当我们谈论 Agent 进化时,通常涉及两类场景。一种是员工办公场景,通过 Coding Agent 或通用 Agent 的记忆、协作风格、用户画像等能力,让智能体越用越懂你。另一种是企业的业务场景,比如对外提供服务的客服 Agent,或是对内做智能分析的 Data Agent。
前者的进化速度令人振奋。Anthropic 发布的 Economic Index 显示,使用 Claude 超过 6 个月的老用户,对话成功率比新用户高出 3–5 个百分点。然而,后者——业务型 Agent——仍处于各企业手动摸索观测、评估、优化,各自沉淀实践经验的阶段。本文要讨论的,正是后者。
企业手搓 Agent 进化飞轮的现状
进化飞轮通常分为四个步骤:数据采集、数据集构建、效果评估、进化资产沉淀。虽然模型和 Agent 的进化流水线看起来相似,但影响 Agent 行为的变量要多得多。
模型任务只是一次调用,包含输入和输出。而 Agent 任务是一条带拓扑结构的“线”,甚至是一张“网”。因为它除了模型调用,还涉及检索、规划、工具调用、浏览器访问、中间状态、反思与决策、回退,乃至多个并行子任务。正是这成倍的复杂性,让传统的 LLM-as-Judge 范式在 Agent 时代显得捉襟见肘。
▍ 数据采集难:从单点到拓扑,Schema 不再稳定
LLM-as-Judge 范式采集的是 (prompt, completion) 二元组,Schema 规整,存日志即可。而 Agent 行为评估需要采集的是完整的 Trajectory(执行轨迹):每一步的输入输出形态各异——检索返回 chunk 列表,工具返回结构化 JSON,浏览器返回 DOM 片段,模型返回 token 流。如何将这些异构事件按时序和因果关系串联,不丢失中间状态和父子调用关系,还要附加上 token 用量、延迟和错误码?存储与埋点的成本是 LLM-as-Judge 的几十倍。更何况,OpenTelemetry 的 GenAI semconv 仍处在草案阶段,目前尚无事实标准,企业基本都在重复造轮子。
▍ 数据集构建难:一条轨迹,是好样本吗?
LLM-as-Judge 可从日志中按 token 长度、置信度、人工反馈筛选 prompt-completion 对。但一条 Trajectory 包含了规划、检索、工具调用、中间状态、反思/决策分支、模型调用及最终输出。把这串完整的序列串起来,就是一次任务的“基因图谱”。
但问题来了:即使最终结果正确,中间却执行了三次错误工具,这条轨迹算好样本吗?反之,结果错了,但前五步推理完美,这五步是否该被单独抽取为训练信号?此外,轨迹中常包含真实的业务数据(如订单、客户姓名),脱敏远非字符串替换那么简单,需要结构化处理才能进入数据集。这些难题让人肉标注几近崩溃。
▍ 效果评估难:单点评分失效,需要分层立体评估
在 LLM-as-Judge 里,评估是对一个点打分。而 Agent 时代至少要分三层来评:
- Step-level:每一步的工具调用是否正确?
- Trajectory-level:整条路径是否合理,有没有绕路、回退或死循环?
- Outcome-level:最终交付成果是否满足需求?
