前段时间有位朋友去面字节的 Agent 方向,二面时面试官问了一个他原以为不会出岔子的问题:“你的多 Agent 系统里,路由分类结果置信度很低的时候怎么办?”
他想了想,回答说选置信度最高的就行。面试官追问:“那如果最高分的那个也是错的呢?”他接着说那就选第二高的,或者加个阈值,低于多少就拒答。面试官笑了笑,说:“你这是拍脑袋,不是设计。生产环境靠的不是‘选哪个’,而是‘选错之后怎么兜住’。”
他当时觉得这个思路很有道理,但具体怎么“兜”,没答上来。回来后跟大伙讨论了一圈,发现多数人给的办法也差不多——加阈值、选次优、人工兜底——都属于“事后补救”,很少有人从系统设计层面去认真想过这件事。
说实话,我自己最初做的时候也没完全想透。路由系统看起来是多 Agent 架构里最“轻薄”的一层,可真上线以后,最先出问题的往往就是它。今天我们就来把 Agent 路由系统的设计原则、拓扑模式、常见坑和质量评估一次性讲清楚,全文较长,建议收藏后慢慢看。
Agent 路由系统是多智能体架构中的核心环节。它决定了一个请求最终由哪个能力单元处理、以什么方式处理、出错时又该如何去兜底。下面我将从设计原则、拓扑模式、避坑清单、质量评估再到落地代码,逐一拆解。
一、为什么路由系统会成为多智能体架构的瓶颈
单 Agent 系统其实不存在所谓“路由”问题,毕竟所有请求都打到同一套模型、同一批工具上。但当系统拆分成多个专精 Agent 后——比如代码、检索、数据分析、客服各司其职——路由层就变成了一个新的单点。
有几个问题值得关注。
首先,路由一旦搞错,下游 Agent 再强也救不回来,因为它根本没拿到该处理的任务。
其次,路由层的延迟会叠加到整条链路的首字节时间上。
再者,路由的可解释性,直接决定了系统出错后能不能被 debug。
所以,路由系统绝不是“加个 if-else 分发”那么简单。它需要被当作一个独立的、可评估、可降级、可观测的子系统来设计。
二、核心设计原则
1. 分层职责要清晰
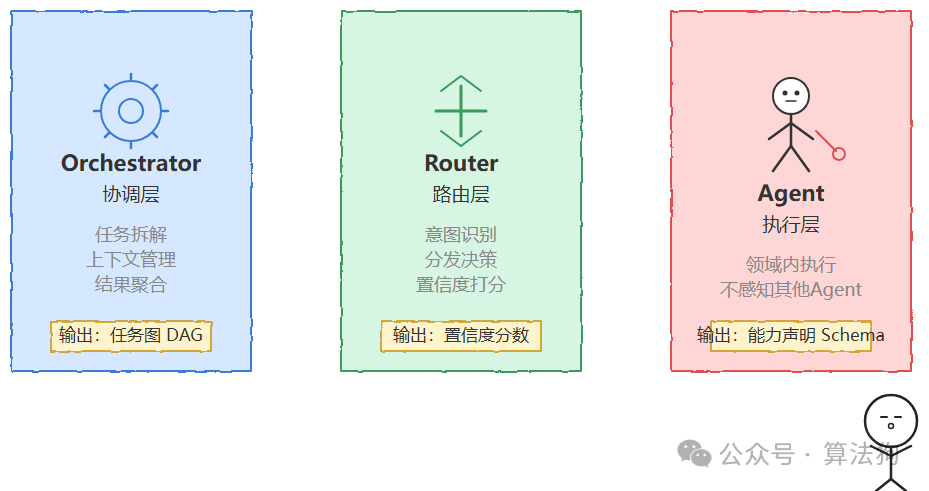
一套好的路由系统,至少应该分三层。每一层都要有明确的输入和输出契约(interface contract),而不是靠隐式约定来维持运转。
先看 Orchestrator(协调层)。它负责任务拆解和上下文管理:将复合任务分解为子任务,识别子任务间的依赖关系——哪些能并行、哪些必须串行——然后维护整个会话状态,最终聚合结果。有一点很重要:不要让它直接调工具,那是 Agent 的事。Orchestrator 的输出应该是一张任务图(DAG),而不是一段自然语言。
{
"session_id": "sess_8821",
"tasks": [
{"id": "t1", "goal": "查询用户最近的订单", "depends_on": []},
{"id": "t2", "goal": "生成退款建议", "depends_on": ["t1"]}
]
}
