有小伙伴在面试里被问过这个问题。
“一张 Postgres 大表里有几千万行历史数据,要清掉一半,你会怎么做?”
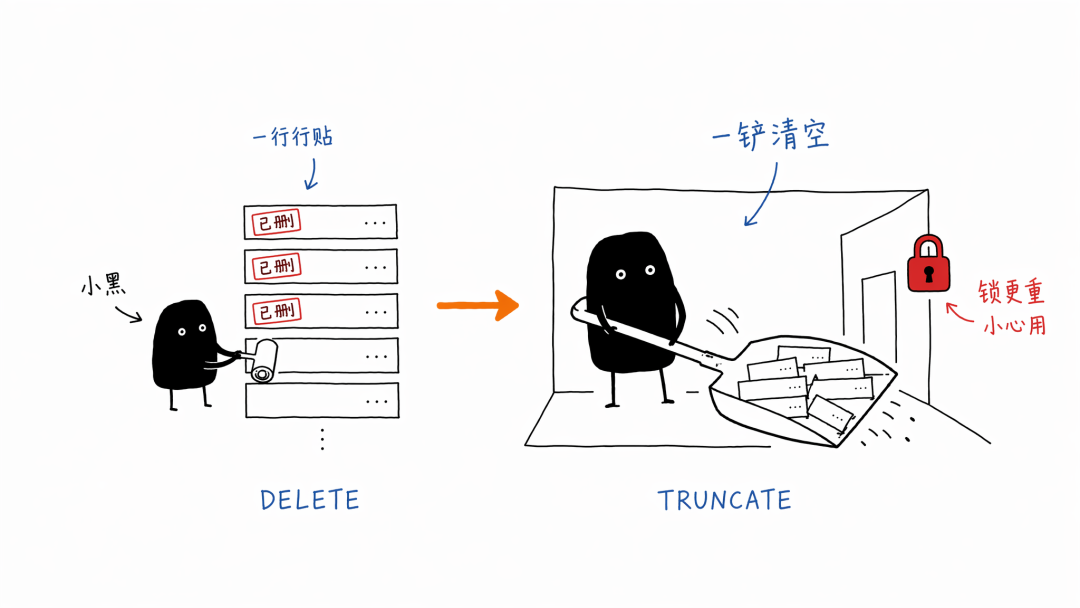
很多人的第一反应很自然,写个 DELETE。
DELETE FROM events
WHERE created_at < now() - interval '90 days';
看起来没毛病。数据多了,删掉。
但 Postgres 其实不是这么干的。
你以为 DELETE 是把旧数据搬走。
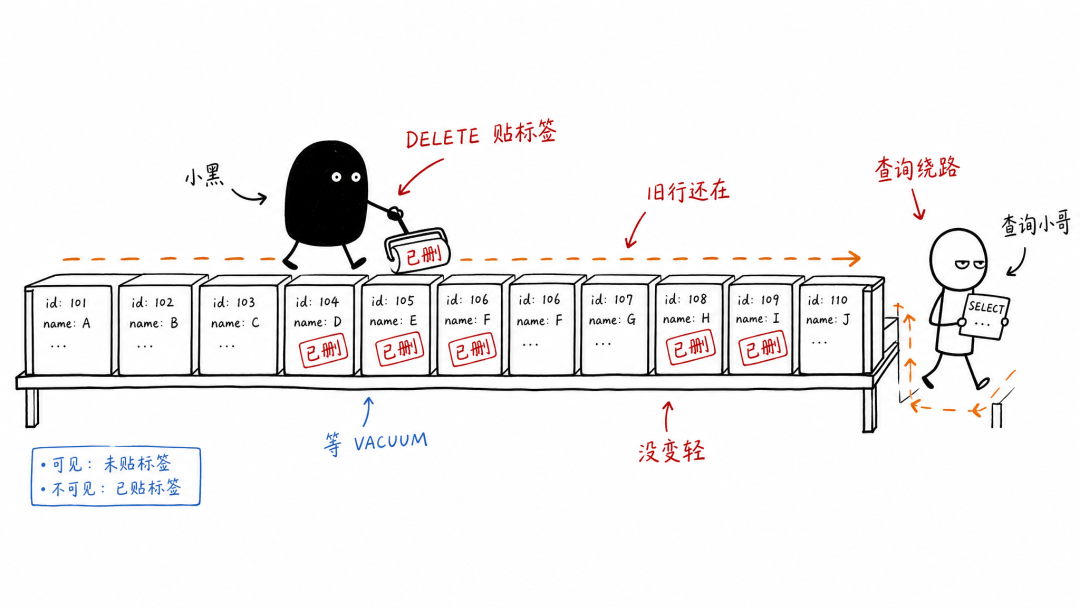
在很多场景里,它更像是给每一行贴一张纸条,写着「这行以后别给新查询看了」。至于这行占着的位置、相关索引、后面谁来清理,都是下一波工作。
所以大批量 DELETE 有时候不是把数据库变轻,而是先给数据库加了一堆活。
我们来画个图看一下。
先把第一个角色请出来。
