当大模型被用于软件开发、数据分析、调试、研究写作这类长周期任务时,一个老问题会反复出现:对话还在继续,但上下文窗口已经不够用了。
论文《TokenMizer: Graph-Structured Session Memory for Long-Horizon LLM Context Management》正是围绕这个问题展开。作者提出的 TokenMizer 不是简单地扩大上下文,也不是把历史对话粗暴总结成一段文字,而是把整个会话历史建模成一张“带类型、带状态、带关系”的知识图谱,再把这张图压缩成很短的恢复块,用来帮助模型在长任务中继续保持上下文连续性。
01|问题的核心:长会话不是“文本太长”,而是“结构丢了”
在长周期任务中,真正重要的信息往往不是最近几句话,而是早期已经确定下来的约束。
例如:
· 第 3 轮做出的技术选型,会影响第 12 轮的实现方式
· 第 7 轮解决过的错误,会影响第 15 轮的测试策略
· 第 4 轮修改过的文件,可能还要在第 18 轮继续保持一致
作者指出,长会话会逐渐形成一套内部结构:任务状态、技术决策、文件变更、错误修复、环境配置等信息彼此关联。如果只是把历史记录当作一长串文本处理,那么这些结构很容易在截断、摘要或检索过程中被破坏。
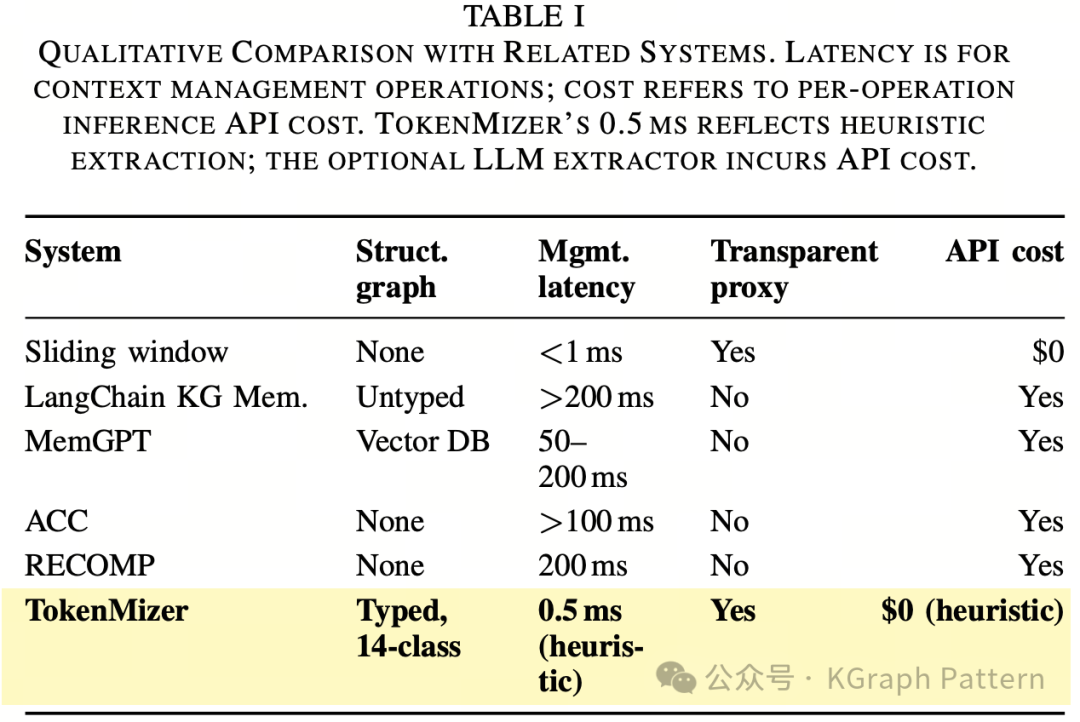
现有方法主要有三类:
① 截断历史
保留最近内容,丢掉最早内容。可问题是,早期内容往往包含项目目标、架构决策和初始技术选型。
② 生成摘要
摘要能压缩内容,但自然语言摘要很难稳定区分“任务已完成”还是“任务待处理”,也很难精确保留“为什么选择某个方案”。
③ 检索增强
向量检索可以按相似度找片段,但某些关键上下文可能和当前问题语义距离很远,因此不一定能被召回。
一句话概括:
