我一看到这类工具,通常不去看宣传词,而是直接敲命令。
uvx whichllm@latest
就这一行,我停了一下。因为本地跑 LLM 最让人头疼的地方,真不是“能不能装上”,而是你明明有块显卡,却不知道该下载哪个 GGUF、量化该选 Q4 还是 Q5、上下文一长会不会立刻撑爆显存。whichllm 做的事很朴实,但非常实在:自动检测 GPU、CPU、内存,然后从 HuggingFace 里筛选出你机器能跑起来的模型,并给你排个名。
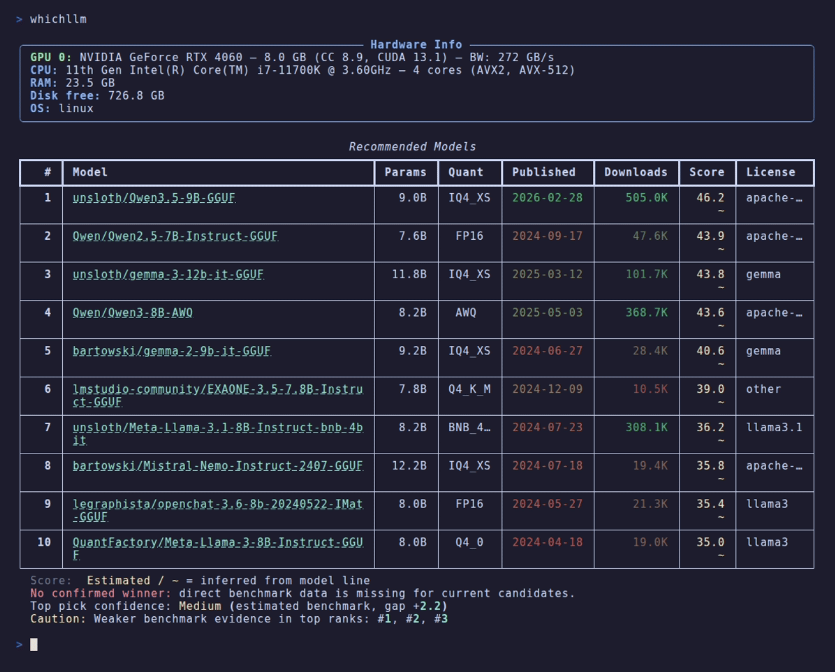
不过它的真正亮点,绝不仅仅是“帮你找一个刚好塞进显存的最大模型”。
它会将真实评测分数、推理速度、量化损耗、模型新旧程度以及证据可信度,一起纳入计算。README 里也特意说明了,分数并不单纯看参数量;那些可信度低、来源是搬运仓库、自报 benchmark 的数据会被打折。啧,这点尤为关键。开源模型圈里最不缺的,就是那些“看起来很美”的模型名,等你真跑起来时,倒未必会报错,但你的电脑风扇会先开始替你骂人。
还有一个买卡前极其好用的玩法:
whichllm --gpu "RTX 4090"
假装你已经有某块显卡,先看看它究竟能推荐哪些模型。反过来也行,用 whichllm plan "llama 3 70b",让工具告诉你跑这个模型大概需要什么硬件配置。以前做本地 Demo,最怕的就是模型几十 GB 下完,结果跑起来像幻灯片,删除也不是,留着也不是。
但先别急着叫好。
README 也写得相当清楚:它给出的速度是规划范围,不是你机器上的实测 benchmark。驱动、后端、散热、内存带宽这些脏活累活,最后还是会找上你。所以,whichllm 更像是一个“帮你少踩第一批坑”的工具,并不是性能玄学的终结者。
选好模型之后,你可以直接用 whichllm run 下载并开始对话,或者用 whichllm snippet 生成一段可复制的 Python 代码。这对新手很友好,对老手也省心——至少不用再在 repo_id、filename、n_gpu_layers 这类小坑里反复翻文档。
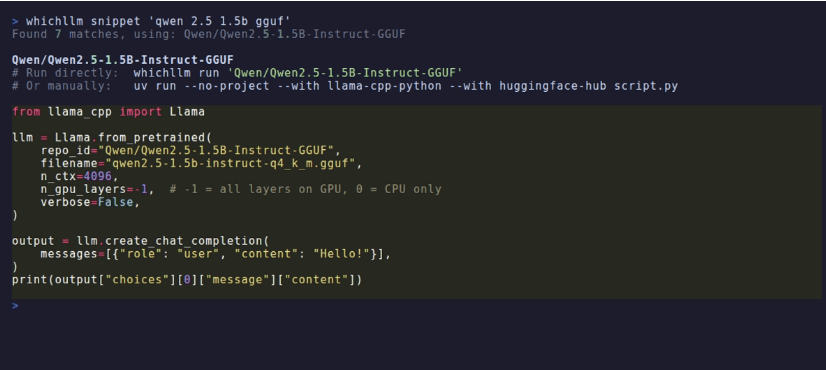
我会把它用在两个常见场景里:一是新机器到手,先扫一眼到底能跑哪些模型;二是买显卡之前,别光盯着跑分,先用它模拟一份本地模型清单。
GitHub 地址:https://github.com/Andyyyy64/whichllm
更多实用工具分享,欢迎来 云栈社区 一起交流。 |  发表于 前天 23:07
|
查看: 20|
回复: 0
发表于 前天 23:07
|
查看: 20|
回复: 0
