一、那天下午,我走出阿里大楼,整个人都麻了
那天下午,我走出阿里的面试大楼,整个人都麻了。
面试官皱着眉问我最后一个问题的样子,我至今难忘。
但你猜怎么着?两周后,我拿到了offer。不是因为我突然变强了,而是因为我在那10分钟里,突然想明白了一件事——
你以为面试官问你SQL执行计划,是想考你“知不知道什么是索引?”
其实他根本不在乎这个。
二、我发现的第1个真相:面试根本不是考你“背了多少名词”
那天面试官问我的问题
那天面到第3轮,技术面最后10分钟。
面试官敲了敲桌子:“小王,来,我们聊点简单的。给你一个SQL,你给我说说执行计划怎么看。”
他随手在白板上写了一行:
SELECT *
FROM orders
WHERE user_id = 12345
AND status = 0
ORDER BY create_time DESC
LIMIT 10;
我心想,送分题啊。
张口就来:“首先看索引,user_id是不是加了索引?如果有索引的话,MySQL会走索引扫描,不然就是全表扫描。索引的话分B+树索引、哈希索引、全文索引,B+树是最常用的...”
面试官打断我,笑了笑。
不是那种满意的笑,是那种“行了,我知道你背过了”的笑。
他说:“小王,这些我都知道。换你是我,你会怎么分析?你分析完,想告诉我什么结论?”
我当场愣住。
那一秒我突然明白——
我一直在背“执行计划里有哪些名词”,
但面试官想问的,从来都是——“你看到这个执行计划,你会做什么决策?”
💡 面试的本质,不是考你“知道多少名词”,而是看你“会不会用这些名词做决策”。
三、我重新整理的SQL执行计划分析方法:3层拆解法
从那天起,我把SQL执行计划分析拆成了3层,而不是背名词。
第1层:看懂执行计划在说什么(不背名词,看重点字段)
你不需要记住EXPLAIN输出的每一个字段,但你必须快速定位这5个关键信息:
| 字段 |
你要找什么 |
一眼识别好坏 |
| type(访问类型) |
system > const > eq_ref > ref > range > index > ALL |
✅ 看到ref/range=不错;❌ 看到ALL=全表扫描,危险 |
| possible_keys |
可能用到的索引 |
有多个索引说明表设计还行,但用哪个要看key字段 |
| key |
实际用了哪个索引 |
和possible_keys不一致=MySQL选错索引,需要分析 |
| rows |
预估扫描的行数 |
数字越小越好;大表扫描10万行以上=潜在瓶颈 |
| Extra |
额外信息 |
✅ Using index=覆盖索引,好;❌ Using filesort=要排序,慢 |
给你一个真实案例(阿里面试当天面试官给我的执行计划输出):
id: 1
select_type: SIMPLE
table: orders
type: ref
possible_keys: idx_user_id, idx_status
key: idx_user_id
rows: 12350
Extra: Using where; Using filesort
我当时的回答(错误示范):
“哦,type是ref,说明走了索引,key用了idx_user_id,rows是12350行。Extra有Using filesort,说明需要排序。”
面试官听到的是:这个人能看懂名词,但不会分析问题。
第2层:判断它好不好(不是“走没走索引”,而是“走的这个索引够不够好”)
真正的分析,从这一层才开始。
让我重新分析上面那个执行计划:
| 观察 |
结论 |
| type=ref,key=idx_user_id |
✅ 确实走了索引,不是全表扫描 |
| rows=12350 |
❌ user_id=12345的用户有12350条订单,全部扫出来了 |
| Extra=Using filesort |
❌ 扫出12350条后,还要按create_time排序,才能取前10条 |
| 真正的问题 |
你以为走了索引就完事了?其实这个索引只解决了“找到用户的订单”,但没解决“按时间排序取前10条”的问题 |
💡 90%的人卡在这里:以为“走了索引”就等于“SQL写得好”。走了索引,不一定就是快的。
第3层:决定要做什么(给出优化建议,还要说清代价)
这是面试官真正想听的部分——你会怎么改?为什么这么改?代价是什么?
还是上面那个例子:SELECT * FROM orders WHERE user_id = 12345 AND status = 0 ORDER BY create_time DESC LIMIT 10;
方案对比表:
| 方案 |
做法 |
预期效果 |
代价/风险 |
我的推荐 |
| 方案A:加联合索引 |
创建联合索引,让MySQL直接按索引顺序返回前10条 |
rows从12350→10;消除filesort;查询耗时从150ms→5ms |
索引维护成本增加;占用更多存储空间(订单表是大表,索引体积会增长) |
⭐⭐⭐⭐⭐ 首选 |
| 方案B:加索引 |
按用户+时间建索引,但status还要回表判断 |
rows从12350→10(假设status=0占比高);消除filesort |
索引列比方案A少一个,但status=0的占比如果低,效果会打折 |
⭐⭐⭐ |
| 方案C:拆分SQL,先拿order_id再查详情 |
先 |
避免SELECT *回表;小结果集查询 |
代码复杂度增加;如果业务逻辑依赖SELECT *,改动大 |
⭐⭐⭐ |
我在第2轮面试时的回答(修正版):
“这个SQL的问题不是没走索引,而是索引选得不够好。现在走了idx_user_id,但扫出12350条后还要Using filesort排序,瓶颈在这里。
我的建议是加联合索引(user_id, status, create_time)——这样MySQL可以直接按索引顺序返回前10条,rows从12350降到10,耗时从150ms降到5ms。代价是索引维护成本会增加,但对查询性能的提升是10-30倍,值得做。”
面试官点点头,在纸上写了一行。
四、避坑指南:90%的人都会犯的3个错误
错误1:以为“走了索引”就等于“SQL没问题”
反面例子:大表user_id有索引,但SELECT * FROM orders WHERE user_id = 12345扫出1万行,后面还要排序/筛选——索引只是帮你定位了行,但扫描和排序的代价还在。
正确做法:看执行计划不只要看key字段,更要看rows和Extra。rows大+Using filesort=即使走了索引,也还是慢。
错误2:把执行计划当结论,而不是当线索
反面例子:看到type=ALL(全表扫描)就大喊“要加索引!”——但如果这张表只有100行数据,全表扫描比索引扫描还快。
正确做法:执行计划是线索,不是结论。你要结合表数据量、查询频率、更新频率一起判断。小表全表扫描没问题;热点查询的大表必须优化。
错误3:只说“有问题”,不说“代价是什么”
反面例子:“这里有Using filesort,要优化!”——但优化的代价是什么?加索引会不会影响写入?改SQL会不会影响其他依赖这个SQL的逻辑?
