闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
Fable 5并非高不可攀。
DeepSeek、Kimi与Gemini三款模型强强联手,足以与其正面抗衡。
OpenRouter日前进行了一项引人注目的实验——让不同大型语言模型组队协作,结果颇有看点。
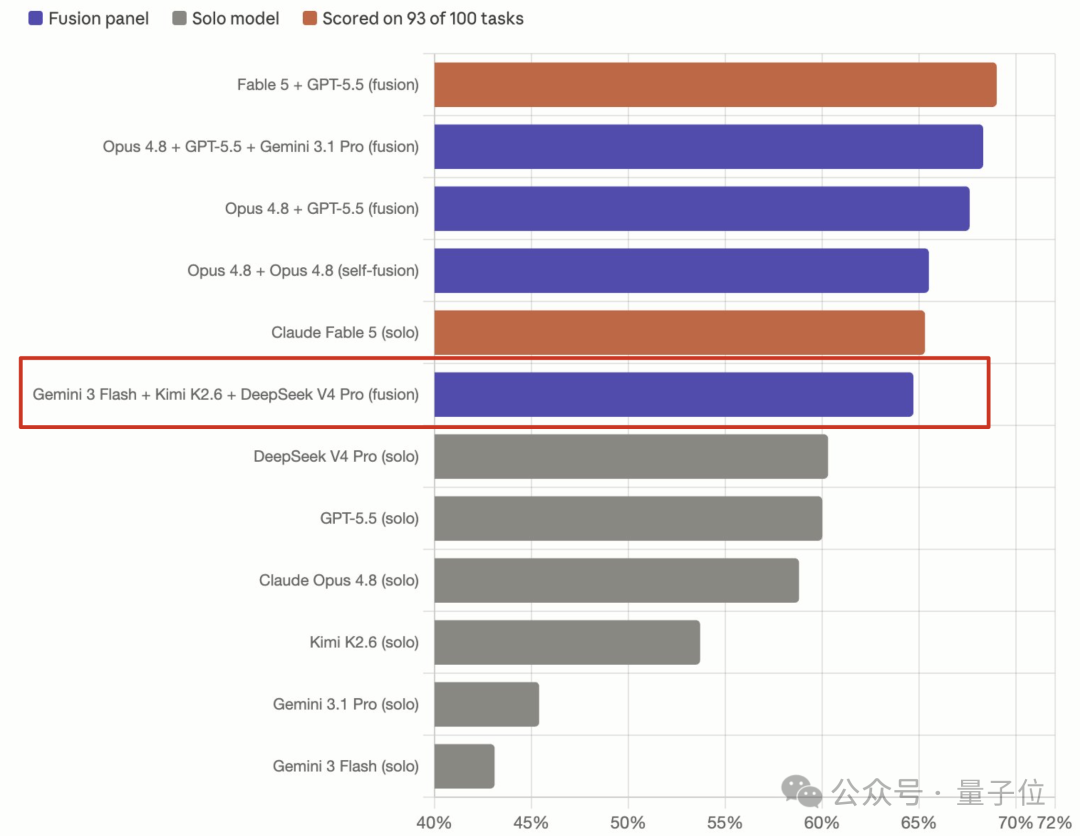
最新测试结果表明,模型抱团之后实力显著攀升:
Opus 4.8 + GPT-5.5 > Fable 5;
Kimi K2.6 + DeepSeek V4 Pro + Gemini 3 Flash ≈ Fable 5。
不仅性能追平,开销还直接减半。
根据官方定价,相较于Fable 5,Kimi K2.6、DeepSeek V4 Pro与Gemini 3 Flash这套平价组合,理论成本降幅接近80%。在本轮测试中,即使计入平台调度与内容融合等附加开销,该组合的单任务花费依然仅为Fable 5的50%——性价比不言而喻。

多个模型组成评审团,完胜单打独斗
此次测试的核心,是OpenRouter的 Fusion多模型融合方案。
当用户向Fusion发送指令后,系统会将任务并行分发给多个模型,所有模型均支持网页检索与内容抓取。随后,判定模型逐一分析各家的回复,梳理出共识观点、矛盾之处、信息缺口、独到见解与认知盲区,并基于这份交叉分析生成最终答案。整套流程在服务端完成,调用体验与使用单模型几乎别无二致。
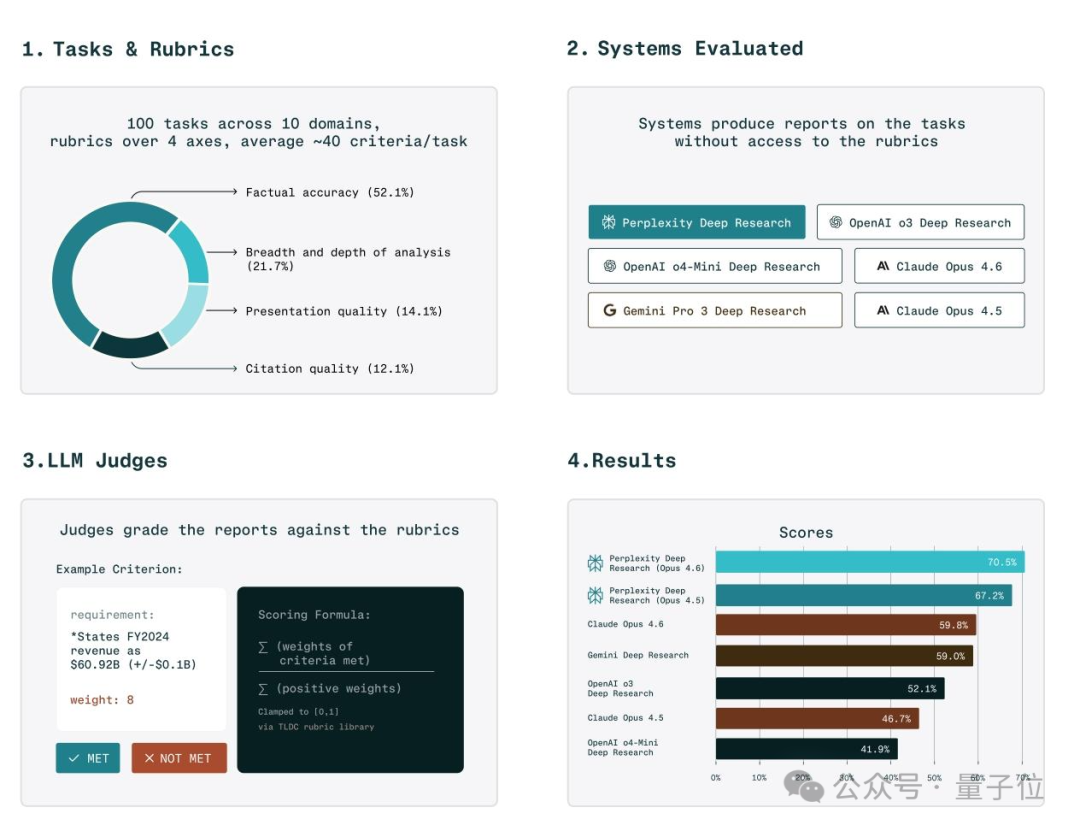
