年初入手了一本技术书,读完后便放在书架上积灰。前几天想翻查某个知识点,找了半天硬是没找到。转头问 AI,结果它张口就编;想做笔记吧,也想不起当初存到了哪个文件夹。更头疼的是,如果直接把一本四百页的 PDF 丢进 AI 对话框,还没等开口提问,上下文窗口早就被撑爆了。
于是去 GitHub 上找到了 book-to-skill 这个工具。它能把任意书籍或文件夹里的文档资料,打包成 Claude Code 的技能文件,随时查阅。

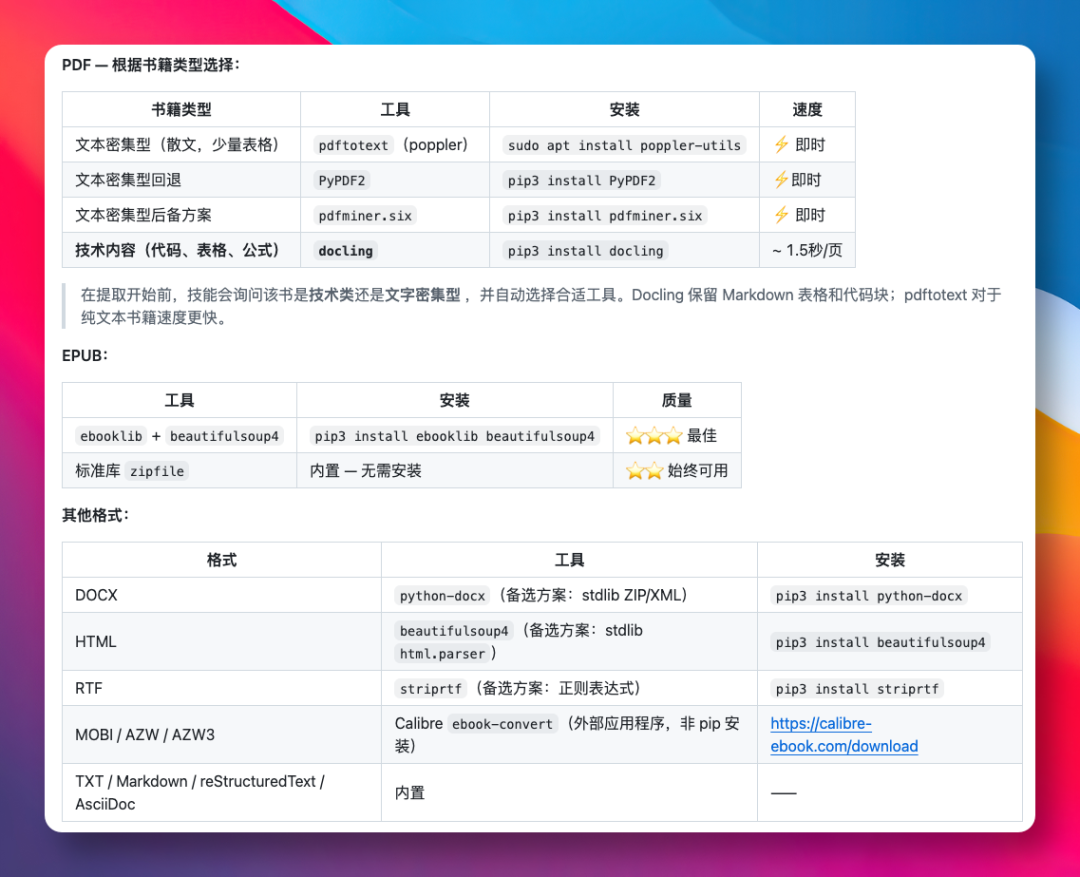
把 PDF、EPUB,甚至 DOCX、Markdown 等格式的文件传给它时,会先问一句:是技术类还是叙事类?如果是技术书,它会走 Docling 这条线,把表格和代码块原样抽出来;反之若是叙事类书籍,它就只做纯文本提取。之后会对整本书进行一次深度分析,拆开并重新组织,生成一个装着核心框架与章节索引的 SKILL.md 文件。然后每个章节单独保存为一个文件,还会额外配上术语表、模式表和速查表。值得一提的是,这些拆分好的章节文件并不会一次性全部塞进上下文,只有问到哪一章才读取哪一章。
在 Claude Code 里使用时,只需在终端输入 /技能名 关键词,它就会自动定位对应章节,照着原文回答。

用过 book-to-skill 后,发现它跟以往两种常见做法不太一样。一种是直接上传 PDF 文件,把整本书塞进上下文,每次对话都重新烧 Token,而且幻觉严重。另一种是通过 RAG,提问时去书里捞出几段文字相近的原文丢给 AI,能不能拼凑出正确答案,全看运气。
而 book-to-skill 走的是另一种路线:在生成技能之前,就对书籍做一次深度剖析,把作者的框架、反模式逐一命名抽离出来。等我们提问时,AI 调用的是这些已经“消化”好的框架,分析问题的准确度自然更高。
安装使用也非常简单,只需打开 Claude Code 发送下面这句话:
请读取下面链接文件内容,并安装好这个 Skill:
https://raw.githubusercontent.com/virgiliojr94/book-to-skill/master/SKILL.md
然后在对话里,就可以指定任意书籍进行处理:
/book-to-skill ~/path/to/your-book.pdf
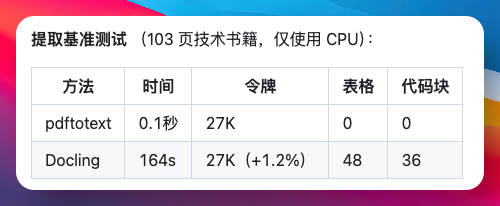
不过要注意,技术书采用 Docling 追求更高精度,代价就是慢。作者测试了一本 103 页的书要跑 164 秒,而纯文本提取只用 0.1 秒。
至于一些比较冷门的书生成完技能后,最好自己再过一遍,毕竟合成质量比单纯抽取更重要。另外,如果要在几十本书之间跨书检索,老实说,可能还不如直接用 NotebookLM 来得方便。它真正擅长的是把一本书或一组资料吃透,并融入到我们的工作流里,方便随时调用。
写在最后
过去想让 AI 读懂一本书,第一反应就是把整本 PDF 上传上去。如今有了更聪明的做法:先让工具把书读懂、拆解、结构化,再让 AI 按需取用。book-to-skill 做的,正是把书架上落灰的知识,变成随手可用的能力。下次再想重温一本念念不忘的书籍时,或许可以先把它喂给这个工具。
GitHub 项目地址:https://github.com/virgiliojr94/book-to-skill |  发表于 2026-6-6 18:19:24
|
查看: 574|
回复: 0
发表于 2026-6-6 18:19:24
|
查看: 574|
回复: 0
