是不是背了无数遍 MVCC 的概念,一遇到线上的幻读、重复读异常就懵了?是不是总也搞不清 ReadView 到底是在什么时候生成的?本文直接从 InnoDB 的源码切入,把 MVCC 的底裤都给你扒开看看。读完这篇,再也不怕相关的面试题和线上问题了。
一、MVCC 到底解决了什么问题
咱们得先搞明白,MySQL 为什么非要整出 MVCC 这么个玩意儿?本质上,它就是为了解决读写冲突带来的性能瓶颈。
我们都知道,数据库要保证事务的隔离性,最直接的办法就是读写都加锁:写的时候加排他锁,读的时候加共享锁。这样一来,读写互斥,自然就不会出现脏读、不可重复读的问题。但代价是什么呢?性能直接被“打骨折”!尤其在读多写少的场景下,所有的读请求都得排队等写操作释放锁,并发能力瞬间就垮掉了。
而 MVCC(多版本并发控制)的核心思路就高明多了:写操作负责生成数据的历史版本,读操作则直接去读对应的历史版本,全程不需要加锁,读写互不冲突,完美解决了读性能的问题。
二、MVCC 的实现基石:三个隐藏字段
InnoDB 中的每一行数据,除了你自己定义的那些字段,还会默认给你加上三个隐藏字段。这是 MVCC 实现的基石。我们先来看一下简化后的源码定义:
// 简化后的InnoDB行结构定义
struct row_struct {
// 用户自定义的字段
...
// 事务ID:最近一次修改这行数据的事务ID,大小6字节
trx_id_t DB_TRX_ID;
// 回滚指针:指向这行数据上一个版本在undo log中的位置,大小7字节
roll_ptr_t DB_ROLL_PTR;
// 隐藏主键:如果用户没定义主键,InnoDB会自动生成这个6字节的ROW_ID
row_id_t DB_ROW_ID;
}
这三个字段里,DB_TRX_ID 和 DB_ROLL_PTR 是 MVCC 的核心。每次有事务修改数据时,都会把自己事务的 ID 赋值给 DB_TRX_ID,同时利用 DB_ROLL_PTR 指向修改前的旧版本,并把旧版本数据存到 undo 日志里。这就像用链条把一个个数据版本串了起来。
打个比方,现在有一个事务 ID 为 100 的事务,把 name 字段从 “张三” 改成了 “李四”,那么数据版本链就长这样:
当前行(DB_TRX_ID=100, name=李四) → undo 日志版本(DB_TRX_ID=90, name=张三) → 更早的版本...
三、核心机制:ReadView 的结构
光有版本链还不够,我们怎么知道哪个版本对当前事务是可见的呢?这就得靠 ReadView(一致性视图)了。我们先来看看 InnoDB 源码里 ReadView 的简化结构:
// 简化后的ReadView结构定义
class ReadView {
private:
// 生成ReadView的时候,当前所有正在活跃(未提交)的事务ID集合
std::set<trx_id_t> m_ids;
// 生成ReadView的时候,活跃事务中最小的事务ID
trx_id_t min_trx_id;
// 生成ReadView的时候,数据库下一个要分配的事务ID(也就是当前最大事务ID+1)
trx_id_t max_trx_id;
// 生成这个ReadView的当前事务的ID
trx_id_t creator_trx_id;
public:
// 可见性判断的核心方法
bool changes_visible(trx_id_t id) const;
}
很多人搞不清楚这几个字段到底是什么意思,我用大白话给你翻译一下:
- 你可以把 ReadView 理解成,在你执行查询的那一瞬间,给数据库里所有事务拍的一张 “快照”,这张快照记录了此刻哪些事务是还没提交的。
min_trx_id 就是这张快照里,所有未提交事务中最小的那个事务 ID。比这个 ID 还小的事务,那肯定都已经提交了。max_trx_id 是快照生成那一刻,数据库即将要分配的下一个事务 ID。比这个 ID 大的,那必然是快照生成之后才开启的事务。m_ids 就是快照生成那一刻,所有还没提交的事务 ID 列表。
四、最核心的可见性判断流程
有了版本链和 ReadView,接下来就是最核心的可见性判断逻辑了。我直接把简化后的源码贴出来:
bool ReadView::changes_visible(trx_id_t id) const {
// 1. 如果这行数据的修改事务ID等于当前事务ID,说明是自己改的,肯定可见
if (id == creator_trx_id) {
return true;
}
// 2. 如果修改事务ID比最小活跃ID还小,说明修改的事务在快照生成前已经提交了,可见