再看 Router(路由层)。它负责意图识别和分发决策。输入是一个子任务加上必要的上下文摘要,输出就是“交给哪个 Agent”。路由的一个关键点是置信度——不要只返回一个选择,要带着分数一起返回,比如 {agent: "code", confidence: 0.91}。当置信度低于阈值时,就得走降级或人工干预。Router 应该是无状态的:同一个输入,任何时候调用都应得到一致的结果,或者至少能解释为什么不一致。状态管理是 Orchestrator 的职责。
最后是 Agent(执行层)。各个 Agent 各司其职,只负责自己领域内的执行,不感知其他 Agent 的存在。它对外暴露的应该是一份“能力声明”(capability schema),而不是一个黑盒:
{
"agent_id": "code_agent",
"description": "处理代码生成、调试、代码审查、单元测试编写",
"input_schema": {"task": "string", "context_files": "array<string>"},
"tools_allowlist": ["read_file", "write_file", "run_tests"],
"cost_tier": "medium",
"avg_latency_ms": 4200
}
这份声明既为 Router 做语义匹配所用,也为安全边界提供依据。关于安全边界,后面“坑 10”处会详细展开。
2. 路由策略的几种主流模式
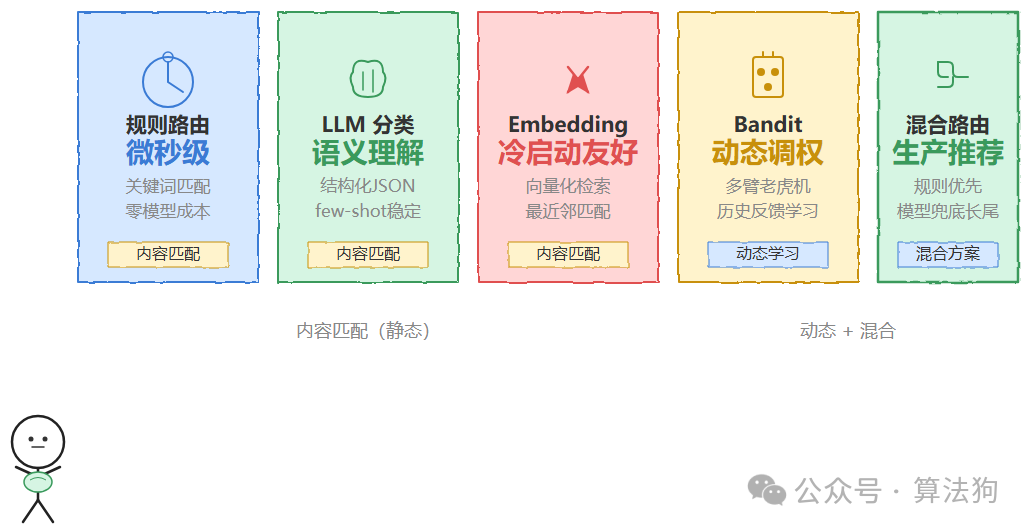
第一种:关键词加规则路由。 速度最快,可达微秒级,可解释性极强,零模型调用成本。适合意图边界清晰的场景,比如客服系统里“退款”“发票”“物流”这类高频明确意图。实现上通常是一棵决策树或一组正则加关键词表:
RULES = [
(r"退款|退货|发票", "billing_agent"),
(r"SQL|查询.*数据|报表", "data_agent"),
(r"bug|报错|代码|函数", "code_agent"),
]
def rule_route(text):
for pattern, agent in RULES:
if re.search(pattern, text):
return {"agent": agent, "confidence": 1.0, "method": "rule"}
return None
不过,维护成本会随规则数量增长而指数上升。规则之间互相冲突、覆盖不到长尾表达,也没法处理“我想查一下上个月的退款金额趋势”这种交叉领域的复合意图。
第二种:LLM 分类路由。 让模型输出结构化 JSON 来判别意图,适合语义模糊、长尾表达多的输入。关键在于 prompt 里要给每个 Agent 写清楚“适合处理哪类任务、不适合处理哪类任务”——负例和正例同样重要,并要求输出置信度与理由。建议用 few-shot 而非纯零样本,边界 case 的示例比规则描述更能稳定模型行为。
