老粉都知道,Claude Code、Cursor、Codex、OpenClaw,这些 AI 编程工具我都在用。可我越用越发现一件事:AI 写代码已经够快了,但 AI 完成一件事够不够格,没人管,经常跑完是一坨屎山。
让它改一个文件,三秒改好,可能改得还挺漂亮;但让它改一个跨五个文件的复杂任务,立刻从热心变胡来。流程、负责人、脚本、外部接口全揽到一起,写一份很漂亮但无法验收的方案。
我跟不少程序员朋友聊,发现这不是我一个人的痛苦。
一个做企业内网的哥们说,他们用 Cursor 写了两个月,AI 每次都说完成了,但每次都要花半天翻聊天记录去判断它到底做了什么。另一个做电商系统的朋友更直接,AI 帮他写支付回调,跑起来才发现漏了一个边界 case,钱多扣了没退。
这不是 AI 能力的问题,是 AI 做完事以后,没有人帮它把身份分清楚、把证据留下来、把结果分门别类。
于是我做了 Meta_Kim。
本篇有些长,但相信我,如果你看完本篇,并且研究清楚了本项目,基本上目前 AI 常用的内容你就全会了。

元架构的创立之初,我就讲过,它基于我多年的产品经验和管理经验,做的其实是现实世界的镜像映射。
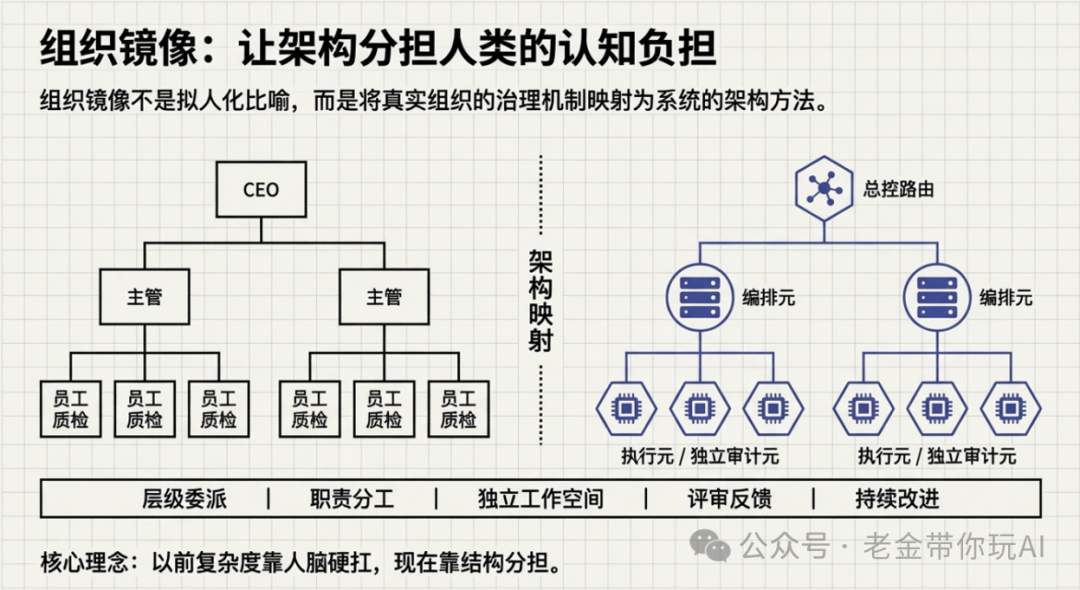
直白讲,Claude Code、Cursor、Codex、OpenClaw 这些工具是干活的手,能写代码、改文件。Meta_Kim 是管事的人,决定先做哪件事、用哪个能力、谁来负责、做到什么程度算交差、怎么证明做完了、怎么避免下次犯同样错误。
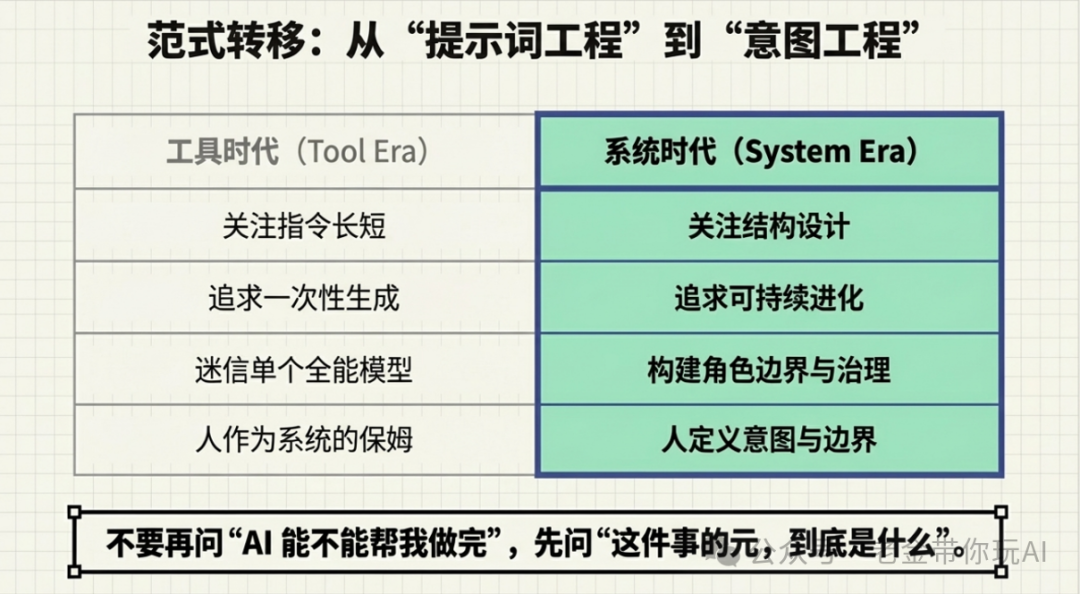
它解决的是一个具体问题:复杂任务别再让一个万能 AI 硬接。真实世界也是如此,没见过哪个 CEO 去关注字体应该多大,也没见过一个执行人员反过来去管战略。位置不同,职责也不同,他们应该做好分内之事——这不就是 AI 的上下文管理问题吗?
我这几年一直在研究一件事:AI 编程从能写代码,进化到能稳定交付复杂任务,中间缺的那块砖到底是什么。
最后我把它叫作“元”。元就是复杂任务里的最小可治理单元。
