这篇文章继续往下聊:从 soulteary/minio 到 OtterIO,中间到底做了什么。
写在前面
如果说上一篇文章《重新审视 MinIO:许可证、归档、社区 fork 与我的 Apache 2.0 基线》是在回答“为什么要重新审视 MinIO,为什么要 fork”,那么这篇文章想回答的是另一个问题:
一个 fork 怎样才不只是“复制了一份旧代码”,而是变成一个可以继续维护、可以分发、可以部署、可以审计的新项目?
OtterIO 就是我对这个问题的一次实践。

OtterIO 取意于 Otter(水獭)+ I/O:像水獭守护贝壳一样,轻巧、可靠地守护你的对象数据。
开源项目地址:soulteary/otterio,如果对你有帮助,欢迎一键三连。
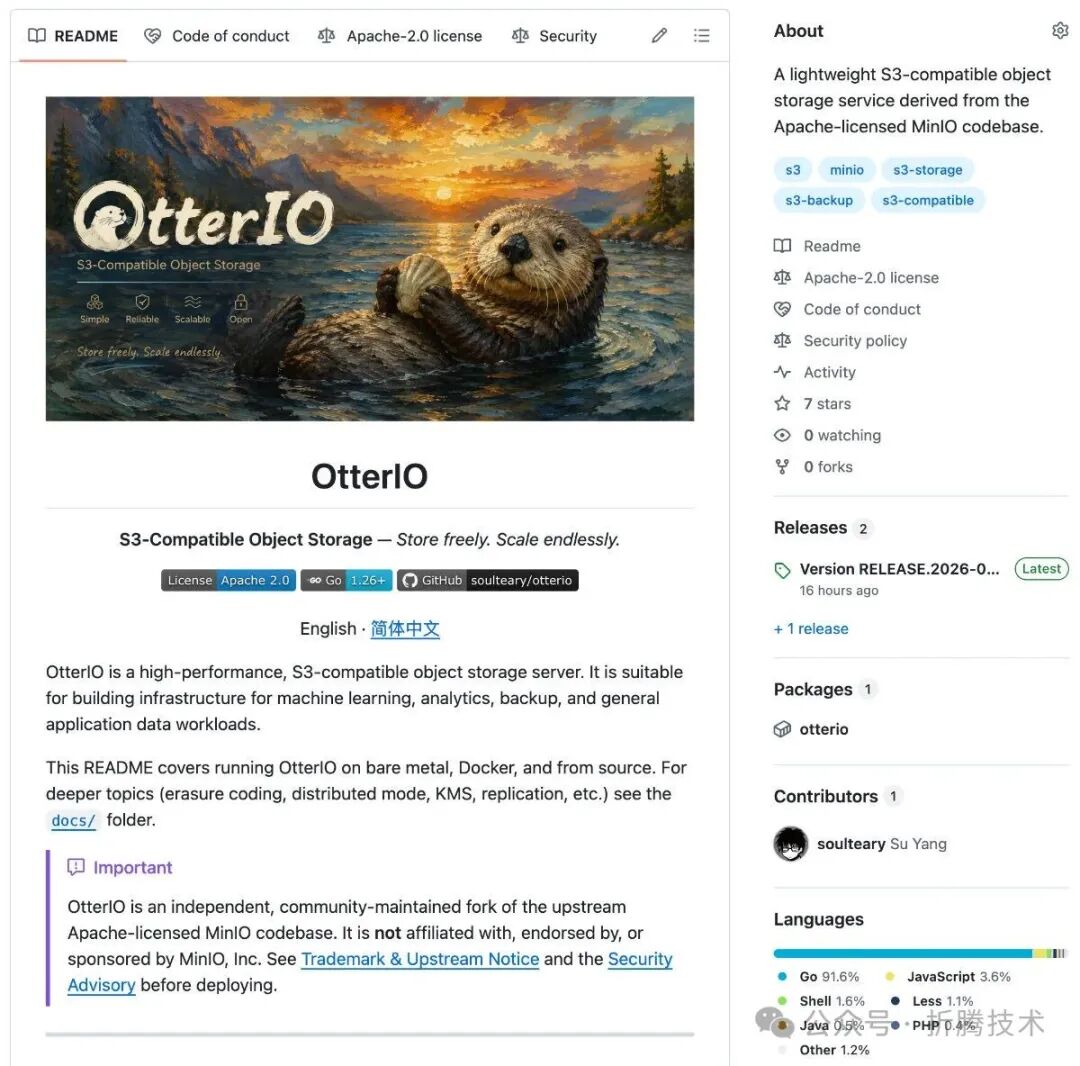
soulteary/otterio
做 fork 很容易,在 GitHub 上点一下 fork,或者把代码 clone 下来换个仓库名,几分钟就能完成。但这只解决了“代码放在哪里”的问题,并没有解决“这个项目是否还能继续被使用”的问题。
尤其是对象存储这类基础设施软件,用户关心的从来不只是源码能不能编译。代码从哪里来,许可证和商标边界是否清楚,旧依赖还能不能在今天的工具链里构建,已知 CVE 和 GHSA 有没有被逐项确认,镜像、二进制和 Release 能不能稳定发布,未来出现安全问题时应该在哪里跟踪,这些都很重要。
这些问题,不是改一个 README 标题就能解决的。
所以,OtterIO 并不是 soulteary/minio 的简单改名。soulteary/minio 解决的是“整理和验证 Apache 2.0 MinIO 旧基线”的问题;OtterIO 要解决的是“把这条整理后的代码线作为一个新项目继续维护”的问题。
当前 OtterIO README 已经明确说明:它是一个 S3 兼容的对象存储服务,基于 Apache 许可 MinIO 代码库的独立社区维护 fork,不隶属于、不受 MinIO, Inc. 认可或赞助,并继续以 Apache License 2.0 分发。
因为代码基是几年前的产物,真正折腾下来,还是有不少“乐趣”。即便有 AI 协助,也花了不少功夫。
这篇文章就从工程角度展开,聊聊我是怎么把这条旧代码线整理成 OtterIO 的。
先把边界说清楚
做这类项目时,最容易掉进一个陷阱:想把上游所有功能都保留下来。听起来这很合理。功能越多,覆盖场景越广,项目似乎越“完整”。
但对个人或小团队维护的基础设施项目来说,功能越多,往往也意味着更多维护成本。每多一个 Gateway,每多一个通知后端,每多一个外部 SDK,每多一组历史兼容逻辑,就会多一组依赖、多一组安全告警、多一组回归测试,以及更多不确定性。
所以, OtterIO 从一开始就没有把目标设成“完整替代 MinIO”。它的目标要窄得多:
保留本地开发、CI、私有化测试、轻量部署和博客示例中最常用的 S3 兼容对象存储能力,同时删掉那些不在当前目标范围内、但会持续增加依赖和维护成本的功能。
这个目标决定了后面的很多取舍。
在 README 里,OtterIO 直接列出了和上游 MinIO 的主要差异:HTTP 请求路由基于 gofiber/fiber/v3 而不是 gorilla/mux;Bucket Notification 只保留 elasticsearch、mysql、postgresql、redis 和 webhook;Kafka、NATS、NATS Streaming、NSQ、AMQP、MQTT 等消息队列通知目标被移除;Gateway 只保留 nas 和 s3,移除了 azure、gcs 和 hdfs;工具链要求 Go 1.26 或更新版本。
