不知道你有没有这个习惯。
不管是在手机上看一个技术直播,还是刷到一本好书、一个好工具的介绍,第一反应都是截图保存。那一瞬间的感觉特别好,好像这条信息已经归我了。
但事实是,截完图它就安静地躺在相册里了。没标签、没分类、没有任何上下文。和你前天拍的午饭照、昨天拍的快递单混在一起。几百张、上千张,越攒越多,越多越不想翻。上周我想找一个之前截过的 Claude Code 直播分享截图,在相册里翻了十分钟没找到,最后放弃了重新去搜。
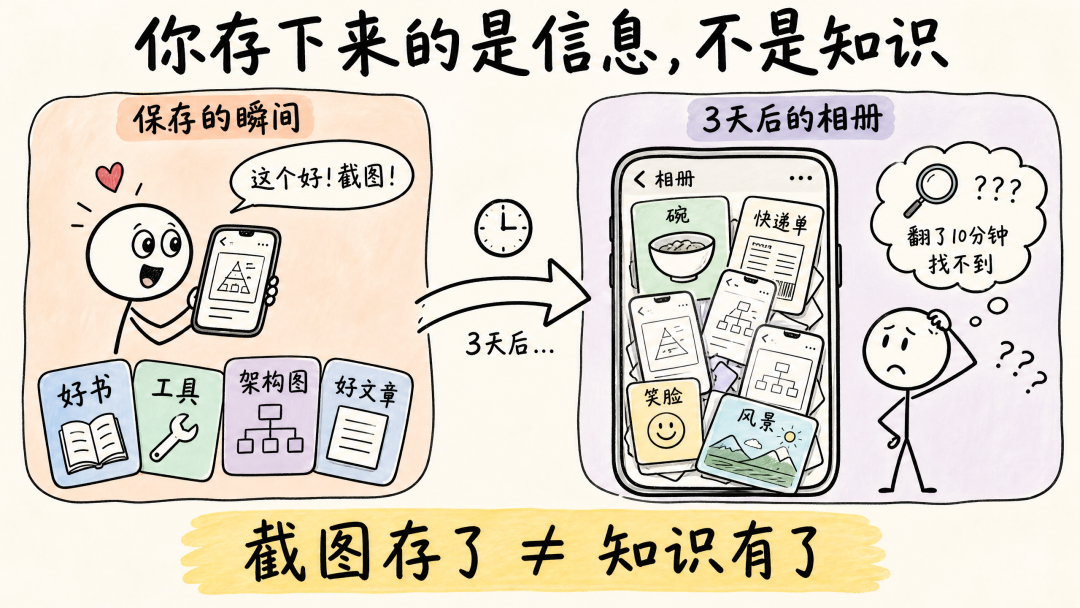
你存下来的是信息,但它从来没变成过知识。
我自己在知识管理上折腾过不少工具。Obsidian 的 LLM Wiki 跑了好几个月,NotebookLM 也接上了自动化投喂。主动记下来的笔记、主动收藏的文章,这些算是管起来了。但说实话,这套东西的上手门槛不低。要配环境、要写命令、要理解一堆概念,对大多数人来说学习成本太高了。
而且就算搭好了,上周我翻相册的时候还是突然意识到:我整理的全是“主动写下来的东西”。那些随手截的图呢?工具截图、文章截图、架构图、别人甩过来的链接截图——这些东西的量比我的笔记多得多,但从来没进过我的知识体系。
前阵子在小某书看到有人用快捷指令整理相册截图,思路挺有意思的。但我在想:能不能不只是分个类,而是直接把截图变成一个能搜索、能检索的知识库?