不是最小零件——零件不一定要被协作、编排、验证、替换。元必须能独立理解、足够小、边界清晰、能被替换、能复用。
一个合格的元至少要满足五条:
- 能独立理解,单独拿出来能讲清在管什么
- 足够小,小到改它不会动全身
- 边界清晰,写清楚管什么、不管什么
- 可替换,坏了能换一块不塌
- 可复用,换个流程还能拿出来用
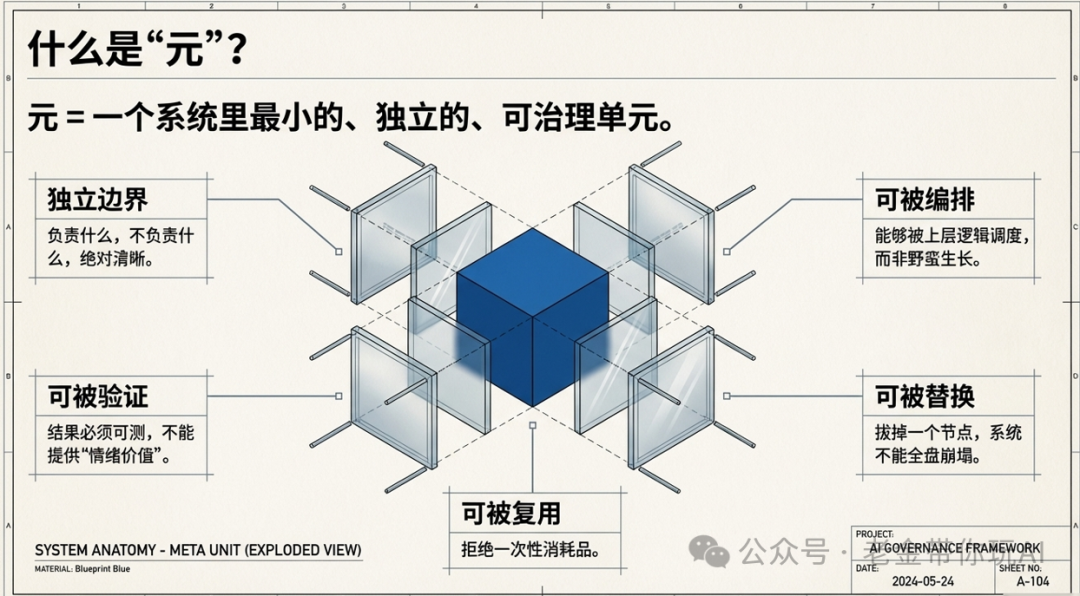
五条凑齐才算一个完整的元。缺一条就会碎、就会胀、就会用完就扔。
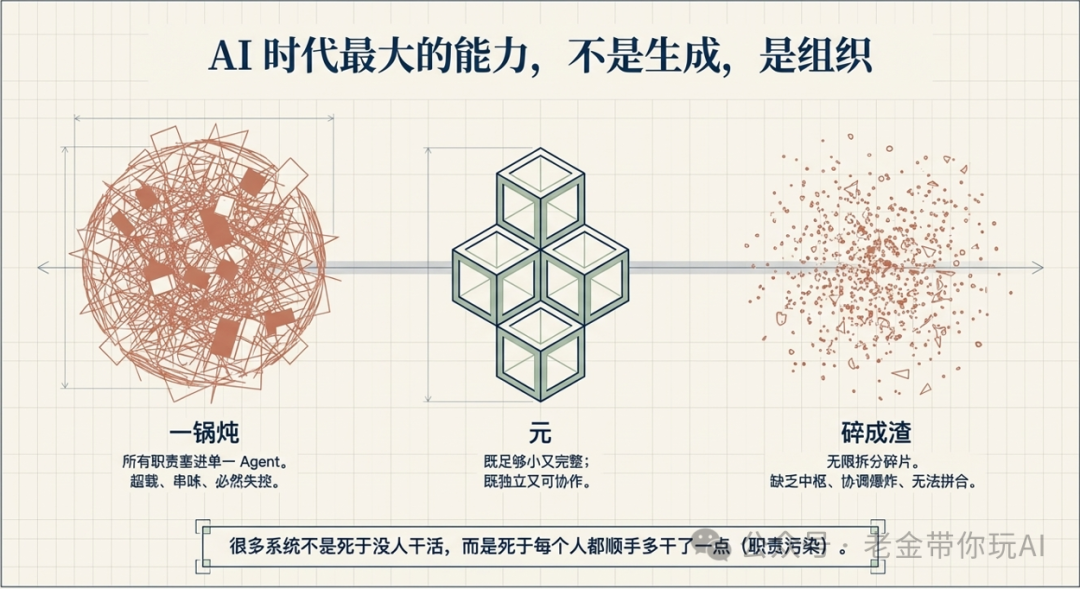
很多人用 AI 做出来的东西改不动、交不了付、下次还得从头来,根上就是因为没拆成元。
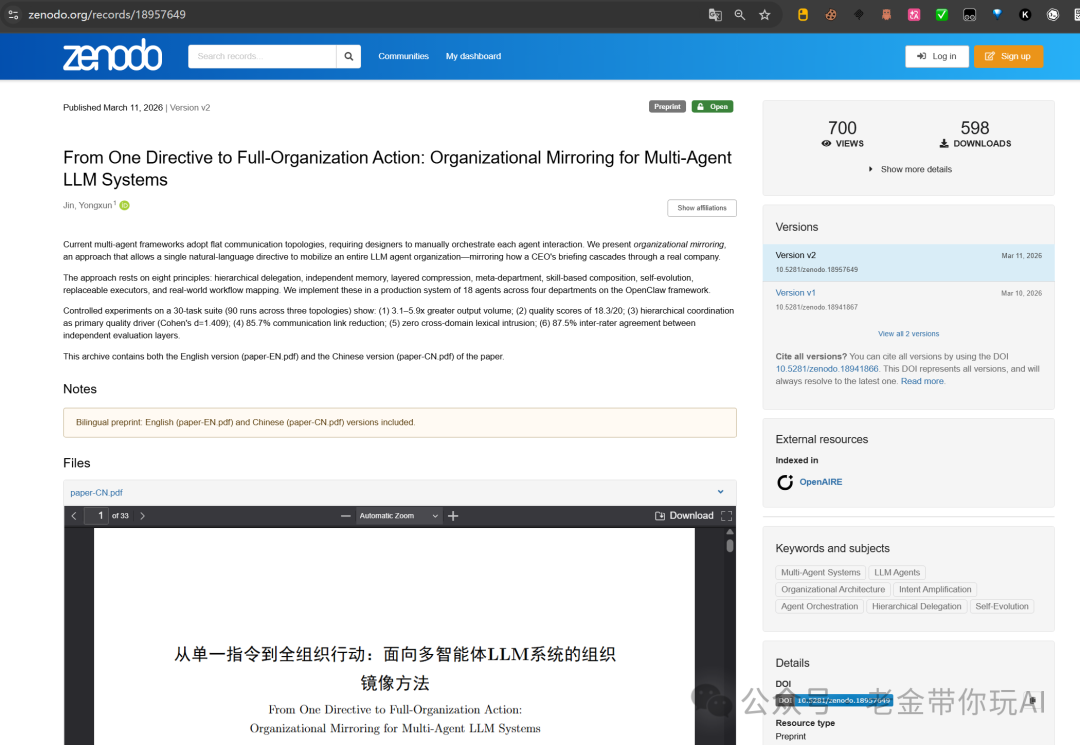
元这个概念我在自己的学术论文里完整论证过(再次感恩 AI 给了我这个老登学渣一次能再次学习的机会)。DOI 是 10.5281/zenodo.18957649,在 Zenodo 上已经被下载接近 600 次了。
我也在 WaytoAGI 做过 2 场直播专门讲这个事,主题就叫“为什么很多人用 AI 越用越乱”。
Meta_Kim 就是“元”这个概念第一次系统性的落地。
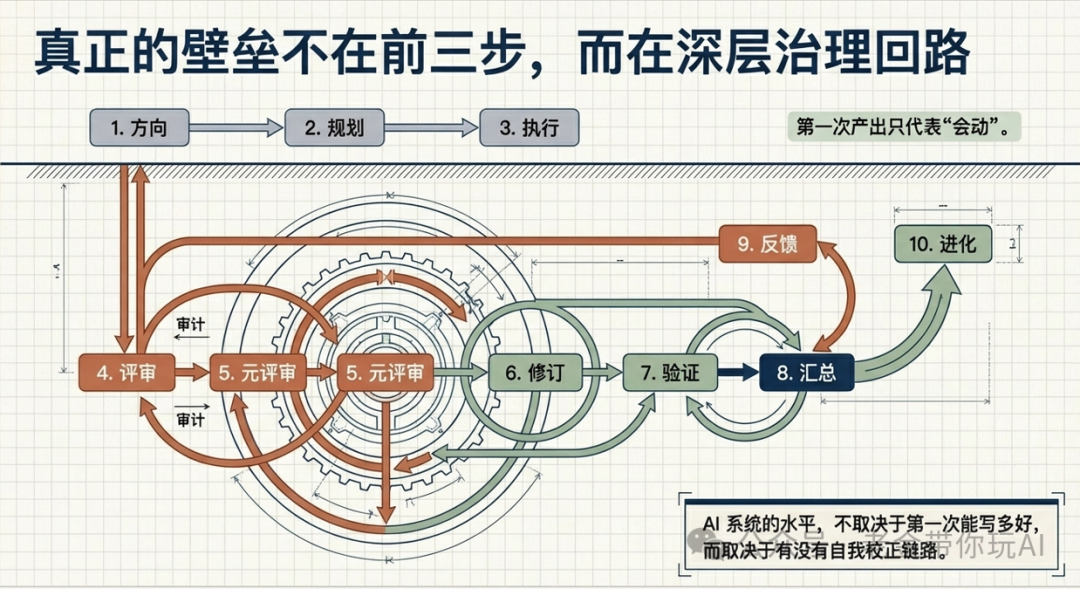
它的执行主干是 8 个固定阶段:澄清需求(Critical)、找能力(Fetch)、定方案(Thinking)、派活(Execution)、检查结果(Review)、再检查(Meta-Review)、验证现实(Verification)、把教训写回下次(Evolution)。前三个阶段全是“想”,Execution 是唯一“做”,后四个阶段全是“验”。
这 8 个阶段是骨架。骨架背后还有一道道门,门决定一个阶段能不能过;每个节点都有合同,明确必须输出什么;干的过程中还有 Dealing(动态干预),根据现场情况插队调整。
整套东西是基于我多年在游戏研发行业作为产品和管理的经验抽象总结的。游戏研发涉及多版本、多部门协同,本就是一件非常复杂的事项。
它解决什么痛点
我迭代了几个月,提交了 400 多次迭代,挡住最多的是 3 类麻烦。
假完成:
AI 说做完了,但没说凭什么说做完。Meta_Kim 会留下报告和证据,至少能回头查。
乱分工:
一个任务里混着流程、负责人、脚本、外部接口,普通 AI 容易全自己接。Meta_Kim 会先拆类型,再分给不同的能力。
乱沉淀:
临时任务不该变成永久规则。Meta_Kim 专门留了一个判断叫 worker_task_only,意思是这件事只这次处理,不进长期系统。
我只在 Claude Code 和 Codex 上跑通了完整流程,OpenClaw 和 Cursor 及其他运行平台只过了冒烟测试,它会把同一套规则同步过去。如果你在用 OpenClaw 或 Cursor 或其他的运行平台,欢迎提交 PR 帮我把覆盖补齐。
怎么安装
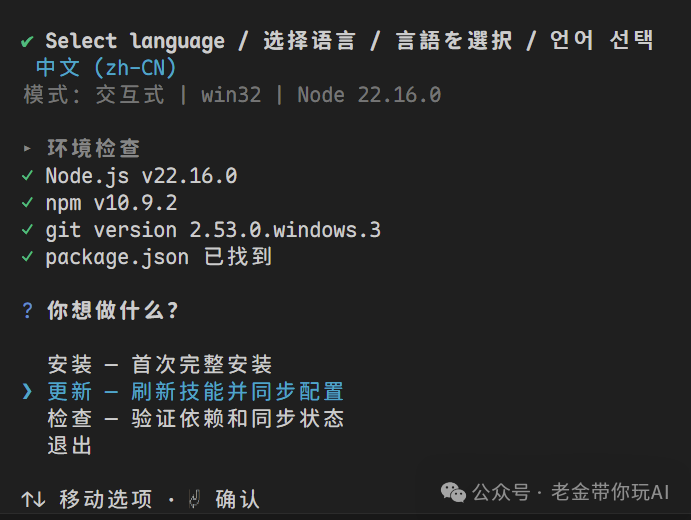
很简单,三步。
第一种方式,最快,一行命令:
npx --yes github:KimYx0207/Meta_Kim meta-kim

如果你的网络链接不上,那就用第二种方式,传统 git clone:
git clone https://github.com/KimYx0207/Meta_Kim.git
cd Meta_Kim
npm install
node setup.mjs
硬条件就一个:Node.js 不低于 22.13.0。版本不够后面脚本跑不起来。
因为还涉及一系列其他依赖项目,我建议定期进行更新,操作同上,选择时候,选择更新就可以了。
这些都是老金实测下来觉得好的,包含老金我自己设计的几个。如果你本地有其他的,也没关系。它在执行的时候会全盘扫描你的本地有什么能力(不单指 Skill,含 rules、mcp、Command、hook 等全方位)。
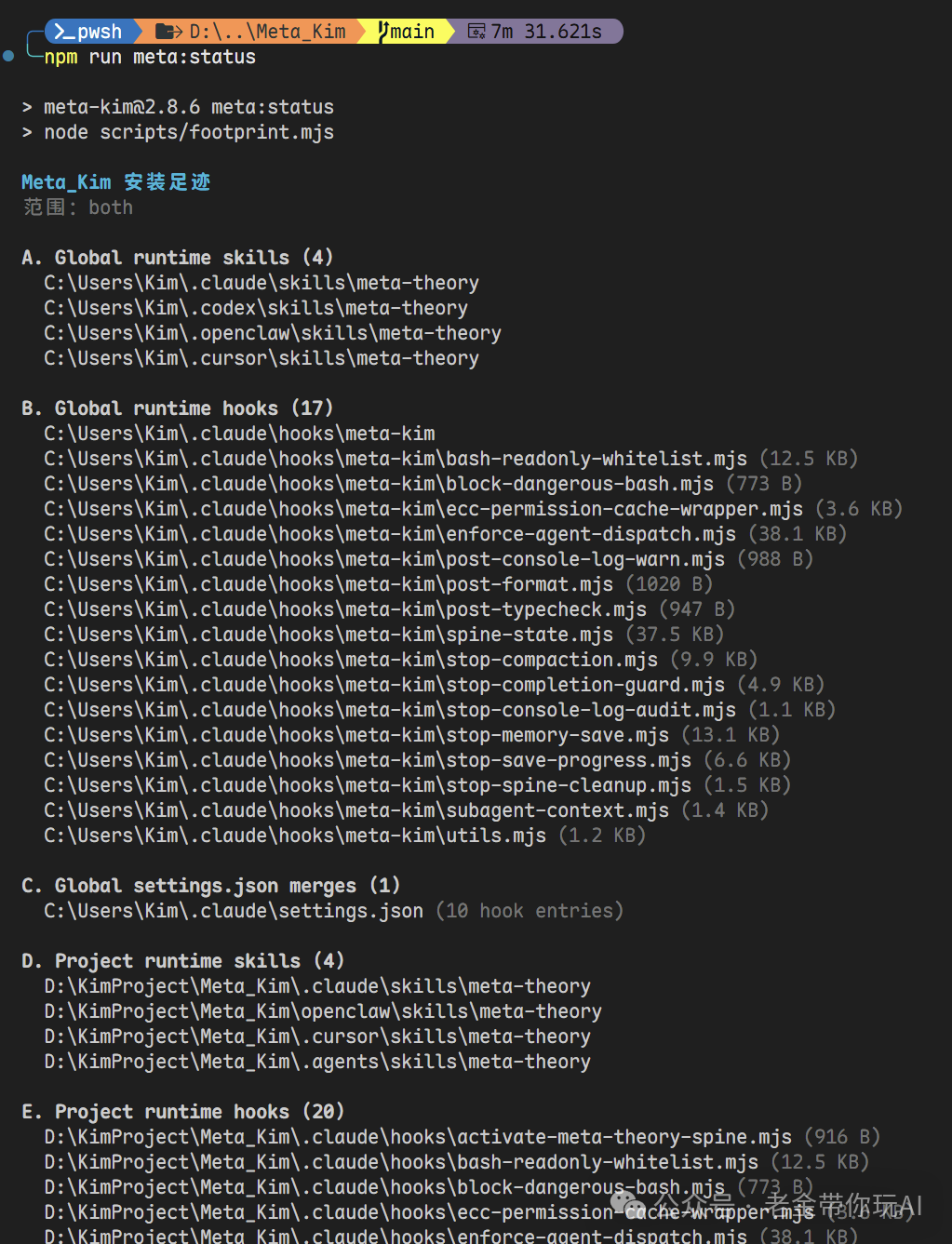
装完跑一条命令看看装了什么:
npm run meta:status
这条命令会告诉你每个产物放在哪、跟上次安装有什么差异。
如果你打算维护这个仓库,编辑的时候先动这几处:canonical/agents/、canonical/skills/meta-theory/、config/contracts/、config/capability-index/。改完跑两条命令同步并校验:
npm run meta:sync
npm run meta:validate
整个安装过程,不超过五分钟。
怎么用
用 Meta_Kim 跑一次完整治理,体验三步走。
第一步,直接使用 /meta-theory 技能作为强制触发全流程的前提。
/meta-theory 你想做的事情XXX
这条命令会启动一次被 Meta_Kim 管理的任务。任务里 AI 会按 8 个阶段走完一轮。
第二步,根据你的问题,进行深刻的意图放大,包含澄清定位你的准确需求,以及帮你联想此方向上的可能性,通过交互式弹窗给你进行展示。
我基本上各个 LLM(大语言模型)都在用,也几乎都是季度或年费会员。本次给大家看看 Minimax M3,这个通常大家觉得有些弱的模型,在 Meta_Kim 的加持下,能做出来什么。有一说一,M3 在 Meta_Kim 的加持下,我认为是不输 Sota 模型的。甚至于说它的多模态,含配音、画图、视频之类的也还凑合,我经常使用它的配音。
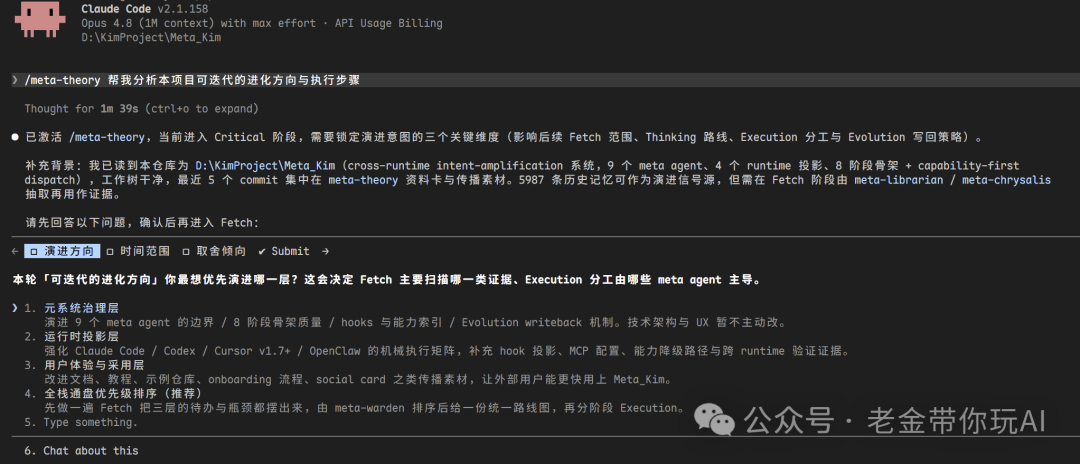
看到了么,它会先帮你澄清你的准确意图,帮你想好你到底要做什么。并且在一切可能引起不同结果的决策上,实时提问,一层层帮你想清楚你到底要做什么,以及做每件事的边界都是什么。
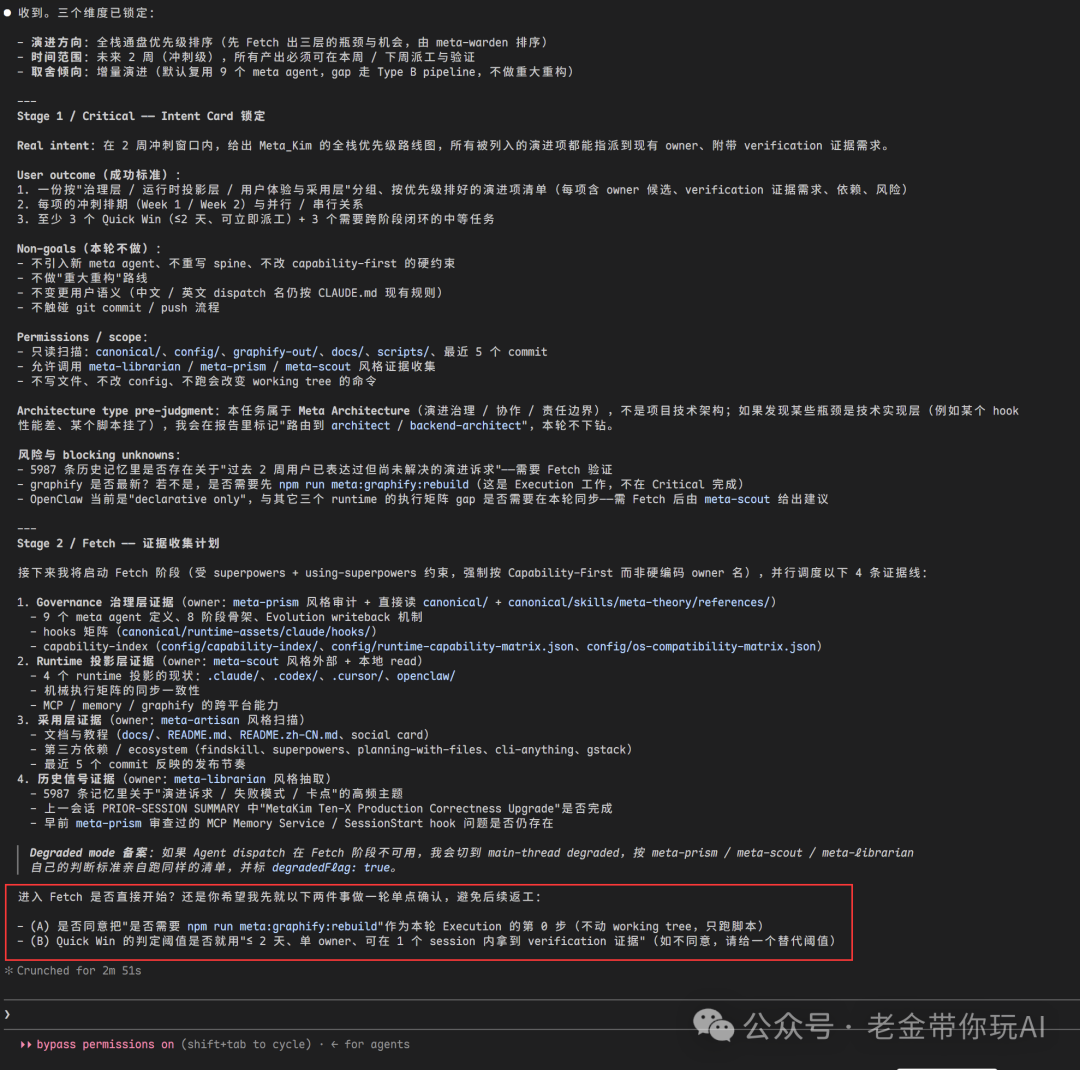
然后它会开始 Fetch 一切的证据,来证明它要怎么进行一件事,确保做的是对的,还会给你输出报告文件,让它的一切操作,可追溯。
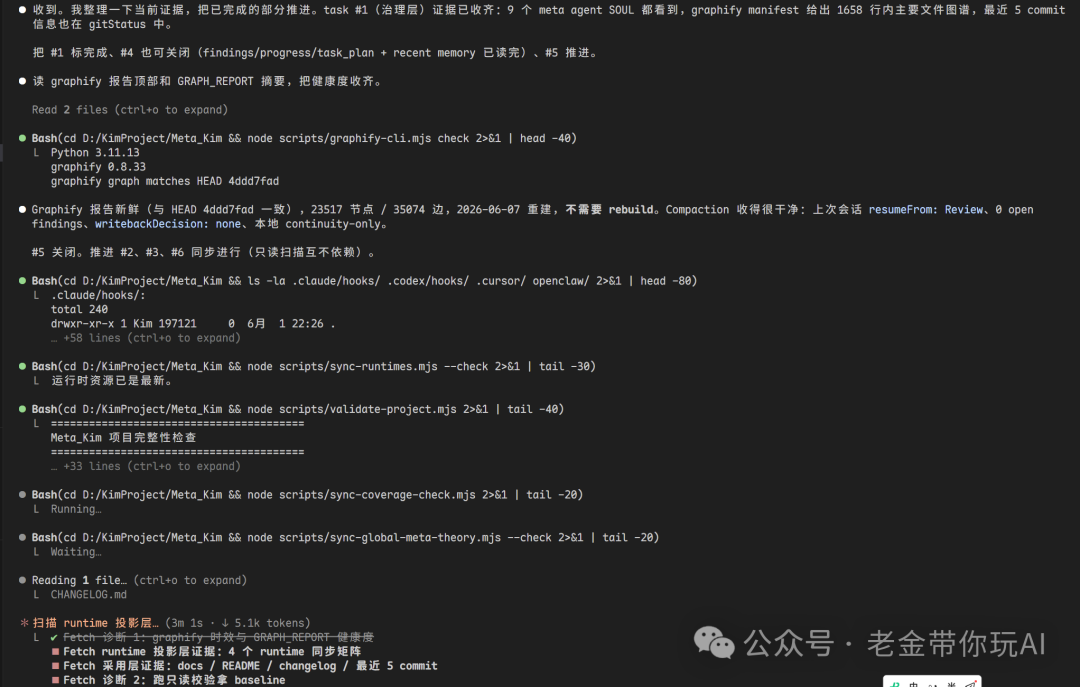
报告里会写清楚 AI 每一步做了什么判断、走了哪条路、为什么选这个方案、哪些地方通过、哪些地方没通过。
之后会进入详细的推理过程,看这里,非常的全面,让人直接可以看懂。什么问题,证据在哪,风险程度什么样子,谁来负责,怎么修改等等一目了然。
这时候,来到了留白,这是老金创建的一组发牌系统策略,完整的教程请看之前关于元的文章,在我的开源知识库中。