这不是为了把项目做小而做小,不是为了“功能缩水”,而是先把维护范围讲清楚。
知道要做什么,也知道不做什么,后面的工作才不会失控。
第一步:先从名字和身份上独立出来
fork 阶段使用 soulteary/minio 这个仓库名,是为了让代码来源足够清楚:它来自 MinIO 的 Apache 2.0 旧基线。
但长期使用这个名字并不合适。
详细原因上一篇文章已经说过:Apache 2.0 允许复制、修改和分发代码,但并不授予商标权。继续使用 MinIO 作为项目名称,容易让用户误以为这是上游官方项目,或者和 MinIO, Inc. 存在某种关联。
所以,OtterIO 首先要做的是建立自己的项目身份。
这件事不只是改仓库名,也包括命令、镜像、文档、内部标识和用户可见文案的整理。比如安全 backlog 中已经写明,回补上游补丁时,涉及 header 或 metadata 的标识需要从 X-Minio-... 改写为 X-Otterio-...,线协议里引用 minio 的 token 也需要改成 otterio;内部存储 key 则统一放进 fork 已经建立的 X-Otterio-Internal-* 命名空间。
这些修改看起来不大,但对衍生项目很重要。
它解决的是“用户到底在运行什么”的问题。一个独立项目应该在日志、镜像、包名、元数据、内部 header、文档和安全说明中尽量减少上游商标混用。否则,哪怕代码可以合法 fork,项目边界仍然会很模糊。
OtterIO 的第一个核心工作,就是让这条代码线从“MinIO 的一个整理分支”变成“一个清楚标识来源、但拥有自己项目身份的新项目”。
第二步:把 2021 年的代码带到 2026 年
旧代码最大的问题之一,是它停留在旧生态里。
Go 语言、标准库、依赖包、安全扫描工具、构建系统和操作系统平台都在变化。一个 2021 年的对象存储代码库,放到 2026 年继续维护,如果只是“能编译”,远远不够。
OtterIO 当前 go.mod 已经切换到 go 1.26。依赖中可以看到 gofiber/fiber/v3 v3.3.0、github.com/minio/minio-go/v7 v7.2.0、github.com/klauspost/compress v1.18.6、go.etcd.io/etcd v3.6.12、golang.org/x/crypto v0.52.0、golang.org/x/net v0.55.0、golang.org/x/sys v0.45.0 等较新的依赖版本。
这一步不是简单把版本号拉满。
老项目升级依赖,经常会连锁触发很多问题:API 变化、类型变化、测试变化、构建标签变化、平台兼容变化、间接依赖冲突,以及老代码里原本没暴露出来的隐藏假设。
真正麻烦的是,很多依赖升级并不是孤立发生的。
有些库已经多年不维护,却还挂着严重 CVE;有些库换了模块路径,但不同依赖同时引用新旧包;有些包升级之后修掉了安全问题,却顺手改了行为;还有一些依赖并不是 OtterIO 核心路径需要的,只是被历史功能顺手带了进来。
所以我在 OtterIO 里选择把“删功能”和“升依赖”一起做。
如果只升依赖但保留所有历史功能,很多不需要的边缘组件会继续拖住维护节奏。如果只删功能但不升级依赖,项目又仍然停在旧安全基线里。
这两件事必须一起推进。
第三步:重做 HTTP 入口