为检验模型们的综合实力,团队选用了 DRACO深度研究基准测试集。这套题库由Perplexity AI精心打造,专门衡量模型处理复杂任务的真实水平。
100道实战题目覆盖学术、金融、法律、医疗、技术等十大领域,高度还原职场办公与专业调研中的实战场景。评分规则尤为严格,共设39项加权标准,从事实准确性、分析深度与广度、排版呈现质量、引用规范性四大维度进行综合评判。
最特别的是,它还加入了一套扣分机制:一旦回答出错、给出不当建议或通篇废话,都会被直接扣分。模型若想靠堆砌文字来蒙混过关,几乎行不通。
从测试数据来看,多模型协同的整体表现明显优于单一模型。
多款高端模型组合后均有显著提升。例如Fable 5与GPT-5.5搭档,以69.0%的最高成绩夺魁,轻松超越两模型单独参赛的分数。Opus 4.8、GPT-5.5、Gemini 3.1等高端模型无论两两配对还是三人组队,结果全部优于其各自的单体状态。
不过,本次测试的最大惊喜是:Kimi K2.6、DeepSeek V4 Pro与Gemini 3 Flash这个“草根组合”,几乎追平了Claude Fable 5。

Fable 5(平价替代版)
Claude Fable 5单独运行时,在DRACO测试中的标准化得分为65.3%。
(因内容安全过滤,该模型仅完成了100道任务中的93道)
而Kimi K2.6、DeepSeek V4 Pro与Gemini 3 Flash三款模型组成的融合阵容,综合得分达到64.7%。两者分差仅有0.6个百分点,性能几乎持平。在此前提下,成本优势便成了这套组合最锋利的杀手锏。
