用AI处理生物数据,就像开着一辆现代汽车,却试图穿越一座中世纪老城。街道是为行人设计的,弯弯绕绕,路标也是给人看的,没有高速路,更没有标准接口。车再好,也跑不起来。
Anthropic最近发布了一篇文章,核心观点一针见血:生物数据基础设施还没准备好迎接AI Agent时代,我们必须重建它。
为什么代码Agent跑得快,生物Agent跑不动?
做过软件开发的人应该都有体会:现在的AI写代码已经相当能打——解决GitHub Issue、跑通测试用例,整个流程顺畅得像开高速公路。
但生物研究不是这样。
软件工程有版本控制、规范的API文档、包管理器,整个环境天然适合机器操作。生物数据则完全相反:数据库五花八门,每个库有自己的标识符规则、文件格式和过滤逻辑,还有大量隐性知识藏在研究员的脑子里,从未被系统性地记录过。
Andrej Karpathy最近在一次关于AI时代软件开发的演讲中忍不住吐槽:他让AI写个小应用,代码部分很快搞定,但一碰到身份验证、支付接口和部署,就陷入了在各种网页仪表盘里不停点击的噩梦。文档只会告诉他:“去这个URL,找这个下拉菜单,点一下。”他的结论是:不应该再让人去做这些事,应该为Agent而建。
Karpathy遭遇的这种困境,生物研究者们已经经历得太久了。
病毒数据库:一个典型的噩梦场景
生物研究里有一类非常基础的工作:从数据库里取序列数据。
NCBI Virus是病毒学家最常用的序列数据库,收录了来自GenBank、RefSeq以及国际INSDC生态系统的病毒序列记录。疫苗设计、诊断试剂开发、蛋白质模型训练数据构建,通常都从这儿开始。
可问题在于,NCBI Virus的很多过滤逻辑只存在于它的网页界面里。如果一个研究员想取出所有2025年发布的、含有表面糖蛋白的SARS-CoV-2序列,在网页上点几下就行。但想用程序自动完成?你可能需要写几百行代码,把REST接口、Datasets接口、E-utilities接口拼在一起,一页一页地翻取数据,下载几百GB的内容,再在本地做过滤,然后把绝大多数数据扔掉。
在病毒学实验室里,如何构建研究数据集的操作指南,常常以一长串复杂筛选条件的形式,在研究员之间口耳相传。这不正是Karpathy抱怨的那种工作方式吗?
为什么这一点如此重要?看看这个真实案例。
2026年5月,刚果民主共和国暴发了由本迪布焦病毒引起的埃博拉疫情。INRB金沙萨在5月14日分析13份血液样本,次日确认其中8份为阳性,疫情宣告暴发。到5月29日,世卫组织已报告逾1000例确诊和疑似病例,死亡超200人。研究人员还测序了首批近完整的疫情基因组,证实这是一次新的病毒溢出事件。
面对这批新基因组,公共卫生官员需要回答三个紧迫问题:这次疫情的病毒与历史上的埃博拉病毒有多大差异?现有诊断方法还能检测到它吗?现有疗法还能保护患者吗?
回答这三个问题,都需要把新基因组与NCBI Virus上的历史基因组进行比对。而整个流程的第一步,依然是手动在网页界面里点来点去,复现各种复杂的筛选条件,并祈祷结果是完整、正确的。
让Agent来干:16.9%到91.3%,都不够用
那么,当前最强的AI Agent在这件事上到底表现如何?
