做研究最让人头疼的,其实不是论文多,而是两件事:读完就忘,笔记找不回来;每次问AI都得把研究方向从头交代一遍,它压根儿记不住你。
最近看到一个刚开源的小项目,叫 PaperFlow,最打动我的就是这点:它会学习,会记住你。

先把话说清楚。PaperFlow 是一个个性化论文推荐 + 阅读 + 报告的开源工具。它的目标用户很明确:博士生、研究者,以及那些长期要追前沿、且研究方向会慢慢演变的人。它还很新,关注度也不高,但在设计上花了不少心思,值得专门聊聊。
它想解决的,是个“动态”问题
市面上论文工具不少:Google Scholar关键词订阅、关联论文网站、把PDF丢给大模型提问。这些都能用,但有一个共同点——都是一次性的。你今天搜,它给你结果;明天再来,它还是从零开始,不知道你昨天看了啥、跳过了啥。
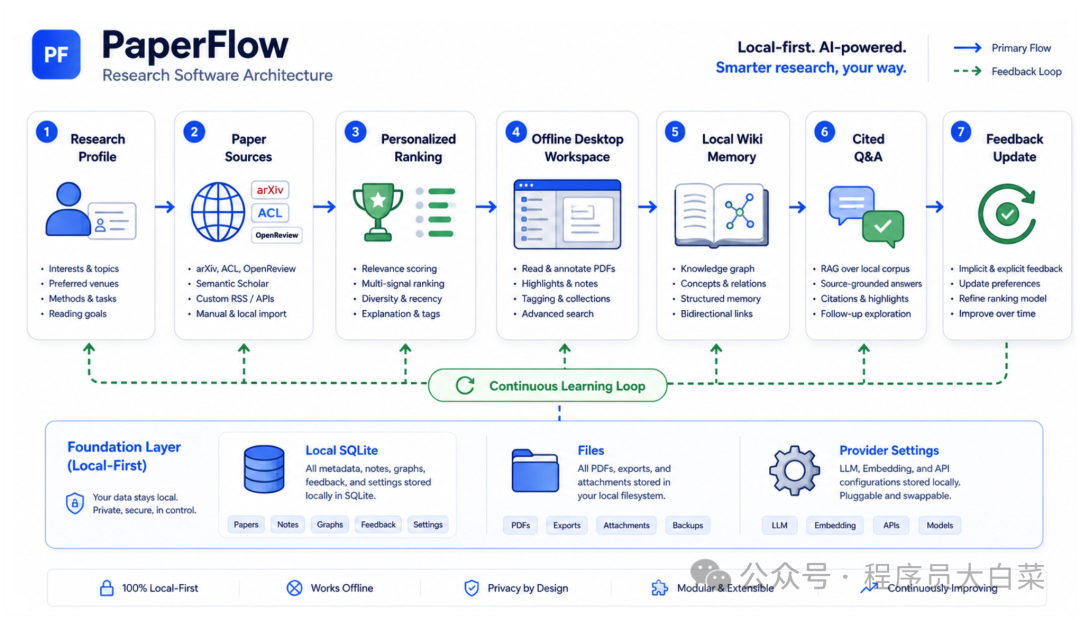
PaperFlow 的思路不一样。它把读论文变成一个会循环的过程:
建立你的画像 → 今天给你推什么 → 你挑了哪几篇读 → 收集你的反馈 → 明天推得更准
这个循环一直转下去,用得越久,它越懂你。
项目 README 里有句话一针见血:“论文推荐不是一次性的排序问题。真正的研究者问的是一个会变的问题——我今天该读什么,系统明天该怎么适应?” 研究这件事,偏偏是长期的、会变的。很多AI工具习惯了“一次调用出一个结果”,却忽略了这一点。
五个让我眼前一亮的设计
拆开来看,PaperFlow有几个普通工具没做、或者没做好的地方。
1. 它越用越懂你
这是它最核心的差异。
你每天收到一批推荐论文,标着不同相关度。你挑几篇读,跳过一些——这些动作都会被记下来,反过来更新你的画像。
有意思的是,它不是无差别记录。有些选择,会被它当成“更重要的信号”:
- 排在很后面:一篇论文推荐位很靠后,你还是点开读了,说明你是真感兴趣;
- 被它判低了:它本觉得这篇跟你不相关,结果你偏选了,这就是在纠正它,信号更强。
换句话说,它懂得区分“顺手选的”和“特地选的”。这比简单的“点击就算喜欢”,聪明了不止一点。
2. 一张PDF,就能读懂你的方向
刚上手怎么让它知道你研究啥?PaperFlow给了四种方式,可单用也可混着来:
- 写一句话:直接描述研究方向,最快;
- 丢几篇论文:把你写过的或最看重的几篇PDF丢进去;
- 给个Scholar主页:它自己去抓你的发表记录;
- 给个个人主页:同样自己解析。
几路信号交叉验证,它就能拼出一份你的学术画像:核心方向是什么,方法论上偏好哪类,哪些作者或主题是你必看的。这一步做好了,后面的推荐才有意义。
3. 它帮你把阅读攒成“私人知识库”
这是我最喜欢的一点。
读过的论文,最怕“读完就散了”。PaperFlow会把你每天的推送、读过的报告、论文间的引用关系,自动织成一张知识网,存在你本地。
然后你可以直接用大白话问它,比如:
我之前读过哪些关于 graph RAG 的内容?
