你是否曾困惑于如何为智能体打造一个“称手”的试验场?当大模型驱动的 Agent 从简单的问答走向复杂的工具调用与多步决策,传统的静态数据集测评早已力不从心。中国科学院自动化研究所的这篇首份 Agentic Environment Engineering 综述,正是要为你拆解:如何系统性地为 Agent 建模、合成、评估并应用那些真正能让它进化的动态环境。

核心贡献:首次从环境工程的生命周期视角出发,对 LLM Agent 的环境建模、自动合成、质量评估与闭环应用做了全方位梳理,并前瞻性地提出了“环境即服务”(Environment-as-a-Service)等方向。

1. 从数据工程到环境工程的范式跃迁
二者的本质差异,在下面这张对比图里一目了然。
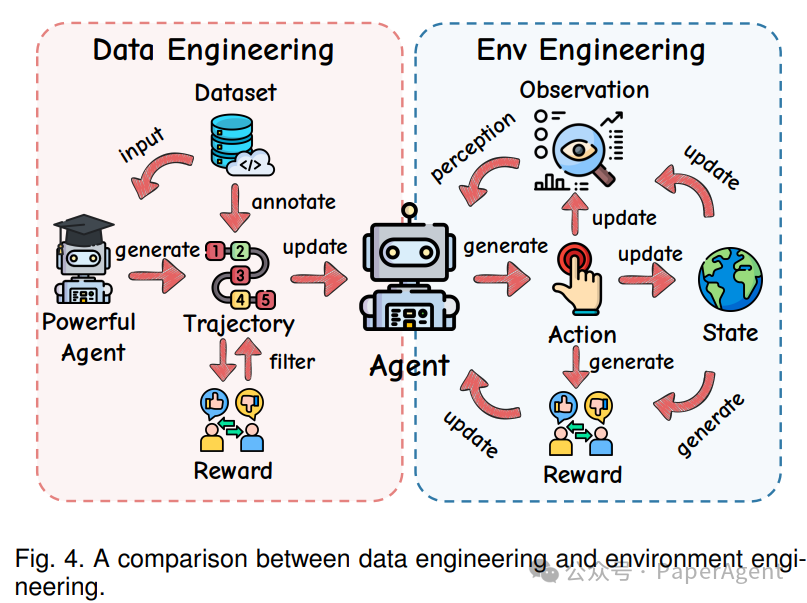
在传统的数据工程范式里,Agent 更像一个被动接收预收集轨迹的“学生”。而环境工程则不然,它让 Agent 通过 感知(Observation)→行动(Action)→状态更新(State)→奖励(Reward) 的完整闭环,摇身一变成为与周遭世界共同进化的探索者。
| 维度 |
传统数据工程 |
环境工程 |
| 学习模式 |
被动接收(单向灌输) |
协作进化(动态交互) |
| 交互形式 |
单轮问答 |
多轮工具调用与反馈 |
| 系统架构 |
开环系统(无反馈) |
闭环系统(状态-动作耦合) |
核心洞察:环境将僵化的“固定知识边界”重塑为一个“动态能力增长引擎”,数据的分布会随着 Agent 自身能力的起伏而实时调整。
2. 环境的形式化定义:POMDP 框架
论文为 Agentic Environment 下了一个严谨的定义,即部分可观察马尔可夫决策过程(POMDP)。
| 组件 |
符号 |
说明 |
| 状态空间 |
( S ) |
环境所有潜在状态的集合 |
| 动作空间 |
( A ) |
Agent 可执行的动作集合,通常由 LLM 生成的文本或工具调用组成 |
| 转移函数 |
( T ) |
状态转移的概率核,定义了环境动态性 |
| 奖励函数 |
( R ) |
标量反馈信号,用于引导 Agent 行为 |
| 观察空间 |
( \Omega ) |
Agent 感知外界环境的接口 |
| 观察函数 |
( O ) |
从环境状态到 Agent 观察的映射关系 |
| 折扣因子 |