OtterIO 一个比较明显的实现变化,是 HTTP 请求路由从 gorilla/mux 切换到 gofiber/fiber/v3。这个差异在 README 中也被列为第一项。
这不是随便换个框架,对象存储服务的 HTTP 层非常关键。S3 API 本质上就是一组 HTTP 请求:签名、路径、Header、Query、对象名、Bucket 名、Range 请求、分片上传、预签名 URL、错误码、重定向、健康检查、管理 API,几乎所有能力都从 HTTP 层进入。
所以替换路由层时,需要特别小心几类细节。
请求路径不能被错误规范化,Header 大小写和多值行为不能影响签名校验,Host、X-Amz-*、Content-Length 这些字段不能被错误解释,chunked upload 和 streaming request 也不能被框架提前吞掉或改写。
对 S3 兼容服务来说,很多问题都不是“请求能不能路由到 handler”这么简单,而是“路由之前和路由之后,请求有没有发生微妙变化”。
OtterIO 的安全加固摘要里,也记录了一个和 HTTP 层相关的审计点:替换路由层之后,需要确认是否会因为重复的 Host 请求头导致前后端对请求产生不同理解,进而出现 Request Smuggling 风险。
当前审计结果是,请求在进入业务处理逻辑之前,fasthttp 和 Go 标准库的 net/http 会先合并或拒绝重复的 Host 请求头;而 AWS 第四版签名校验,也只会读取单一的 r.Host 字段。因此,不存在代理层和服务端分别看到不同 Host 值的情况。
这类记录都很重要。fork 不是只继承上游风险,也会产生自己的风险。换 router、改 header、拆 listener、重命名内部 metadata,都可能引入新的攻击面。只回补上游 CVE 不够,自己改出来的新边界,也要能说清楚。
第四步:做减法,缩小维护面
OtterIO 里移除了不少原本 MinIO 支持的功能。
Bucket Notification 不再保留 Kafka、NATS、NATS Streaming、NSQ、AMQP、MQTT 等消息队列目标,只保留 elasticsearch、mysql、postgresql、Redis 和 webhook。Gateway 只保留 nas 和 s3,移除了 azure、gcs 和 hdfs。
这些删减有一个共同点:它们对某些用户有用,但对当前目标不是必要能力。
OtterIO 首先要服务的是本地开发、CI、测试、小规模私有化和轻量部署。对这些场景来说,最重要的是能快速启动,能创建 bucket,能上传、下载、列举和删除对象,能被常见 S3 SDK 和工具访问,能持久化数据,也能通过容器、二进制或包管理器方便获取。
相比之下,保留所有历史 Gateway 和通知目标,带来的更多是依赖和审计成本。删除这些功能之后,项目的依赖面、测试面和安全扫描面都会变小。后续维护时,真正需要关注的路径更集中,修复 CVE 时也更容易判断影响范围。
这里举一个具体例子。
原始 MinIO 支持构建 32 位二进制。但升级依赖到较新的 apache/thrift 之后,这个库在 32 位平台上存在一个很麻烦的问题:32 位平台上的 int 最大值是 2147483647,而某些代码路径会涉及 math.MaxUint32 = 4294967295,超出了 32 位 int 的范围,导致编译失败。
社区里有相关讨论,也有人给过特殊补丁版本,但实际折腾下来,这条路径并不顺。
这时候就要回到一个很现实的问题:今天我们到底会不会在 32 位环境里运行这个对象存储服务?
