本人从事AI逆向与AI开发已有两年左右时间(目前主要在做Agent开发),从早期网页版GPT辅助逆向,到Claude 3.5,再到AI爆发时代的GLM 5.1、Claude 4.7等模型都一路用过来。看到很多人在AI逆向时,思路和手法还比较局限,大多仍然停留在纯粹的流式对话阶段,所以想分享一些新思路。笔者本身是做算法逆向还原的,本文就以此方向来抛砖引玉,聊聊怎样更高效地进行逆向。(本文零AI注水,请放心阅读,仅绘图部分使用了AI)
AI逆向过程中的难点
结合我自己的经验,AI逆向主要存在以下几类问题:
- 传统工作模式仍然以“人肉分析”为主导,AI仅作辅助。这导致大量前期的定位、勘探仍然依赖手工,整体效率不高。我更希望AI能成为主导,人只做关键决策,这样才能并行推进多个任务。
- 上下文管理太弱。AI逆向时经常出现一种情况:经过N轮对话后,我们终于定位或拿到了想要的东西(核心算法点位、风控协议的点位等),但链路上存在不少关联信息需要一并厘清才能完成整个任务;又或者一个对话窗口不够用,经历N次压缩后出现信息丢失,不得不回头重新查阅辅助信息,效率大打折扣。
- AI在逆向时发散性过强。我们下达一个指令后,AI通过思维链和工具调用,很可能已经偏离了正确的分析轨道。逆向本身就经常面临N条路径需要取舍和深挖的情况。一旦AI走上了错误路径,我们就不得不频繁打断、纠正,大量时间还是浪费在盯着它的思维链上,并未真正解放人力。而且打断后由于上下文问题,前面的分析路径很可能就丢失了,如果中途出了意外,重新开一个新会话几乎是从头再来。
- AI并不真正懂得正确的逆向手法。它能识别汇编,却不太清楚汇编如何正确地转换为高级代码。它极有可能采用一种低效的还原逻辑,并且在逆向过程中非常依赖IDA的F5反编译,极易产生错误。尤其在精度要求极高的算法还原场景下,哪怕只是0.2%的偏差,任务就直接失败。这个问题在国产模型中尤为严重,Claude 4.7虽有所改善,但根源仍在。
- 上下文爆掉的问题。AI在读取较大函数或冗长的汇编代码时,常有上下文撑爆的情况。即使有类似“No MCP”这样的工具辅助,受模型自身注意力机制的限制(通常聚焦于前部和末尾),它也很难去关注上万行的汇编代码。
如何解决
这些问题困扰了我相当长时间。结合实践,我总结出了一套方法:
- 构建一套健壮的上下文管理机制,所有AI产物都必须遵循规范进行管理。