棘手的是,这三层的评估结论可能完全矛盾。
▍ 沉淀进化资产难:经验难以标准化
模型的资产形态非常清晰:SFT 数据、DPO pair、LoRA 权重,业界有共识,工具链也成熟。而 Agent 的资产形态仍在分化:可以回流成 prompt 改进,可以构造成 few-shot 经验库,可以做成 episodic memory,还能抽成可复用的 Skill 或子流程。每种形态消化 Trajectory 的方式都不同,且缺乏像模型权重那样的统一容器。这导致企业即便完成了前三步,最后一步资产如何落地、落到哪、由谁来消费,依然是个未知数。
最终的结果就是:Agent 上线了,用户更多了,但企业拥有的可进化资产并未同步增长。 这已成为企业智能体进化的普遍现状。
阿里云 AgentLoop 的实践
AgentLoop 是阿里云推出的面向企业级智能体的一站式自进化平台,提供了 Agent 全栈观测与审计、评估与实验、资产管理与持续优化等核心能力,旨在帮助企业构建智能体进化的数据飞轮。其应对方案具体如下:
▍ 第一环:全栈观测分析——完整的 Trajectory 执行轨迹
AgentLoop 通过 LoongSuite 开源自动插桩框架,将采集对象从二元组升级为完整的 Trajectory。

LoongSuite 融合了三层语义规范:OTel GenAI 社区标准(含阿里贡献的 STEP / MCP span 扩展)、AgentLoop 产品侧数据契约,以及采集层自有扩展(session / turn / step / cost 等专属字段),总计覆盖 55 个 GenAI 语义字段。在第三方源码逐行对比中,LoongSuite 的有效字段覆盖率高达 84%,而竞品最高仅为 51%。
基于采集到的 Trajectory,AgentLoop 提供了四类交叉印证的诊断视图:调用树(逐层下钻 Span 耗时占比)、推理轨迹(还原 ReAct 思考-工具-观察序列,自动检测无效循环)、时序线(清晰区分串行/并行与阻塞等待)和链路拓扑图(还原全局调用关系)。
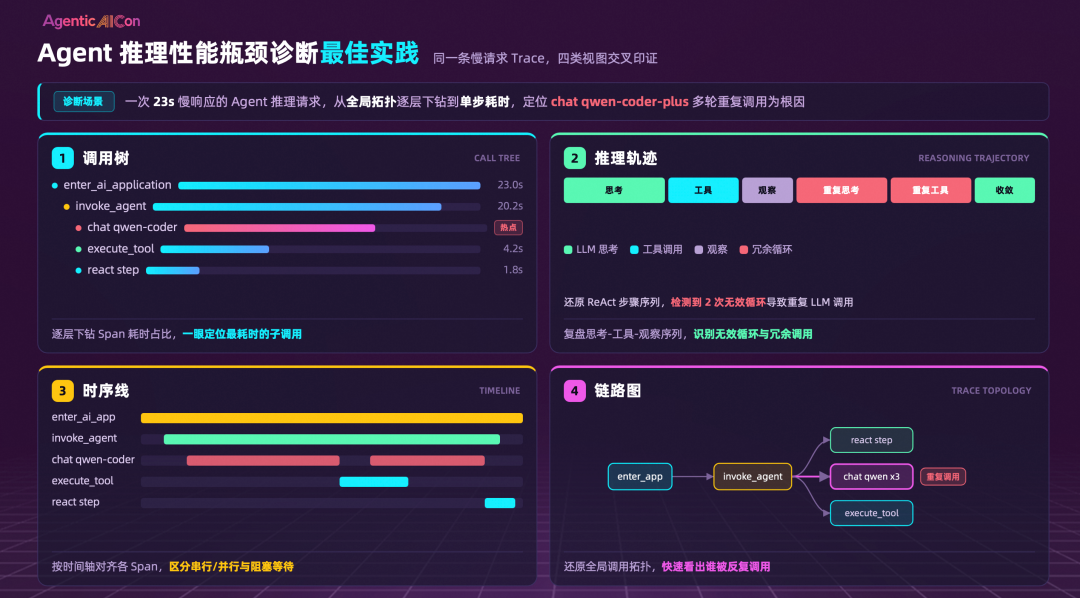
例如,一个 23 秒的慢请求,通过这四层视图交叉定位,可以精准锁定“某一轮 LLM 的多步冗余循环调用”这一根因。