如果按照真实使用价值排序,首先要保障的是 linux/amd64、linux/arm64、darwin/arm64,然后是 darwin/amd64 和 windows/amd64,再往后才是 linux/ppc64le、linux/s390x 这类企业平台。至于 linux/mips64、freebsd/amd64、netbsd/amd64 之类的组合,能确保可编译已经算不错。再激进一些,连 linux/s390x 都可以交给真正需要的人自己编译(IBM Z 用户基本都是自己编译)。
想清楚哪些平台必须支持,哪些平台只是历史包袱,就能少掉大量构建适配和测试时间。这就是做减法的价值,不是为了少做事,而是把时间花在真正会被使用的路径上。
第五步:把历史安全问题逐项入账
从 2021 年的 MinIO Apache 2.0 旧基线继续往前走,最不能回避的问题就是安全。
对象存储不是一个普通 demo 服务。它涉及认证、授权、签名、加密、对象元数据、IAM、LDAP、STS、复制、管理 API 等很多路径。很多漏洞也不是升级一个依赖就能解决的。
所以,我没有简单写一句“已修复若干 CVE”。
在 OtterIO 里,我把上游 MinIO 在 2021 年 4 月之后公开的 CVE / GHSA 都视为“可能适用”,然后逐项进入 backlog。
项目的 SECURITY 文档里写得比较明确:OtterIO 来自 RELEASE.2021-04-22T15-44-28Z 这个 Apache 2.0 MinIO 基线,此后针对 minio/minio 发布的每个 CVE / GHSA,都会先被当作潜在适用项,直到能够证明不适用。
截至 2026 年 6 月,backlog 状态是 14 个已处理、2 个不适用、剩余 0 个悬而未决。新的上游安全公告如果出现,也会以 待定 状态进入同一张表。这张表不是简单列漏洞编号,而是按攻击面整理,包括 SSE / object metadata、IAM / STS / service accounts、LDAP、Bucket / IAM policy、SigV4 / chunked upload、replication / header 等。
每个条目都尽量记录状态、上游参考、代码路径、审计说明和回归测试。这样做的意义在于,安全维护不是“补完一次就结束”。只要未来继续有新的 GHSA 或 CVE,OtterIO 就需要有地方登记、判断、回补、测试、关闭,或者明确说明为什么不适用。
比起“这次修了什么”,我更关心“下次出现问题时,应该怎么处理”。
第六步:把安全修复拆到具体攻击面
安全 backlog 只是入口,真正麻烦的是每个攻击面都要落到代码和迁移路径上。
第一类,是对象元数据和服务端加密相关的问题。
有些攻击会利用对象元数据做文章,比如往里面塞一些本来不该由用户控制的加密字段。OtterIO 的做法是,在请求刚进来的地方,以及解析元数据的地方,都直接拦住这些带有保留前缀的元数据,不让它们继续往后传。
还有一类问题是,用户虽然没有权限读取某个对象,但通过条件式 GET 或 HEAD 请求,仍然可能从 ETag、Last-Modified 这些响应头里猜到对象是否存在、有没有变化。
这类信息本身看起来不像对象内容,但在权限边界里也属于泄露。OtterIO 的修复方式是,在返回这些信息之前重新做权限检查。特别是当访问控制依赖对象标签时,如果标签策略不允许访问,就不能提前把对象状态暴露出去。
第二类,是服务端加密和密钥管理服务之间的绑定问题。
这里的核心是,不能只相信请求里带来的加密上下文。攻击者有可能伪造或篡改这些上下文,所以服务端需要根据真实的存储桶名和对象名重新生成加密上下文。
也就是说,系统自己确认“这个对象到底是谁”,而不是相信客户端说的内容。如果请求里的 MetaContext 不对,就在真正调用密钥管理服务之前直接拒绝,并返回 403 错误。
过去有一些上传路径只是简单返回“还没实现”,这在安全逻辑上并不严谨。现在这些路径都统一接入了 enforceSSEKMSRequest 这道安全检查,包括普通上传、分片上传、复制对象和表单策略上传,避免某些上传路径绕过服务端加密检查。
第三类,是身份、权限和服务账号相关的问题。
这类问题说白了就是,不能让用户通过服务账号、添加用户、更新服务账号等接口,把自己的权限偷偷放大。
比如服务账号可以有自己的子策略,但这个子策略必须是调用者原本权限的子集。你自己没有的权限,不能通过创建服务账号变相拿到。否则,服务账号就会变成权限提升的后门。
OtterIO 的安全清单里,也记录了和服务账号权限提升、AddUser 的 PolicyName 权限提升、admin:UpdateServiceAccount 等相关的修复或继承状态。
第四类,是 LDAP 身份名称的规范化。
这个问题表面上很小,但实际很关键。
以前系统会把 LDAP 返回的 DN,也就是“可分辨名称”,原封不动地当成身份标识来用。磁盘上的策略文件是 <DN>.json,内存里也是用这个 DN 当 key。
问题是,LDAP 里的 DN 并不等于普通字符串。大小写、空格、字段写法不同,可能指向的是同一个人或同一个组。比如在 Active Directory 这类目录服务里,这种差异很常见。