第三种:Embedding 相似度路由。 将每个 Agent 的能力描述向量化存入向量库,输入 query 也向量化,做最近邻检索。这种方式在人工智能领域应用较多。
agent_vecs = {aid: embed(desc) for aid, desc in agent_descriptions.items()}
def embedding_route(query, threshold=0.72):
qv = embed(query)
best_agent, best_score = max(
((aid, cosine_sim(qv, v)) for aid, v in agent_vecs.items()),
key=lambda x: x[1]
)
if best_score < threshold:
return {"agent": "general_agent", "confidence": best_score, "method": "fallback"}
return {"agent": best_agent, "confidence": best_score, "method": "embedding"}
冷启动很友好——新增 Agent 只需写一段能力描述、生成向量插入索引即可,无须改动任何 prompt 或规则表。缺点是对复合意图、否定语义不敏感,比如用户说“不要用 SQL,直接给我看图”就处理不好,而且阈值需要持续调优。
第四种:性能反馈路由(Bandit 路由)。 前面三种都是“内容匹配”,但在实际生产中,同一类任务可能有多个 Agent 都能处理,谁更擅长要靠历史数据学出来。可用多臂老虎机(如 Thompson Sampling 或 UCB),根据各 Agent 历史成功率、用户满意度反馈来动态调整路由权重,在“探索新 Agent 能力”与“利用已知最优 Agent”之间寻求平衡。不过收敛较慢,通常作为前几种方法之上的动态调权层。
第五种:混合路由,也是生产环境推荐的做法。 规则优先拦截意图边界清晰的高频请求,通常能覆盖 60%–70% 的流量,零延迟、零成本;不确定的走 LLM 分类或 Embedding 检索;Bandit 权重在多个候选 Agent 之间做最终裁决;超低置信度的统一走人工兜底或澄清话术。这也是目前业界对“路由”与“分发”模式的共识——确定性规则负责能预判的部分,模型判断负责处理边界模糊的长尾。
3. 路由拓扑:不止“选一个 Agent”这么简单
很多人把路由简化成“从 N 个 Agent 里选 1 个”,但在实际生产系统中,至少存在五种拓扑。搞混了它们,会直接导致延迟、成本与失败模式的误判。
| 拓扑模式 |
说明 |
典型场景 |
| Pipeline(顺序链) |
固定顺序的 Agent 流水线,A 的输出是 B 的输入 |
KYC 审核、文档三段式审批 |
| Supervisor(层级监督) |
一个路由或监督 Agent 在顶层做分发、收敛、决定升级或重试 |
客服 triage、最主流的生产默认模式 |
| Handoff(移交) |