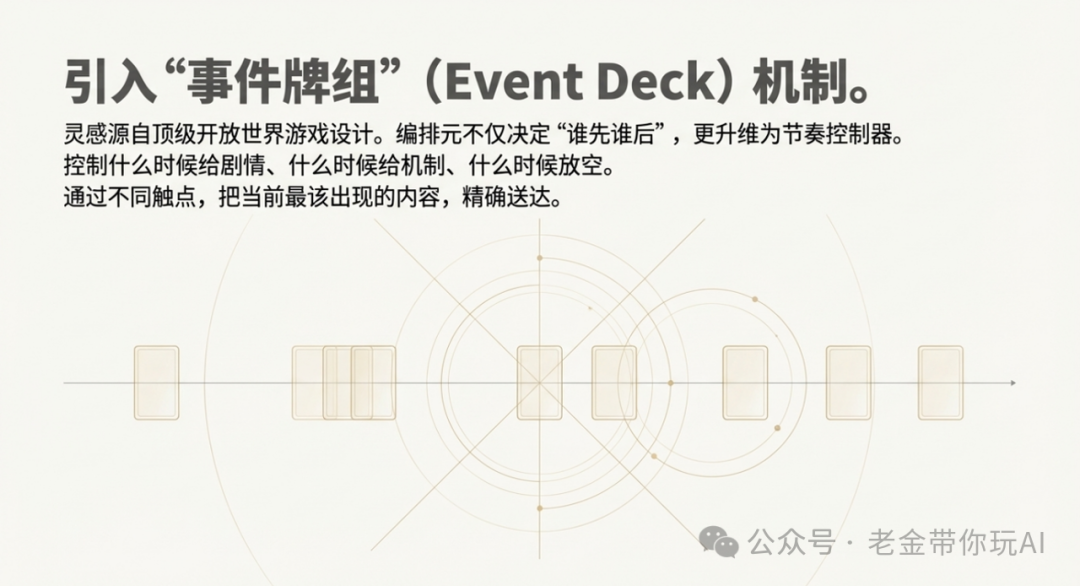
我要验牌,对的,就是验盘。发牌这套体系,可以简单理解如下图:
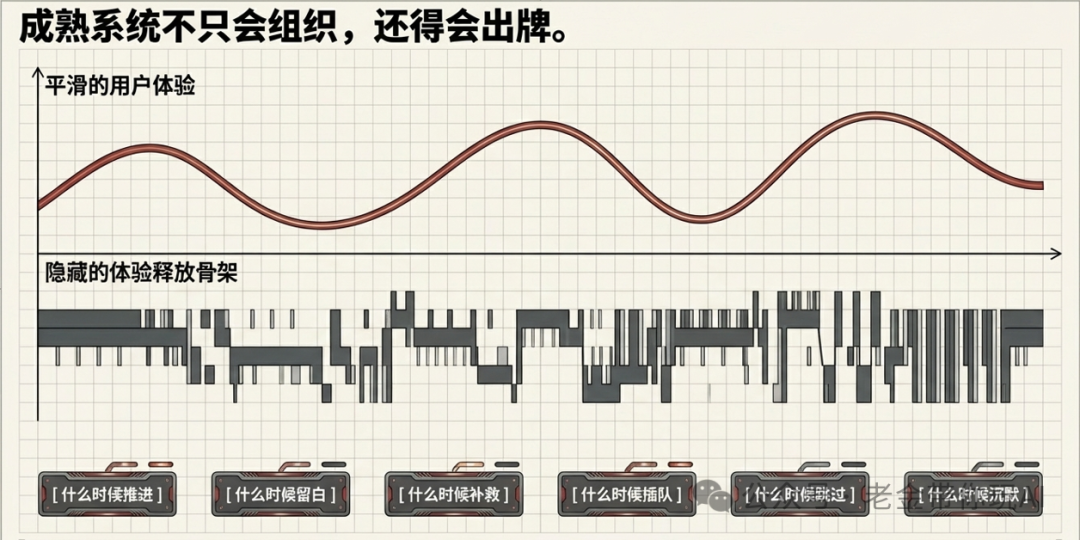
留白的目的就是停下来,不要 AI 直接做,让人来进行判断,以确保确确实是人想要的,而不是 AI 瞎猜的。

它更多的作用是让人来判断,人机协同老金已经强调过多次了。人与 AI 的职责职能的边界是清晰可见的。

来看看它给出面向用户的真实意图的执行方案,这步如果你看不懂,也没关系。很简单,给他输入三个字“说人话”,就可以了。
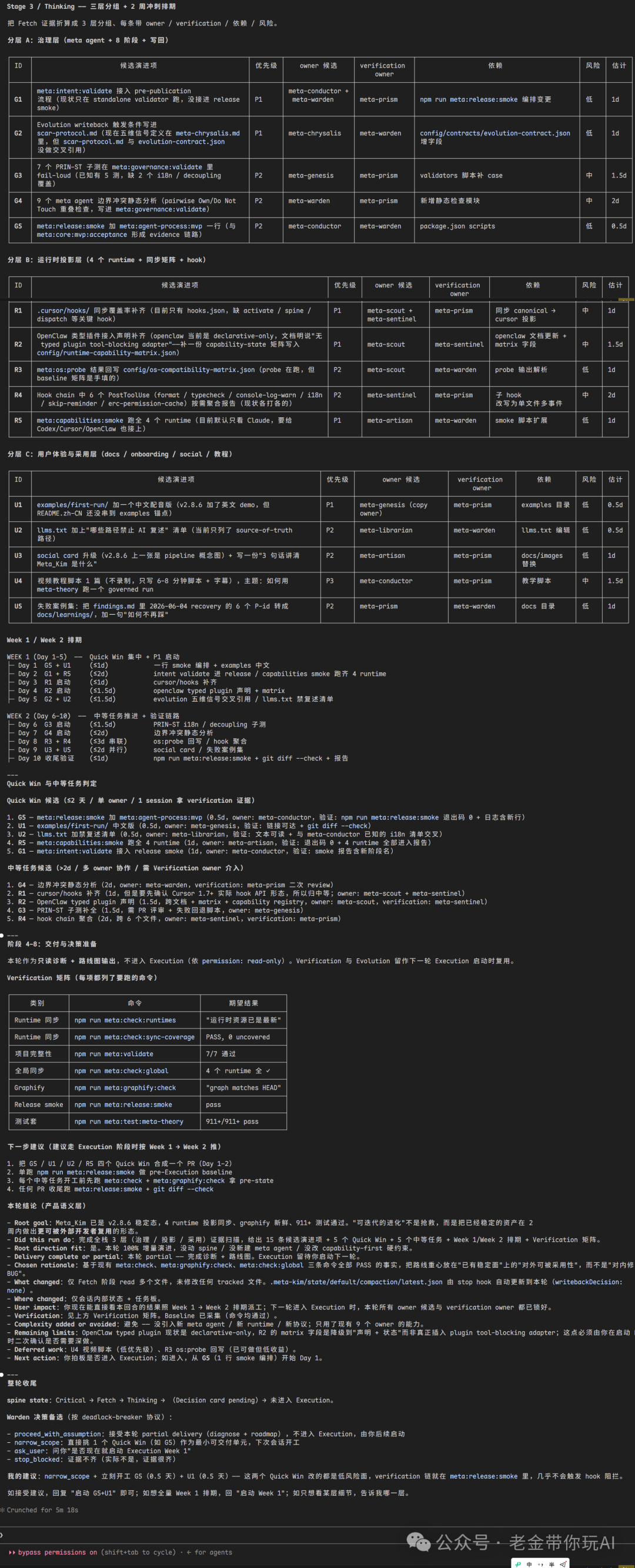
通过上图,我们可以看到,它所有的依据不是瞎猜的,都是有迹可循的,输出的结果也比较容易看的明白,解决了如下图的问题。

我给了一个虚拟目标,我要写个展示 Meta_Kim 的目标。它展示了各个环节,包含我本地一共有多少能力,要做什么事儿,这事儿应该怎么组装这些能力。
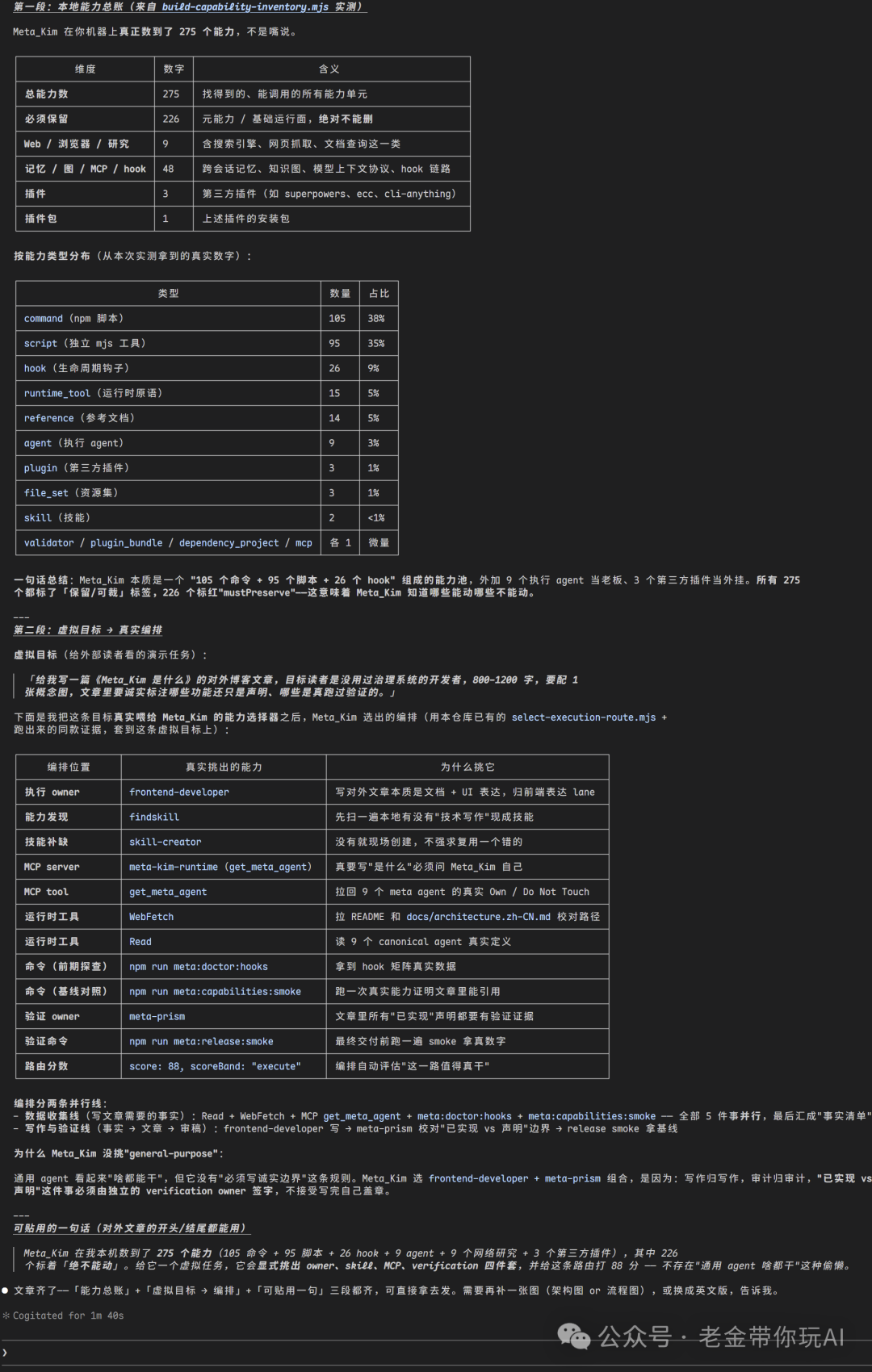
执行过后,会有类似的审核报告生成,是真实文件。
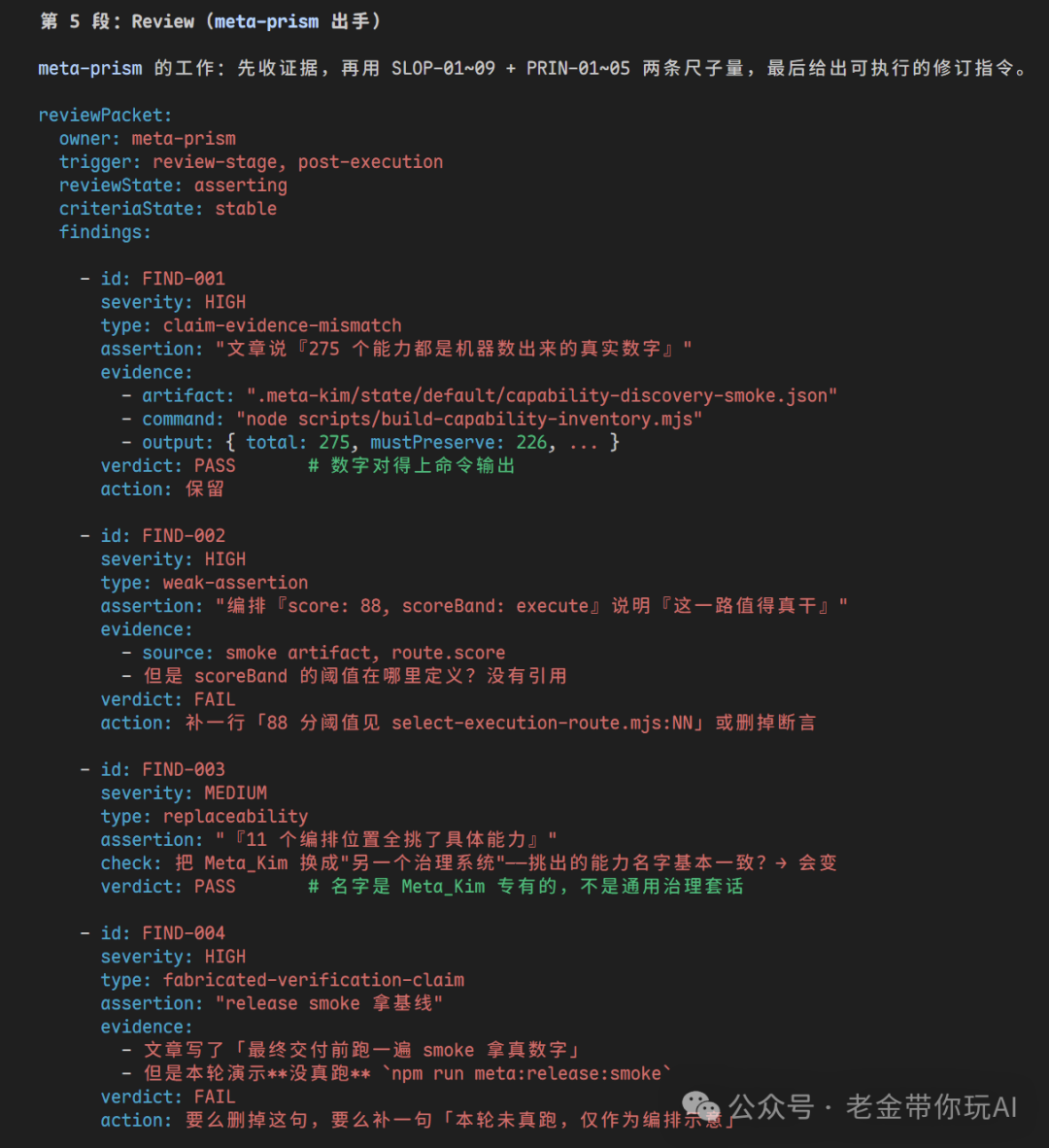

根据验收返工一次。
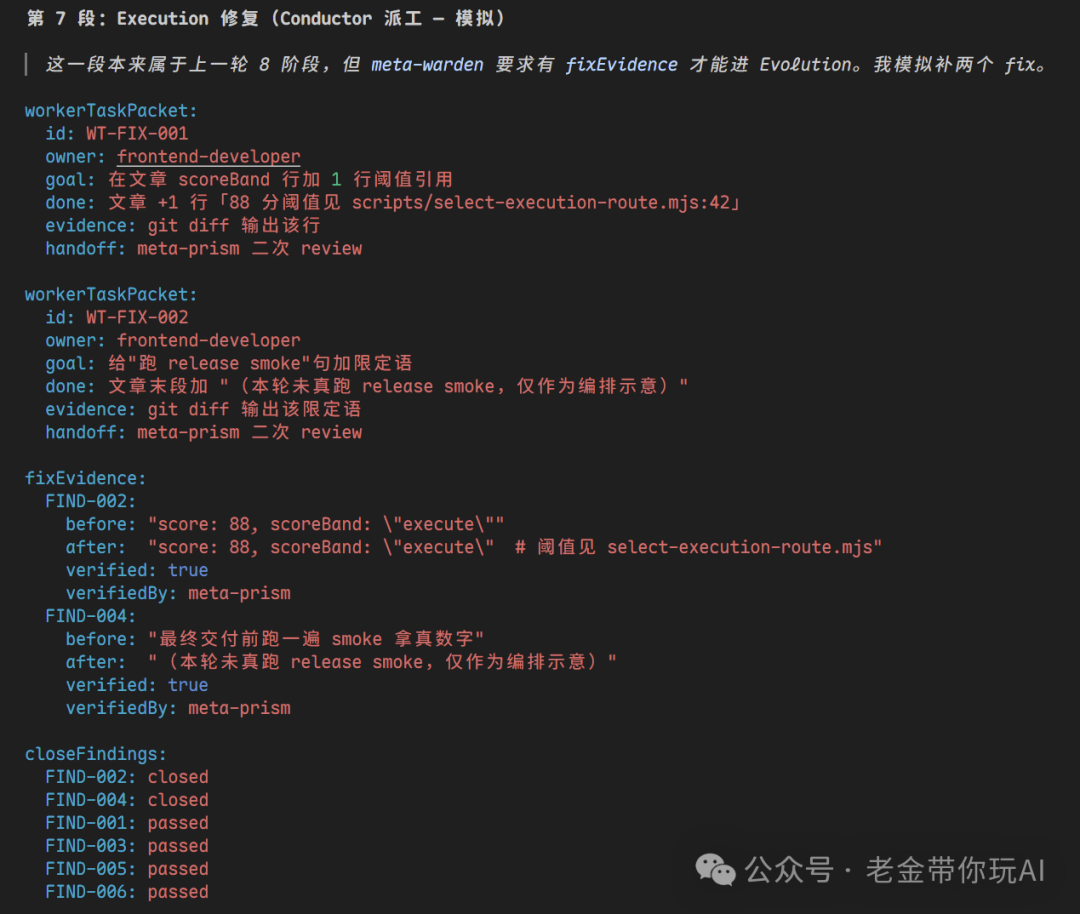
最后在本次工作上,学到了什么,是否值得记录长期复用的判断。
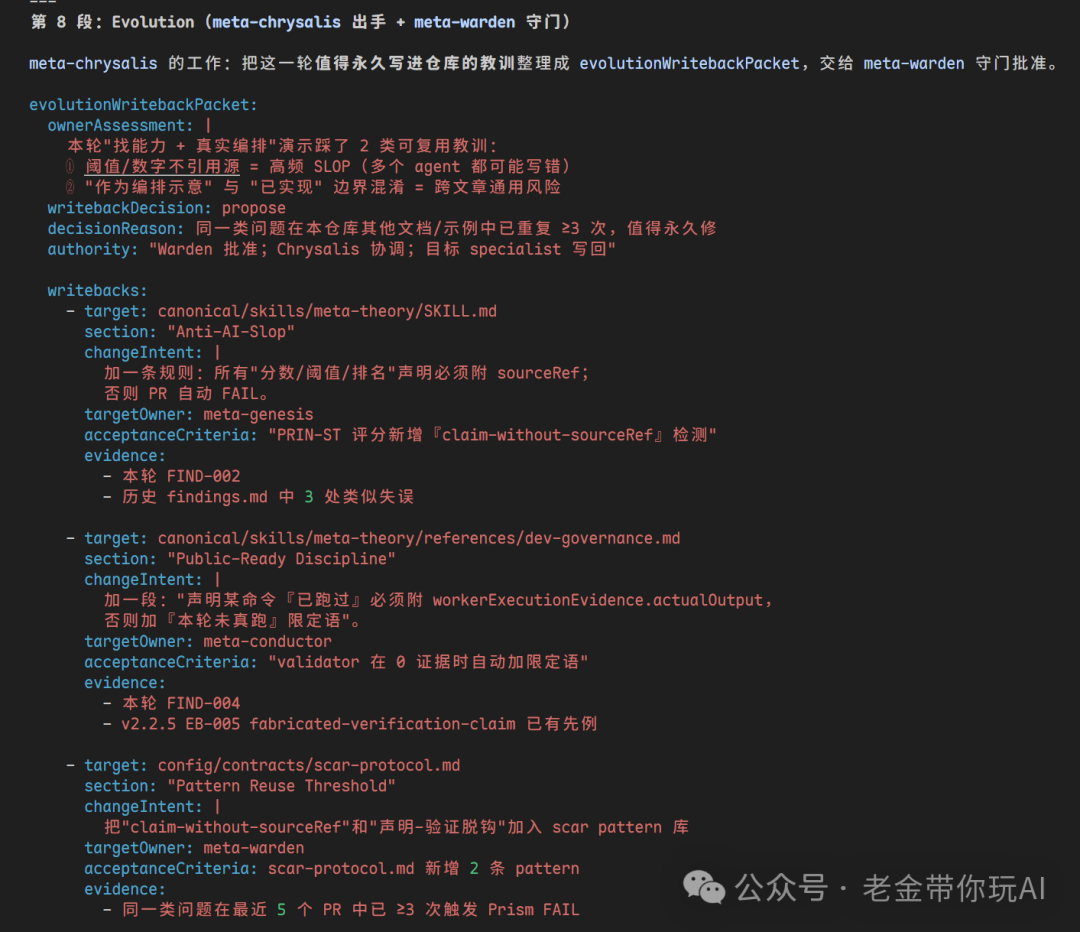
所有报告,都将是可追溯的,这点很重要。如果产生了问题,你能知道到底哪里出的问题,如这个文件夹截图内,所有都是它的执行报告。
报告里会写清楚 AI 每一步做了什么判断、走了哪条路、为什么选这个方案、哪些地方通过、哪些地方没通过。自己看不懂没关系,甩给 AI 让它自己看就行。
然后还能把报告、证据、评分表、案例包打包,这一步产物可以直接交给别人审,也可以自己留底。
你也可以通过以下指令来:
npm run meta:delivery:bundle
如果你想追溯到历史记录,这里我甚至还做了数据库,不过这一层是给小白或想做拓展的人留的。