如果系统把这些不同写法当成不同身份,就可能导致权限判断混乱。一个人可能在某个写法下有权限,换个大小写或空格写法后,又被当成另一个身份。
所以 OtterIO 新版本会在身份进入权限系统之前,先通过 NormalizeDN 把它规范化。后续无论是处理请求、读写策略数据库,还是处理安全令牌服务相关逻辑,都统一使用规范化后的结果。
不过,这个修复不是完全没有代价。
文档里明确说了,这是一次性的破坏性变更。如果某些部署过去真的依赖 DN 的大小写差异来区分不同身份,那么升级后这些身份会被合并。
为了降低风险,OtterIO 提供了试运行模式。可以设置:
OTTERIO_IAM_LDAP_DN_MIGRATION=off
这样系统只会在内存里做规范化和合并,不会真的改磁盘文件。正式迁移时,系统会扫描用户和用户组的策略数据库,把非规范化的 DN 条目迁移到规范路径。如果遇到冲突,就保留 .conflict-* 文件,让管理员手动处理。
我觉得这类文档对基础设施项目非常重要。
安全修复不能只写一句“已修复”就完事。只要修复会影响已有数据、身份模型或权限映射,就必须讲清楚怎么升级,怎么试运行,出了冲突怎么办,升级前怎么备份,必要时怎么回滚。
这样用户才敢真的把修复用到更严肃的环境里。
第七步:别让修过的问题再回来
CI 这件事很容易被忽略。
很多项目做完安全修复、依赖升级之后,会有一种“已经收工”的错觉。但如果没有把这些修复结果固化到 CI 里面,后续回归会来得很快。
OtterIO 的 Go workflow 并不是简单执行一个 make test 就结束,而是把测试、Race Detector、交叉编译、漏洞扫描、前端测试、Shell 脚本检查等内容拆成多个独立 Job 并行执行。
这样做不是为了把 CI 配得很“豪华”,而是为了让每个检查项有明确职责,出了问题也容易定位。耗时任务拆开跑,也能避免一个大杂烩流水线拖慢所有反馈。
最基础的一层,是保证代码至少能够在目标平台上正常构建和运行。当前 CI 同时覆盖 Linux 和 Windows。Linux 会执行完整的构建和测试流程,Windows 则只做编译验证。
这不是偷懒,而是现实取舍。OtterIO 的代码主体来自早期 MinIO,大量测试默认假设 POSIX 文件系统语义。一些涉及磁盘修复、数据扫描、Erasure Coding 的测试,在 Windows 环境下收益有限,甚至可能因为文件系统行为差异导致误报或卡死。与其为了“看起来覆盖更全面”而增加大量无意义失败,不如让 Windows CI 专注于确认发布目标能够构建,行为验证继续放在 Linux 上完成。
Race Detector 则单独拆成一个 Job。
对象存储本质上是一个并发系统。请求处理、后台扫描、缓存更新、元数据同步、磁盘恢复,几乎所有核心路径都涉及并发访问。很多问题在普通功能测试里不会暴露,只有打开 Race Detector 之后才会出现。
单独拆出来还有一个很现实的原因:Race 测试太慢。如果把它和普通测试绑在一起,每个 PR 的反馈时间都会被拖长。拆开之后,普通测试先给反馈,Race Detector 继续跑,两边互不影响。
生成代码检查也是 CI 里很值得保留的一项。
很多 Go 项目都会使用 go generate、stringer、msgp 等工具生成代码。开发过程中常见的问题是:本地改了源文件或生成器版本,但忘记提交生成后的 _gen.go。这种问题有时不会在编译阶段暴露,等别人拉代码时才发现生成结果不一致。
OtterIO 的处理方式很直接:CI 里执行一次 go generate,然后检查仓库是否出现新的 _gen.go 变更。如果有未提交内容,直接失败。
交叉编译负责提前发现发布阶段才会暴露的问题。某个依赖在 ARM 下无法编译,某个条件编译标签失效,某个平台缺少系统调用支持,这些问题平时很容易被忽略。把 Cross Compile 放进 PR 流程,至少能避免等到发版当天才发现构建失败。
安全扫描部分,OtterIO 使用 Go 官方维护的 govulncheck。它不仅检查依赖版本,还会分析代码实际调用路径,只报告真正能够触达的漏洞。
这比单纯扫依赖树更适合长期维护项目。因为维护者最怕的不是发现漏洞,而是每天收到大量低价值告警,最后对真正重要的安全问题也失去敏感度。
Lint 策略也比较务实。
OtterIO 没有试图一次性清理所有历史静态检查问题,而是采用“只关注新增问题”的策略。对于有历史包袱的代码库来说,一次性修完几百上千条 Lint 告警往往不现实。但如果放任不管,新问题又会不断产生。
所以最合理的办法,是先守住增量。旧问题慢慢还债,新代码不允许继续欠债。
此外,Browser 目录会跑 Bun 测试,运维脚本会经过 ShellCheck 校验,避免质量边界只停留在 Go 代码上。
这些检查单独看都不复杂,但组合在一起之后,CI 就不再只是“代码能不能编译”的检查,而是真正承担了质量门禁的角色。
第八步:让用户可以一条命令跑起来
修代码是一回事,让别人愿意用,是另一回事。
过去很多开发者选择 MinIO,并不是因为研究过它的源码结构,也不是因为了解它背后的实现细节。
原因往往很简单:它足够容易启动。
无论是在技术文章、示例项目、开发环境,还是临时测试场景里,复制一条命令,几秒钟之后就能得到一个可用的 S3 服务。这种低门槛体验,本身就是 MinIO 当年能够广泛传播的重要原因之一。