我叫它,贴标签工人。
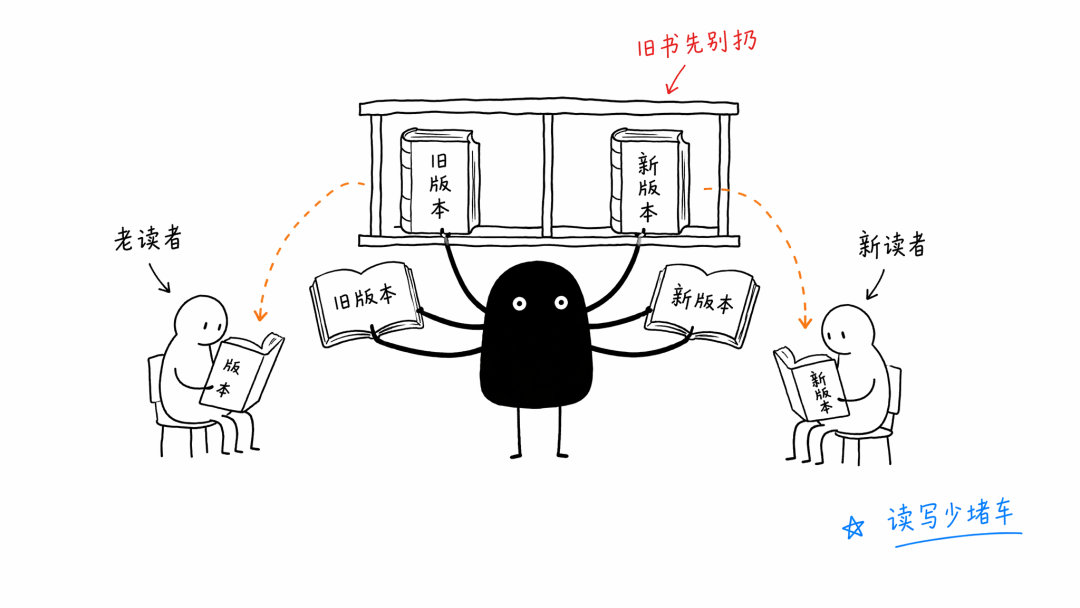
Postgres 用的是 MVCC,多版本并发控制。这个机制的好处很明显,读和写不容易互相堵住。
比如你在看一份报表,另一个人在更新数据。Postgres 不会粗暴地把你挡在门外,而是让你继续看你开始查询那一刻的版本。
这就像图书馆里有人正在改一本书,新读者看新版,老读者手里那本旧版还能继续看。大家互不干扰。
问题也在这里。
为了让老读者还能看到旧版本,Postgres 不能随手把旧行物理删掉。执行 DELETE 的时候,它要考虑还有没有事务可能看见这些行。
于是 DELETE 做的事情更像这样。
- 找到符合条件的行。
- 给这些行标上删除痕迹。
- 写 WAL,保证复制和恢复能跟上。
- 留下索引里指向旧行版本的线索。
- 把真正清理空间的活留给后面的
VACUUM。
你看,贴标签不是不干活。