这个问题我卡了一阵子。截图不像文字笔记,你没办法直接往知识库里丢。它是图片,里面的信息是锁死的,你不拆开它,它就永远是一张图。而且相册里几千张截图,你也不可能一张张手动传到知识库里去整理。
但是这整条路径我用 Kimi Work 跑通了。而且跟我之前折腾的那些工具比,这个门槛低太多了。Kimi Work 是 Kimi 最近发布的一个桌面端产品,整体能力和定位都比较接近 Codex,电脑上装一个客户端就能用。不用写代码,不用配环境,不需要任何编程背景。
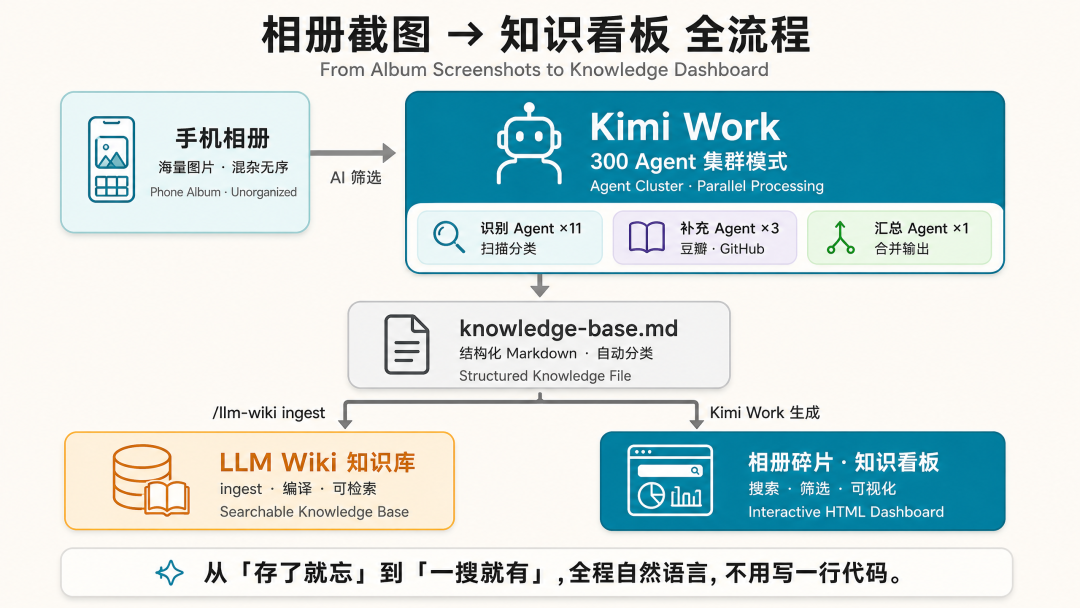
第一步:把相册里的碎片全捞出来
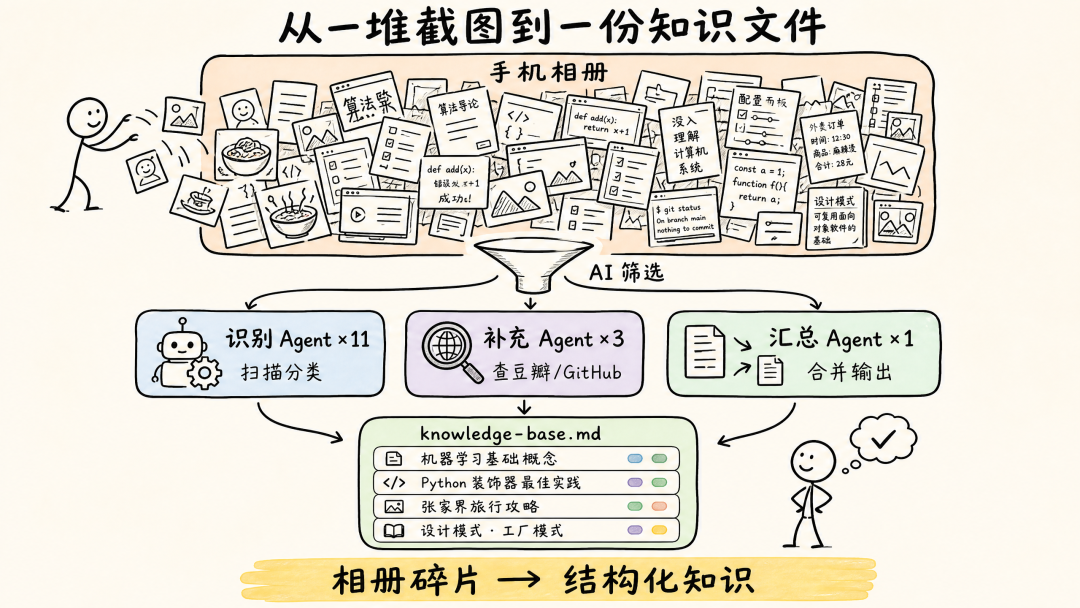
我先把手机相册里的截图同步到了电脑上的一个文件夹,大概 2 千多张图,什么类型都有。n8n 工作流截图、AI 工具界面截图、公众号文章截图、群聊里别人推荐的资源截图,还有一些书和电影的截图也混在里面。
然后我跟 Kimi Work 说了一段话。我在 Prompt 里定义了三种 Agent 角色——识别、补充、汇总,各自负责什么写清楚就行。至于每种角色要派多少个 Agent 出去、怎么分批、怎么调度,这些 Kimi 自己会判断。
当然,你也不一定要像我这样在 Prompt 里手动设计分工。Kimi 的 Agent 集群会根据你的任务自行拆解和分配。我这里写细一点,是因为想让集群的分工更可控。
发出去之后,我盯着屏幕看它怎么干的。它分了三段来执行。
第一段:扫描 + 规划
Kimi 先扫了一遍文件夹,发现里面有 2055 张图片。然后它自己做了一轮筛选——通过尺寸、格式、文件大小等特征,过滤出 1641 张截图候选。再进一步,按截图特征打分,挑出了 326 张高概率截图(score≥7),分成 11 个批次。