▍ 第二环:Agent Ontology + Pipeline,让观测数据图谱化,自动构建高质量数据集
仅有 Trajectory 还不够,因为采集回来的观测数据仍然是孤立的元数据,是一条条互不关联的 span。AgentLoop 在此基础上做了第二件事:基于 UModel 构建面向 Agent 实体关系的拓扑——Agent Ontology。它能自动发现 Agent → Tool → Model 之间的实体关系,打破数据孤岛,将观测数据图谱化。
有了 Agent Ontology,每一条 Trajectory 就成了一张关系明确的有向图。运维和算法团队得以从 Agent 的视角审视问题,再也不用在扁平的海量日志里大海捞针。
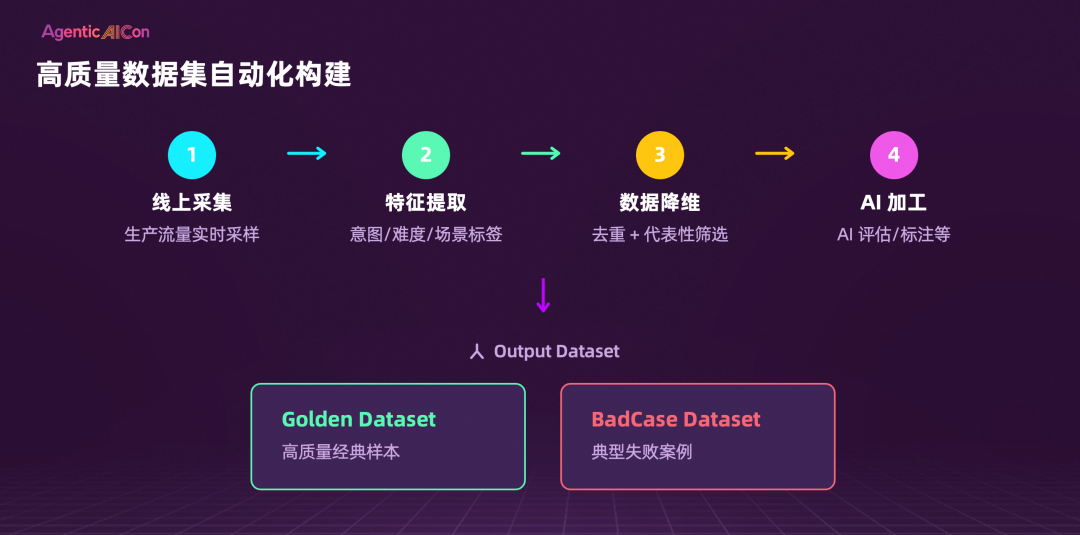
在 Ontology 之上,AgentLoop 还叠加了一条自动化 Pipeline:Trace2Dataset。其逻辑是:将线上全量运行时数据(Trajectory),通过 Pipeline 编排数据源接入 → 数据降维(过滤/去重/采样) → 特征提取(意图/难度/场景标签) → AI 审核与改写 → 写入目标数据集,最终自动构建出 Golden Dataset(高质量经典样本) 和 BadCase Dataset(典型失败案例)。这套流程整体可节省 90% 以上的 Token 消耗与时间成本。
▍ 第三环:内置标准化评估器,准确评价 Agent 真实表现
数据有了,数据集也构建了,下一步就是评估。Meta AI 与 KAUST 团队在《Agent-as-a-Judge: Evaluate Agents with Agents》论文中提出了一个关键观点。他们构造了 DevAI 基准(包含 55 个真实 AI 开发任务与 365 条层级化用户需求),要求评估方不仅要看最终结果,还要核对中间每一步是否满足结构化需求。
实验表明,与人类专家评估的一致率,从 LLM-as-a-Judge 的约 65% 提升到了 Agent-as-a-Judge 的 90%。更关键的是,Agent-as-a-Judge 的评估成本仅为人工的 1/30。