Agent 之间直接把控制权和上下文整体转交给下一个 Agent,转交后原 Agent 不再参与 |
客服从通用坐席转接到专科坐席 |
| Fan-out/Fan-in(并行分发加聚合) |
同一任务并行发给多个 Agent,结果汇总后再处理 |
同时检索加查数据库加调用计算工具 |
| Swarm/Debate(对等协作或多角度评议) |
多个 Agent 平级协作或互相评议,由裁判节点合并结论 |
多视角内容审核、复杂决策的交叉验证 |
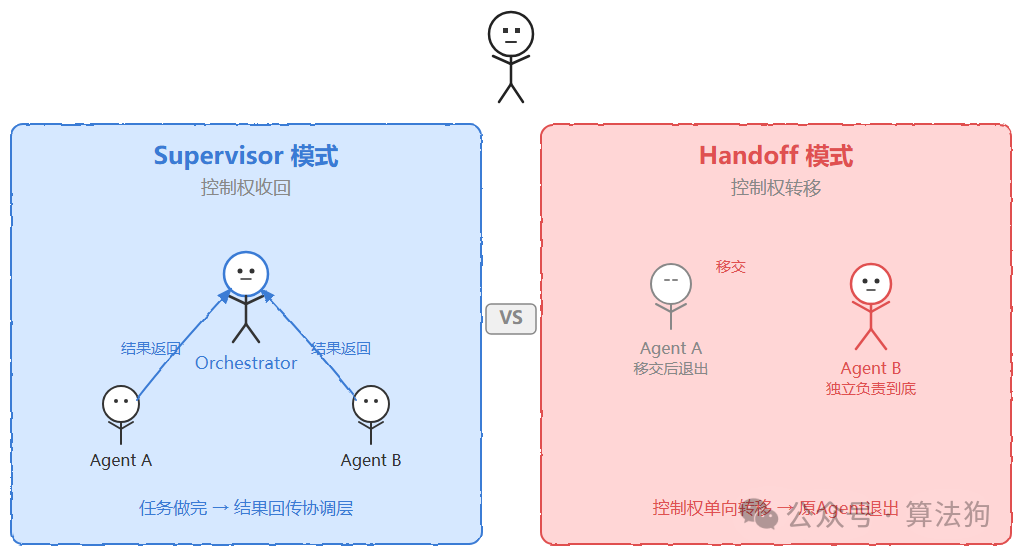
Supervisor 与 Handoff 的核心区别在于控制权是否收回。Supervisor 模式下,任务做完结果要“返回”给协调层;Handoff 模式下控制权是单向转移的,移交后原 Agent 彻底退出,新 Agent 独立负责到底。选错拓扑的常见后果是什么?该用 Handoff 的场景用了 Supervisor,协调层在不必要的环节反复中转上下文,白白增加延迟。
三、常见坑和避法
坑 1:路由层做了太多业务逻辑
Router 一旦开始判别“这个代码问题是 bug 修复还是新功能”,就失控了。Router 的职责只是分发,业务细分是 Agent 自己的事。保持路由层的 prompt 简短,单个 Agent 描述控制在 1 到 2 句话。超过这个长度,往往说明这个 Agent 的职责本身该拆分了。
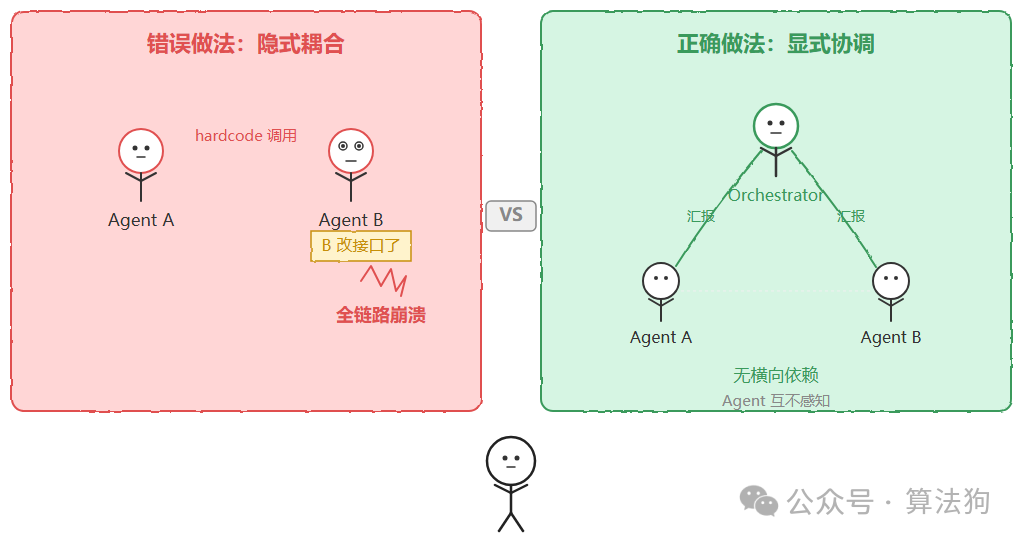
坑 2:Agent 之间直接调用形成隐式耦合
Agent A 内部 hardcode 调用 Agent B,一旦 B 改接口就全链路崩溃,而且这种耦合在测试环境很难暴露,通常上线才炸。正确做法是所有跨 Agent 调用都走 Orchestrator 或消息总线。Agent 只向上汇报结果,不横向感知彼此。如果确实需要“A 完成后必须紧接着 B”,应在 Orchestrator 的任务图里显式声明依赖边,而不是在 A 的代码里直接 import 或 call B。
坑 3:没有置信度降级机制
这正是面试官追问的核心。路由分类的置信度低于阈值时——经验值常取 0.6–0.7,需按场景标定——系统应触发澄清、兜底到通用 Agent 或发出人工干预信号。直接选最高分的 Agent 会在边界 case 静默出错,而且这种错误往往不报异常、不进日志告警,只体现为“用户体验变差但你不知道为什么”。这是最棘手的一类问题。
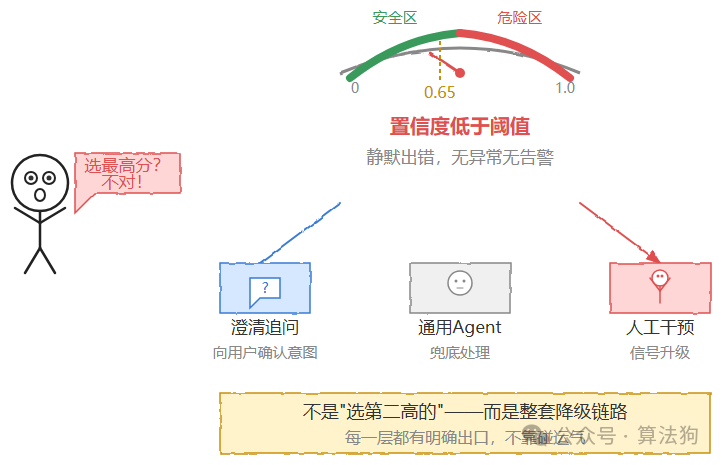
面试官说的“降级机制”到底是什么?不是“选第二高的”,而是一整条链路:LLM 分类超时退回规则路由、规则没命中路由到 general_agent、连续低置信度触发人工干预。每一层都有明确出口,不靠“换一个候选”去碰运气。
坑 4:上下文在路由层丢失
多轮对话中,Router 如果每次只拿到当前这一句用户输入,会丢失上文,“那这个呢”这类指代消解失败的请求大概率被错误分类。解决方案是 Orchestrator 维护 session 上下文,每次路由时把摘要一起打包给 Router——注意不是全量历史,避免 prompt 过长拖慢速度。Router 本身不应存储状态。