- 必须确保方向明确,避免模糊的提示词输入。在基座模型效果尚可的情况下,可以让AI自己去拆解用户意图,进行多轮信息了解,并自主制定方案再去定位分析。
- 引入多Agent隔离机制。好处在于隔离上下文,防止互相污染或爆掉。同时,避免了海量汇编对AI决策的直接污染。也可以同时调度多个模型进行操作,类似GitHub上大火的ohmycode这类项目思路。
- 采用半自动化决策,必须设置“钩子”(Hook)来适时打断AI的发散,在特定关键节点引入人工决策,否则就成了完全不受控的野蛮发散。
框架设计
基于上述思考,我设计了一套针对逆向(RE)的工程框架。每当参与大型逆向工程时,我都会启用这套体系。
设计图如下:
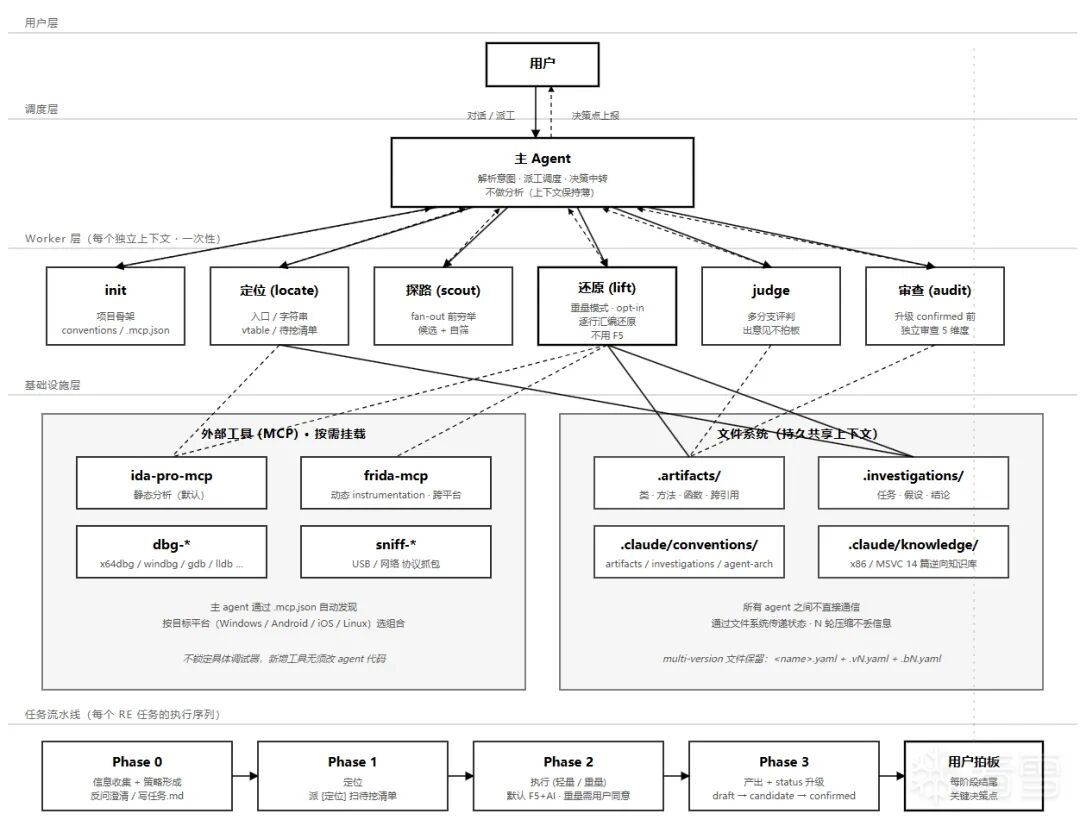
我设计的是一个多Agent框架,由“主脑”来进行决策和任务派发。主Agent直接与用户交互,拆解用户的语义分析,并指挥下面的Worker们(小弟)干活。同时,把上下文管理、逆向分析、审查等环节拆分成几个Agent各自负责。如果后续任务复杂度提升,还可以继续增加子Agent,进一步拆分细化任务。
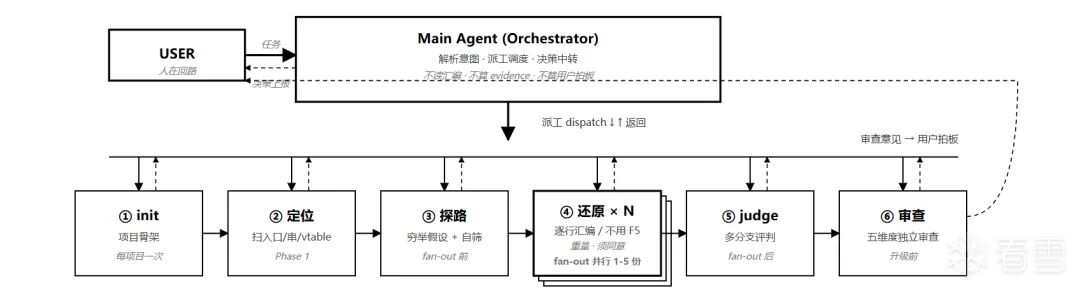
上下文管理设计
我把AI产物划分为两大部分:
- AI分析过程里的还原信息,比如:类信息、成员信息、函数信息、函数的高精度反汇编、结构体等(存放于
.artifacts)。
- AI分析过程中的逆向路径与思维链全都进行存储,避免二次返工(存放于
.investigations)。
用一张图来解释:
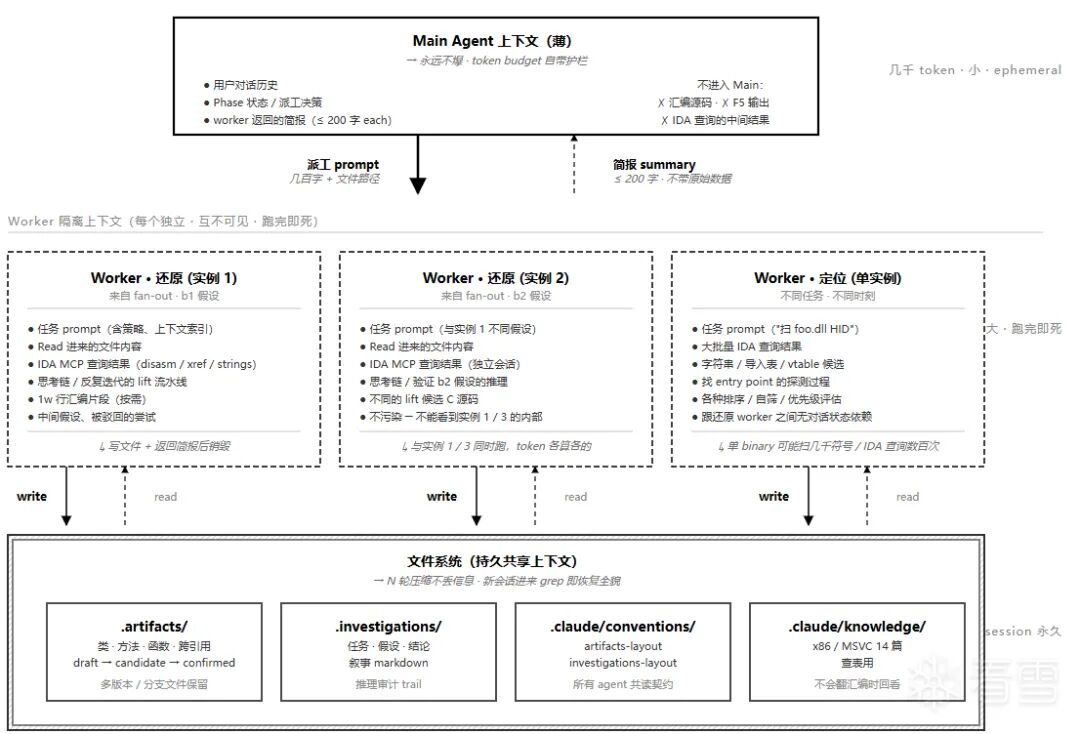
我曾经考虑过用SQLite或RAG那种向量数据库来做管理,但最终觉得这些方案都太重了,而且会伴随大量的工具调用和SQL生成,在逆向这种场景里并不太友好。原因在于这太浪费token了,而且在国产模型上引入这么多复杂操作是否会产生漂移,也需要打上一个大大的问号。
具体设计如下:
<project>/
├── CLAUDE.md ← init 从模板拷贝(项目自包含)
├── .mcp.json ← 项目级 MCP 注册(IDA / frida / dbg-*)
├── README.md
│
├── .artifacts/ ═══ AI 产物 ═══
│ ├── index.yaml 主索引(地址 → 路径)