因此,AgentLoop 采用了这一范式,并将其产品化。它的评估器本身就是一个 Agent:它能基于大模型进行规划、调用工具、回放轨迹,并基于中间状态做多步推理来做出判断。AgentLoop 提供了 13 个标准评估器,如“Agent 任务完成度”、“Agent 回答证据支持度”、“Agent 工具调用成功率”等,并支持用户自定义。
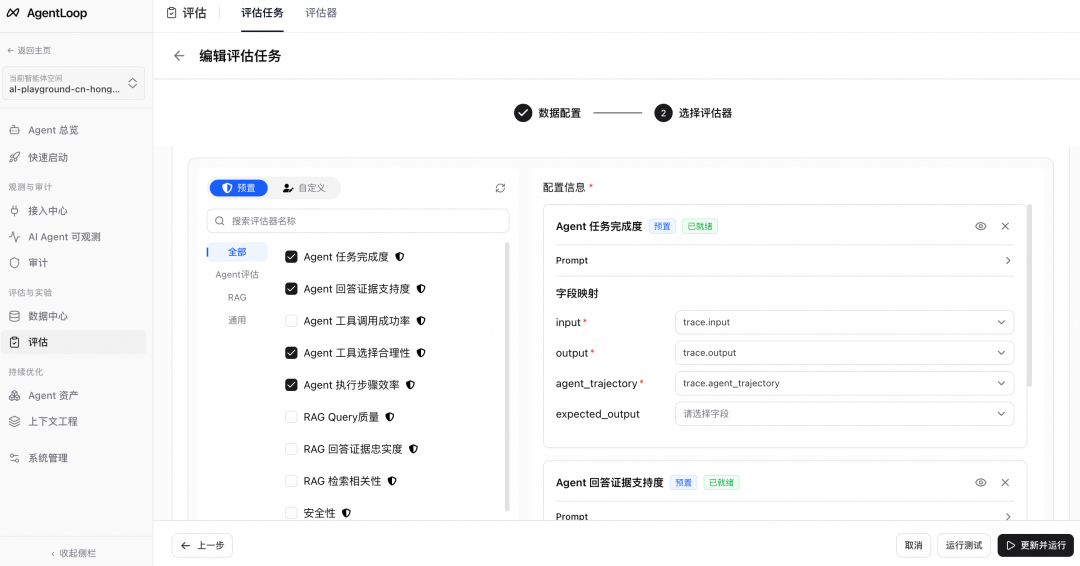
这些评估器覆盖了六大维度:问答准确性、Skill 执行质量、意图达成度、安全合规、上下文一致性和业务自定义。总的来看,AgentLoop 通过全量自动化数据采集、Agent Ontology、自动化 Pipeline 以及 Agent-as-a-Judge 范式,实现了持续评估,为进化飞轮铺好了基础设施。
▍ 第四环:记忆库与经验库,智能体进化的上下文工程
然而,飞轮中的全栈采集、图谱认知和精准评估,本质上都是“打分器”。如何将评估结果转化为智能体效果的提升,才是构建飞轮的最终目的。AgentLoop 将此拆解为两条路径。
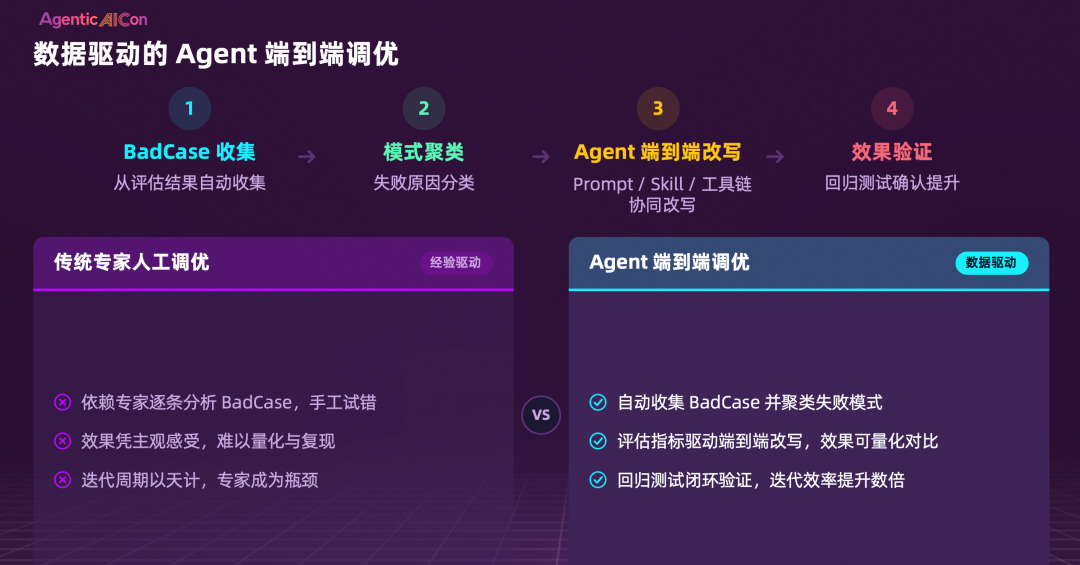
路径一:数据驱动的 Agent 端到端调优。 从评估结果中自动收集 BadCase → 失败模式聚类 → Agent 端到端改写(Prompt / Skill / 工具链协同改写) → 回归测试验证提升。这是“快速拉升基线”的路径,见效快。
路径二:Trajectory 驱动的自进化闭环。 这是一种更彻底的自动化演进方式:Agent 运行中自动记录完整调用轨迹与上下文 → 从成功/失败的 Trajectory 中自动提取可复用的经验规则 → 经验规则按需(Just-in-Time)注入 Agent 上下文 → 评估注入效果,持续迭代优化经验库。
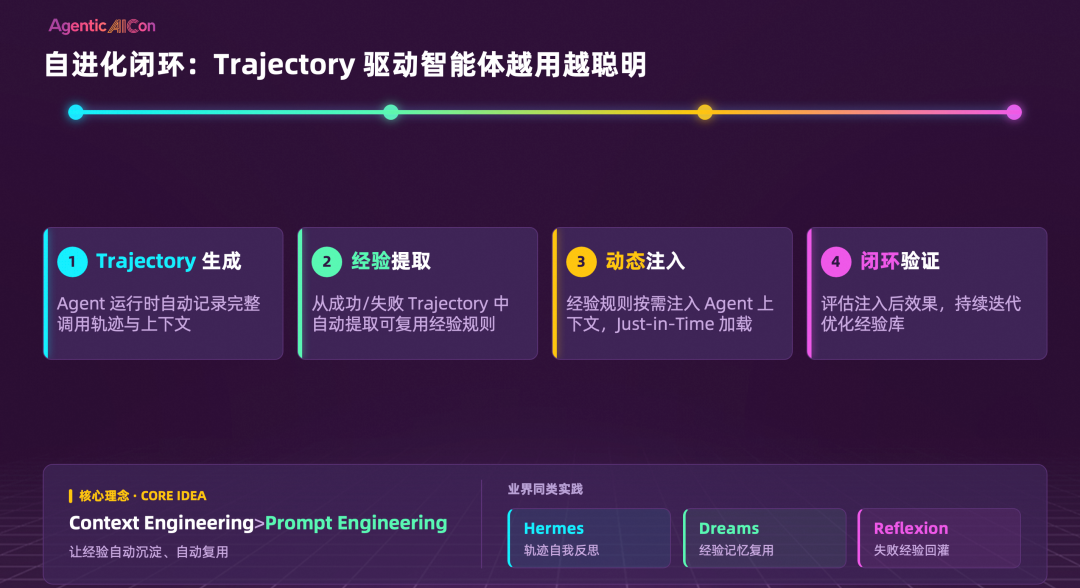
要将以上两条路径落地,AgentLoop 提供了记忆库与经验库两个独立组件。记忆库覆盖事实、情节、摘要和自定义四种策略,将用户偏好和历史上下文沉淀为长期可检索层,并在下次遇到类似请求时自动注入。经验库则聚焦于成功模式的提取与复用,通过与各行业专家共建,将经验泛化为规则,归纳为长期记忆或 Skill,在相似场景触发时自动激活。