Anthropic团队构建了一个名为VirBench的基准测试,包含120个真实的病毒序列查询任务,覆盖40种病原体,每道题都有经人工验证的正确答案。这些查询反映了病毒监测、诊断试剂设计和蛋白质模型训练数据构建中真实存在的任务。
参与测试的模型包括Claude、Biomni、Edison Analysis和GPT系列。
一个典型的查询长这样:从NCBI提取TaxID为3052462(扎伊尔埃博拉病毒)的病毒序列,条件是宿主为人类、样本采集地为非洲、采集时间在2014年1月1日到2014年6月20日之间、最小序列长度15200个碱基、最多1900个模糊字符(N),并排除实验室传代样本。
测试结果出来了:当Agent完全靠自己解决这些查询时,Claude Sonnet 4、Claude Opus 4.7、Biomni、Edison Analysis、GPT-5.2-pro和GPT-5.5的平均准确率在16.9%到91.3%之间波动。
这个范围听起来有高有低,但关键在于:在生物数据构建任务里,标准实际上是100%。一条序列的遗漏或错误,可能会让诊断试剂的覆盖范围评估失真,也可能让疫情暴发的推算起点提前或推后好几周。
更麻烦的是,同一个模型、同一个问题,每次回答都不一样。以上面那道埃博拉病毒查询为例,Sonnet 4第一次返回了106条序列(正确答案是266条),第二次返回15条,第三次返回5条。提示词完全相同。
错误的序列数据,能把疫情起源推到1922年
这种不稳定性带来的后果,远不止数字不对那么简单。
用Agent取回的序列分别构建系统发育树——这是病毒学中用来重建疫情中各病毒样本亲缘关系的标准分析方法。其中一个关键指标是最近共同祖先时间(TMRCA),它推算这次疫情的病毒起源于什么时候,直接影响到对疫情发生时间和地点的判断。
用人工在NCBI网页上手动检索的序列集构建的系统发育树,给出的TMRCA是2014年1月,与此前关于2014年埃博拉疫情的研究结果一致(95%最高后验密度区间为2014年1月27日至3月14日)。
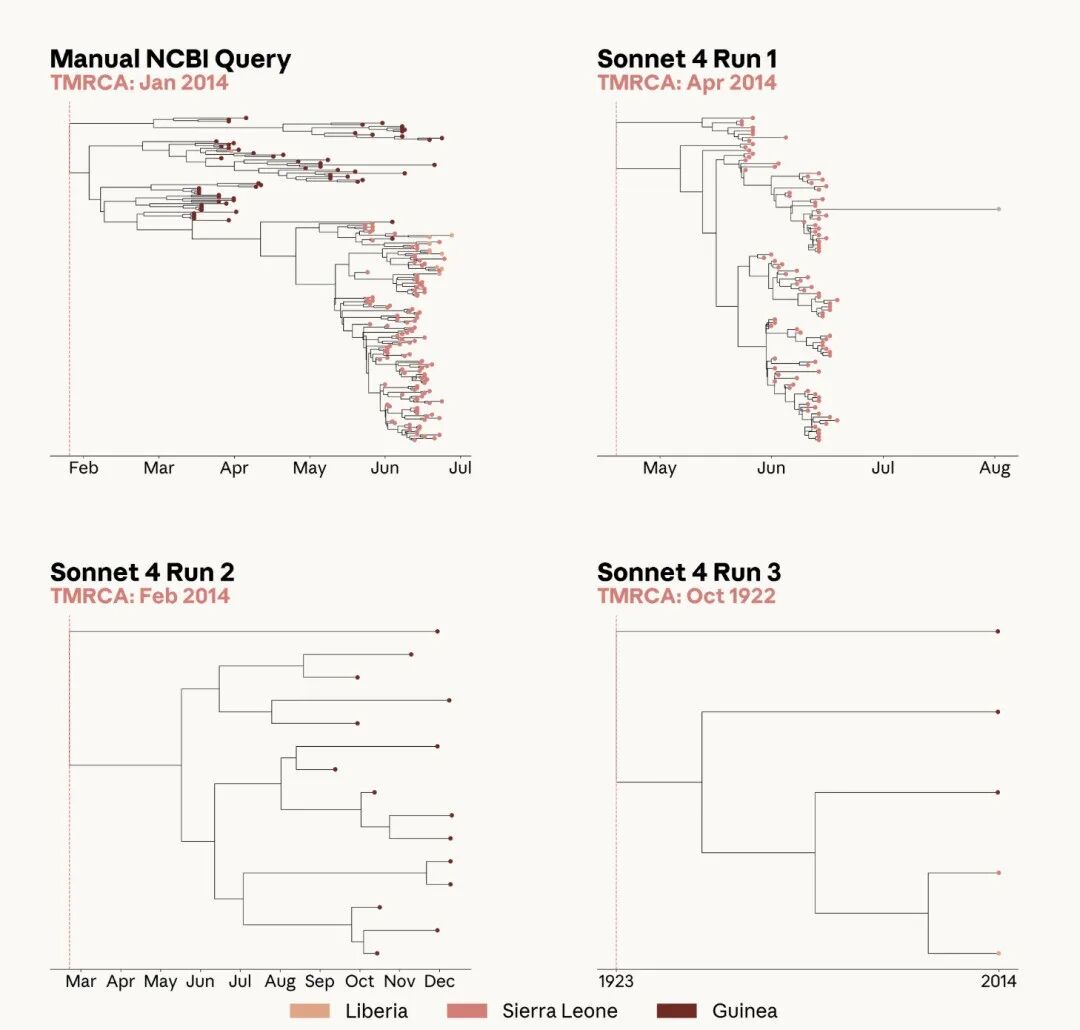
而Sonnet 4三次取回的序列集里,有两次构建出来的系统发育树明显残缺。其中一次算出来的TMRCA竟然是1922年。剩下的数据集表面看起来没什么问题,但缺失了来自几内亚的序列,导致TMRCA被推后到2014年4月,疫情推算的起始时间因此发生偏移。
在治疗方案分析上,类似问题同样存在。团队还检索了埃博拉病毒糖蛋白序列,用来分析maftivimab和MBP134这两种抗体药物(均为世卫组织优先推荐的扎伊尔埃博拉病毒治疗候选药物)的靶点表位在相关序列中是否出现过突变。这类分析帮助研究人员判断:随着病毒演化,现有疗法是否还能保护患者?