│ ├── <binary>/ 每个目标 binary 一个目录
│ │ ├── classes/
│ │ │ └── <Class>/
│ │ │ ├── class.yaml 类元数据
│ │ │ └── methods/
│ │ │ ├── speak.yaml 主文件 = 当前活跃
│ │ │ ├── speak.v1.yaml 历史版本
│ │ │ └── speak.b1.yaml fan-out 分支
│ │ └── functions/
│ │ └── 0x140xxxxx.yaml 未归类函数
│ └── cross_refs/
│ ├── index.yaml 跨引用内部索引
│ └── xref_001.yaml 单条跨引用
│
└── .investigations/ ═══ AI 思考过程 ═══
├── 000-定位-<binary>/ Phase 1 产出
│ ├── 任务.md
│ ├── 发现*.md
│ └── 待挖清单.md
└── 001-<任务名>/ Phase 2 任务
├── 任务.md 任务简报(Phase 0 写)
├── 假设A-*.md 多假设并行
├── 假设B-*.md
└── 结论.md 结案后写
此外,还设计了如下几种文件格式来存储逆向过程中的信息:
schema_version: 1
# 1) 项目里有哪些目标 binary
binaries:
- name: foo.dll
sha256: 8f3a2b1c00000000000000000000000000000000000000000000000000000000
arch: x64
- name: bar.exe
sha256: a12b3c4d00000000000000000000000000000000000000000000000000000000
arch: x64
# 2) 每个分析过的地址,当前文件在哪(核心)
addresses:
'foo.dll:0x1400077c0':
path: 'foo.dll/classes/Animal/methods/speak.yaml'
kind: method # method | function
'foo.dll:0x140007740':