它很忙。
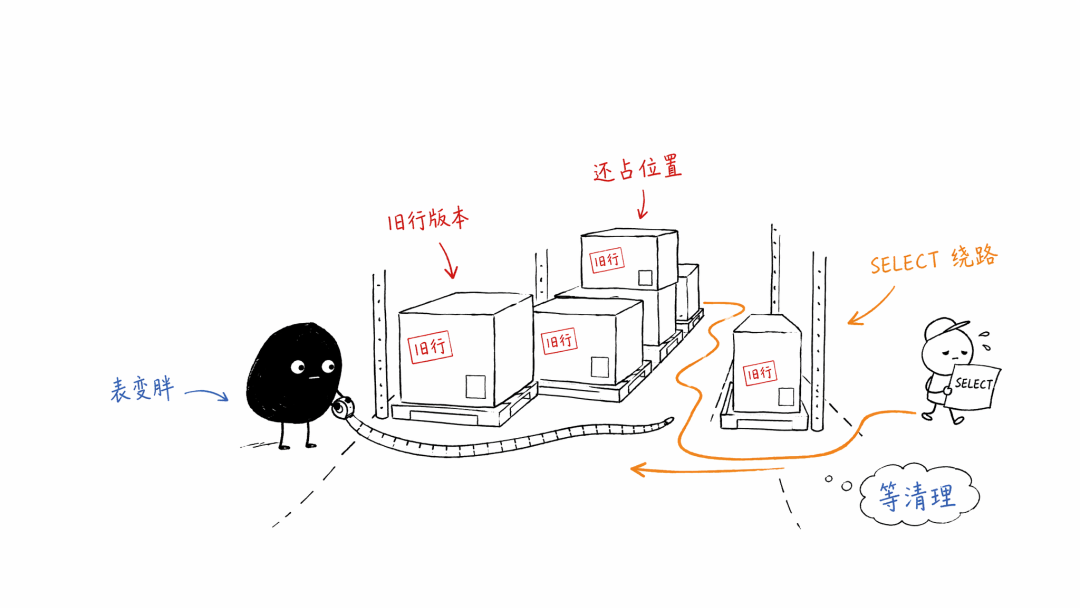
被贴过标签的旧行版本,常被叫作 dead tuple。
这个名字挺瘆人,但你可以把它理解成仓库里的旧纸箱。
纸箱上贴了「不用了」,可它还堆在货架上。新来的工人知道别拿它,但每次经过货架,眼睛还是得扫一下。
这就是为什么大量旧行版本会让数据库变忙。
查询时,Postgres 不是只看索引就完事。它还得判断这行对当前事务能不能看见。
索引里也会留下指向这些旧行版本的线索。旧线索越多,查询越容易绕路。你明明只想找一条有用的数据,路上却不断遇到旧纸箱。
更烦的是,普通 VACUUM 清理后,空间通常只是还给表内部复用,不一定马上还给操作系统。
所以你会看到一种很让人困惑的场景。
删了几千万行。
磁盘没怎么变小。
查询还变慢了。
这不是 Postgres 在装傻,而是你刚刚制造了一堆需要善后的旧行版本。
那谁来真正收拾这些旧纸箱?