( \gamma ) |
决定了未来奖励在当前决策中的权重 |
关键区别:与传统强化学习模拟器不同,Agentic Environment 支持的是开放式、以语言为中心、由工具增强的交互。其动作空间不再只是简单的离散动作编号,而是由自然语言 token 与丰富的工具调用共同构成。
3. 环境属性的八维分类体系
一次优秀的环境设计,离不开多维度属性的权衡。下图系统地梳理了环境设计的八个核心维度。
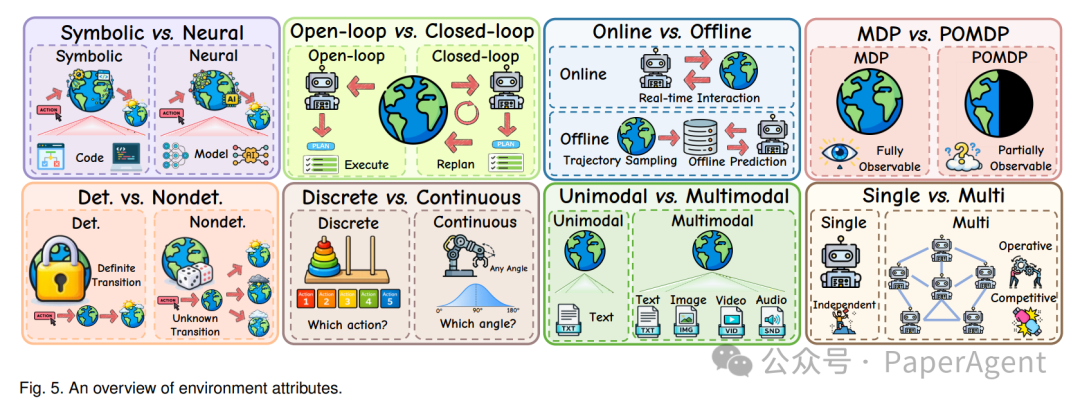
3.1 Symbolic vs Neural(实现范式)
- Symbolic:基于代码或规则引擎(如 PDDL、Python 脚本),核心优势在于确定性与可验证性。
- Neural:由神经网络参数化构建(如 World Model),通过前向传播来近似环境的复杂动态。
3.2 Open-Loop vs Closed-Loop(反馈机制)
- Open-Loop:仅依赖初始观察来执行一次性的固定计划,不接收后续反馈。
- Closed-Loop:每一步行动后都会接收新观察,并据此动态调整策略。
3.3 Online vs Offline(交互模式)
- Online:与真实的动态系统实时交互,如 WebArena 等在线沙盒。
- Offline:基于预先采样的静态轨迹数据集进行离线评估。
3.4 MDP vs POMDP(可观察性)
- MDP:环境状态完全可观察,Agent 掌握全局信息。
- POMDP:环境状态部分可观察,例如 WebArena 中,Agent 仅可见当前浏览器标签页的内容。
3.5 Deterministic vs Nondeterministic(转移特性)
- Deterministic:执行固定动作,必然导向固定的结果,行为完全可预测。
- Nondeterministic:状态转移具有随机性,同一动作可能导致不同结果。
3.6 Discrete vs Continuous(动作空间)
- Discrete:在有限的动作集合中进行选择,如 ALFWorld 中的文本指令。
- Continuous:输出一个实值向量,常用于机器人关节的精细控制。
3.7 Unimodal vs Multimodal(感知模态)
- Unimodal:输入为纯文本,如 API-Bank。
- Multimodal:输入包含文本、图像、视频等多种模态。