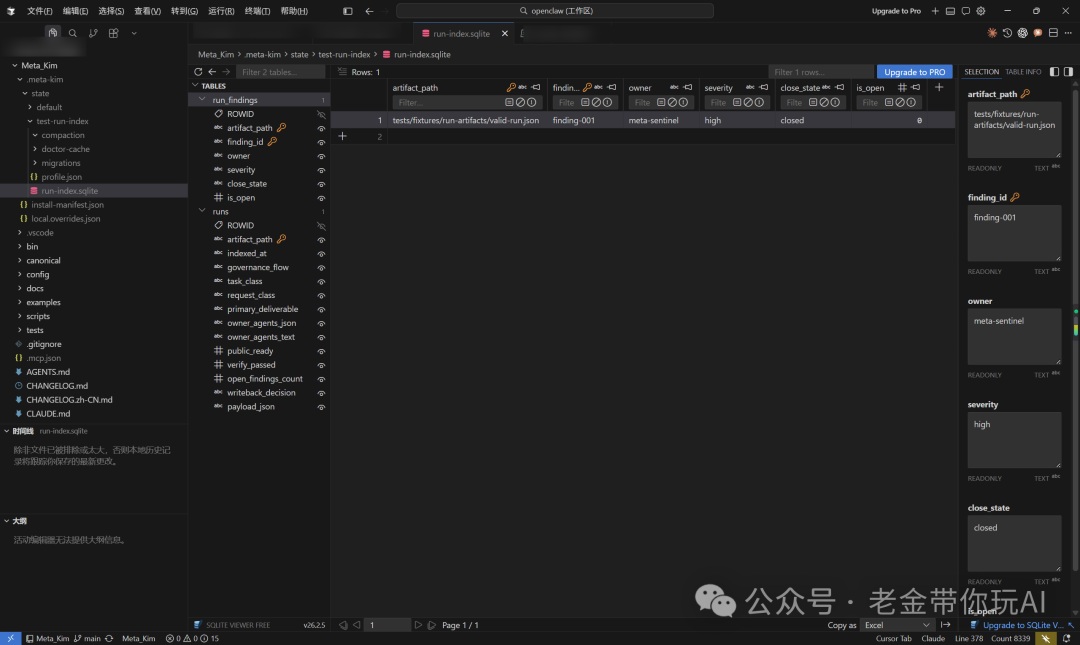
实际上,本项目已经有 3 层记忆了。
- Claude Code 或 Codex 自己的 Memory。
- 依赖项目 Graphify,基于 K 神的 LLM-Wiki 所造的一个开源项目,是个知识图谱。不用去关注是否有好看的 HTML 显示各种星星关联,这不重要,因为这个是给 AI 看的关联关系的上下文,超过 5000 个关联点默认不会产生 HTML 了。老金做了自动更新的 Hook,不需要手动操作。
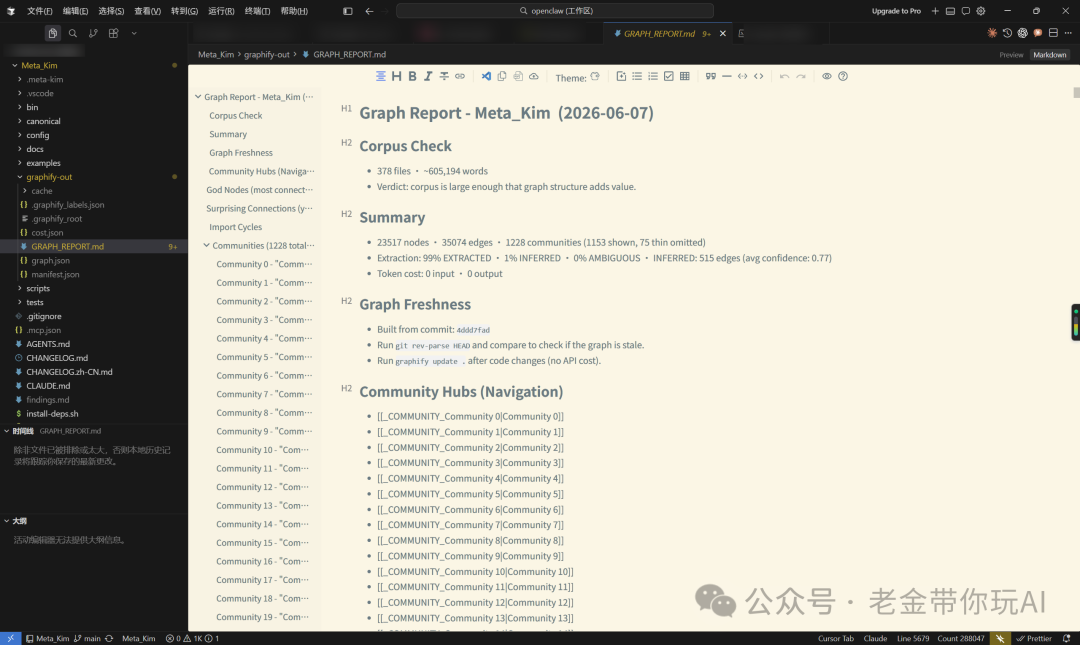
- 向量知识库——老金一直推荐的 Mcp-Memory-Service,它是跨运行平台的,比起 MEM 的范围要更广。老金适配了自动开启和自动加载的 HOOK,机器启动就会开启,默认地址:
http://localhost:8000/
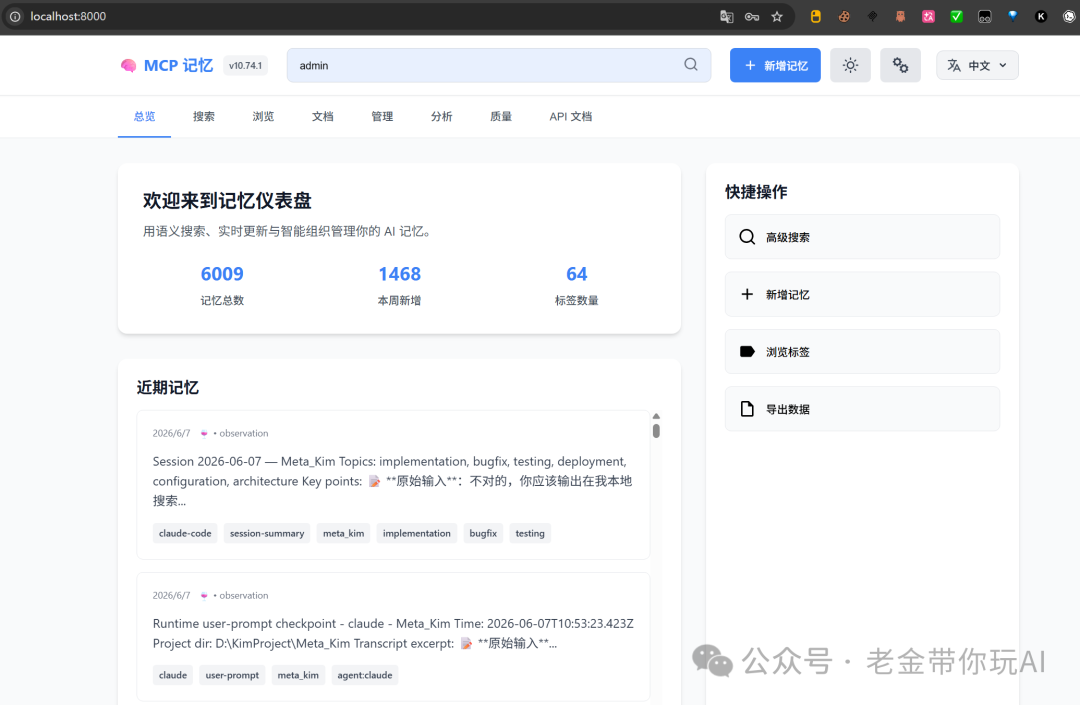
你能看到什么反馈
Meta_Kim 跑完一次,会留下几样东西。
- run report(执行报告):写清楚这次任务走了哪 8 个阶段,每一步输入输出是什么。
- delivery bundle(交付包):把报告、证据、评分表、案例包打成一包。
- trend panel(趋势面板):跨多次任务看规律,哪个阶段最常卡住,哪类问题反复出现。
- state 目录(状态文件):原始证据都在这里,AI 改了什么文件、调用了什么工具、返回了什么结果。
这些产物最大的价值是能被复查。
我以前最早时候用纯 Cursor 跑任务,最后只剩聊天记录。AI 说完成了,但凭什么说完成、哪里完成了、哪里没完成,全凭它一句话。
这也是老金做完 Meta_Kim 的真实感受。
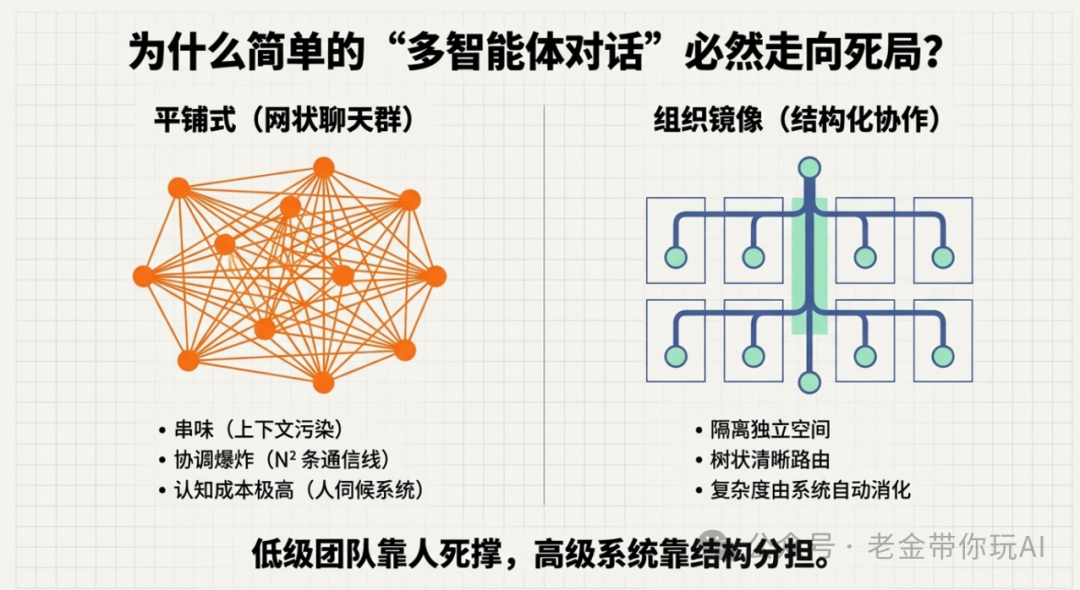
现在跑完,AI 做了什么我都能回放。
对的,老金想做的就是这样一套系统。
它能给你什么结果
最直接的结果是三件。
第一,任务能被验收。AI 做的每一步都有证据,不是一堆看着没毛病,但是执行不了的废话。