然后它自己创建了一份 plan.md,设计好 Agent 分工方案。右边的进度面板很清楚地列出了五步计划:

我什么都没干,它自己把活拆好了。
第二段:集群并行处理
这段是真让人愣了一下的地方。
Kimi 起了 11 个识别 Agent,每个领一个批次,并行识别截图内容。界面上能看到 Subagent 工具在同时跑:识别批次 09 截图内容——已完成,识别批次 10 截图内容——已完成,识别批次 11 截图内容——已完成……识别完了之后,3 个补充 Agent 接上,开始并行查资料。补充批次 01 背景信息——进行中,补充批次 02 背景信息——进行中,补充批次 03 背景信息——进行中。
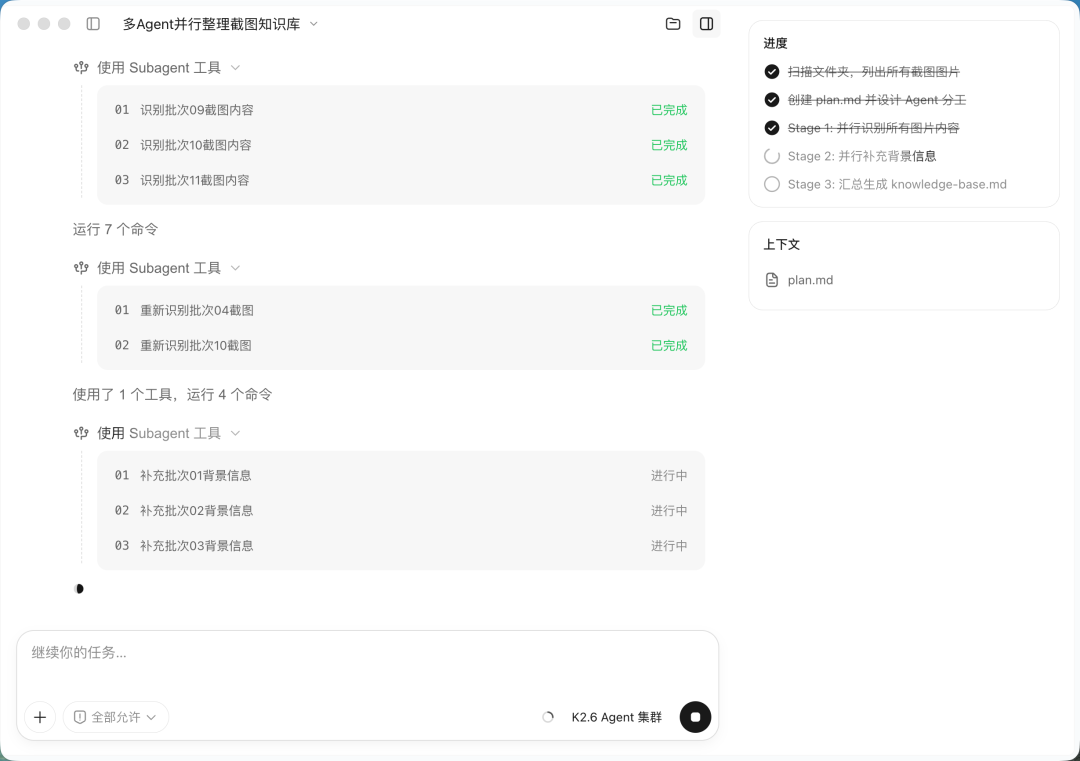
一群 Agent 同时干活的感觉确实很不一样。不是一个助手在那顺序跑任务,而是一个团队在并行推进,效率完全不在一个量级。
第三段:汇总输出
所有识别和补充的结果到齐之后,1 个汇总 Agent 把它们合并成最终的 Markdown 文件。

326 张截图,被分成了 7 大类。技术工具的补充了官网链接和定位说明,书影音的补充了作者和评分信息,公众号文章也补充了背景资料。最终输出一份 knowledge-base.md,每条信息都有类型、来源、核心观点、补充信息、标签和原始文件路径。
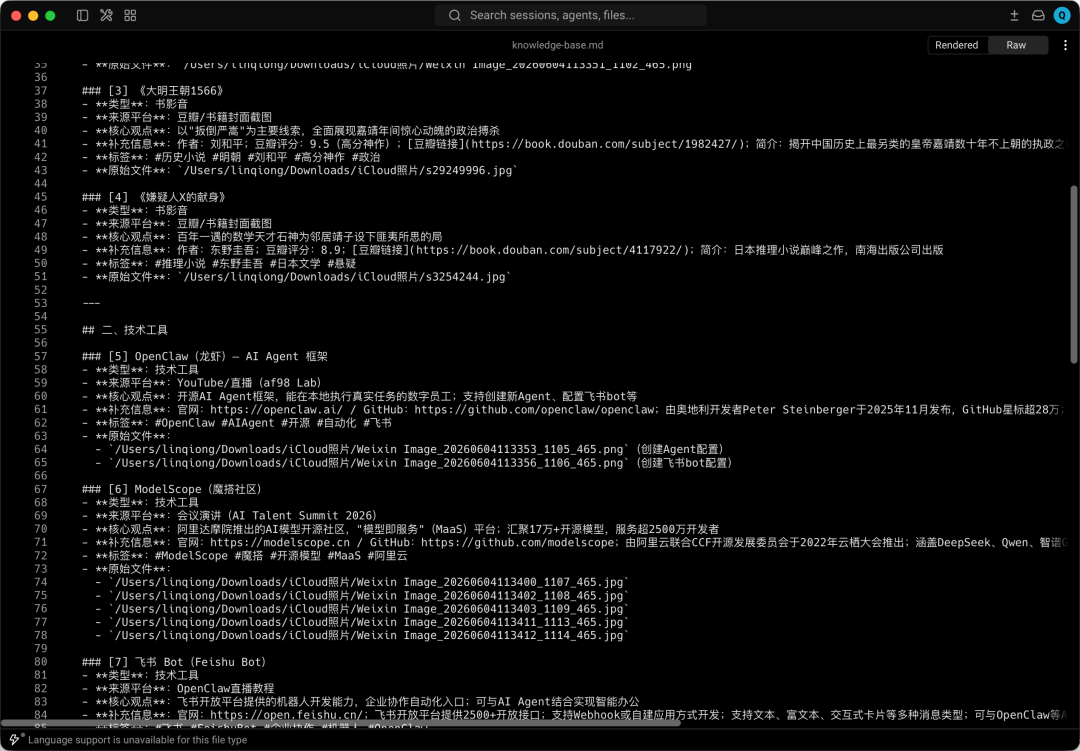