如果 OtterIO 希望承担类似角色,就不能停留在“源码能够编译通过”。
用户不应该先学习项目结构,安装 Go 工具链,下载依赖,再经历一轮本地编译,最后才能得到一个对象存储服务。对大多数人来说,更合理的方式仍然是一条命令启动。
OtterIO 目前已经提供了容器镜像,并发布在 Docker Hub 的 soulteary/otterio,以及 GitHub Container Registry 的 ghcr.io/soulteary/otterio。
最简单的启动方式是:
docker run -p 9000:9000 soulteary/otterio:latest server /data
如果希望数据在容器重启后仍然保留,可以把宿主机目录挂载到容器里的 /data:
docker run -p 9000:9000 -v $(pwd)/data:/data soulteary/otterio:latest server /data
对于 macOS 用户,也可以通过 Homebrew 安装:
brew install otterio/stable/otterio
otterio server /data
这些入口看起来只是文档和发布方式,但对项目能不能被真实使用影响很大。
当一篇文章的主题是图片上传、备份系统、AI 数据集管理或者静态资源存储时,读者关注的是业务逻辑,而不是对象存储软件本身。如果搭建存储服务需要先花半小时折腾编译环境,很多人会在真正开始之前就放弃。
所以这一步的目标很简单:
让 OtterIO 像过去启动 MinIO 一样,复制命令就能跑起来。
只有做到这一点,它才有可能重新出现在文章、示例项目、测试环境和开发流程里,而不只是一个整理得比较干净的源码仓库。
第九步:让每个版本都能追溯
能跑起来只是第一步。基础设施软件还需要回答另一个问题:
几个月后出问题时,我还能不能知道当时跑的是哪一版?
很多开源项目在技术层面并没有明显问题,但长期使用体验不好。原因往往不是代码质量,而是发布体系不清楚。
用户不知道哪个版本能用,不知道哪个版本修复了问题,不知道镜像对应哪个提交,也不知道出现故障之后应该回滚到哪里。对对象存储这种基础组件来说,这类问题非常麻烦。
所以 OtterIO 需要自动化发布链路。
当前 release workflow 的设计比较清晰:当推送 v* 或 RELEASE.* 这样的 tag 时,会构建版本化 release,产出跨平台二进制、校验和、多架构 Docker 镜像,并创建带二进制附件的 GitHub Release。GHCR 默认使用 GitHub token 发布,Docker Hub 则在配置 secrets 后发布。
当前 GitHub Releases 页面中,项目已经有 RELEASE.2026-06-04T03-00-56Z,并带有多个构建产物。
与此同时,Docker workflow 把 main 分支上的开发镜像和正式 release 分开。
edge 总是指向最新 main,适合愿意跟进开发分支的测试者;sha-<short_sha> 是用于排查问题和复现环境的不可变 tag;正式 release 则面向需要固定版本、校验和和二进制产物的使用场景。
这套分层很重要。
latest 面向普通用户,应该尽量稳定。edge 面向愿意跟进 main 的测试者。sha-<short_sha> 面向排查问题和复现环境。
GitHub Release 面向需要固定版本、校验和和二进制产物的场景。
镜像构建也不是只面向单一架构。Docker workflow 会交叉编译 Linux 二进制,并构建 linux/amd64、linux/arm64、linux/ppc64le、linux/s390x 多架构镜像。
这样一来,用户下载的二进制文件、Release 页面里的版本号、容器仓库中的镜像标签,以及对应的 Git 提交记录,就能关联到同一次构建。
基础设施项目最怕“我不知道我跑的是哪一版”。有了 tag、commit、镜像标签、Release 资产和 CI 构建链路,问题排查和回滚都会容易很多。
第十步:把 S3 API 和管理后台拆开
如果长期维护过对象存储服务,就会发现一个很常见的问题:开发环境和生产环境对于访问边界的要求完全不一样。
本地测试时,大家通常希望一切都在一个端口里。浏览器打开管理界面,SDK 连同一个地址上传文件,命令行工具也连同一个地址。这样配置简单,复制命令就能启动。
但真正进入更严肃的环境之后,情况往往正好相反。
对象存储接口和管理后台属于两类不同流量。前者是业务流量,后者是运维流量。业务系统、CI 流程、备份程序、网关服务会持续访问 S3 API;管理后台通常只会被少数管理员偶尔登录。
很多团队最终都会在反向代理层额外做一次拆分:有的用不同域名,有的用不同路径,有的再套一层 VPN 或堡垒机。
本质上都是在解决同一个问题:存储服务和管理入口最好不要混在一起。
OtterIO 把这件事情直接放进了服务本身。现在 S3 API 和控制台可以运行在不同的监听端口上:对象存储服务继续监听业务端口,控制台和管理 API 则运行在独立端口。
默认情况下,Web Console 和 S3 API 共用 --address 绑定的 listener。但可以通过 --console-address 或 OTTERIO_BROWSER_ADDRESS 启用独立控制台 listener。