TokenMizer 要解决的不是“如何塞进更多文本”,而是“如何保留长会话真正有用的结构”。
02|作者的关键判断:会话历史本质上是一种“结构化知识资产”
TokenMizer 的核心洞察很明确:LLM 会话历史不是平面文本,而是一种结构化知识资产。
作者将长会话中的关键信息拆成几类:
· TASK:任务及其状态
例如 pending、in-progress、completed、failed。
· DECISION:决策及其理由
例如为什么选择 Redis、bcrypt、JWT 或 PostgreSQL。
· FILE:文件及其修改历史
例如哪些源码文件、测试文件、配置文件被创建或修改。
· ERROR / FIX:错误与修复关系
例如某个报错由哪个改动解决。
· ENVIRONMENT:环境事实
例如 Python 版本、运行时、框架、基础设施配置。
这些实体之间并不是孤立存在的。它们通过关系连接起来,例如 IMPLEMENTS、FIXES、DEPENDS_ON、BLOCKS 等。作者认为,只有保留这些类型和关系,系统才能真正理解“这段会话已经走到哪里了”。
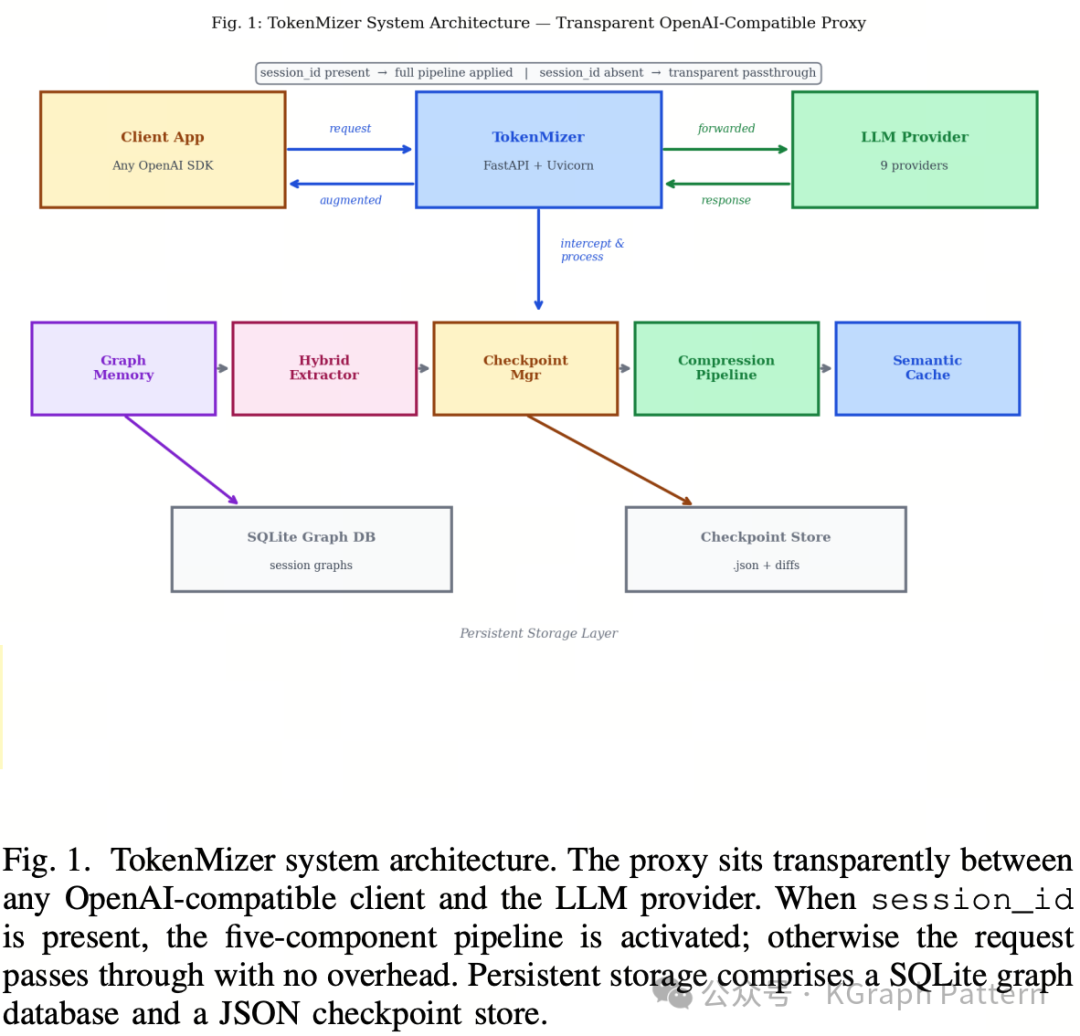
03|系统设计:TokenMizer 是一层透明代理,不要求大改应用
TokenMizer 的部署方式比较轻量。它作为一个 HTTP 反向代理,兼容 OpenAI Chat Completions API。应用端只需要把 base_url 指向 TokenMizer 服务,不需要重写业务逻辑。
当请求中带有 session_id 时,TokenMizer 就会启动完整的上下文管理流程;如果没有 session_id,请求会直接透传,不增加额外处理。系统内部由五个主要组件组成:
· Graph Memory:图记忆模块
负责保存会话中的结构化节点和关系。
· Hybrid Extractor:混合提取器
负责从对话中提取任务、决策、文件、错误等信息。
· Checkpoint Manager:检查点管理器
负责在上下文接近上限时生成恢复块。
· Compression Engine:压缩引擎
负责在内容进入上下文前进行多层压缩。
· Semantic Cache:语义缓存
负责复用语义相近问题的响应,减少重复请求。
作者还实现了多模型供应商适配,并使用 SQLite 存储图数据库,用 JSON 存储检查点。
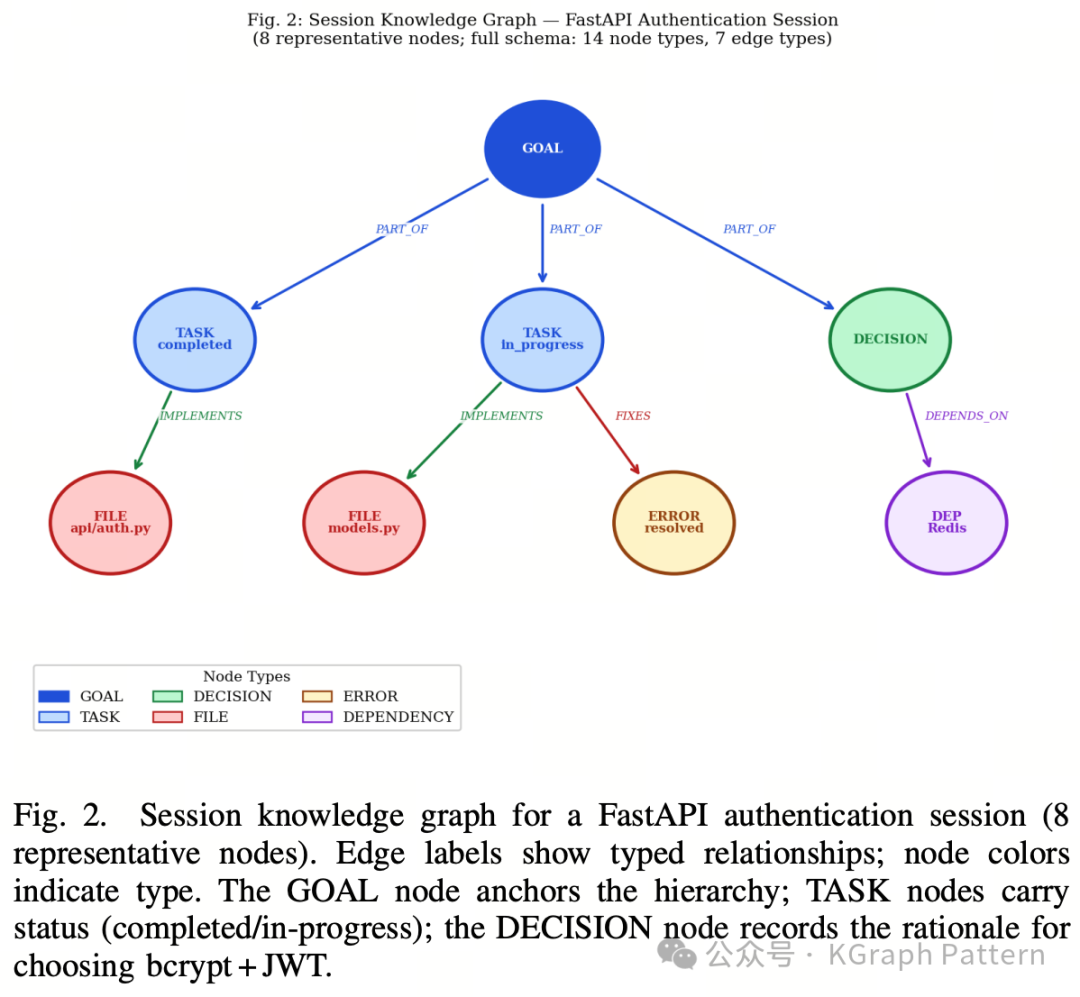
04|知识图谱怎么建:14类节点,7类边,还有状态生命周期
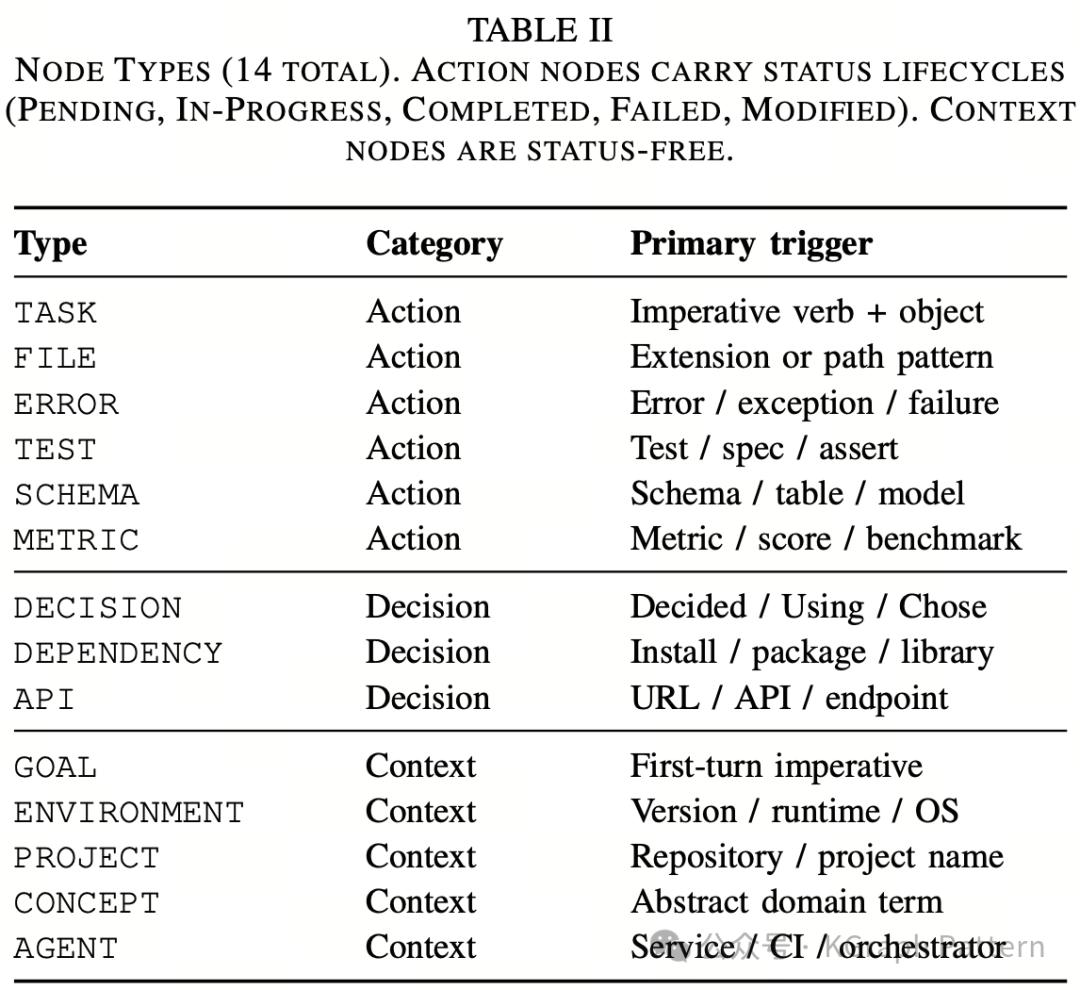
TokenMizer 的知识图谱 schema 是论文中最关键的设计之一。作者定义了 14 种节点类型,大致可以分为三组:
第一组:动作类节点
包括 TASK、FILE、ERROR、TEST、SCHEMA、METRIC。
这类节点通常带有状态生命周期,例如 pending、in-progress、completed、failed、modified。
第二组:决策类节点
包括 DECISION、DEPENDENCY、API。
这类节点用于记录技术选择、依赖库、接口和服务端点。
第三组:上下文类节点
包括 GOAL、ENVIRONMENT、PROJECT、CONCEPT、AGENT。
这类节点用于描述项目目标、运行环境、项目名称、抽象概念和服务组件。
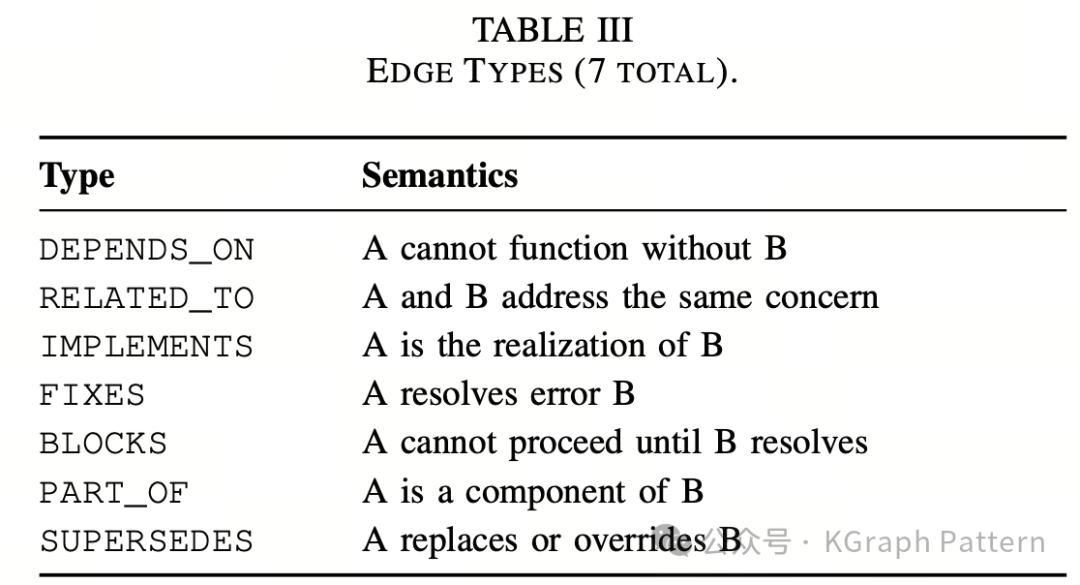
同时,图中的边也有明确语义。论文定义了 7 种边类型:
· DEPENDS_ON:A 依赖 B
· RELATED_TO:A 和 B 处理同一类问题
· IMPLEMENTS:A 实现 B
· FIXES:A 修复 B
· BLOCKS:A 阻塞 B
· PART_OF:A 是 B 的组成部分
· SUPERSEDES:A 替代 B
这种设计让系统不只是知道“Redis 被提到过”,而是能够知道“Redis 是某个 DECISION 节点中的技术选择,并且可能和某个任务、文件或环境事实相关”。
05|从会话到恢复块:提取、校验、检查点三步走
TokenMizer 并不是等到上下文爆掉之后才处理,而是在会话过程中持续提取结构化信息。
论文中的 V1 提取器主要依赖规则表达式,共使用 34 个编译正则,覆盖任务、决策、文件、错误、环境和端点等信息。这个版本的特点是速度非常快,平均提取延迟约为 0.5 ms,且不需要额外推理成本。
随后,作者在 V2 中针对四类问题做了改进:
① 扩展触发词
增加 Fixed、Deployed、Resolved、Migrated、Running、Launched、Shipped、Finished、Updated 等常见表达。
② 引入模糊标签匹配
解决“提取标签很长,但人工标注很短”的问题。例如系统提取到详细错误描述,而标注只写了“iOS crash fix”。
③ 拆分复合任务句
例如 “Completed: API auth, tests, deployment” 不应只生成一个任务,而应拆成多个任务节点。
④ 拆分 CSV 风格决策
例如 “Decided: Prometheus, Grafana, Jaeger” 应该生成多个决策节点,而不是一个混合节点。