当然也有不完美的地方。Kimi Work 目前还是 Beta 阶段,有些模糊的截图识别得一般。但你想想,2055 张图片里筛出 326 张,自动分类、自动查资料、自动生成结构化文件,这要是手动来,得干多久?
到这一步,一堆乱七八糟的截图变成了一份结构化的 Markdown 文件。
我后来把这个过程叫“开矿”。你的相册就是一座没被开采过的知识矿,截图是矿石,Kimi Work 是采矿队。但这还只是第一步。
第二步:让捞出来的东西回到知识体系
一份 Markdown 文件存在桌面上,跟之前截图存在相册里其实没有太大区别,只是从“乱的”变成了“整齐的”。我想让它真正进入我的知识库,形成一个可检索、可调用的系统。
还记得我之前那篇 Hermes + LLM Wiki 的文章吗?那套体系有个 raw 目录,专门放原始素材,会自动把它编译成结构化的 Wiki 页面。Kimi Work 里也能直接调 llm-wiki 这个 skill。所以我直接把刚才生成的 knowledge-base.md 作为附件,在 Kimi Work 里说了一句:“/llm-wiki 把附件的文件存入到知识库中”。
使用了 15 个工具,运行了 5 个命令。跑完之后它给了我一份 ingest 报告。然后我试了一下检索。直接在 Kimi Work 里问:“/llm-wiki 找一下有没有东野圭吾相关的书籍截图”。一句话就找回来了。文件路径、作者、评分、标签,全都在。还能直接点开看原图。这张图是我之前随手截的豆瓣封面,截完之后就再也没打开过,我自己都忘了相册里有这个。
这一步操作很轻,附件加一句 ingest 命令就搞定了。但效果很关键:截图里的“死数据”接进了我已经在跑的知识飞轮。之前那个“采集→整理→检索→输出”的循环,现在多了一个入口。如果你也想搭建一套自己的技术文档与知识管理流程,不妨从这份自动化方案开始尝试。