它会从你的阅读历史里找答案,而且答案带出处——每句话都能点回是哪篇论文、哪份报告来的。如果你用 Obsidian 记笔记,还能一键把PDF、精读报告、每月总结都导出过去,自动按角色和月份归好类。从“读”到“存”这一段,基本不用手动整理了。
4. 多端同步,必读清单永远置顶
它有命令行、本地网页、桌面版,还接入了飞书机器人。不管从哪个端操作,更新的都是同一份画像——在实验室用网页选了几篇,回家路上在飞书回个编号,它都认得你。
还有个贴心的设计叫必读清单。你可以把最关注的几个作者、机构或关键词加进去,比如“某某教授的论文必须看”。之后只要命中,这篇论文会无条件出现在推送最前面,不会沉没。
反过来,如果你加的某个方向你连续很多天都跳过,它还会主动提醒:“这个方向你最近都不看了,要不要移除?”
5. 数据留在本地,成本也可控
很多AI工具默认走云端,你的数据得先上传。PaperFlow是本地优先的:画像、阅读记录、知识库,默认都存在你自己机器的数据库里,除非主动开飞书同步,否则不外传。
成本上也克制。它支持换不同模型运行,默认用一个轻量模型就能跑出不错的效果。如果你完全不想花 API 的钱,还能用本地模型免费跑,只是第一次要下载几个 G 的模型文件。即使 API key 都没配,也能先跑个离线 demo,确认环境装好再继续。
它到底靠不靠谱?
你可能会想:听起来很好,效果经得起检验吗?
这个项目做了一件很多工具不做的事——它自己造了一套公开的评测基准,叫 PaperFlow-Bench,放到了 HuggingFace 上,谁都能拿去跑。这套基准模拟了 24 个研究方向不同的研究者,跑了 50 天的论文流,涉及两万多篇真实论文、近五十万条推荐记录,还生成了三千多份阅读报告。它不靠“我感觉挺好”来糊弄,而是用数据说话。
更意外的是,它还把十几个主流大模型(从 GPT、Claude、Gemini 到国内的通义、Kimi、DeepSeek)拉来横向对比。结果挺有意思:
各模型推荐质量咬得很紧,差距很小;但调用消耗能差出好几倍。PaperFlow 默认选的那个轻量模型,效果已经接近最好的那几个。
这说明这个项目没在“堆大模型”上押宝,而是把功夫花在怎么用好模型上——把画像、反馈、排序这套机制做扎实,小模型也能打出接近顶级的效果。这个工程判断,我觉得很清醒。
适合谁,怎么上手
它适合长期要追论文、研究方向会慢慢变、愿意花点时间做一次配置的人。典型的就是博士生、博后、需要跨多个子领域的研究者。
如果只是偶尔看一两篇论文,直接 Google Scholar 就够了,没必要搭一套系统。另外它需要用命令行、配一个模型,对完全没碰过终端的人有点门槛。
想试的话,核心就五步,前三步一次性做完,后两步变成日常:
# 安装(完整版,带抓取和解析功能)
git clone https://github.com/OpenRaiser/PaperFlow.git
cd PaperFlow
pip install -e ".[all]"
# 初始化 + 建立你的画像(一句话描述方向即可)
paperflow init
paperflow profile --user-id me --natural-language "我研究 LLM agent 和科学发现"
# 每天的日常:推送 + 选读
paperflow daily --user-id me
paperflow read 1 3 7 --user-id me
不想敲命令,paperflow gui 打开一个本地网页,点点选选就行。配置上填个模型(API key 或选本地免费方案),数据全在本地。
最后,说点我的看法
往深了看一层,这个项目最值得说的,不只是一个好用的论文工具,而是它把一件很多人想做、却没做扎实的事做对了:让AI长期记住一个用户,并从用户的反馈里慢慢学习。
现在大部分AI产品,每次对话都是“失忆”的——今天聊完,明天重来。PaperFlow用一份长期存着的“用户画像”打破了这个循环:你每选一次、每跳过一次,都在让它更懂你。这套 “会进化的画像 + 把反馈喂回去” 的思路,对做AI应用的人来说,本身就是一个值得借鉴的设计。
当然,它还很年轻。功能不缺,但生态和文档的成熟度都还在早期,可能会遇到些边角问题得自己查。也正因为年轻,现在关注、甚至参与进去,成本最低。一个公开不到一个月、还很小众的项目,能把“会学习的个性化推荐”做成一套带公开评测的闭环系统,这份认真劲儿,值得被看见。
如果你正被论文淹没,又受够了工具记不住你,值得花一个下午把它跑起来试试。像PaperFlow这类注重本地化与隐私的开源实战项目,在当今的开发者社区中正获得越来越多的关注。
参考来源
 发表于 1 小时前
|
查看: 2|
回复: 0
发表于 1 小时前
|
查看: 2|
回复: 0