3.8 Single-Agent vs Multi-Agent(参与实体)
- Single-Agent:环境中仅有一个智能体独立决策。
- Multi-Agent:环境中存在多个智能体,行动空间为联合动作,如涉及合作与欺骗的社会推理游戏。
Takeaway 3:当前的基准测试环境在 Multi-Agent 场景的设置上仍显单薄;未来的一大挑战,在于如何平衡好 Symbolic 范式的工程可靠性,与 Neural 范式的生成可扩展性。
4. 环境领域的八大任务分类
覆盖了 GUI、深度研究、具身智能、游戏、工具、代码及特定专业领域的完整应用图谱。
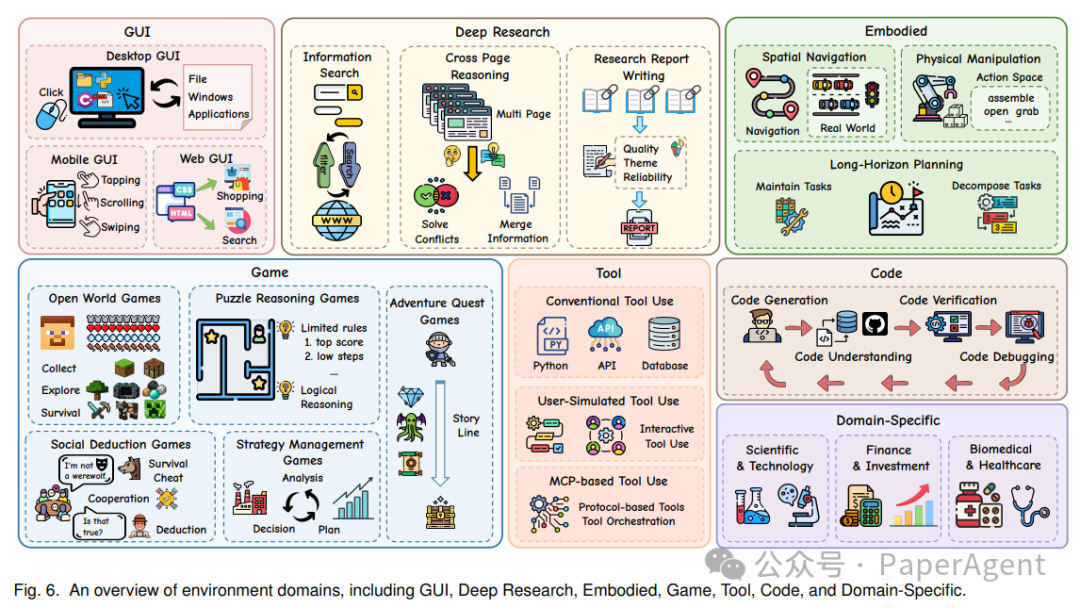
4.1 GUI 环境(桌面/移动/Web)
从静态的演示数据向可执行、可复现的真实交互演进是大势所趋。
| 子领域 |
代表环境 |
核心能力 |
| Desktop GUI |
OSWorld, WindowsAgentArena |
跨越不同桌面应用的复杂长程规划 |
| Mobile GUI |
AitW, AndroidWorld, Mobile-Env |
在小尺寸屏幕上进行深层页面导航与精确交互 |
| Web GUI |
WebShop, Mind2Web, WebArena |
处理动态且信息丰富的网页操作任务 |
4.2 Deep Research 环境
可分为三个具备递进关系的层次:
- Information Search(信息检索):如 SimpleQA 等。
- Multi-Source Reasoning(多源推理):综合多个页面信息进行逻辑推理。
- Research Report Writing(报告生成):基于收集到的海量信息撰写研究报告。
4.3 Embodied 环境(具身智能)
| 类型 |
核心挑战 |
代表环境 |
| Spatial Navigation |
空间表征构建与泛化能力 |
Habitat, MetaDrive |
| Physical Manipulation |
精确的物理接触与操控 |
RLBench, Robocasa, BEHAVIOR |
| Long-Horizon Planning |
复杂任务的分解与长时状态维护 |
ALFRED, ALFWorld, TEACh |
4.4 Game 环境
- Open World:如 MineDojo,考验探索与生存能力。