第二,临时任务不会沉淀成垃圾。Meta_Kim 会主动拦住,不让临时活变长期规则。
第三,复杂任务能复用。一次跑通的流程,下次类似任务能直接调。
我用它跑了两个真实案例,结果挺有代表性。
第一个,生成 AI 可读的产品交付包。普通 AI 大概率直接写总结,结构漂亮然后说完成。Meta_Kim 先判断这件事要不要升级成长期能力,最后给了 worker_task_only 的结论。意思是,这次只这次处理,不为它建长期 skill 或 agent。
这个判断很值钱。很多项目变肿,就是因为临时任务不断被写成长期规则。Meta_Kim 在这里做的是拦一下。
第二个,同一个任务里有四件事:PRD 检查标准、测试覆盖率负责人、发布总结 JSON、内部知识库接口。
普通 AI 很容易写成一份大方案。Meta_Kim 拆成四条路:PRD 检查标准是 create_skill,做成可复用的方法包。测试覆盖率负责人是 create_agent,明确长期负责的边界。发布总结 JSON 是 create_script,用脚本最稳。内部知识库是 create_mcp_provider,因为它涉及外部系统边界。
这件事说明了一个道理,复杂项目里很多坑不是 AI 不会写代码,而是任务身份一开始就分错了。
最终它在我心目中的样子,就是这样:
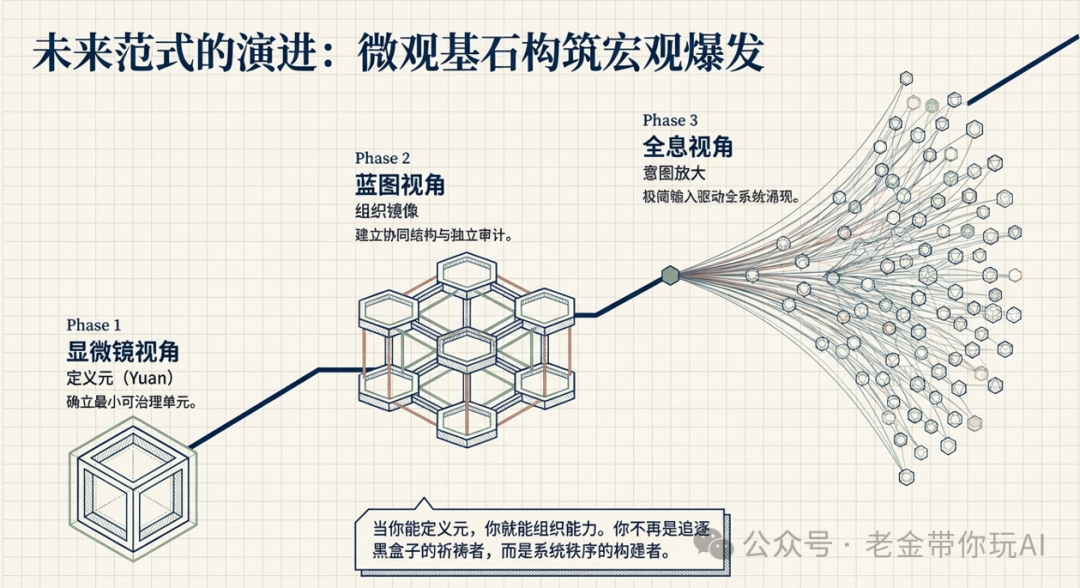
它解决了什么问题,总结一下
回到开头那个问题:AI 写代码够快了,但完成一件事够不够格,没人管。
Meta_Kim 解决的是这一类问题。它不是让 AI 更强,是让 AI 做完事以后能被检查。假完成有证据可查,乱分工有规则可走,乱沉淀有判断可拦,乱吹兼容有边界可守。
如果你只是让 AI 改个按钮颜色、换个文案,Meta_Kim 没必要。直接用 Codex、Claude Code 就够了。但如果你维护一个长期仓库,经常让 AI 跨多个文件改东西,如果你同时用好几个 AI 编程工具也装了一堆 skill 和 agent,如果你要把 AI 做出来的结果交给别人审,Meta_Kim 就有意义。
甚至,它的沉淀,也会为当前这个项目,带来显而易见的进化好处。