轮到第三个角色,VACUUM。
我叫它清扫工。
“清扫工说,你们贴标签贴得痛快,最后都得我来收拾。”
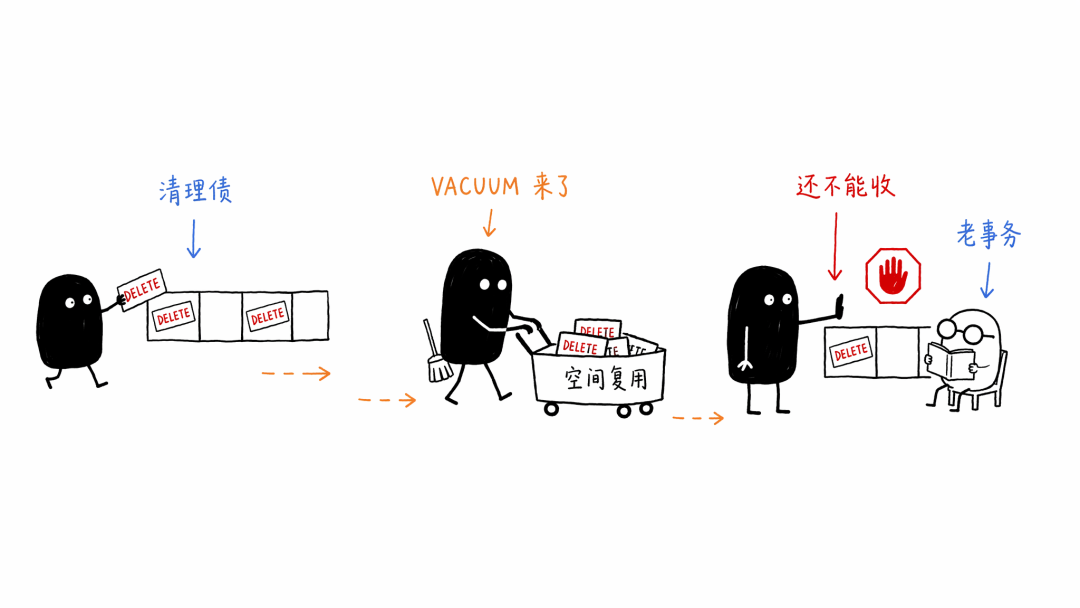
VACUUM 的工作,是把已经没人需要的旧行版本清掉,并把空间标记成可以复用。
听起来挺简单,其实也不轻松。
它要扫表,要处理索引,要维护 visibility map,还要顾着别影响线上业务太狠。如果你一下子删掉几千万行,清扫工就不是拿扫帚了,它得开着清洁车进来。
更糟糕的是,如果数据库里还有长事务没结束,清扫工可能看着一堆旧纸箱也不敢动。
因为它不知道有没有老读者还在看那本旧书。
这时旧行版本继续堆着,表越来越胖,索引越来越绕,读查询也跟着受罪。
所以大批量 DELETE 最容易制造三笔债。
第一笔,写入债。每一行删除都要记录和复制。
第二笔,清理债。旧行版本要等 VACUUM 慢慢收。
第三笔,查询债。清理前的读请求要不断绕过这些旧行版本。
这就是「越删越忙」的关键。
你以为自己在减负,其实是在给系统开了一张延期账单。
那能不能别贴标签,直接清空?
可以。
如果你要删的是整张表,Postgres 文档里也直接提醒,TRUNCATE 通常比无条件 DELETE 更快。
TRUNCATE 像什么?
像大铲子。
它不一个一个贴标签了,而是直接说,这个房间清空。
所以它快。
它不需要逐行扫描,不需要给每行制造旧行版本,也不需要后面再靠普通 VACUUM 收拾同一批空间。
但这把大铲子也有代价。
它会拿更重的锁。它也不是逐行触发 DELETE 那套语义。你不能把它当成一个万能替代品,在线上核心表上随便搞。
所以面试时如果你直接说「用 TRUNCATE」,面试官多半会追问。
“那只删 90 天前的数据怎么办?”