if (id < min_trx_id) {
return true;
}
// 3. 如果修改事务ID大于等于最大ID,说明修改的事务是快照生成之后才开启的,不可见
if (id >= max_trx_id) {
return false;
}
// 4. 走到这里说明事务ID在min和max之间,判断是不是在活跃事务集合里
// 如果在集合里,说明快照生成的时候这个事务还没提交,修改不可见;如果不在,说明已经提交了,可见
return m_ids.count(id) == 0;
}
整个判断逻辑的流程图如下,看不懂代码的,看下面这张图就全懂了:
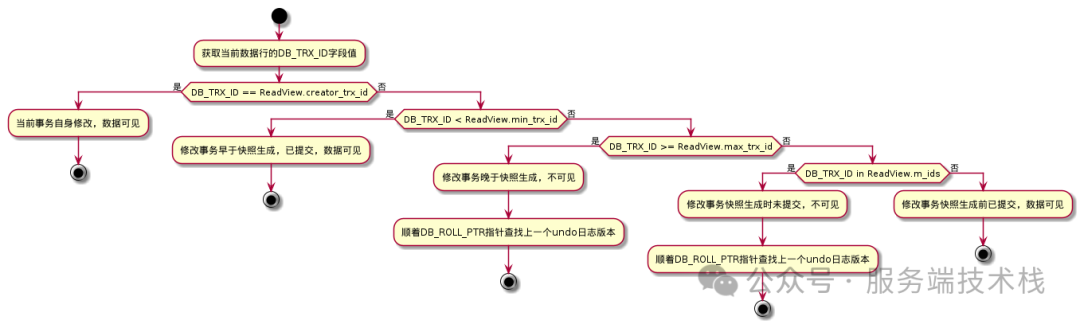
如果一个数据版本被判断为不可见,InnoDB 就会顺着 DB_ROLL_PTR 指针,去 undo 日志里找到上一个版本,然后重新走一遍上面的判断逻辑。这个过程会一直重复,直到找到一个可见的版本,或者遍历完所有版本链都找不到,就返回空。
五、RR 和 RC 隔离级别下的 MVCC 差异
很多人都知道,InnoDB 的可重复读(RR)和读已提交(RC)隔离级别,都是用 MVCC 来实现的。但这两者的区别到底在哪?其实,最核心的差异就在于 ReadView 的生成时机不同:
-
RC(读已提交)级别下:每次执行 SELECT 查询的时候,都会生成一个全新的 ReadView。
这意味着,同一个事务里的两次 SELECT,可能会用到两个不同的 ReadView。如果两次查询的间隙里,有其他事务提交了修改,那么第二次查询就能看到这个最新的提交内容。这就是 RC 级别下为什么会出现不可重复读的原因。
-
RR(可重复读)级别下:只有事务中第一次执行 SELECT 查询的时候,才会生成 ReadView,并且之后本事务内的所有查询都复用这一个 ReadView。
这样一来,整个事务期间看到的数据都是一致的,自然就不会出现不可重复读的问题。但是要注意,RR 级别下的 MVCC 并不能完全解决幻读问题,它解决的只是快照读的幻读。对于当前读(比如 SELECT ... FOR UPDATE),幻读问题还是得靠间隙锁(Gap Lock)来解决。
我们来举一个实际的例子,假设现在有两个事务,事务 A(ID=200)和事务 B(ID=300):
-
时间点 1:事务 A 开启,并执行了第一次查询 name 字段的操作。这时生成 ReadView,活跃事务 ID 集合是{200, 300},min_trx_id 是 200,max_trx_id 是 301。
-
时间点 2:事务 B 把 name 改成了“王五”,并提交了事务。
-
时间点 3:事务 A 执行第二次查询 name 字段。
-
如果是在 RC 级别下,时间点 3 会生成一个新的 ReadView。此时活跃事务集合里只有 {200}。判断逻辑发现,事务 ID=300 小于 max_trx_id,并且不在活跃集合里,所以事务 B 的修改是可见的。事务 A 将看到“王五”,这就出现了不可重复读。
-
如果是在 RR 级别下,时间点 3 会复用第一次查询时的 ReadView。判断逻辑发现,事务 ID=300 依然存在于活跃事务集合 m_ids 里,所以这个修改不可见。事务 A 看到的仍然是原来的内容,这便保证了可重复读。
六、常见误区避坑
最后,给大家梳理几个关于 MVCC 的常见误区:
- MVCC 只在 InnoDB 的 RC 和 RR 隔离级别下生效。读未提交级别,每次都直接读最新数据,根本用不上 MVCC;串行化级别,所有操作都靠加锁来保证,也不需要 MVCC。
- undo log 不是无限保留的。InnoDB 有一个专门的 purge 线程,会定期清理那些不再被任何事务需要的 undo 日志。如果你一个事务开了好几个小时都不提交,就可能导致 undo 日志不断膨胀,白白占用大量磁盘空间。
- MVCC 的版本链是针对聚簇索引的。二级索引上并没有
DB_TRX_ID 和 DB_ROLL_PTR 这两个隐藏字段。查询二级索引时,需要先根据二级索引找到对应的聚簇索引主键,然后再回到聚簇索引上走版本链进行可见性判断,因此性能会比直接查聚簇索引差一些。
关于 MVCC 的底层逻辑今天就先聊到这儿。你是不是也曾被这些概念绕晕过,或者在线上踩过相关的坑?对源码的解读还有哪些疑问?欢迎来云栈社区一起深入探讨,咱们论坛里见真章。
 发表于 2026-6-9 02:34:39
|
查看: 197|
回复: 0
发表于 2026-6-9 02:34:39
|
查看: 197|
回复: 0
