
谷歌的急行军还在继续,但这一次,传来的消息似乎少了一些惊喜,多了一丝争议。
好消息是,Gemini 3.5 Pro 快发布了!
坏消息是,这次更新后的 Gemini 可能仍不敌 Claude 和 ChatGPT。
谷歌CEO承认:在Agentic Coding上确实落后了
5月,在谷歌的 I/O 旗舰开发者大会现场,观众席虽然座无虚席,但与会者普遍感到颇为失望。
“我知道大家已经迫不及待地想要体验 Gemini 3.5 Pro 了,”谷歌首席执行官劈材在台上说道,“再给我们一点时间,下个月我们就会把它交到大家手中。”

毫无疑问,谷歌正在悄然主导 AI 领域一个极其重要的类别——数学。Gemini 3.1 Deep Think 的最新推理更新,已巩固了其在高级数学证明领域的领先地位。谷歌上个月是毫无争议的赢家,而且他们正保持着这一势头。

在 DeepSeek 的测试中,Gemini 在世界知识上也独占鳌头。
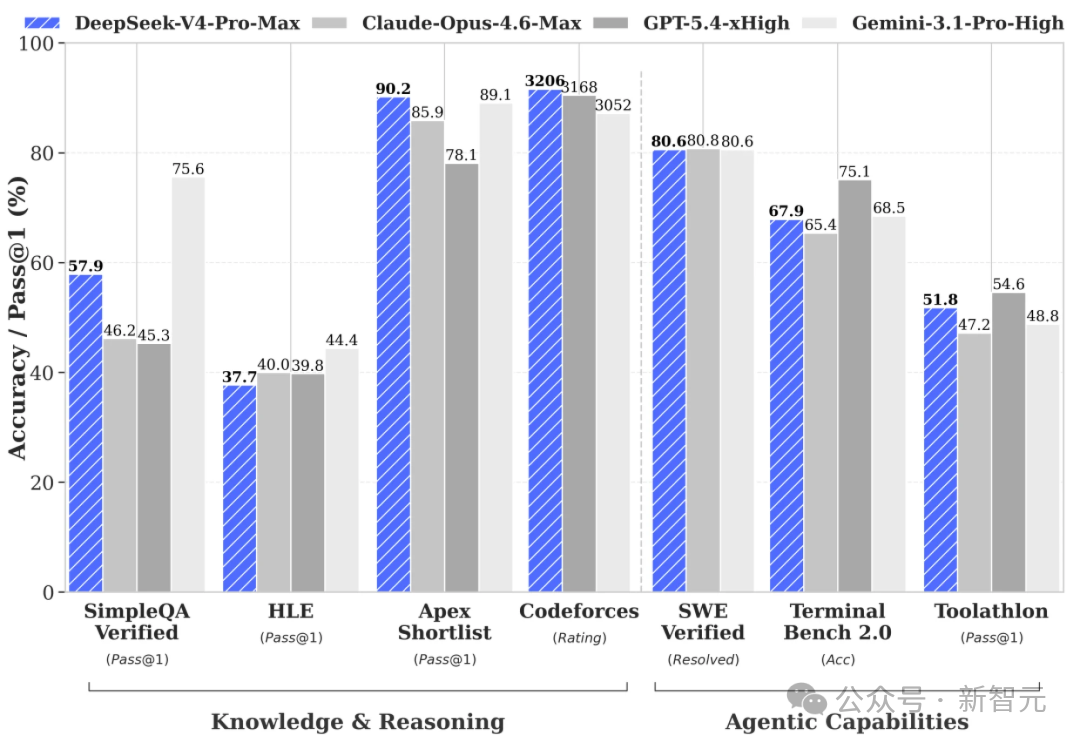
但古怪的是,Gemini 在编程中的体验却有些拉胯。