为了避免错误节点进入图中,作者还设计了 GraphValidator。每个候选节点都会被打置信分,低于阈值的节点会被拒绝;文件路径、版本号、标签长度等都会影响评分。
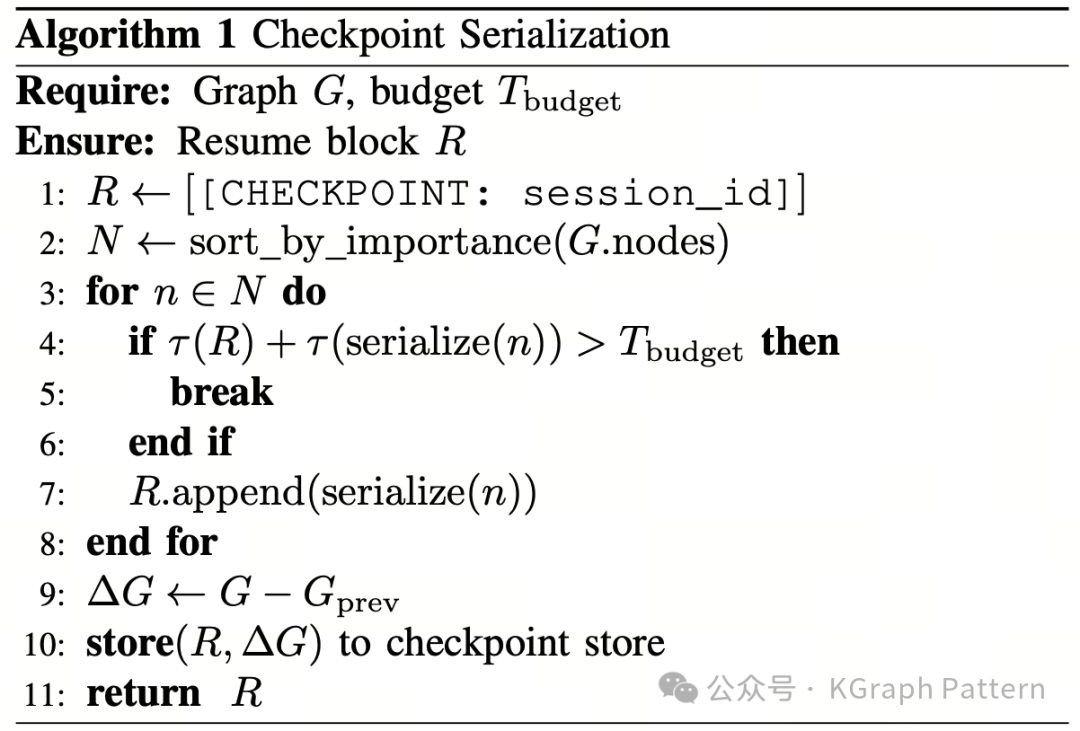
当累计 token 数达到配置 MECW 的 85% 时,TokenMizer 会触发检查点。检查点不是保存完整对话,而是把图中最重要的节点序列化成一个紧凑的 resume block。论文中定义了三档恢复块:
| 层级 |
内容 |
token 预算 |
| Critical |
GOAL、进行中的 TASK、最重要 DECISION |
≤100 |
| Standard |
所有 TASK、DECISION、FILE、ENV |
≤300 |
| Full |
完整图,包括 DEPENDENCY、SCHEMA |
≤600 |

06|压缩与缓存:不是单纯省 token,而是降低长会话成本
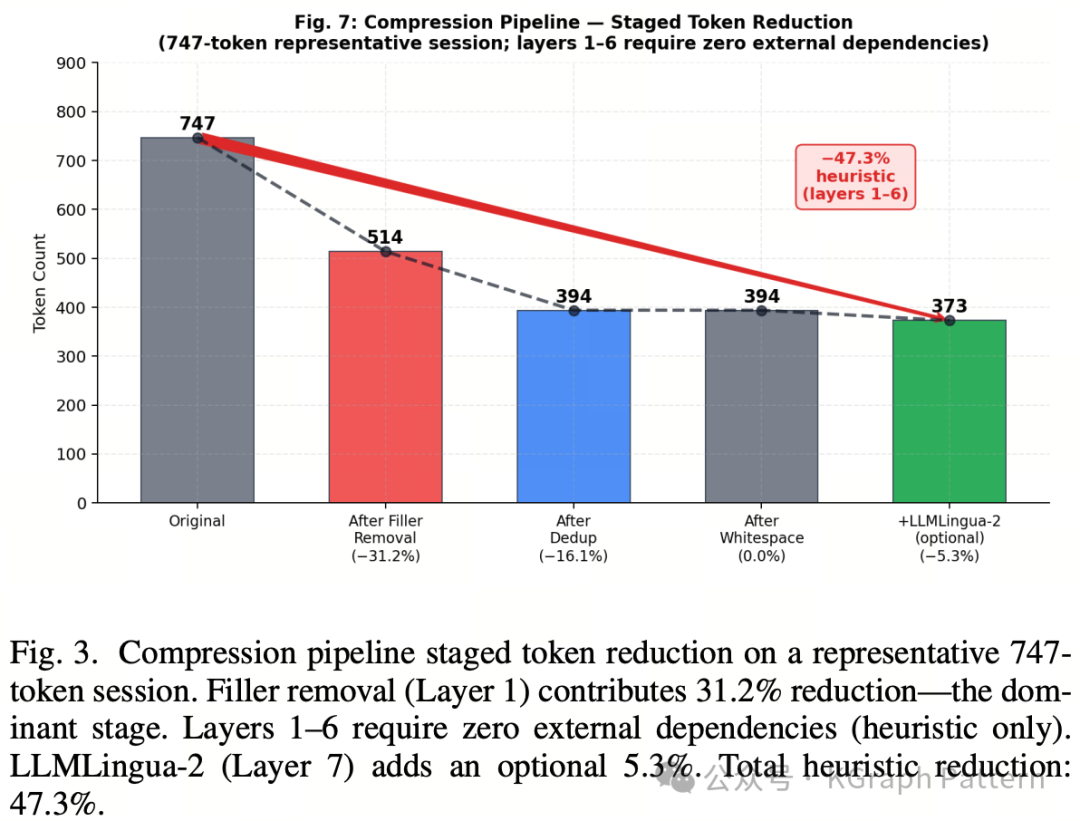
TokenMizer 还设计了一条 8 层压缩流水线,用于处理长文件、长 API 响应和历史消息。
其中最重要的是前两层:
第一层:去除填充语
包括 “Certainly”、“I’d be happy to”、“As an AI language model” 等对任务结构没有帮助的表达。在代表性样本中,这一层带来 31.2% 的 token 减少。
第二层:去重
删除重复代码块、日志行、错误信息等,在样本中进一步减少 16.1%。
后续几层包括空白归一化、注释剥离、历史消息裁剪、文件类型智能截断等。可选的神经压缩层使用 LLMLingua-2 和 LongLLMLingua,但论文中的主要结果强调:仅靠启发式压缩,TokenMizer 已经达到 47.3% 的 token 减少,而且不需要额外推理调用。