第三步:生成一个能搜索的知识看板
前面两步解决了“捞回来”和“接回去”。但我还想再往前走一步。我希望有一个东西,能让我打开浏览器就看到所有截图里的知识碎片,按分类排列、能搜索、能点开看详情。就像一个私人的信息雷达。
所以我又跟 Kimi Work 说了一段话,这次写得比较细,直接贴出来:
你现在是我的自动化知识整理 Agent 团队。我需要你们像一个专业的前端开发团队和数据可视化团队一样分工协作,完成一轮"相册碎片 · 知识看板"的端到端编译任务。
【输入资料】 本地已经生成的 `knowledge-base.md`。请先阅读该文件,自动识别其中的分类结构、数据条数、标签体系和字段格式,作为后续所有步骤的数据源。
请启动集群模式,调度不同专长的子 Agent 并行执行以下任务:
【步骤一:前端架构与高密度 UI 编写(前端开发 Agent 介入)】
* 基于 `knowledge-base.md` 的实际数据,编写一个单文件、可交互的 `dashboard.html` 知识看板。
* 页面标题为"相册碎片 · 知识看板",副标题自动展示实际的数据条数和截图总数。
* 功能要求:
1. 顶部有动态搜索框,支持关键词实时过滤标题、标签、核心观点。
2. 根据文件中的实际分类自动生成高亮分类筛选按钮。
3. 卡片式布局,卡片需展示:核心摘要、分类标签、来源平台、补充信息(如豆瓣评分、GitHub Stars、官网链接等)。
4. 支持点击卡片弹出高亮 Modal(模态框)展示详情,包含原始文件路径。
【步骤二:引入 ECharts 数据可视化(数据可视化 Agent 介入)】