根据官方公开定价,Claude Fable 5的收费十分高昂:每百万输入token需10美元,每百万输出token更是高达50美元,比上一代Opus 4.8翻了一倍。对于日均调用量较大的企业、工作室和个人开发者而言,长期使用无疑是一笔不小的开支。
而组合中的三款模型,均为典型的高性价比选手:
DeepSeek V4 Pro经过永久降价后,每百万输入token仅需0.44美元,输出为0.87美元;
Gemini 3 Flash主打轻量低成本,每百万输入约0.5美元、输出3美元;
Kimi K2.6采用缓存计费机制,首次处理内容按0.95美元/百万token计费,重复使用同一上下文时,输入成本可降至0.16美元/百万token,输出为4美元/百万token。
三款模型组成融合阵容后,综合调用成本相较Claude Fable 5降幅接近80%。
不过,从本次测试的实际开销来看,不同组合的花费差异明显。表现优于Fable的组合受调用方式影响,整体开销也略高;而三人组即使在计入平台调度与内容融合等附加成本后,单任务总花费依然低于Claude Fable 5,是全场性价比最优的解决方案。
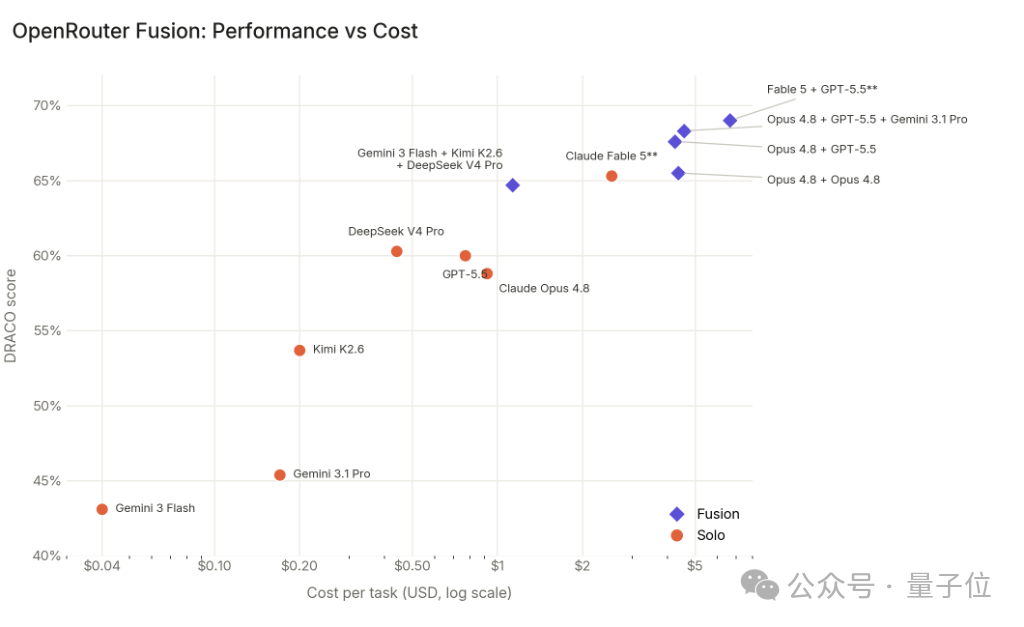
此外,测试中还有一个有趣的现象:即使是单一模型进行“自我融合”,也能实现性能跃升。例如Opus 4.8自身组合后,得分从单体的58.8%提升至65.5%。这从侧面印证了,Fusion方案的增益不仅来自不同模型的能力互补,答案整合与逻辑梳理这一流程本身就足以优化输出质量——同一指令交由同一模型多次运行,会产生不同的推理路径、工具调用逻辑与信息筛选结果,再经过整合优化,最终内容会更加完善。
那么,这套“平替打法”究竟怎么实现?