path: 'foo.dll/classes/Animal/methods/get_age.yaml'
kind: method
'foo.dll:0x140007550':
path: 'foo.dll/functions/0x140007550.yaml'
kind: function # 还没归类
'bar.exe:0x140003200':
path: 'bar.exe/functions/0x140003200.yaml'
kind: function
# 3) 已识别的类(轻量列表)
classes:
- id: 'foo.dll:Animal'
path: 'foo.dll/classes/Animal/'
- id: 'foo.dll:Dog'
path: 'foo.dll/classes/Dog/'
它由树形目录结构和一份主索引构成,共同管理着我们的具体逆向信息。
产物一共分四类:class类文件、方法文件、未归类函数(或面向过程分析中碰到的函数)。
类文件格式:
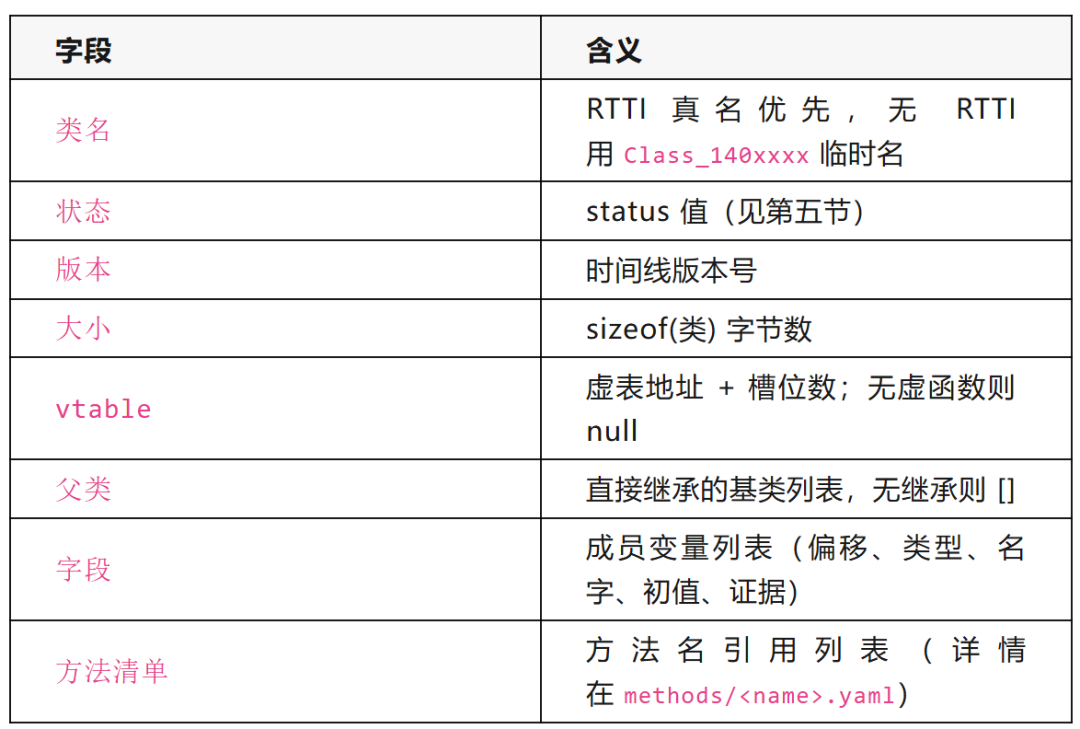
方法文件格式:
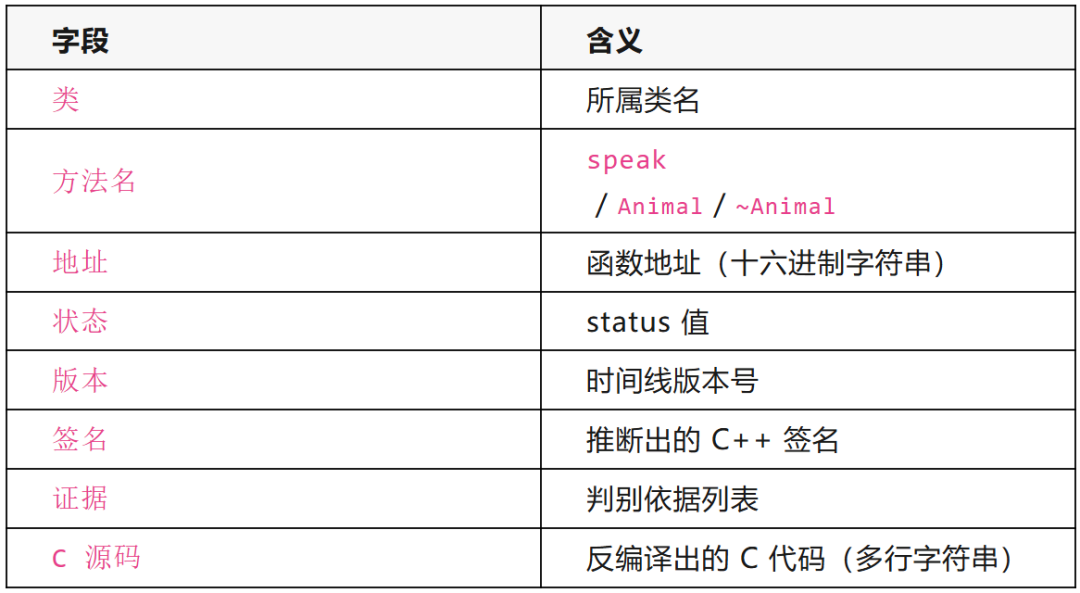
未归类函数格式:
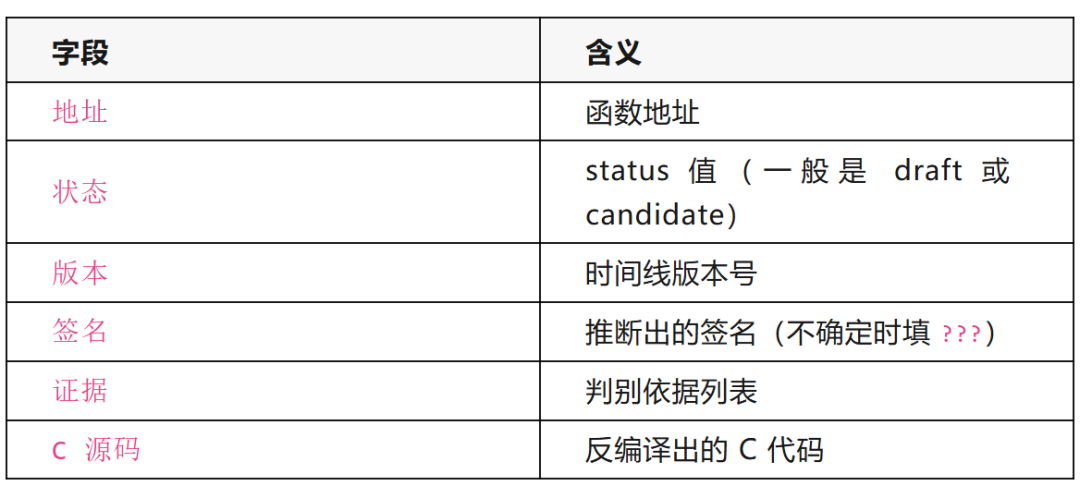
Status 状态机
这里要介绍一下 status 值。它本质上代表了我们逆向产出的置信度。在AI逆向过程里,任何来自AI的产出都并不可靠,都存在置信度问题。如果对某个结果100%信任,那你早晚会出大问题。所以,我们需要为每个结果打上一个置信度标签,只有积累了足够证据、经过多维度交叉验证后,它才能算是可信的。否则,Agent在阅读这些信息时,都应该带着一定的怀疑态度去审视。
这个状态的更改,由审查Agent负责,并结合半人工的方式来完成。(这一步主要是为了解决幻觉问题)
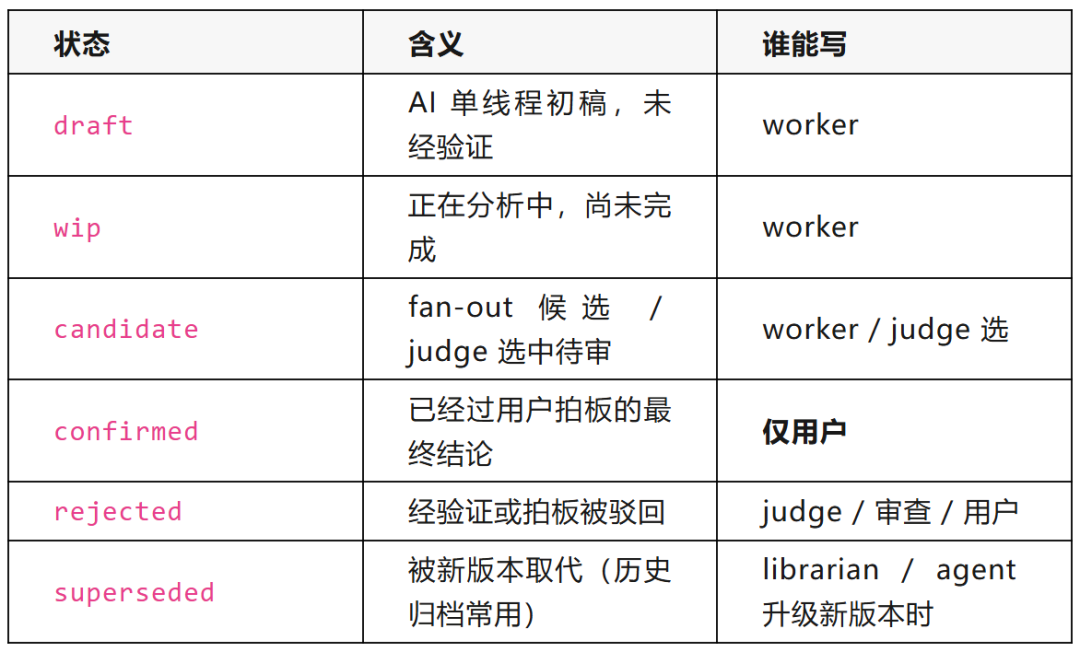
我设计了下面这些状态值:
常见的流转流程是这样的:
[worker / fan-out 产出]
状态: candidate
↓
[审查 agent 独立审查]
读:candidate.yaml + 关联 .investigations/ 推理
出:同意 / 不同意 / 需补证据
↓
[主 agent 转给用户]
附带审查意见
↓
[用户拍板]