这就需要更好的设计。
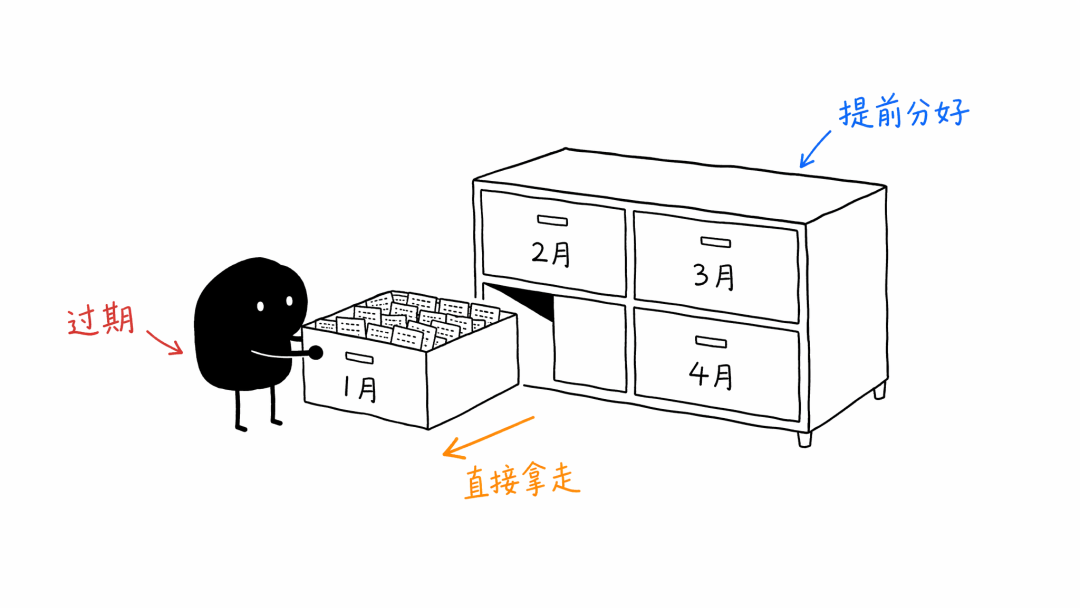
如果数据天然按时间过期,最舒服的方式不是每天去大表里挖旧行。
而是提前把它放进抽屉。
一月的数据放一月抽屉,二月的数据放二月抽屉,三月的数据放三月抽屉。
到了该清理的时候,不是一行一行删,而是把整个旧抽屉拿走。
这就是分区表的价值。
Postgres 官方文档里讲分区维护时也提到,移除旧数据最简单的方式就是 drop 掉不再需要的分区。它可以很快删掉几百万行,因为不用逐行删除。
快,不是因为 DROP TABLE 有什么魔法。
快是因为你提前把「将来要一起丢掉的数据」放到了一起。
就像搬家。你如果提前把旧书装进一个箱子,扔的时候抱走箱子就行。你如果把旧书散在每个房间、每个抽屉、每个床底,那你就只能满屋子翻。
数据库也是一样。
大批量删除慢,很多时候不是 SQL 写得不够骚。
是表设计一开始没给「未来怎么删」留门。
现在回到开头。
面试官问,大表要删一半历史数据,怎么做?
别只答一句 DELETE。
可以这样说。
如果只是少量删除,正常 DELETE 没问题。
如果是一次性误写入了大量脏数据,我会先评估锁窗口。如果能接受短暂停写,可以考虑建临时表保留要留下的数据,再 TRUNCATE 或重建表。不能接受停写,就要分批删,小事务慢慢跑,并观察 autovacuum、复制延迟和表膨胀。
如果是长期按时间清理历史数据,最好在设计阶段就做分区。让清理从「逐行贴标签」变成「拿走一个旧抽屉」。
最后补一句,VACUUM FULL 它会重写表,能真正缩小文件,但锁重、成本高,别把它当成万能药。
这题真正想考的不是你会不会写 DELETE。
它想看你知不知道一件事。
在 MVCC 数据库里,删除不是一个动作。
它是一条流水线。
贴标签,等事务,清旧行,维护索引,复用空间,必要时重写表。
你删得越大,流水线后面的活越多。
所以 Postgres 大批量 DELETE 反而越删越忙,不奇怪。
你只是按下了删除键。
数据库才刚开始加班。
更多 PostgreSQL 性能优化的深入讨论,欢迎访问 云栈社区。
 发表于 10 小时前
|
查看: 4|
回复: 0
发表于 10 小时前
|
查看: 4|
回复: 0