OpenRouter针对不同使用人群,提供了网页版与API两种方式。在网页端,可直接选择预设组合一键启用,也可按需自由搭配模型。
如果需要自动化调用,只需使用API接口并在参数中指定模型即可。
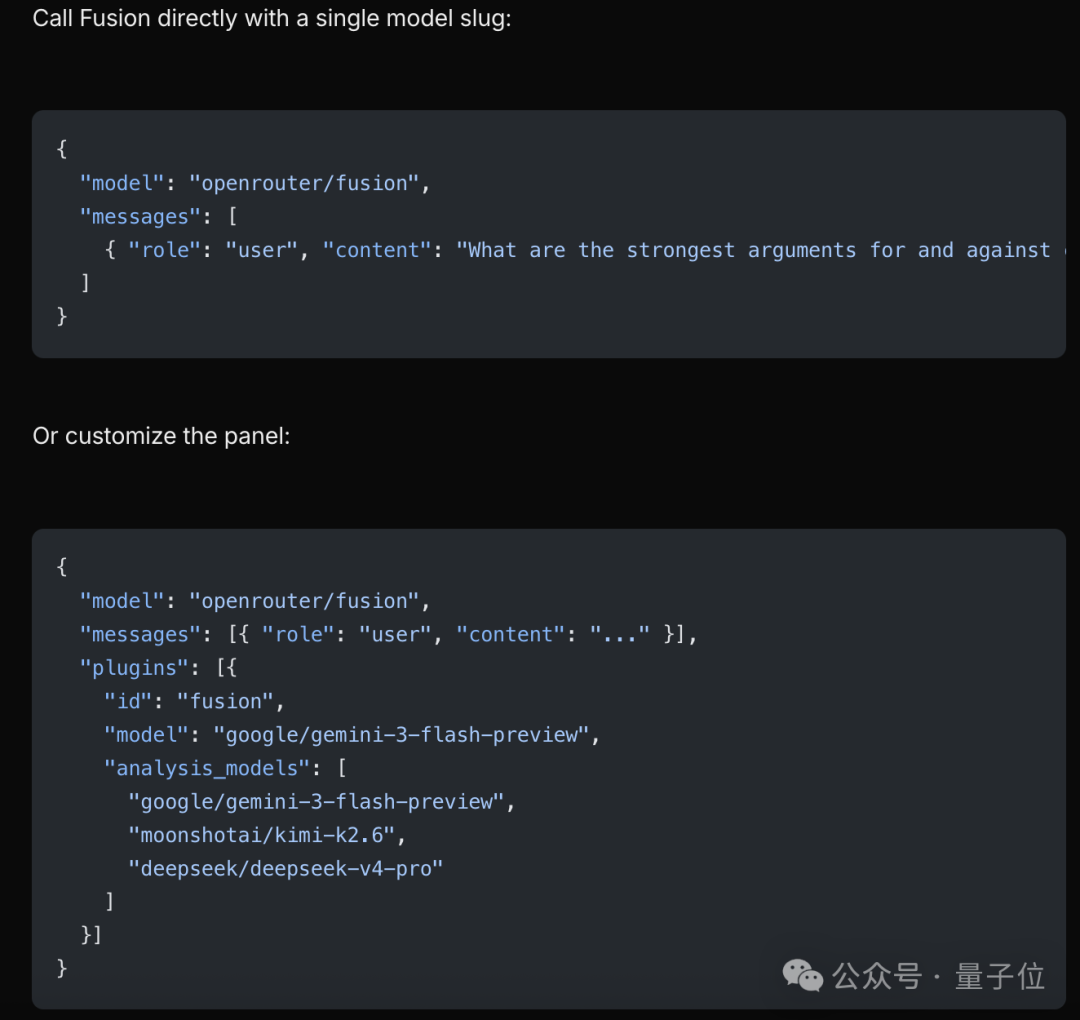
调用Fusion模型,默认只需一行model参数:
{
"model": "openrouter/fusion",
"messages": [
{
"role": "user",
"content": "What are the strongest arguments for and against"
}
]
}
你还可以自定义参与分析的专家模型列表,以匹配特定任务风格:
{
"model": "openrouter/fusion",
"messages": [
{
"role": "user",
"content": "..."
}
],
"plugins": [
{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshtai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}
]
}
感兴趣的朋友不妨亲自上手一试,毕竟用多模型智能组队来平替旗舰方案,确实让人直呼“真香”。
参考链接:
[1] https://openrouter.ai/blog/announcements/fusion-beats-frontier/
[2] https://x.com/OpenRouter/status/2065856860435988482
对于热衷追踪前沿AI应用与性价比方案的开发者而言,这种多模型协作的范式无疑开启了一条全新的优化路径。如果你想深入探索这类工程化技巧,或是获取更多实测数据,不妨到云栈社区与众多同道中人一起交流挖潜。
 发表于 2026-6-14 23:18:23
|
查看: 289|
回复: 0
发表于 2026-6-14 23:18:23
|
查看: 289|
回复: 0