这一设计思路,也借鉴了业界在自进化闭环领域的成功实践,例如 Hermes 的轨迹自我反思、DreamGym 的合成经验回放训练框架,以及 Reflexion 的失败经验回灌机制。
至此,一个完整的进化飞轮形成:全栈观测采集完整 Trajectory → Agent Ontology 图谱化数据 → Pipeline 自动构建数据集 → 标准化评估器准确评价表现 → 记忆库/经验库将好的经验反哺回 Agent 上下文。周而复始,智能体便能越用越聪明。
进化飞轮,是企业智能体下半场的发令枪
由于进化飞轮基础设施尚不成熟,且评估结果转化为进化资产极度依赖行业经验,多数企业智能体正陷入“上线即落后”的窘境,难以实现越用越聪明的预期。
LangChain 的《State of Agent Engineering》报告显示,22.8% 的生产团队完全不做评估,离线评估覆盖率仅 52.4%,线上评估更是只有 37.3%。足足有 32% 的团队将“质量”列为生产环境的头号障碍。Databricks 的《State of AI Agents》也给出了一组耐人寻味的数据:接入评估体系的企业数量,只有接入治理企业数量的 17%。
大部分企业正陷入一个恶性循环:缺少进化飞轮的基础设施,就不敢放量;无法放量,就没有观测数据;没有数据,就无法进化。
阿里云 AgentLoop 希望通过提供完善的进化飞轮基础设施,携手企业共同开启企业智能体的下半场。
相关链接:
[1]《Agent-as-a-Judge: Evaluate Agents with Agents》
https://arxiv.org/abs/2410.10934
[2] Hermes 的轨迹自我反思
https://hermes-agent.nousresearch.com/docs/
[3] DreamGym 合成经验回放的 RL 训练框架
https://www.emergentmind.com/papers/2511.03773
[4] Reflexion 的 episodic reflection(失败经验回灌机制)
https://arxiv.org/abs/2303.11366
 发表于 6 小时前
|
查看: 4|
回复: 0
发表于 6 小时前
|
查看: 4|
回复: 0