confirmed / rejected / 保持 candidate(要求补证据再审)
最后,我们给不同的Agent赋予不同的权限,但 confirmed 这一状态,一定要有人(用户)来拍板,确保这个结论点完全靠得住。
- worker 自己产出的最高只能是 `draft` 或 `candidate`
- judge 评判 fan-out 后只出意见,不直接改 status
- 审查 agent 只输出审查意见,不直接改 status
- `confirmed` 必须由用户亲自拍板 —— AI 永远写不到这一档
跨文件关联分析
在上述设计下,我们实现的是单一文件的一对一管理。但我们都知道,逆向通常涉及多个.so或.dll之间的互相引用。这种跨文件关联如何解决呢?
答案是使用一个 cross_refs 文件来管理跨DLL之间的关系表达。
格式如下:
| 字段 |
含义 |
编号 |
形如 xref_001 |
状态 |
status 值 |
版本 |
时间线版本号 |
从 |
引用发起方(binary + 地址) |
到 |
引用目标(binary + 类 + 方法 + 地址) |
关系类型 |
调用 / 引用虚表 / 引用数据 / 字符串引用 / 继承 |
证据 |
判别依据 |
举一个实际例子:
编号: xref_001
状态: confirmed
版本: 1
从:
binary: bar.exe
地址: '0x140003200'
到:
binary: foo.dll
目标类型: 方法
类: Animal
方法名: speak
地址: '0x1400077c0'
关系类型: 调用
证据: 间接调用 [rcx+8],rcx 在 0x14000312A 处加载 Animal::vftable(??_7Animal@@6B@)
版本管理
我们不可能只通过一轮对话就把一个任务彻底完成,这其中就存在版本迭代的问题。比如,逆向的第一版我们已经拿到了,但由于各种原因,我们推翻了之前的分析过程和结论。但切换到第二个方向是否就一定对呢?不确定。因此,就需要对各个版本进行管理。
格式如下:
| 命名 |
含义 |
何时产生 |
<name>.yaml |
当前活跃版本 (主文件,索引指向这个) |
总是存在 |
<name>.v1.yaml / <name>.v2.yaml / <name>.vN.yaml |