- Puzzle Reasoning:如 Baba Is AI,聚焦规则重写与组合推理。
- Social Deduction:如 AvalonBench,模拟多 Agent 间的欺骗与社交推理。
- Strategy Management:如 CivRealm,强调资源的长期规划与策略管理。
| 类型 |
特点 |
代表环境 |
| Conventional Tool Use |
围绕标准 API 的调用能力 |
API-Bank, ToolBench, AppWorld |
| User-Simulated Tool Use |
嵌入复杂的用户交互模拟 |
τ-bench, UserBench, τ²-bench |
| MCP-based Tool Use |
基于标准化协议的工具调用与编排 |
MCPVerse, MCP-Bench |
4.6 Code 环境
完整覆盖了软件工程的全生命周期,包括代码生成(MBPP)、代码理解(NL2Repo-bench)、代码验证(LiveCodeBench)以及代码调试(SWE-Bench)等环节。
4.7 Domain-Specific 环境
| 领域 |
代表环境 |
专业要求 |
| Biomedical & Healthcare |
MedAgentBench, MedAgentGym |
精通临床术语与生物信息学工作流 |
| Science & Technology |
DiscoveryWorld, ScienceAgentBench |
深入理解科学文献并进行实验设计 |
| Finance & Investment |
StockBench, FinDeepResearch |
实时分析市场信号并作出风险决策 |
4.8 Cross-Domain 环境
用于评估 Agent 的跨领域泛化能力,代表基准如 AgentBench、GEM 等。
5. 环境自动合成:从人工构建到规模化生成
5.1 Symbolic Synthesis(符号合成)
合成范式的演进路径,本质上是一个自由度不断释放的过程。
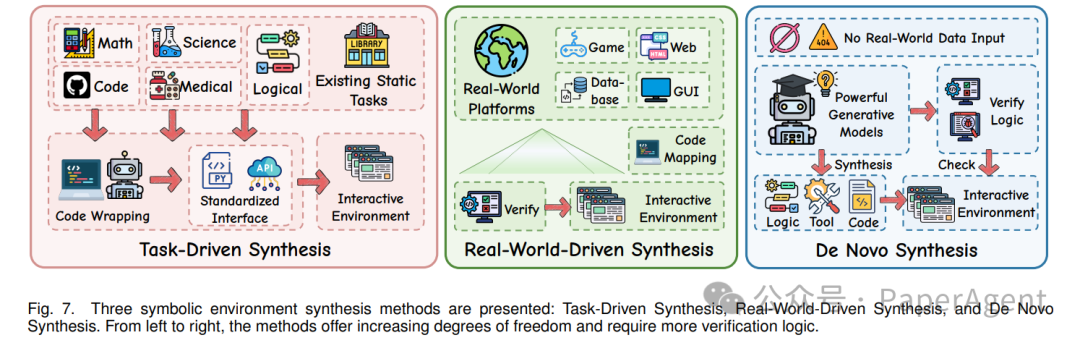
| 范式 |
自由度 |
依赖数据 |
代表方法 |
| Task-Driven |
低 |
已有静态任务数据 |
SWE-Gym, AgentScaler |
| Real-World-Driven |