* 在网页顶部,引入 CDN 链接加载 Apache ECharts,基于文件中的实际数据自动绘制两个动态可视化图表:
1. "个人知识碎片分类占比图"(雷达图 Radar Chart,维度和数值从文件中的分类自动提取)。
2. "技术栈与平台来源分布图"(横向柱状图 Horizontal Bar Chart,来源平台和占比从文件中自动统计)。
* 图表风格必须与整体暗黑科技风无缝融合,支持 Hover 显示 Tooltip。
【步骤三:视觉与轻量特效打磨(视觉设计师 Agent 介入)】
* 风格采用 Muted & Pastel(低饱和度、温润克制)的暗黑科技风,参考高级 SaaS 控制台质感:
* 背景色:#121315(深炭灰)
* 卡片背景:#1E2022(微亮炭黑),圆角统一 12px,带极为内敛的浅色描边。
* 特效:所有卡片和按钮的 Hover 状态必须有 `transition: all 0.3s ease;` 的平滑微浮起动画;点击弹窗使用毛玻璃滤镜(Blur CSS Effect)做背景遮罩,营造精致的 UI 质感。禁止使用大体量 3D 框架。
【步骤四:多产物交叉交付(文档交付 Agent 介入)】 请在当前工作目录下,同时输出并保存以下文件:
1. `dashboard.html`(完整可交互的前端看板网页,必须保证无网络也能看骨架和图表交互)
2. `dashboard_data.json`(将所有数据格式化为结构化的底层 JSON,供后续调用)
3. `agent_build_report.md`(详细记录本次集群调度中,各子 Agent 的分工合作情况与质量检查清单)
任务流程长且细节多,请各 Agent 互补协作,不要偷懒省略代码,完成后列出所有生成文件的路径。