例如:
otterio server --address ":9000" --console-address ":9001" /data
或者:
export OTTERIO_BROWSER_ADDRESS=":9001"
otterio server --address ":9000" /data
启用之后,:9000 只服务 S3 API、STS、HealthCheck 和 Metrics;:9001 服务 Web Console /otterio/ 和 Admin API /otterio/admin/v3/*。两个端口不能相同,否则启动时会 fail fast;收到 Ctrl+C 或 SIGTERM 时,两个 listener 都会优雅关闭。
这个改动不会增加新的存储能力,也不会提升吞吐量,但它能让部署边界清楚很多。
访问控制可以按端口处理:允许应用服务器访问 S3,禁止普通业务网络访问管理接口,甚至可以把控制台完全放进内网。日志分析也更清楚:对象上传下载产生的是业务访问日志,管理员登录后台产生的是运维访问日志,两者原本就不应该混在一起看。
证书管理也会更灵活。
在很多企业环境里,对象存储和管理后台不一定使用同一个域名,甚至不一定属于同一个安全域。有些团队会把存储服务暴露给业务系统,而把管理入口限制在办公网络或 VPN 内部,这时候使用不同 TLS 证书是很常见的需求。
OtterIO 支持通过 --console-certs-dir 或 OTTERIO_BROWSER_CERTS_DIR 为控制台 listener 配置独立证书目录。--console-certs-dir 必须配合 --console-address 使用,否则启动会 fail fast;如果不设置控制台证书目录,控制台 listener 会复用 --certs-dir 的证书。
过去很多团队会在 Traefik、Nginx、HAProxy 或云负载均衡上手工实现类似策略。现在这些边界可以直接在服务层体现出来,部署者理解起来也更简单。
第十一步:保留 S3 使用体验,减少迁移心智负担
做这个项目的时候,我一直在刻意避免一件事情:不要为了证明自己做了很多改动,而创造一套新的使用方式。
很多 Fork 项目最后都会掉进这个陷阱。作者修改了一些功能,增加了一些配置,调整了一些实现,然后开始引入新的命令、新的接口、新的概念。结果是代码越来越不像原来的项目,用户也不得不重新学习一整套东西。
从技术角度看,这当然可以成立。但从迁移角度看,代价很高。
绝大多数用户并不关心底层实现究竟发生了什么变化,他们关心的是:原来的东西还能不能继续工作。
事实上,我决定维护 OtterIO 的一个重要原因,就是过去这些年写过太多依赖 MinIO 的内容:开源项目里的演示环境、文章里的示例、各种自动化脚本、测试环境、CI 流程,甚至一些长期运行的小型服务。
这些内容积累下来已经很多。如果未来每篇文章都要重新解释对象存储配置,每个示例都要换一种 SDK 用法,每套脚本都要重写一遍,那迁移本身就会变成新的负担。
所以从项目开始整理的时候,我就给自己定了一个原则:尽可能保留原有的 S3 使用体验。
应用程序不应该因为底层存储服务从 MinIO 换成 OtterIO,就必须修改业务代码。SDK 不应该换,访问方式不应该换,对象读写逻辑也不应该换。大部分情况下,修改 endpoint、账号密码和镜像名称就应该足够了。
一个最小 Docker Compose 示例可以写成这样:
services:
otterio:
image: soulteary/otterio:latest
container_name: otterio
command: server --address ":9000" --console-address ":9001" /data
ports:
- "9000:9000"
- "9001:9001"
volumes:
- ./data:/data
启动后,S3 endpoint 是:
http://127.0.0.1:9000
控制台地址是:
http://127.0.0.1:9001/otterio/
默认 root credentials 是:
otterioadmin / otterioadmin
这个示例只适合本地开发和演示。生产环境不应该使用默认凭据,也不应该只用单节点临时目录。
对开发者来说,最好的迁移往往是感觉不到迁移。
AWS SDK 可以继续连接,AWS CLI 可以继续使用,mc 可以继续管理 Bucket,rclone 可以继续同步数据,各种第三方工具也不需要专门适配。很多时候,一个项目真正成功的标志,不是用户发现它,而是用户没有发现它,因为系统已经平滑地完成了替换。
过去几年里,MinIO 之所以能够成为技术文章里的“默认对象存储”,很大程度上也是因为这一点。
写文章和文档的时候,不需要花大量篇幅解释对象存储本身。读者默认知道它是什么,默认知道怎么启动,默认知道如何连接。于是大家可以把注意力放在真正想讨论的问题上。
OtterIO 希望延续的,就是这种体验。
它不是要重新定义 S3,而是在保留原有使用习惯的前提下,让这些文章、示例、测试环境和轻量部署场景继续跑下去。