TokenMizer 还实现了语义缓存。系统使用 sentence-transformer embedding 作为键,对新查询和缓存查询计算余弦相似度;当相似度超过 0.92 时视为命中。论文报告了一个小规模受控测试:10 个查询中命中率为 70%,但作者也明确指出,这只是概念验证,不应直接理解成生产环境命中率。
07|实验设置:21个合成会话,覆盖5类长任务场景
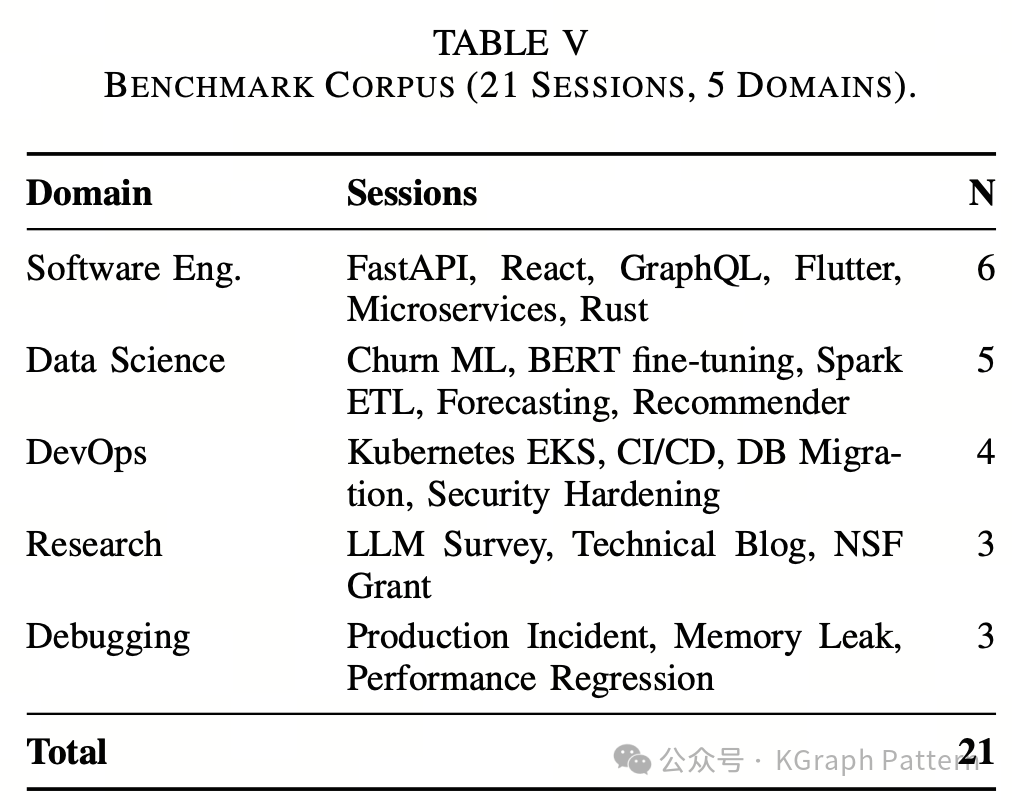
论文的实验基于一个受控 benchmark,共包含 21 个会话,覆盖 5 个应用领域:
| 领域 |
会话数量 |
示例方向 |
| 软件工程 |
6 |
FastAPI、React、GraphQL、Flutter、微服务、Rust |
| 数据科学 |
5 |
用户流失预测、BERT 微调、Spark ETL、时间序列、推荐系统 |
| DevOps |
4 |
Kubernetes、CI/CD、数据库迁移、安全加固 |
| 研究写作 |
3 |
LLM Survey、技术博客、NSF Grant |
| 调试 |
3 |
生产事故、内存泄漏、性能回归 |
作者为每个会话标注了完成任务、待处理任务、技术决策和文件变更,并使用任务召回率、决策召回率、文件召回率、信息损失、恢复块 token 数、压缩比、token 效率和提取延迟作为评估指标。
不过,作者也没有回避实验边界:这些会话是人工构造的合成数据,而不是来自真实开发者的现场会话;标注也由作者本人完成,因此结果更适合作为受控概念验证,而不是生产环境性能估计。
08|结果:平均78个token,比基线少一半,还更会保留“决策”