坑 5:工具调用没有幂等保护
Agent 重试时可能重复执行写操作,比如发邮件、下订单、扣款。所有工具调用需要带 request_id,工具层做幂等校验——同一个 request_id 的重复调用直接返回首次结果,不再重新执行。这虽不是路由层本身的问题,但路由层设计重试策略时必须考虑此约束,否则“路由重试”就会变成“业务重复执行”。这类典型的后端 & 架构问题,在设计高可用系统时尤为重要。
坑 6:同步调用阻塞整条链
多个独立子任务串行执行会让延迟线性叠加。能并发的任务——比如同时搜索加查数据库——要在 Orchestrator 层用 Fan-out 拓扑并发发出,gather 结果后再合并。实际经验是:先画出任务依赖图,只有真正存在数据依赖的边才需要串行,没有依赖关系的任务默认应并行。
坑 7:Agent 能力描述写得模糊,路由长期漂移
像“general_agent:处理其他任务”这种兜底描述写多了,Router 会逐渐倾向于把不确定的请求都丢给它,导致专精 Agent 利用率走低,general_agent 越来越臃肿。能力描述应既写清楚“擅长什么”,也写清楚“不擅长什么、与谁的边界在哪”,并随 Agent 实际能力变化同步更新——能力声明是活文档,不是一成不变的静态配置。
坑 8:路由决策没有可观测性,出错了无法复盘
线上用户反馈“问题没得到正确处理”,如果路由层没有记录每次决策的输入、候选打分、最终选择与理由,就完全没法复盘。最低限度要给每次路由打日志,包含 trace_id、原始输入摘要、各 Agent 候选分数、最终选择、路由方法、是否触发降级。这套日志同时也是后续路由质量评估的原始数据来源。
坑 9:路由层本身是单点故障,没有降级链路
如果 Router 调用的分类模型超时或限流了,整个系统入口就瘫痪了。生产系统的路由层必须有显式的降级链路:LLM 分类超时就退回规则路由,规则也没命中就路由到 general_agent,而不是直接报错。路由层的可用性目标通常应高于任何一个下游 Agent,因为它是所有流量的必经之路。
坑 10:Agent 之间没有权限隔离,安全边界缺失
如果每个 Agent 都能调用全部工具——包括发邮件、改数据库、执行代码——一旦某个 Agent 被路由到不该处理的任务,或被 prompt injection 误导,影响面是系统级别的。每个 Agent 应该只被授予其能力声明里列出的工具白名单,这就是最小权限原则。路由层在分发任务时也应校验“该任务所需权限是否在目标 Agent 的授权范围内”,而不是无条件信任分类结果。
四、路由质量怎么评估
路由系统上线后,不能只靠“感觉准不准”,需要量化指标。
第一,按 Agent 维度的精确率与召回率。 每个 Agent 类别单独计算,不要只看整体准确率。整体 90% 准确率可能掩盖某个低频但关键的 Agent 召回率只有 50% 的事实。