中 |
源自真实系统的抽象映射 |
AgentSynth, OSWorld-MCP |
| De Novo |
高 |
仅需极少的种子甚至零样本 |
AutoEnv, LOGIGEN, AutoForge |
关键演进:从“任务驱动”(用代码封装静态数据),到“真实世界驱动”(对现实系统做虚拟映射简化),再到“从零开始生成”(以最小先验知识自动创造),合成的自由度在不断放大。
5.2 Neural Synthesis(神经合成)
按表征的粒度层级,可以划分为三种范式。
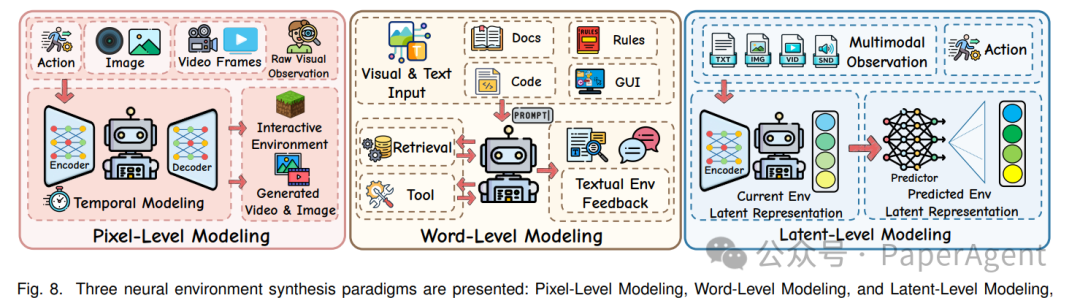
| 层级 |
表征对象 |
优势 |
劣势 |
代表方法 |
| Pixel-Level |
原始视觉观测(图像/视频帧) |
高保真,细节丰富 |
信息冗余,计算开销巨大 |
Matrix-Game, NeuralOS, DIAMOND |
| Word-Level |
自然语言描述 |
高度抽象,计算成本低,跨领域通用 |
存在信息压缩损失,易产生幻觉 |
WebDreamer, WKM, Code2World |
| Latent-Level |
模型学习到的隐空间表征 |
在紧凑性与预测力之间取得平衡 |
可解释性较差,依赖预训练 |
V-JEPA 2, DINO-world |
5.3 环境质量评估的四维框架
有了环境,如何判断它的好坏?这里提出了一套四维评估标准。
| 维度 |
核心问题 |
评估手段 |
| Correctness |
状态转移是否有效?任务本身可解吗? |
程序执行、单元测试、专家审核 |
| Diversity |
覆盖的任务、状态与工具空间是否足够多样? |
嵌入去重、聚类分析、t-SNE 可视化 |
| Complexity |
难度是否与 Agent 当前的能力相匹配? |
结构参数(步数/工具数)、强模型胜率 |
| Fidelity |
是否忠实反映了真实系统的特性? |
FID/LPIPS 等感知指标、Web Turing Score |
Takeaway 5.3:质量评估正在从“先大量生成,后过滤挑选”的后处理模式,转向“生成-验证-精炼”的闭环。在四个维度中,Correctness 的研究已相对成熟,而 Diversity、Complexity 与 Fidelity 则仍处于探索的起步阶段。
6. Agent 进化:四大互补路径