实验结果里,最值得关注的不是单一召回率,而是 TokenMizer 在“结构保留”和“token 开销”之间取得的平衡。
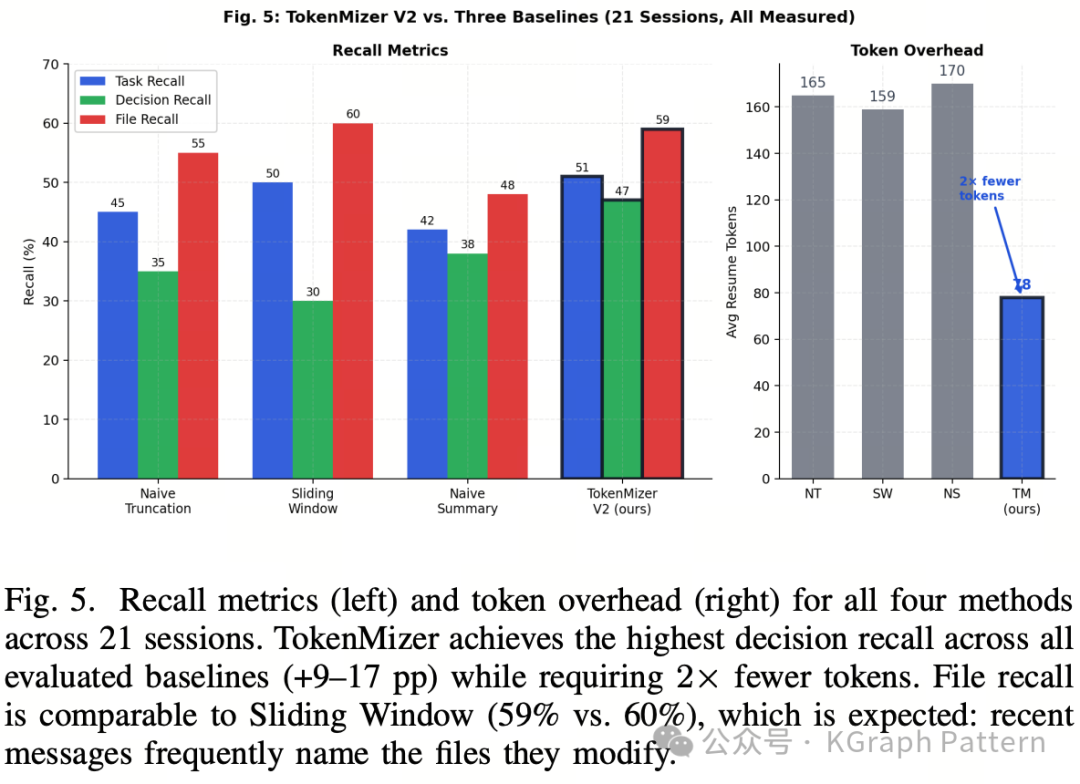
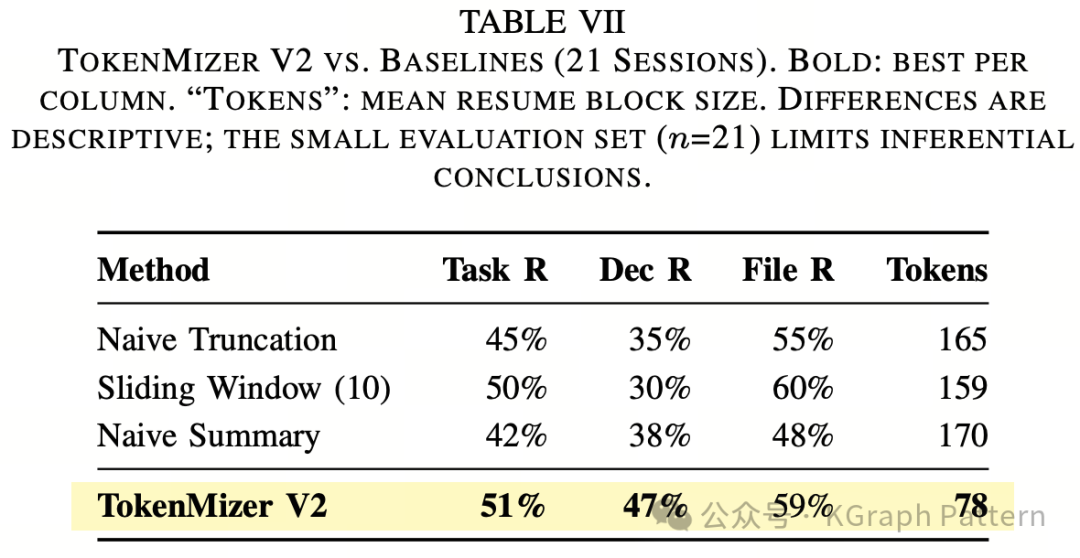
在 21 个会话上,TokenMizer V2 的整体结果为:
· 任务召回率:51%
· 决策召回率:47%
· 文件召回率:59%
· 平均恢复块长度:78 tokens
与三个文本保留基线相比,TokenMizer 的优势主要体现在决策召回和 token 开销上。论文中的对比结果如下:
| 方法 |
任务召回 |
决策召回 |
文件召回 |
平均 tokens |
| Naive Truncation |
45% |
35% |
55% |
165 |
| Sliding Window |
50% |
30% |
60% |
159 |
| Naive Summary |
42% |
38% |
48% |
170 |
| TokenMizer V2 |
51% |
47% |
59% |
78 |
TokenMizer 的决策召回率比所有基线高 9–17 个百分点,同时恢复块平均只有 78 tokens,约为基线的一半。作者强调,基线即使保留了某些关键词,也无法结构化表达“为什么选择了某项技术”;而 TokenMizer 的 DECISION 节点可以直接承载技术选择和理由。
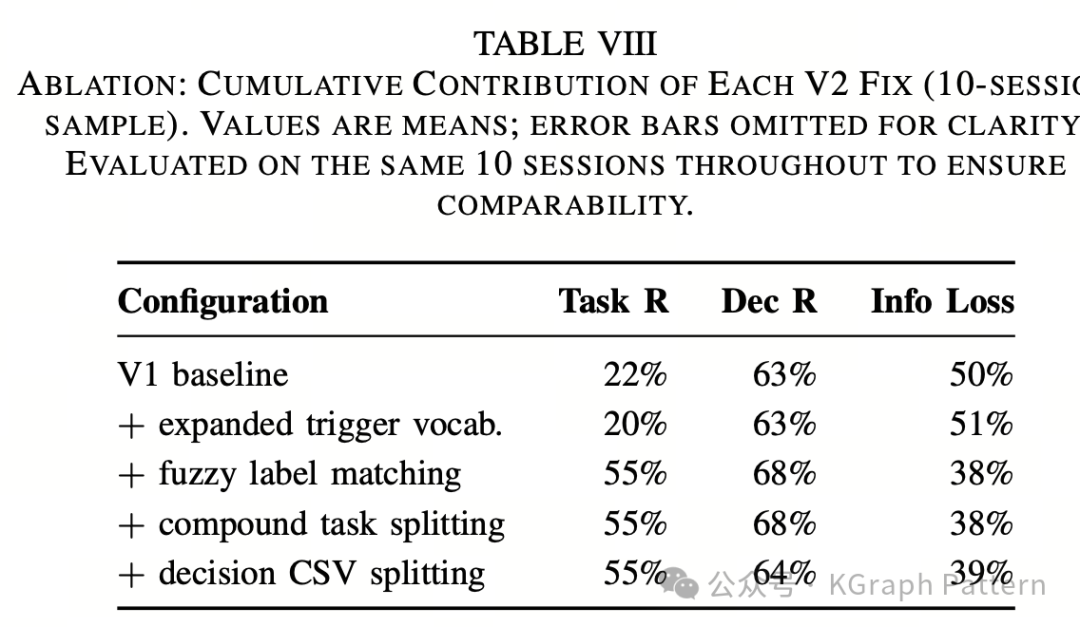
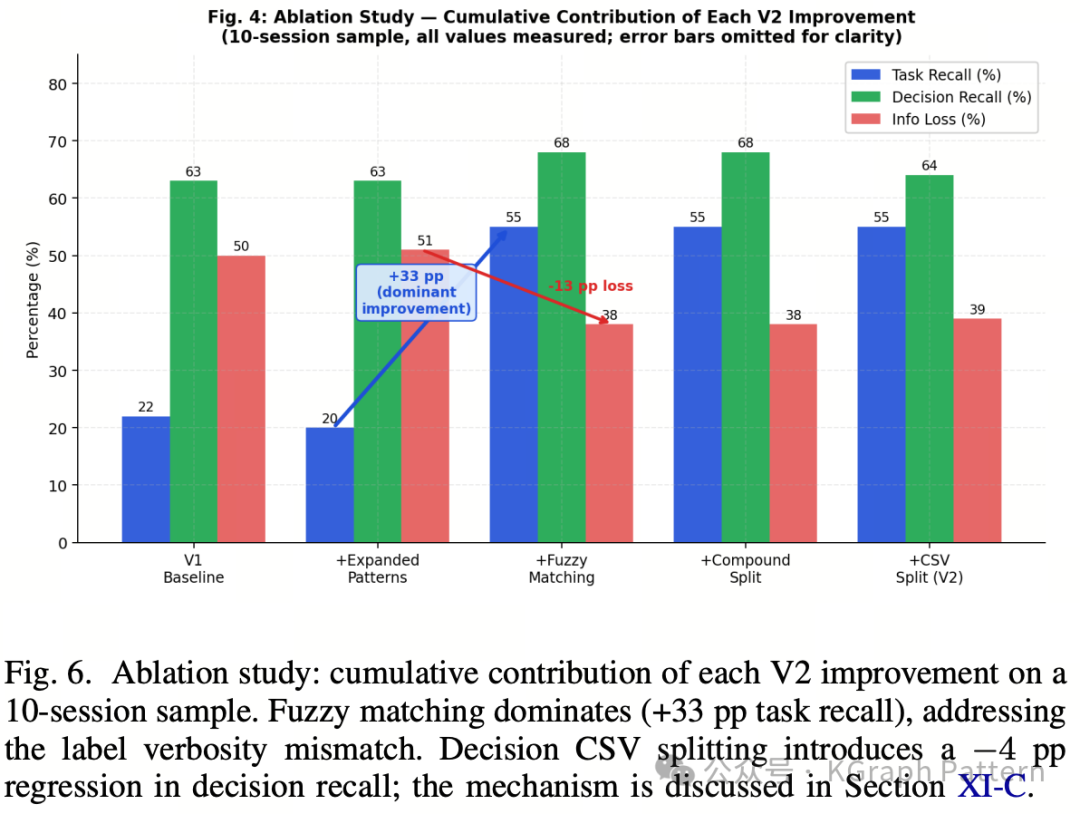
进一步的消融实验显示,V2 改进中贡献最大的不是扩展触发词,而是 模糊标签匹配。它让任务召回率提升了 33 个百分点,说明系统最主要的瓶颈并不是“有没有提取到”,而是“提取出来的标签能不能和人工标注正确对齐”。