这次跑的时间稍微长一点,大概 15 分钟。因为它不光要把数据组织好,还要写前端代码、排版、做搜索和图表功能。跑完之后我打开一看,效果远远超出了我的预期。
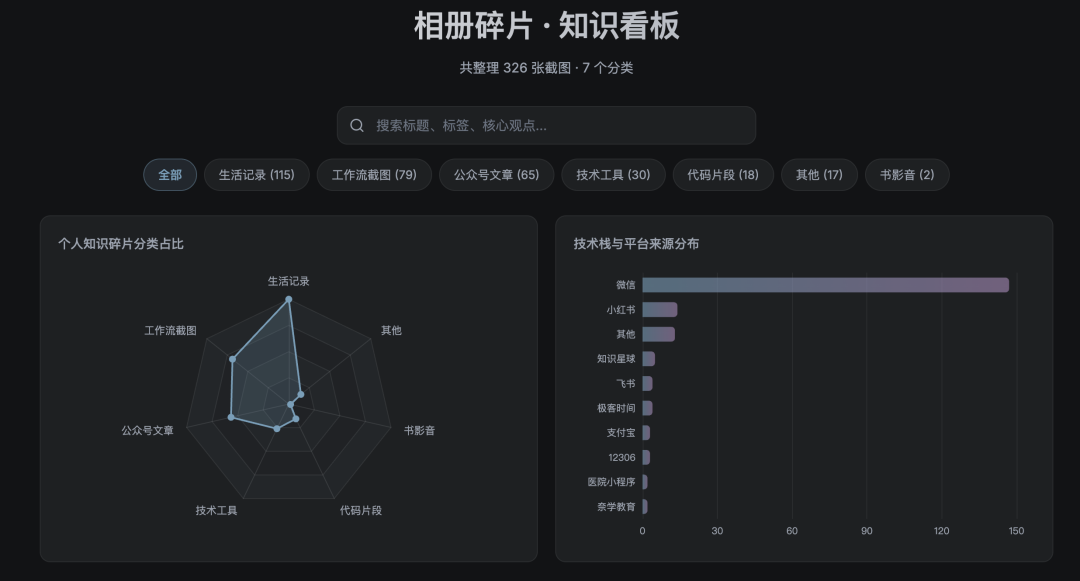
左边那个雷达图一看就乐了,“生活记录”那一角直接顶到了最外圈,比“技术工具”和“工作流截图”高出一大截。看来我平时截得最多的不是技术资料,是生活琐碎。热爱生活这件事,相册不会骗人。
我点了一下“公众号文章”的分类按钮,之前截过的公众号内容全出来了,每条都带着标签和摘要。
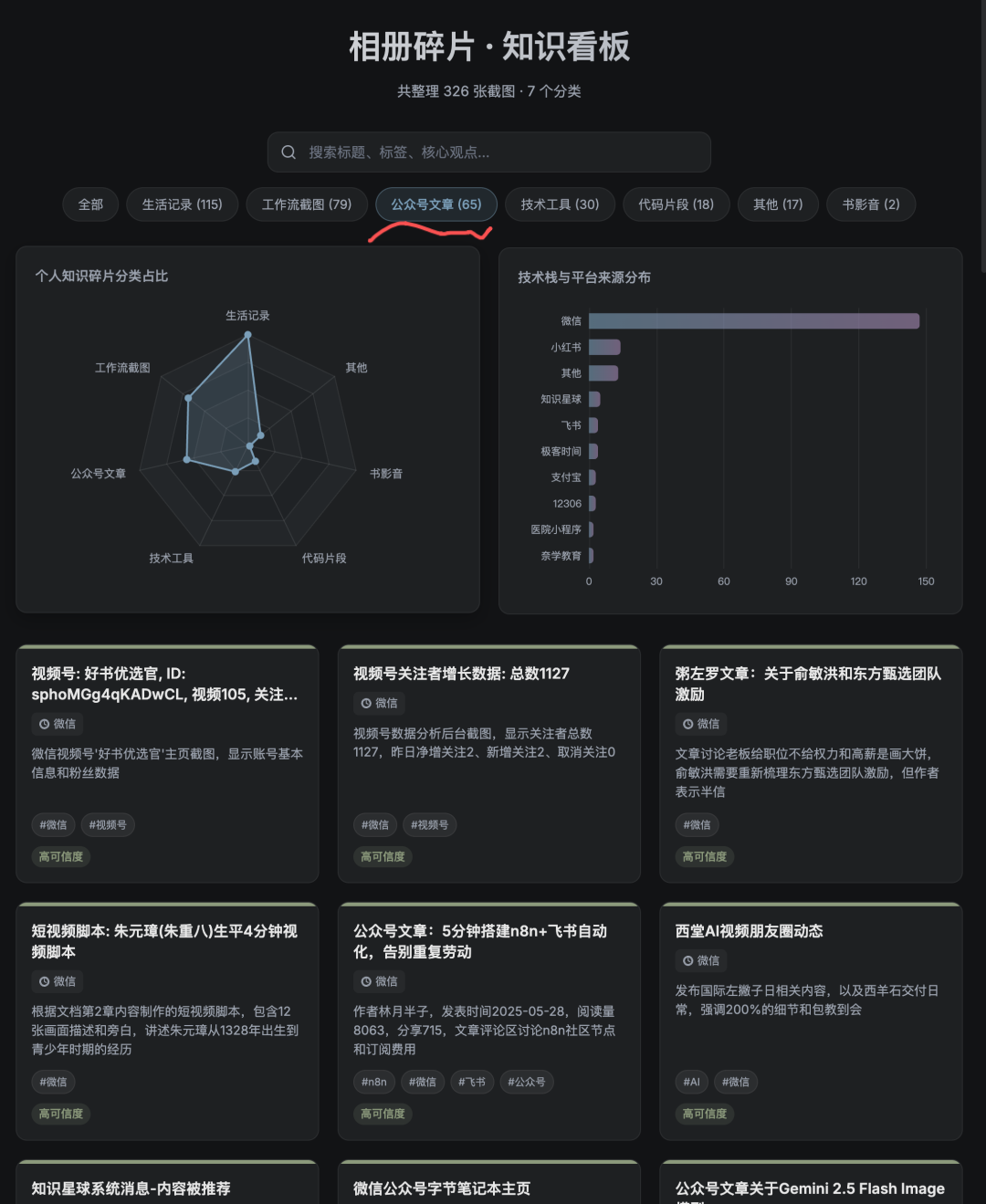
搜索也能用。我搜了一下“东野”:
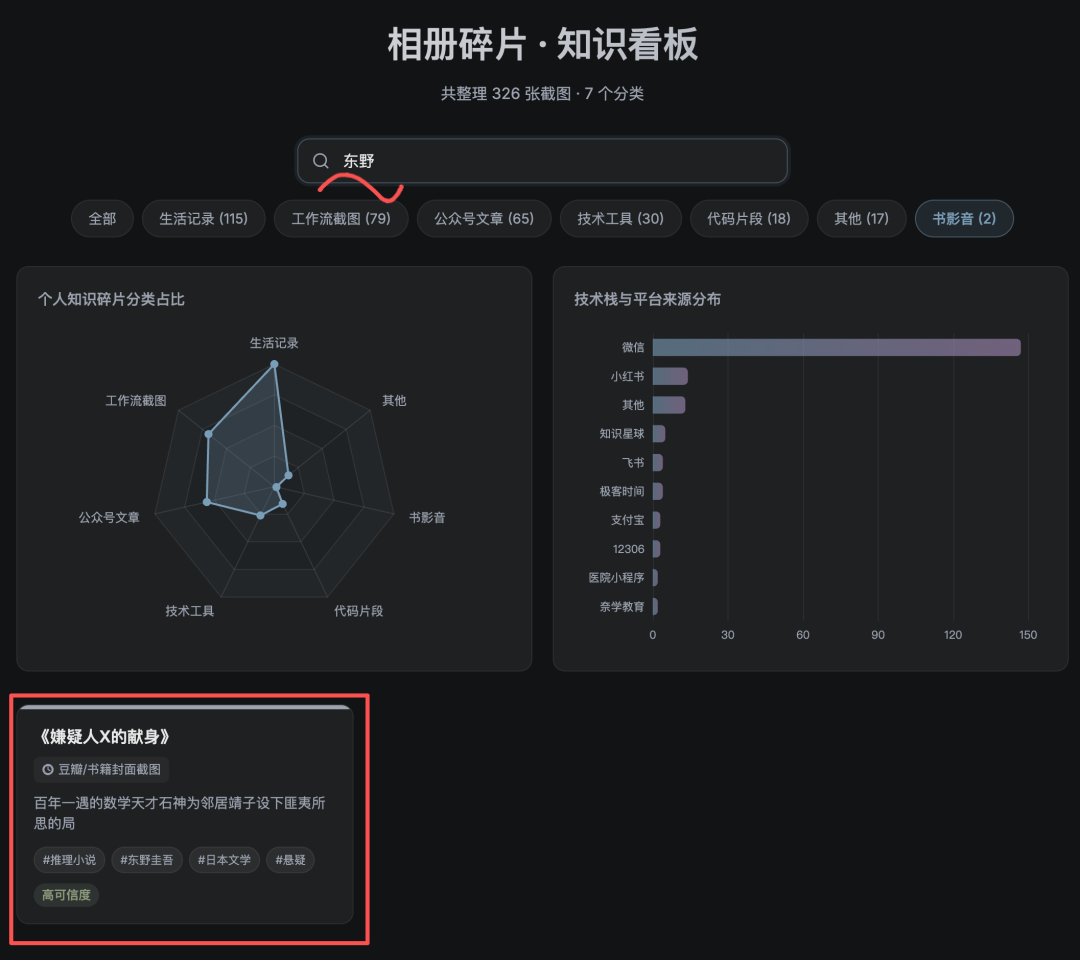
点开卡片还有详情弹窗:
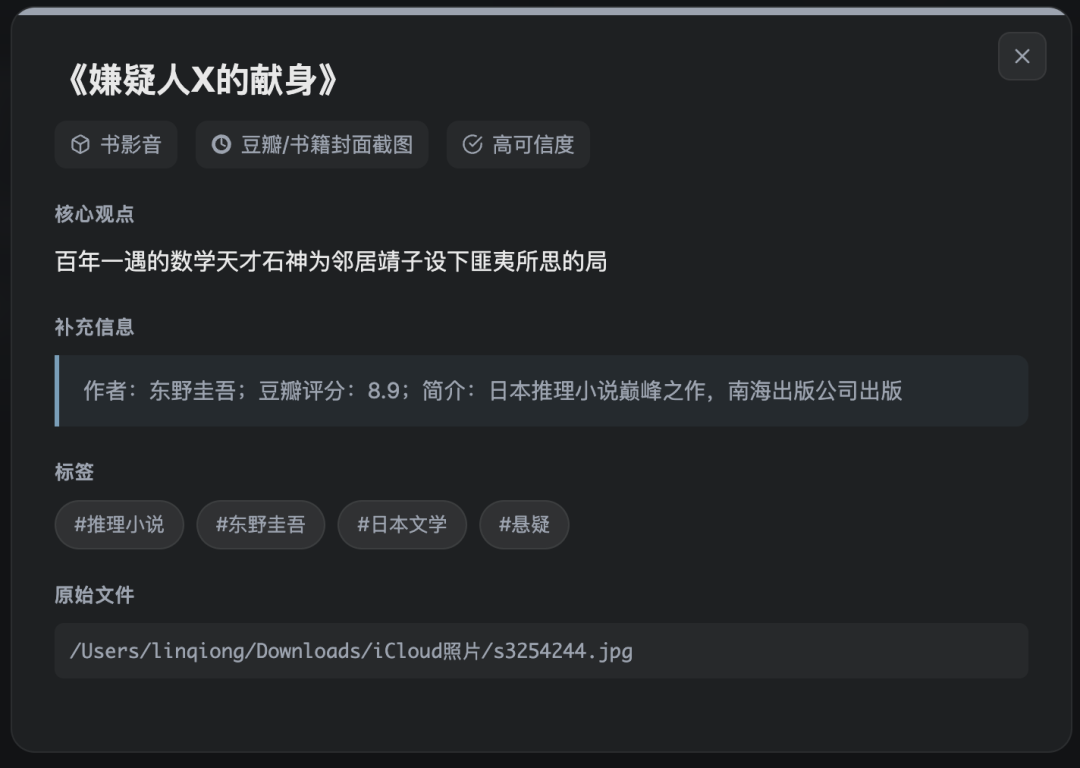
核心观点、补充信息、标签、原始文件路径,全都在。想找原图,路径直接复制就能打开。这个完成度超出我预期了。深色背景、卡片布局、雷达图、柱状图、搜索、详情弹窗,作为一个用自然语言指令从零生成的 HTML 页面,它已经接近一个正经产品的原型了。当然也有可以打磨的地方。卡片上没有直接显示缩略图,部分摘要可以更精炼。但这些都可以继续跟 Kimi Work 说哪里要调,它能在已有代码上迭代。
这套流程还能怎么玩
从我自己跑出来的结果就能看到,相册里什么都有,生活记录、工作流截图、技术工具、书影音,乱七八糟混在一起。但 Kimi Work 全给你分清楚了。这套流程换个人换个相册完全一样能跑。