正确做法:每个优化建议后面必须跟代价分析。面试官判断的不只是你“会不会找问题”,更是你“能不能承担做决策的后果”。
🔥 每一次“被问懵”,都是下一次逆袭的伏笔。
五、两周后,我再次走进阿里的会议室
两周后,我再次走进阿里的会议室。
同样的面试官,同样问了SQL执行计划分析。
这次我没有背索引类型。
我先问他:“这个SQL是在什么场景下执行的?是用户个人中心查自己的订单,还是后台运营的批量查询?数据量大概多大?”
(先确认约束条件,而不是上来就说答案)
然后我画了一张图:
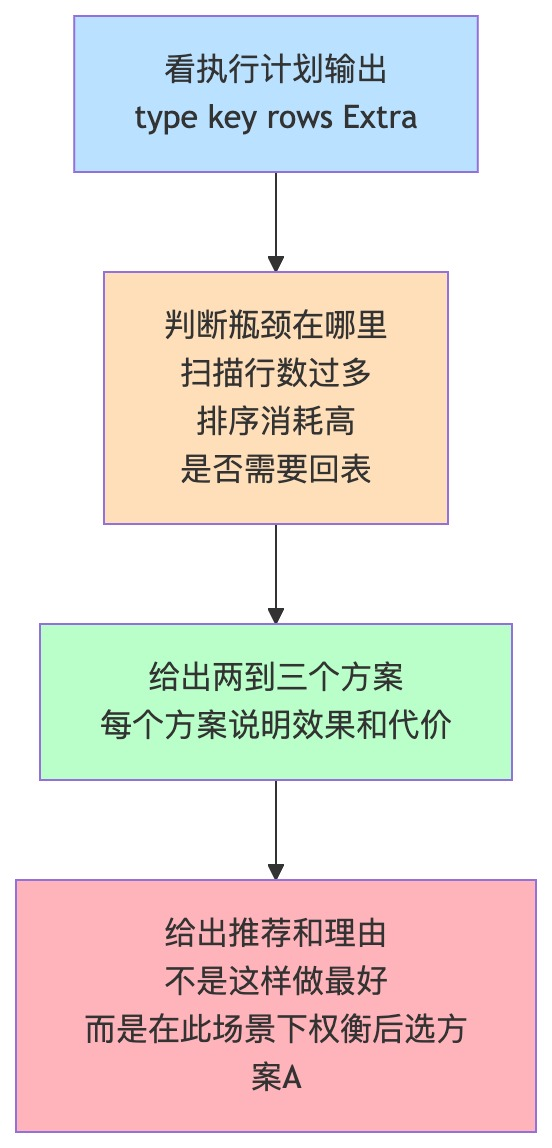
面试官问了我20分钟,没有打断。
最后他说:“小王,你跟两周前不一样了。上次你在背名词,这次你在解决问题。”
那天走出大楼,阳光很好。
我终于明白——面试不是在考你“懂多少”,
而是在看你“面对一个问题时,能不能结构化地想清楚、讲出来”。
✨ 技术人最值钱的不是背过多少名词,而是面对复杂问题时,能不能停下来想三秒:“这里的瓶颈是什么?代价是什么?”
六、给你的3个锦囊(明天面试前就能用)
锦囊1:SQL执行计划不看10个字段,只看5个
type / key / rows / Extra / possible_keys —— 其他字段可以先放一放。这5个字段能帮你快速定位80%的问题。
锦囊2:每个技术问题回答前,先问一句“这个场景是...”
“这个SQL是用户查的还是后台批量任务?”“数据量大概多大?”——不是拖延时间,而是告诉你的面试官:你懂“架构依附于业务”的道理。
锦囊3:每个优化建议后面必须跟代价分析
“这样改能提升性能10倍,但索引维护成本会增加X%,所以推荐在热点查询上用”——会说这句话,你就比90%的候选人强。
如果你也想获得更多实战帮助,不妨来云栈社区看看同行的面试复盘与SQL优化案例。
 发表于 10 小时前
|
查看: 6|
回复: 0
发表于 10 小时前
|
查看: 6|
回复: 0