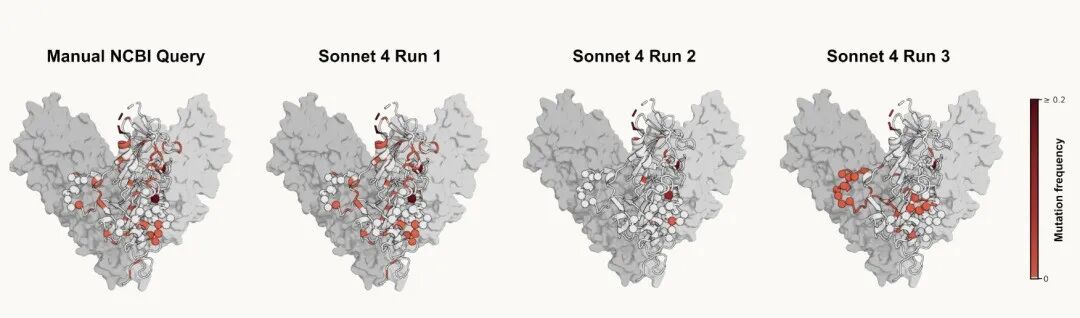
Sonnet 4的第一次运行接近了人工检索的结果,但第二次遗漏了大多数突变位点,第三次又突出显示了一组不同的位点——三次运行,三种不同的结论。
两组分析都指向同一个根本原因:不是模型不聪明,而是它们缺少一个可靠的、确定性的方式来访问数据库,也无法验证结果并保证可复现。答案看起来合理,实际上可能是错的,而且每次都不一样。这对科学工作流而言尤其危险,因为序列检索通常是一条长长下游分析链条的起点。
失误的模式也很清晰:大型数据集(流感A、HIV-1、SARS-CoV-2等序列数量多的病毒)更容易出问题,因为翻页取数据时停在了半途,或者在本地过滤时用错了条件;元数据字段含义依赖上下文和领域惯例时,Agent也容易出错;同时叠加三四个以上过滤条件,准确率就明显下滑。
加一层确定性工具,准确率直奔100%
解法是什么?Anthropic团队和NCBI的研究人员合作,开发了一个叫gget virus的开源工具。
gget virus的核心逻辑是:把NCBI Virus网页界面上那套复杂的检索行为,翻译成一个准确、可复现的程序接口。
这件事做起来比想象中难。NCBI Virus是架在多个底层资源上的入口,这些资源由美国、欧洲、日本协同维护的国际序列数据库组成。一个看似简单的查询,往往需要从好几个地方拼凑信息。
因此,gget virus需要协调REST、Datasets和E-utilities三套API,判断哪些过滤条件可以直接通过这些API施加,哪些必须在本地处理(因为网页界面暴露的某些过滤行为在任何单一程序接口上都找不到对应)。它还要处理分批次拉取大型结果集的问题,确保数据量庞大的病毒序列能被完整取回而不是任意截断。当某项过滤条件依赖存储在独立数据库中的额外信息时,gget virus会先取回那些记录,用它们完成过滤,并在最终输出中保留相关的GenBank信息。最后,它返回人机均可读的标准化输出,并附上详细日志,记录最终结果是如何产生的。
给Agent接上gget virus之后,所有模型的准确率都飙升至90%以上,其中GPT-5.5达到了99.7%。同一个问题多次运行的结果差异基本消失,各模型之间的性能差距也大幅收窄。