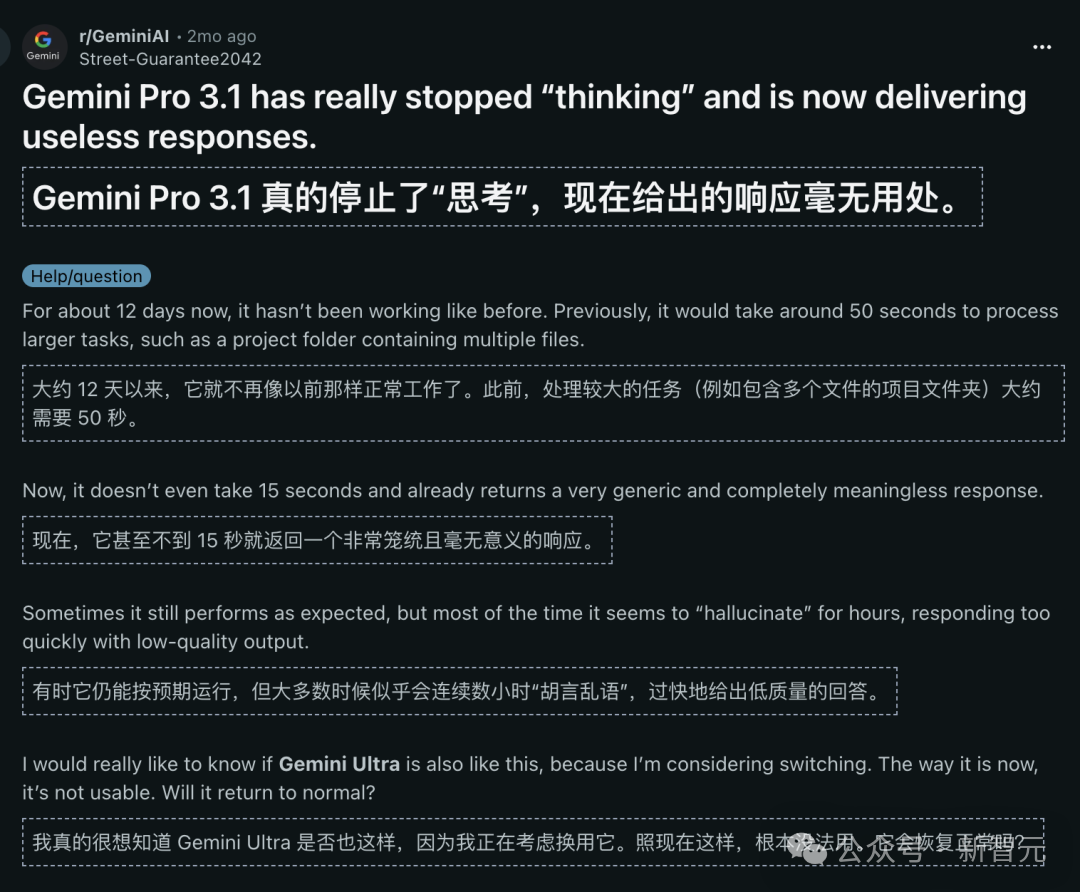
2个月前,Gemini Pro 3.1 被爆开始「摸鱼」,不深入思考,回应毫无用处。
这似乎是 Gemini 的老毛病——在 AI 编辑器中,Gemini 3 Pro 曾过于激进地自动重写代码,导致用户在审阅待接受代码时,仅因提问就被覆盖了原有工作;一旦拒绝修改,则会丢失已生成的全部代码。而竞品 Opus 4.6 表现则堪称完美:无需任何严格提示,只需一次项目上下文输入,即可进行只读分析并回答问题,全程尊重待处理状态,绝不覆盖差异代码。
这种「懒惰」,或许正是大家觉得 Gemini 用起来别扭的真正原因。毕竟,一个在世界知识上最强的模型,如果就是懒得调用工具,那就像一位博览群书的人,你问他最近发生了什么,他却耸耸肩说:“我没看今天的报纸”。
谷歌首席执行官劈材已坦承,在 AI 编程 领域,尤其是处理复杂软件任务方面,谷歌正落后于竞争对手。

尽管承认了差距,劈材听起来却并不怎么担心。他在内部表示:“我在公司内部从未见过这样的情况;(使用量)每周都在翻倍,人们确实在让这些模型投入到实际工作中。” 他还高调宣称,公司内部 75% 的新代码已由 AI 生成。
然而,谷歌内部员工却在内部论坛大量发布反 AI 表情包,嘲讽公司自研工具 Jetski 不可靠,制造的全是「垃圾代码」(slop)。




如果说他们大量分享的反 AI 表情包能说明什么问题的话,那就是谷歌员工已经受够了这项技术。
Gemini 3.5 Pro:有点令人失望
据最新独家爆料,谷歌目前正在紧锣密鼓地对即将发布的重磅大语言模型 Gemini 3.5 Pro 进行高强度迭代,在正式揭晓之前,内部预计还会测试更多的版本。然而,现阶段的测试反馈却多多少少有些让人失望。

目前最棘手、也最让全网关注的硬伤,依然是 Gemini 在面对长文本以及高复杂度任务时表现出的「消极怠工」现象。这种大模型的「偷懒」行为,已经成为谷歌在正式发布前必须全力攻克的头号顽疾。
当然,作为 3.5 时代的重磅产品,它并非毫无亮点。相比于上一代 Gemini 3.1 Pro,新模型在视觉能力、图像生成、SVG 生成质量以及多模态理解方面都展现出了更强劲的实力。
有爆料称,Gemini 3.5 Pro 上下文窗口将达到 2M token。
但与这些硬实力升级相伴而来的,是更严格的内容过滤机制与安全限制。
懒惰,已然成为 Gemini 3 Pro 最后的顽疾。
更现实的挑战在于成本——爆料明确指出,Gemini 3.5 Pro 的定价要比 Gemini 3.1 Pro 更加昂贵。
而 OpenAI 和 Anthropic,不仅模型更优,发布速度还在不断加快。


留给 Gemini 的时间,真的不多了。
AI深水区
谷歌 3.5 Pro 暴露出的这些问题,或许正是当前 AI 下半场的缩影。谷歌在 I/O 大会上的局促,以及 3.5 Pro 爆料出的困境,实际上宣告了整个 AGI 行业正式迈入了「边际效应递减」的深水区。靠堆砌参数、堆砌算力就能让 AI 实现指数级跨越的「黄金时代」,正在逐渐远去。随之而来的,是昂贵的算力成本、越来越窄的安全红线,以及模型自身在物理极限下的自我妥协。
参考资料:
https://archive.ph/BeICs
https://www.timesnownews.com/technology-science/google-ceo-sundar-pichai-admits-google-is-falling-behind-in-ai-coding-race-article-154420504
 发表于 5 小时前
|
查看: 4|
回复: 0
发表于 5 小时前
|
查看: 4|
回复: 0