如果说环境是舞台,那么 Agent 的自我进化则是舞台上的重头戏。下面这张全景图展示了四条核心进化路径。
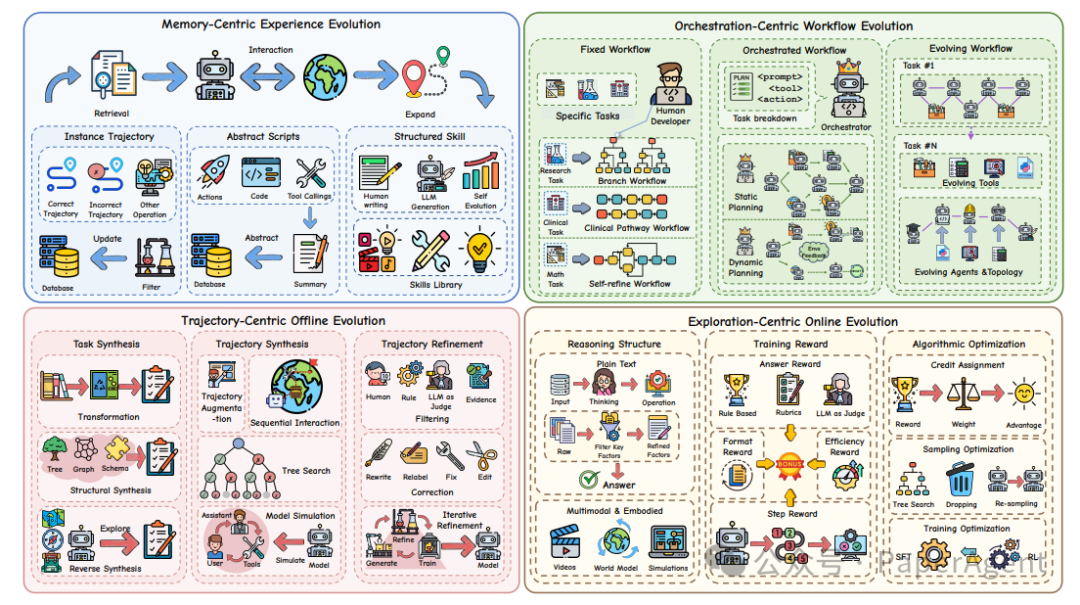
6.1 Memory-Centric Experience Evolution(记忆中心)
从过去的经历中汲取养分,是 Agent 进化的基础。
| 粒度 |
形式 |
特点 |
代表方法 |
| Instance Trajectory |
完整的交互轨迹 |
最详细、最具体,但泛化能力弱 |
Synapse, WorldMM |
| Abstract Scripts |
可复用的脚本化模式 |
具备一定跨任务泛化性 |
Reasoning-Bank, Agent-Pro |
| Structured Skill |
模块化的技能库 |
高度结构化,支持组合与调用 |
SAGE, SkillWeaver, SkillRL |
6.2 Orchestration-Centric Workflow Evolution(工作流编排)
解决复杂任务,靠的是组织有序的工作流。
| 类型 |
拓扑特征 |
控制方式 |
代表方法 |
| Fixed Workflow |
确定性的逻辑图 |
人工预设,固定不变 |
MetaGPT, Agentless |
| Automated Workflow |
动态编排图 |
由中心协调器统一调度 |
AutoFlow, MaAS |
| Evolving Workflow |
持续自我演化的结构 |
自主迭代与拓扑优化 |
AFlow, Chain-of-Agents |
6.3 Trajectory-Centric Offline Evolution(轨迹离线优化)
这条路径遵循经典的三阶段流水线:
- Task Synthesis(任务合成):通过资源转换、逆向或结构合成创造新任务。
- Trajectory Synthesis(轨迹合成):通过增强、树搜索等手段生成交互轨迹。
- Trajectory Refinement(轨迹精炼):对生成的轨迹进行过滤、修正与迭代优化。
6.4 Exploration-Centric Online Evolution(探索在线强化)
这部分直接关系到强化学习中的奖励塑造与算法优化,是 Agent 在交互中提升性能的关键。
| 组件 |
设计目标 |
代表方法 |