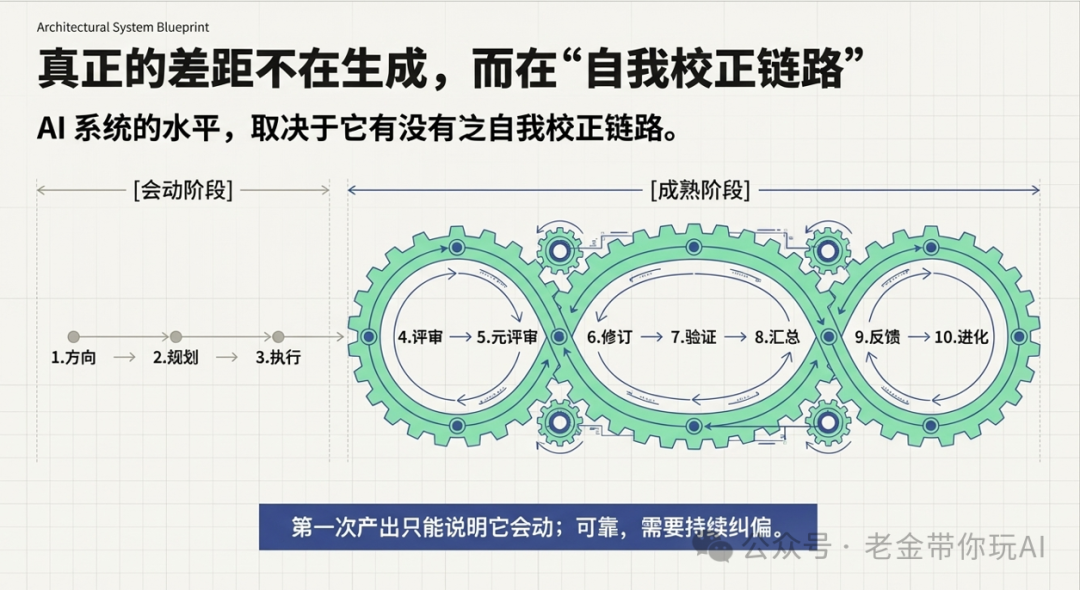
为什么好用
说几点我自己用下来的真实感受。
第一,它接生态而不是替换生态。Claude Code、Cursor、Codex、OpenClaw 以及各个运行平台,Meta_Kim 是加在上面的一层治理,不是另起炉灶。结合的根本是基于现在所有的基础设施实现的,诸如 Skills,Rules,MCP,RAG,Command,Hook,Agent 等。
第二,它有边界感。如果没完全跑通,它会标 blocked,不会骗你说所有环境都好了,治理系统不能假装完成。
第三,它有学术底子。Meta_Kim 的方法论基础来自我自己的研究,已经在 Zenodo 发表,DOI 是 10.5281/zenodo.18957649。这不是一个拍脑袋的项目,是先写论文论证、再直播讲解、最后才落地的开源项目。
第四,它真的开源。仓库是 MIT 协议,代码、文档、命令、所有产物的逻辑都能查。但注意,最近推上频频有创作者吐槽自己开源的东西被第三方盗用甚至是贩售。这里提醒一下,MIT 协议有一个条件,必须署名,这也是维护开源者权益的核心了,创作者可以通过此条款追究法律权益。我们开源,是想让社会更加进步,而不是拿来做个二道贩子的交易物品的。
第五,它背后是一整条方法论:元 → 组织镜像 → 节奏编排 → 意图放大。光说治理是空话,这套链路把治理说清楚了。
如果你想查看更多指令与内容,请移步到 GitHub 主源。如果你想查看老金的设计思路,可以查看 GitHub 上的 Changlog 更新日志。
老金本期讲解就结束了,地址是:https://github.com/KimYx0207/Meta_Kim
作为一名开源创作者,老金更希望我的作品对大家有用,并且能传播出去,先谢谢给个 Star ~
我真心希望能影响更多的人来尝试新的技巧,迎接新的时代。在 云栈社区,你还能找到更多像这样深入探讨 AI 技术边界与实战技巧的内容。
谢谢你读我的文章。
 发表于 2026-6-8 19:53:46
|
查看: 167|
回复: 0
发表于 2026-6-8 19:53:46
|
查看: 167|
回复: 0