时间线历史版本 (已被新版本替代) |
升级新版本时,旧主文件改名为 .vN |
<name>.b1.yaml / <name>.b2.yaml / <name>.bN.yaml |
fan-out 分支候选 (同时刻互斥假设) |
scout 出 N 候选 → 主 agent 派 N 个 worker → 各产出一个 .bN 文件 |
真实情况看起来是这样的:
classes/Animal/methods/
├── speak.yaml ← 当前主文件(v3 内容,confirmed,从 b3 复制来)
├── speak.v1.yaml ← 第一次分析(status: rejected,把它当成普通函数)
├── speak.v2.yaml ← 第二次分析(status: superseded,识别为 Animal::speak 但还原不准)
├── speak.b1.yaml ← fan-out 候选 1(djb2 假设,status: rejected)
├── speak.b2.yaml ← fan-out 候选 2(strcmp 假设,status: rejected)
└── speak.b3.yaml ← fan-out 候选 3(CRC32 假设,status: superseded,已被 speak.yaml 取代为活跃)
文件迁移机制
我工作中遇到的通常是大型商业软件的逆向,面向过程的极少,大多数是面向对象的设计模型(就看那几种老传统了)。所以逆向到最后,它一定是一个类方法、虚方法之类的东西。这里面存在一个环节:从早期的函数形态向面向对象的上下文进行转型。比如,一个核心算法,它最后肯定属于一个类,而非孤立的一个函数。在我们的上下文管理体系里,就存在从“函数(function)”状态到“类(class)对象”的迁移过程。
设计是这样的:
1. 写新位置 `classes/<X>/methods/<name>.yaml`,加上 `类` 和 `方法名` 两个字段
2. 更新主索引 `addresses` 里对应那条:
- `path` 改为新位置
- `kind` 从 `function` 改为 `method`
3. 更新类的 `class.yaml`,在 `方法清单` 数组里加上 `<name>`
4. 删除旧位置 `functions/<addr>.yaml`