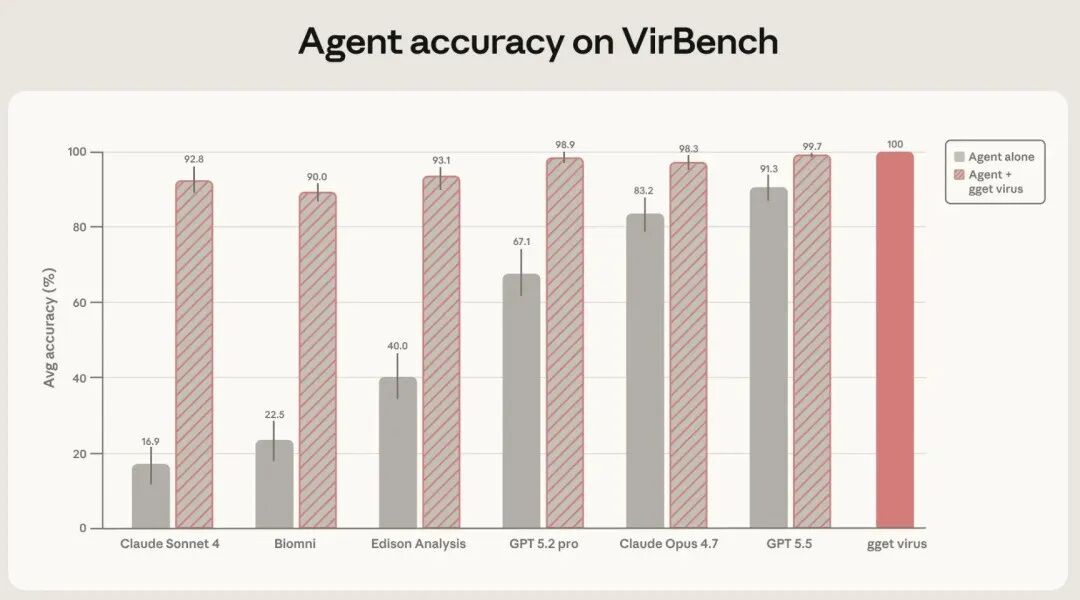
这最后一点值得多说两句。加了确定性检索层之后,选哪个模型变得不那么重要了。这意味着,可靠的数据集构建不应该依赖于你能否拿到最新最贵的模型,也不该依赖于你对哪个模型最擅长处理哪个数据库有多深的了解。反而,更便宜的模型配上合适的工具,就能既降低结果波动,又让更多人用得起。
更大的问题:基础设施要为Agent而建
gget virus是一个具体的解决方案,但它指向了一个更普遍的问题。
Anthropic的判断是:生物Agent的瓶颈,不只是模型的推理能力,而是缺乏覆盖面广的、确定性的生物数据执行层。科学家能清楚地表达自己的意图——比如“找出所有含有某个结构域的人类激酶并提取它们的结构”——但Agent往往缺少一个可靠的途径去访问存放这些信息的数据库。
这也不是生物领域独有的问题。凡是把Agent插入一个为人类设计的环境里,都会遇到类似的摩擦。目前已有一些工作在尝试推进,包括ToolUniverse、Edison Scientific的Robin、Biomni以及相关的生物医学Agent系统,它们通常依赖模型适配层,把Agent和生物数据源连接起来。
但有个更长远的问题值得想清楚:如果把模型的能力曲线往前外推,很容易想象这样一个未来——Agent变得足够强,能自己搞定混乱的数据库门户,能自己对齐标识符,能自己处理分页,能自己从错误中恢复。到那时,gget virus这类工具或许就不再必要了。
然而,即便Agent最终能做到,也不意味着每一次任务都应该让Agent临时发挥、每次都重新摸索一遍。能够硬闯一个混乱生物信息学工作流的模型,对于日常科学任务来说,仍然可能太贵、太慢、太难审计、太难信任。就算Agent将来让今天的适配层变得多余,对生物数据库的设计者而言,这个教训依然成立:在考虑用户的时候,要把Agent纳入视野,要为规模化使用而建。
现在,用Agent做生物研究,模型推理不是最大的障碍。基础设施才是。
参考:https://www.anthropic.com/research/agents-in-biology
 发表于 2026-6-9 21:01:11
|
查看: 143|
回复: 0
发表于 2026-6-9 21:01:11
|
查看: 143|
回复: 0