第十二步:诚实说明适用范围
文章写到这里,反而应该把话说得更保守一点。
很多开源项目的问题,不是功能不够,而是文档太乐观。大家总是习惯先看支持什么、性能多少、有没有这个功能、能不能替代某个产品,却很少认真阅读项目不适合什么场景。
但真正导致线上事故的,往往恰恰是后者。
所以 OtterIO 在 README 里明确提醒,正式采用之前需要根据自己的部署上下文进行评估,包括工作负载、容量和吞吐目标、合规与数据驻留要求、支持版本策略,以及组织内部的变更管理要求。
基础设施组件上线前,也应该经过实验环境、预发环境到生产环境的分阶段验证。
这个过程不会因为项目名字从 MinIO 变成 OtterIO 而消失。
S3 兼容也不等于 AWS S3 完全一致。对象存储领域本身就存在大量实现差异,不同厂商对于 ACL、Replication、Object Locking、Versioning、Lifecycle 等能力的支持程度也各不相同。
更准确的说法是:OtterIO 适合绝大多数开发、测试、CI 和文章示例场景。至于生产环境,则应该根据具体需求验证对应能力是否满足要求。
同样,单节点启动解决的是快速体验问题,不是高可用问题。
开发环境追求简单,生产环境追求可靠。前者希望一分钟启动完成,后者需要考虑故障恢复、数据冗余、容量扩展、监控告警、备份策略、升级策略和回滚方案。
README 里也专门提醒,Standalone OtterIO 更适合开发和评估;如果需要 Versioning、Object Locking、Bucket Replication 等能力,应当使用启用 Erasure Coding 的分布式部署,并按照对象存储系统的设计要求规划磁盘和节点数量。
安全策略上,也需要把话说清楚。
当前 OtterIO 的维护工作主要围绕主线代码进行。公开 Docker 镜像和源码包本质上是 main 在某个时间点的快照,会随着安全和兼容性修复向前滚动。安全修复优先落在 main,tagged releases 是 best effort。对于已经被再次 fork、私有修改或者 vendored 进其他项目的代码副本,维护者无法直接保证后续修复能够自动传递过去。
这听起来不够“商业”,但我认为这是更诚实的表达。
开源项目可以公开代码、公开修复、公开讨论,但最终是否升级、是否部署、是否验证,仍然是使用者自己的责任。对象存储也只是整个系统中的一个环节,它依然需要监控、备份、容量规划、升级策略和故障恢复方案。
所以 OtterIO 不应该被包装成“无脑替代所有对象存储”的方案。
它更适合本地开发、CI、测试环境、博客示例、小型私有化场景,以及愿意自己评估和验证的团队。
越是基础设施软件,越需要诚实地描述边界。这不会削弱项目价值,反而会让它的价值更清楚。
最后
回头看,OtterIO 的出现并不是因为缺少一个新的对象存储软件。
恰恰相反,今天能够选择的对象存储项目已经很多了。MinIO、SeaweedFS、Ceph、Garage、OpenIO,以及各种云厂商的对象存储服务,都有各自适合的场景。
OtterIO 不打算参与这种竞争,它更像一次维护工作。项目想解决的是一个更具体的问题:当我们希望继续使用 Apache 2.0 时代 MinIO 这条技术路线时,是否还能有一个许可证边界清楚、代码来源可追溯、安全状态可跟踪,并且可以继续构建、测试和发布的项目。
然后,继续向前维护,仅此而已。
把一条仍有使用价值的旧代码线重新整理出来,补齐公开问题,修复确认过的风险,更新工具链和依赖,建立 CI、Release 和镜像发布链路,再把适用范围和风险边界写清楚。
如果你需要这样的 S3 兼容对象存储,OtterIO 可以作为一个选择。如果不需要,也没关系。它从一开始就不是为了替代所有对象存储。至于结果如何,交给时间和实际使用场景去验证就好。
下一篇文章里,我会把话题从项目本身转向迁移实践。过去文章里的 MinIO 示例应该怎么调整,Docker Compose 需要修改哪些内容,mc、AWS CLI 和常见 SDK 是否能够直接使用,以及当我们更新旧文章的时候,应该如何向读者说明这些变化。
这些问题,可能比项目本身更有实际价值。
你可能也会对云栈社区里的其他技术实践感兴趣,那里有不少同行在分享类似的经验。
—EOF
引用链接
[1] 重新审视 MinIO:许可证、归档、社区 fork 与我的 Apache 2.0 基线: https://soulteary.com/2026/06/07/revisiting-minio-license-archive-community-forks-and-my-apache-2-baseline.html
[2] soulteary/otterio: https://github.com/soulteary/otterio/
[3] OtterIO README: https://github.com/soulteary/otterio
[4] OtterIO 当前 go.mod: https://github.com/soulteary/otterio/blob/main/go.mod
 发表于 2026-6-8 19:59:49
|
查看: 125|
回复: 0
发表于 2026-6-8 19:59:49
|
查看: 125|
回复: 0