主要就是完成文件的迁移,把之前的旧文件删掉,迁移到对应的类下面。
AI思维分析上下文管理
这部分内容非常庞杂,没法像上面那样做太精细的区分。
这里拿一个真实项目举例:
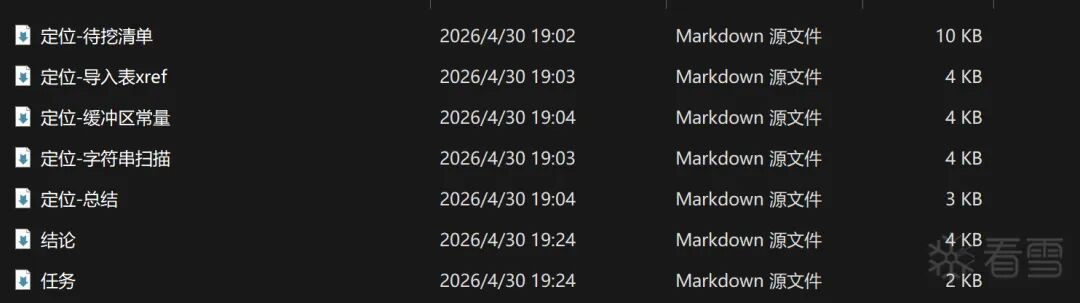
从任务出发,到最后定位总结分析,完整的一条链路。
设计如下:
---
编号: 001
任务: 分析foo.dll的USBHID协议
任务类型: 协议分析 # 还原 / debug / patch / 协议分析 / 行为分析 / ...
模式档位: 轻量 # 轻量 / 重量(重量启动前必须用户同意)
状态: 进行中 # 进行中 / 已结案 / 已放弃
创建时间: 2026-04-30
更新时间: 2026-04-30
---
Knowledge 设计
在聊完上下文管理之后,想说说我自己任务里遇到的高精度还原问题。
第一步,我把自己蒸馏了。我将所有最基础、最纯粹的逆向工程和编译原理知识,蒸馏成了一个静态的知识库。
INDEX 是整个知识库的索引目录,用来告诉Agent在遇到问题时,该去读取哪一块必要的知识。
Skills
前面我说过,AI其实并不“懂”逆向,它懂的是F5和汇编,不太明白如何完整地还原一个类或一套算法逻辑。
所以这里我整理了两个Skills,一个是“类识别(class-identify)”,另一个就是“lift”,也就是我常说的人肉F5。

在这个位置,我们放置了AI不会、但经人为指点后就能做好的事情所需技能。比如脱壳、去花指令等。
Lift Skills
在高精度还原中,我们人类是通过汇编骨架来逐层还原的。流程如下:
步骤 1 骨架还原 控制流壳(if/while/for/switch),条件和函数体用占位符
↓
步骤 2 逐行机械翻译 asm → C 伪代码,变量名直接用寄存器名(不识别不优化)
↓
步骤 3 签名草稿 从调用方视角推断调用约定 + 参数个数(待修正)
↓
步骤 4 优化 约定寄存器识别 / 折叠中间寄存器 / 内存操作分类 / lea 处理
↓
步骤 5 语义折叠 识别算法模式 + 改有意义变量名 + 修正签名
这里的产出一定是一个.cpp文件,也与前面上下文产物管理相对应的部分直接挂钩。
Class-identify Skill
由于工作中需要大量评估整个项目里类与对象的工程化结构,我急需一套系统化的评估技能,于是基于自身业务制作了一个Skills。
