前两天有个读者问我:
“项目里序列化用 JSON 就好了吧,为什么大厂非要搞 Protobuf?”
这个问题问得很好。很多人写代码,序列化这件事从来没认真想过,能跑就行。
但当你的服务每天处理几亿次请求,序列化格式的选择,直接决定了你的带宽成本、CPU 消耗、接口延迟。
今天就把 JSON、Protobuf、MessagePack 这三个放在一起,彻底讲清楚。
先搞懂:序列化是在做什么?
程序里的数据——一个结构体、一个对象——是活在内存里的。你想把它存到磁盘,或者通过网络发给另一台机器,就必须把它“压扁”成一串字节。
这个过程就是序列化,反过来还原叫反序列化。
三个选手,一句话介绍
JSON:人能直接看懂,键值对文本格式,到处都支持。
Protobuf:Google 出品,二进制格式,体积小、速度快,需要提前定义 .proto 文件。
MessagePack:也是二进制格式,可以理解成“二进制版 JSON”,不需要提前定义 schema。
同一份数据,三种格式长什么样?
假设我们有这样一条用户数据:
用户ID: 1001
用户名: "xiaokang"
年龄: 28
是否VIP: true
JSON 序列化后:
{
"user_id": 1001,
"username": "xiaokang",
"age": 28,
"is_vip": true
}
可读性很强,但你注意到了吗?字段名 user_id、username 这些键也被完整传输了,纯属浪费。
Protobuf 序列化后(二进制,示意):
08 E9 07 12 08 78 69 61 6F 6B 61 6E 67 18 1C 20 01
没有字段名,只有字段编号 + 值,体积缩到极致。
MessagePack 序列化后(二进制,示意):
84 A7 75 73 65 72 5F 69 64 CD 03 E9 A8 75 73 65 72...
比 JSON 小,但因为还是保留了 key,比 Protobuf 大一些。
图解:三种格式编码方式

对比同样的 4 个字段,JSON 传了 60 字节,Protobuf 只用了 17 字节——差了将近 4 倍。
这不是 benchmark 数字游戏,而是实实在在的带宽和性能差距。当你的服务每秒处理 10 万条消息的时候,这个差距就会直接变成账单上的数字。
为什么 Protobuf 这么小?
核心原因只有一个:它不传字段名。
JSON 每次都要老老实实把 "user_id"、"username" 这些字符串打包进去,接收方才知道每个值是什么意思。
Protobuf 在 .proto 文件里提前定好字段编号,发送方只传编号+值,接收方拿到编号 1,就知道这是 user_id。
// user.proto
message User {
int32 user_id = 1;
string username = 2;
int32 age = 3;
bool is_vip = 4;
}
提前约定好,运行时就省掉了所有字段名的开销。这不仅是序列化格式的选择,更是一种典型的后端架构设计权衡——用前期的 Schema 定义成本,换取运行时的极致效率。
性能实测数据
光说体积还不够,实际的序列化速度呢?
用同一份 C++ 数据做 10 万次序列化 + 反序列化,结果如下:
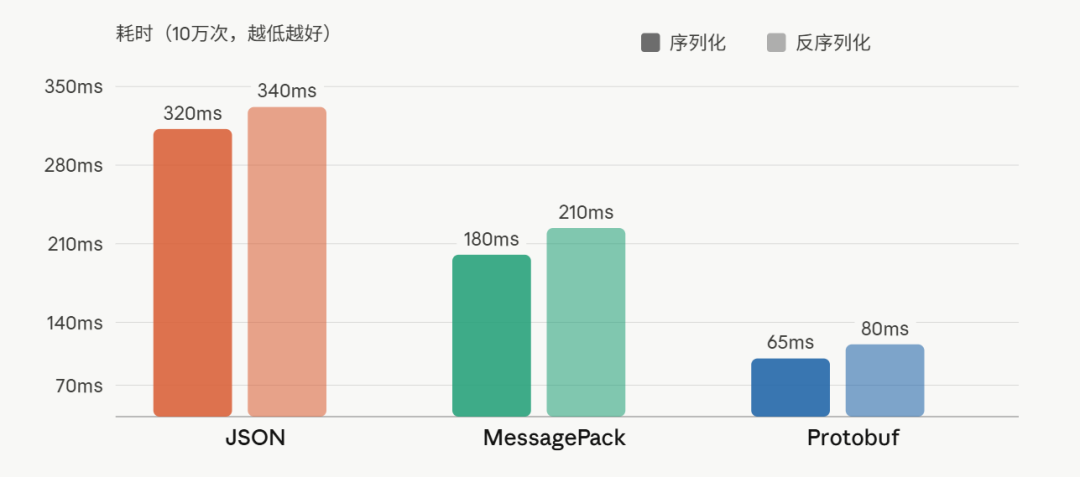
Protobuf 序列化只用了 65ms,JSON 用了 320ms,差距将近 5 倍。
这还只是 10 万次。你可以想象,在一个每天处理亿级请求的微服务里,这个差距意味着什么。
那什么时候用哪个?
三种格式都有自己的场景,不存在“谁更好”,只有“谁更合适”。
用 JSON 的场景:
- 对外暴露的 REST API(前端要能直接读)
- 调试、日志记录(人要能直接看)
- 对性能要求不高的内部接口
用 MessagePack 的场景:
- 想要 JSON 的灵活性(无需提前定 schema),但又在意体积
- 跨语言项目,不想引入 Protobuf 的编译流程
- 游戏、实时通信这类对体积敏感但接口变动频繁的场景
用 Protobuf 的场景:
- 高并发微服务之间的通信(RPC 首选)
- 对性能和带宽极度敏感的场景
- 接口相对稳定,愿意维护
.proto 文件
用代码感受一下差距
下面用 C++ 分别序列化同一份数据,感受三者的代码风格:
JSON(用 nlohmann/json):
nlohmann::json j;
j["user_id"] = 1001;
j["username"] = "xiaokang";
j["age"] = 28;
j["is_vip"] = true;
std::string data = j.dump(); // 直接得到可读字符串
Protobuf:
User user;
user.set_user_id(1001);
user.set_username("xiaokang");
user.set_age(28);
user.set_is_vip(true);
std::string data;
user.SerializeToString(&data); // 二进制,人看不懂,但很快
MessagePack(用 msgpack-c):
msgpack::sbuffer buf;
msgpack::packer<msgpack::sbuffer> pk(&buf);
pk.pack_map(4);
pk.pack(std::string("user_id")); pk.pack(1001);
pk.pack(std::string("username")); pk.pack(std::string("xiaokang"));
pk.pack(std::string("age")); pk.pack(28);
pk.pack(std::string("is_vip")); pk.pack(true);
可以看出:JSON 最直觉,Protobuf 需要预先生成代码,MessagePack 灵活但手写稍繁琐。
最后一张图总结

小结
选序列化格式这件事,没有银弹。
写对外 API——用 JSON,别让前端骂你。
写高并发内部服务、RPC——上 Protobuf,性能差距肉眼可见。
想要折中——MessagePack 是个不错的过渡方案。
大多数人在职业生涯早期会一直用 JSON,直到系统遇到性能瓶颈才开始考虑 Protobuf。理解背后的原因,你就能在架构评审里说得清楚为什么换、换了能带来多大提升——这才是真正的工程判断力。
 发表于 2026-6-5 00:52:44
|
查看: 173|
回复: 0
发表于 2026-6-5 00:52:44
|
查看: 173|
回复: 0