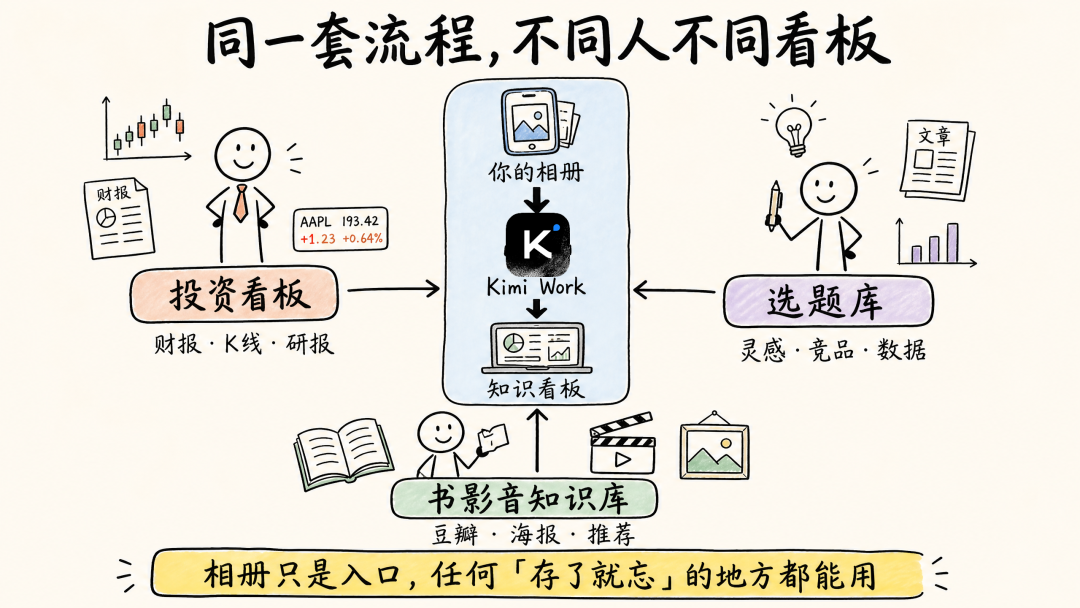
你如果是做投资的,相册里可能存了一堆财报截图、K 线图、研报截图——让 Kimi Work 帮你提取关键数据,生成一个投资信息看板。你如果是做内容的,相册里可能存了一堆选题灵感截图、竞品文章截图、数据截图——直接变成一个选题库。你如果平时爱看书、看电影、逛展览,相册里可能存了一堆豆瓣截图、海报截图、推荐截图。跑一遍出来的就是一个私人书影音知识库。而且 Kimi Work 在处理过程中会自动去豆瓣补评分、查简介——前面我那批截图里已经看到这个效果了。
相册只是一个入口。你电脑里的本地文件夹、下载目录、微信收藏,任何“存了就忘”的地方,这套逻辑都通。对于想深入探索人工智能在个人效率领域应用的朋友来说,这正是一个绝佳的实战切入点。
写在最后
回到开头那个问题。我们每天都在截图、收藏、保存。但这些动作结束的那一刻,信息就开始贬值了。不是因为它没用,而是因为你再也找不到它。
这次用 Kimi Work 把相册翻了一遍之后,我最大的感受倒不是“AI 真厉害”,而是——原来我这些年存下来的东西,比我以为的多得多。它们不是碎片,只是没被整理过。
知识管理这件事,我之前花了不少精力搭流程。但如果你连素材都没整理过,流程再好也是空跑。每个人手机里都有一座没被开采过的知识矿。区别只在于,你有没有把采矿队派进去。先把矿开了。后面的事,后面再说。
在云栈社区上,有很多像我一样热衷于用技术优化工作流的小伙伴,大家会分享各种实用的学习笔记和避坑经验,欢迎一起来交流。
 发表于 2026-6-9 20:31:39
|
查看: 176|
回复: 0
发表于 2026-6-9 20:31:39
|
查看: 176|
回复: 0