09|边界与启示:TokenMizer 最适合“结构清晰”的长任务
TokenMizer 的优点很清楚:它把长会话中的任务、决策、文件和环境事实变成可查询、可压缩、可恢复的结构化状态。对于软件工程、数据科学、调试这类任务,它尤其有价值,因为这些场景通常包含明确的动作、文件名、错误信息和技术选择。
但论文也给出了比较明确的限制:
· benchmark 是合成数据,不是真实生产会话
· 标注由单人完成,缺少多标注者一致性验证
· 启发式提取对隐含表达不够敏感
· 决策召回仍有明显上限
· 当前图边连接方式偏浅,主要依赖词汇重叠
· 目前每张图只服务于单个会话,还没有实现跨会话记忆
尤其是在研究写作、规划讨论、学术表达这类场景中,很多信息并不会以“Completed”“Decided”“Fixed”这类显式触发词出现,因此启发式方法容易漏掉关键信息。作者也把 LLM extractor 作为未来最重要的升级方向之一,用于捕捉更隐式、更自然的表达。
最终来看,TokenMizer 的价值不只是节省 token。
它真正提出的是一种新的上下文管理思路:
长会话不是一堆需要压缩的文本,而是一张需要维护的状态图。
这也是这篇论文最值得关注的地方。它没有把“更长上下文”当作唯一答案,而是尝试把上下文变得更结构化、更可恢复、更便宜。对于未来的代码助手、研究助手、数据分析 Agent 和长期运行的 LLM 工作流来说,这种设计思路很可能比单纯扩大窗口更重要。
更多详细内容可以参考论文原文。
 发表于 2026-6-11 00:05:13
|
查看: 107|
回复: 0
发表于 2026-6-11 00:05:13
|
查看: 107|
回复: 0
