 Reactor——一个事件循环用 epoll 管理所有连接。它快的根本原因:① 操作全在内存,没有磁盘 I/O;② 命令处理时间极短(微秒级),不会长期占用 CPU;③ 不需要多线程,没有锁竞争开销。单线程 + epoll + 内存操作,三者叠加,就是 10 万 QPS 的底气。(Redis 6.0 引入了多线程处理网络 I/O,但命令执行仍是单线程。)
Q:Nginx 为什么比 Apache 快?
本质是架构差异:Apache 传统上用多进程/多线程模型(一连接一线程),线程数一多,切换和内存开销爆炸;Nginx 用 Multi-Reactor,每个 worker 进程跑一个事件循环,一个 worker 能管上万连接,几乎没有上下文切换,内存占用极低。
Q:协程和线程的本质区别?
线程切换由内核调度,需要陷入内核态,保存/恢复完整的 CPU 上下文,开销约数微秒;协程切换在用户态完成,只保存/恢复少量寄存器,开销在纳秒级。一个线程可以跑成千上万个协程,协程等 I/O 时让出 CPU 给别的协程,不浪费任何资源。
Q:什么场景用多线程,什么场景用协程?
CPU 密集型任务(加密、压缩、编解码)→ 多线程,充分利用多核并行。I/O 密集型任务(网络请求、数据库查询、文件读写)→ 协程,等待期间不浪费 CPU。绝大多数服务器业务是 I/O 密集型,协程优势明显。
结语
从单线程到协程,每一次架构升级背后都有一个核心矛盾在驱动:
- 多进程解决了“一次只能处理一个连接”的问题,代价是内存爆炸
- 多线程减轻了内存压力,但线程切换开销随并发线性增长
- Reactor 让线程彻底从“等待”中解放出来,一个线程管万连接
- 协程在 Reactor 高性能基础上,还消灭了回调地狱,让代码再次可读
这条路走下来,本质上就是一件事:不断减少“等待”对资源的浪费。
理解了这一点,你就理解了所有高性能服务器的设计哲学。
也希望云栈社区能成为你深入技术路上的一个讨论角落。
 发表于 2026-6-5 00:43:04
|
查看: 121|
回复: 0
发表于 2026-6-5 00:43:04
|
查看: 121|
回复: 0