工作流(简版):
1. RTTI 优先 → 有 RTTI 的话整套继承图、类名、虚函数表都能直接拿到
2. 没 RTTI 时用户给起点 → 用户给某个 ctor / thiscall 方法的地址作为分析起点
3. 通过 vtable 列虚方法
4. thiscall 偏移聚类列非虚方法
5. 配合方法体粗还原汇总 [this+N] 偏移得成员清单
输出强制 yaml schema
实测验证
这里我拿之前在半古法网页AI时期分析的一个案例(Gtuner软件协议分析,可以去看我自己的其他文章)来做测试,看看我设计的这套东西到底能不能跑通。
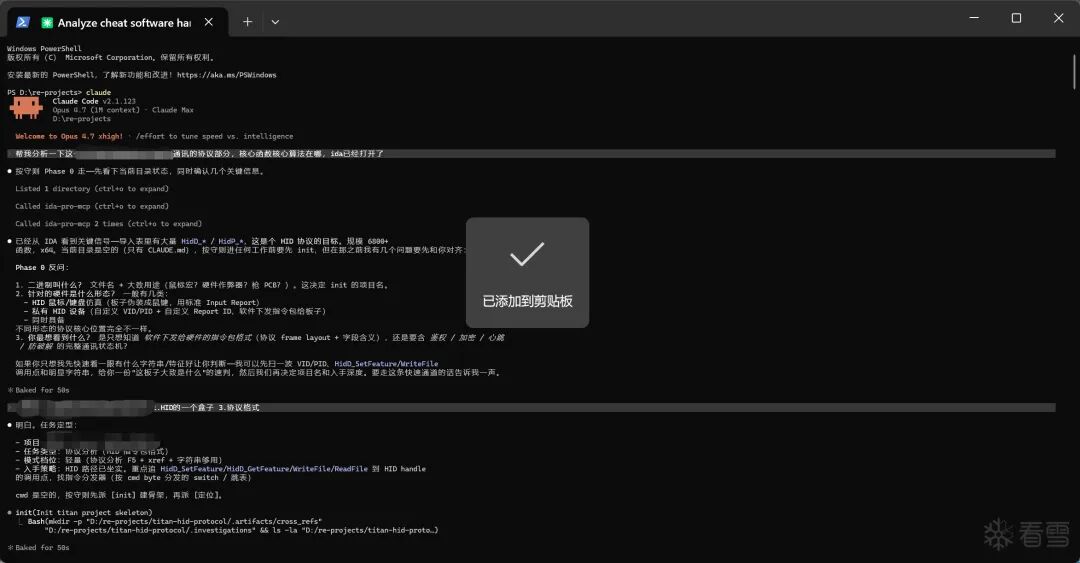
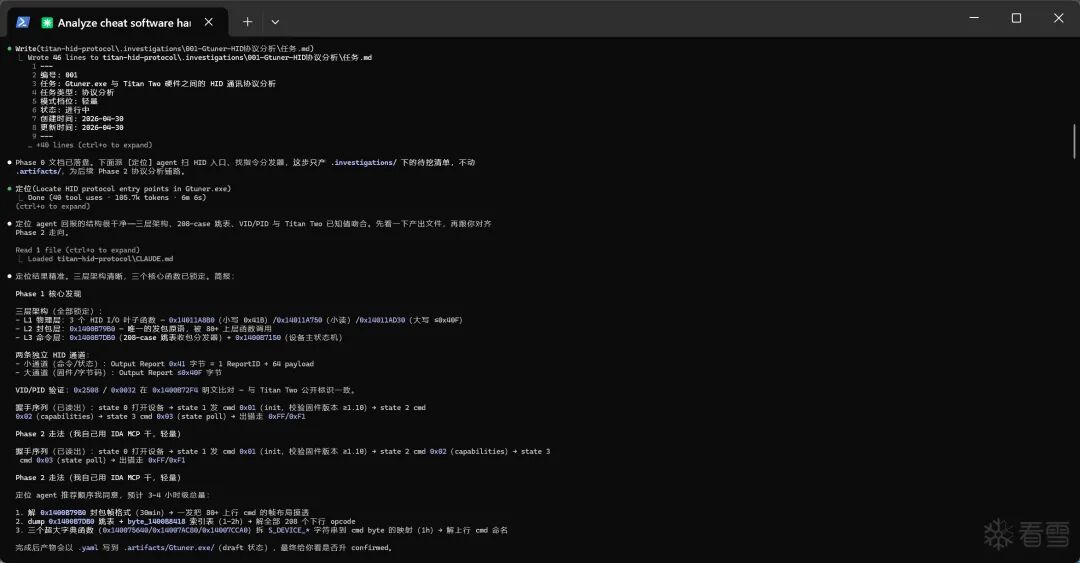
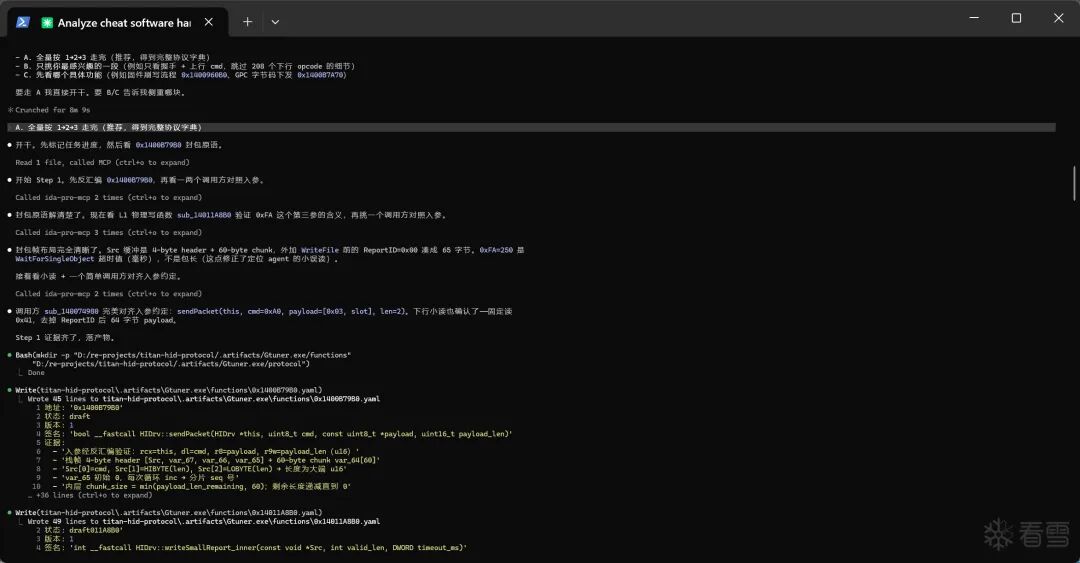
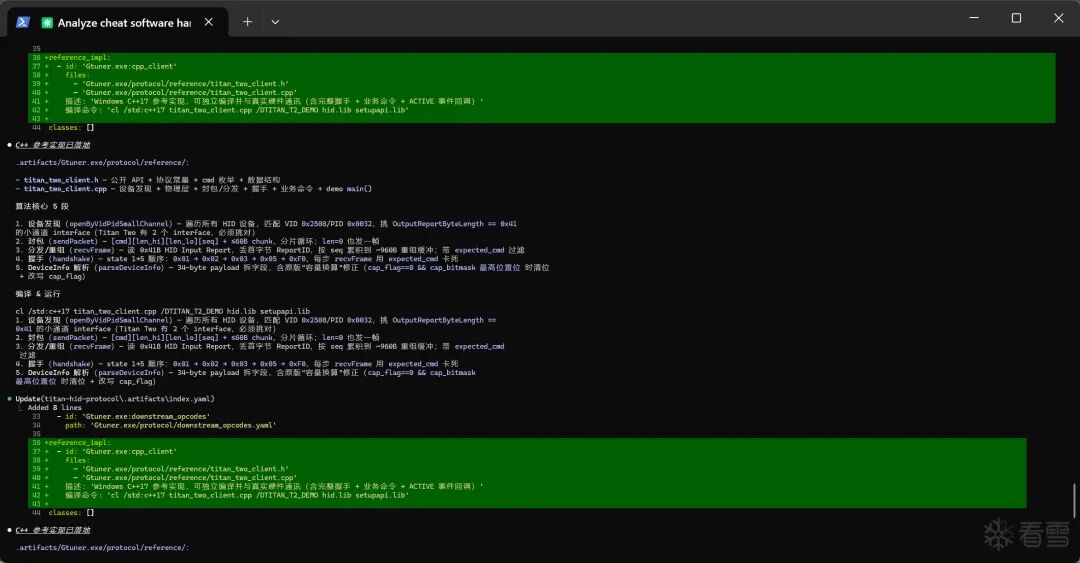
最终产物:

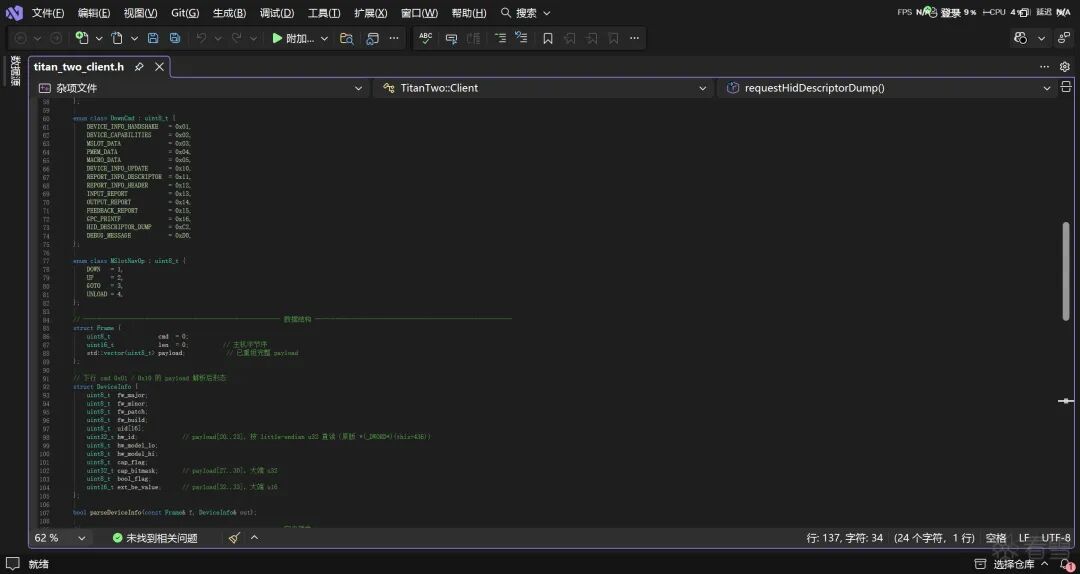
整个过程几乎没有占用我多少时间,全流程都由Agent自主完成了。中间只打断了四次——我趁机去打了把游戏,回来它就干完了。
到这里可以发现,高效的多Agent协作,本质上就是把复杂的逆向工程问题,拆解成一个由“主脑”调度、各角色各司其职的系统工程。这其实也呼应了AI逆向分析的一个未来趋势:人只保留关键决策权,其余繁重的上下文推进与交叉验证工作,完全可以放心地交由机器去迭代。
结尾
以上框架就是针对我自己的工作流进行的专项设计。目前还有动态调试这部分的融入方法没有展开讲。本文重点在于分享这套设计思想。虽然我会把工程文件放到附件里,但并不推荐大家直接照搬,更好的方式是利用我这种设计思路,去打造属于你自己的“逆向工程解决方案”。工具方面,推荐使用 OpenCode,可以把“主脑”配置到 DeepSeek V4 这类模型,干活的Worker可以选用 GLM 5.1,这样即便用国产甚至内网模型也能完成工作,就不用完全受制于 Claude 了——尽管截至目前,它依然是纯粹的逆向能力上最强的那一个。
本文基于看雪论坛精华文章技术框架整理
 发表于 6 小时前
|
查看: 4|
回复: 0
发表于 6 小时前
|
查看: 4|
回复: 0