| Reasoning Structure |
修改推理范式(如标签、步骤格式) |
Search-R1, AutoRefine |
| Training Reward |
设计多维奖励信号(结果、过程、效率) |
ToolRL, GDPO |
| Algorithm Optimization |
提升训练稳定性与样本效率 |
RAGEN, GiGPO |
7. Environment Evolution:环境自身的三大进化范式
环境不应是一成不变的,它也需要主动适应 Agent 的成长。这才是环境工程的精髓所在。
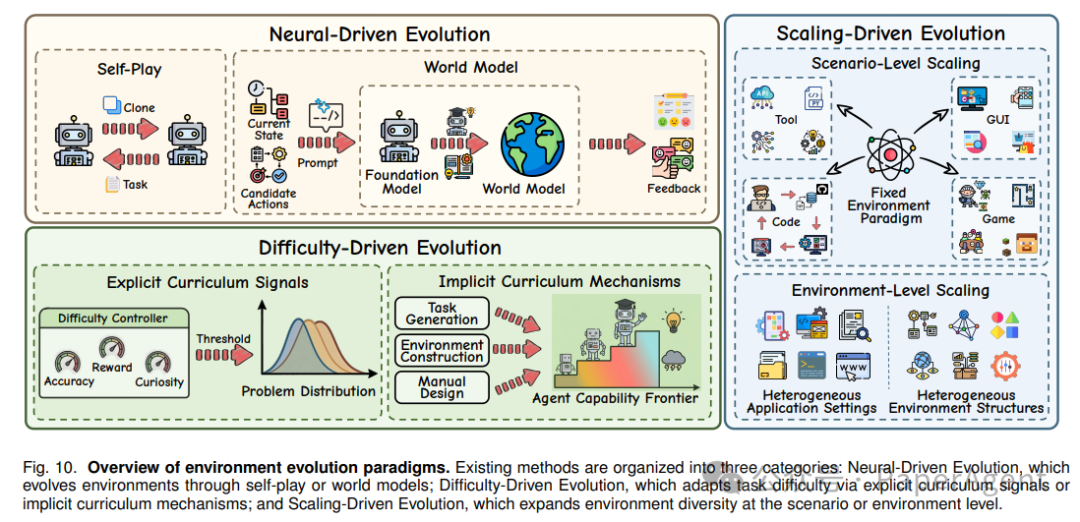
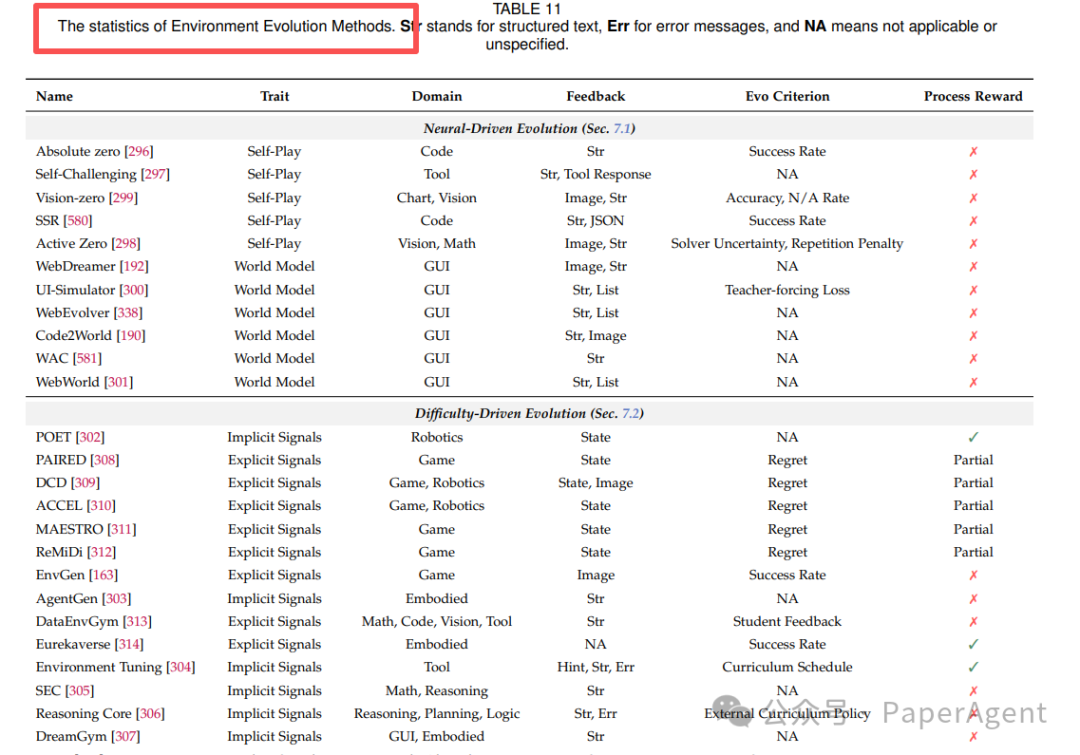
7.1 Neural-Driven Evolution(神经驱动)
- Self-Play:Agent 自身扮演提议者、解决者乃至深度挑战者,在左右互搏中生成新环境。
- World Model:学习一个世界模型来近似模拟环境动态,作为“世界模拟器”。
7.2 Difficulty-Driven Evolution(难度驱动)
- Explicit Curriculum:由准确率、遗憾值或好奇心等明确信号驱动,动态调整关卡的难易。
- Implicit Curriculum:难度并非显式指定,而是从任务生成的过程中自然涌现,逐步递增。
7.3 Scaling-Driven Evolution(规模驱动)
- Scenario-Level:在相同范式内,像细胞分裂一样增加任务、轨迹或网站的多样性。
- Environment-Level:跨领域地扩展环境的结构,从单一场景迈向异构的综合应用场。
最终洞察:Agentic Environment Engineering 绝不仅仅是在“给 Agent 造个游乐场”。它的本质,是在构建一套可进化、可验证、可扩展的认知基础设施。这正是我们从“训练一个模型”,迈向“培育一个真正的智能体”这一范式跃迁过程中,最坚实的核心支撑。
这片领域才刚刚拉开序幕,对智能体系统与环境协同进化的探索,必将深刻重塑我们构建人工智能的方式。
论文地址:Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
 发表于 前天 23:19
|
查看: 23|
回复: 0
发表于 前天 23:19
|
查看: 23|
回复: 0