第二,混淆矩阵。 看看哪两个 Agent 之间最容易被混淆,这往往直接指向能力描述不够清晰或边界重叠的问题。
第三,置信度校准曲线。 模型给出 0.8 置信度的预测,实际准确率是否也接近 80%?如果置信度系统性偏高或偏低,降级阈值就是错的,需要重新标定。
第四,离线评测集加人工标注闭环。 定期从线上日志抽样,人工标注“正确的 Agent 应该是谁”,回灌成离线评测集。每次改动路由 prompt 或规则前,先跑这个评测集做回归测试,避免“改好了 A 场景却悄悄改坏了 B 场景”。
第五,延迟与成本分布。 规则路由几乎零成本零延迟,LLM 分类路由每次都有 token 成本和网络延迟。混合路由系统要监控“走到了哪一层”的分布。如果大量请求都落到最贵的 LLM 分类兜底层,说明规则层或 Embedding 层的覆盖率需要提升。
五、一个更完整的路由 prompt 模板
相比只给 Agent 列表的简单模板,生产环境的路由 prompt 通常需加入边界说明和 few-shot 示例来稳定边界 case 的判断:
你是一个意图路由器。根据用户输入,从以下 Agent 中选择最合适的一个。
- code_agent:处理代码生成、调试、代码审查、单元测试。
不处理:纯数据查询、不涉及代码的报表需求(应路由到 data_agent)。
- search_agent:处理联网查询、文档检索、事实核查。
不处理:需要执行计算或访问内部数据库的任务。
- data_agent:处理数据分析、SQL 查询、图表生成。
不处理:代码层面的调试,即使涉及 SQL 代码本身的语法错误。
- general_agent:处理闲聊、任务规划、以及不属于以上任何一类的请求。
参考示例:
输入:"帮我看看这段 Python 为什么报 KeyError" → code_agent(涉及代码调试)
输入:"上个月各地区销售额对比一下,画个图" → data_agent(数据分析+可视化,非代码任务本身)
输入:"这个 SQL 语句报语法错误,帮我改一下" → code_agent(虽然涉及 SQL,但本质是调试代码语法,不是数据分析需求)
输出 JSON,不要输出任何额外文字:
{"agent": "<agent_name>", "confidence": <0-1>, "reason": "<一句话,说明为什么不是其他候选>"}
用户输入:{input}
会话摘要(如有):{context_summary}
置信度低于 0.65 时,在 Orchestrator 里拦截,触发澄清流程——向用户追问一句,而不是直接选最高分硬路由。连续两次澄清仍低置信度,则转人工或转 general_agent,同时记录为待复盘 case。
六、一个可运行的混合路由示例(伪代码)
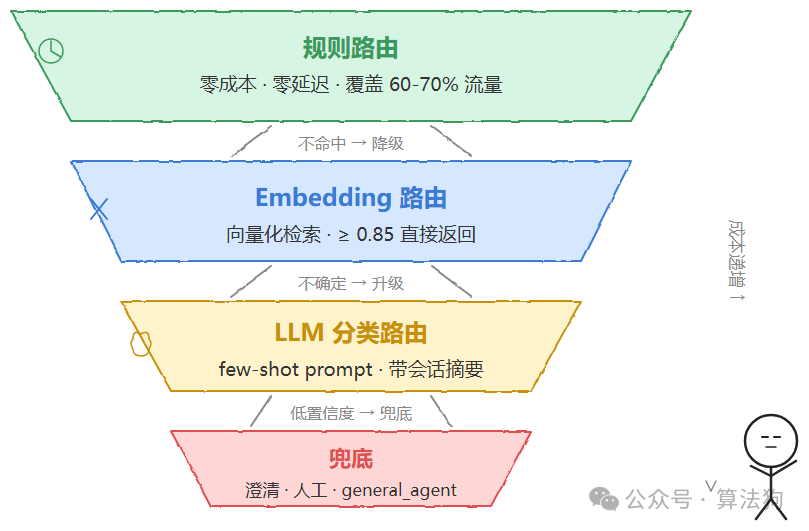
把前文讲的规则、降级、日志串起来,大致是这样一个流程:
def route(query: str, session_ctx: dict) -> dict:
trace_id = new_trace_id()
# 1. 规则路由优先,零成本零延迟
result = rule_route(query)
if result:
log_routing_decision(trace_id, query, result)
return result
# 2. Embedding 路由,召回候选加打分
result = embedding_route(query, threshold=0.72)
if result["confidence"] >= 0.85:
log_routing_decision(trace_id, query, result)
return result
# 3. 候选不够确定,升级到 LLM 分类路由(带 few-shot prompt 加会话摘要)
try:
result = llm_classify_route(query, context_summary=session_ctx.get("summary"))
except TimeoutError:
# 9号坑:路由层自身的降级链路
result = {"agent": "general_agent", "confidence": 0.0, "method": "fallback_timeout"}
# 4. 置信度阈值兜底
if result["confidence"] < 0.65:
result = trigger_clarification_or_human_escalation(query, session_ctx)
log_routing_decision(trace_id, query, result)
return result
这个骨架的核心思路是:便宜的方法先尝试,贵的方法只在必要时兜底。每一层都有明确的降级出口,且每一次决策都落日志,供后续质量评估和 A/B 测试使用。
总结
一句话概括:路由层要薄,Orchestrator 要聪明,Agent 要专一,工具调用要防御性编程,每一次决策都要可观测、可降级、可复盘。
具体展开来说:
三层职责——Orchestrator、Router、Agent——要靠清晰的接口契约分开,不要靠“大家心照不宣”。
路由策略按场景混用:规则兜底高频确定意图,LLM 和 Embedding 处理长尾模糊意图,Bandit 做动态调权。别迷信单一方法。
拓扑模式——Pipeline、Supervisor、Handoff、Fan-out、Swarm——要按任务依赖和控制权转移方式去选,选错会直接影响延迟和失败模式。
十个坑里,半数与“边界不清”有关——职责越界、能力描述模糊、权限未隔离;另一半与“缺乏防御性设计”有关——无降级、无幂等、无可观测性。
路由系统上线后,要持续用量化指标做回归评估:精确率、召回率、置信度校准、延迟成本分布,不要只凭线上反馈“感觉”去调整。
哪一层越界做了不属于自己的事,或者哪一层缺了降级兜底,那里就会成为系统的脆弱点。
在云栈社区,我们始终认为,越是看起来“简单”的基础组件,越值得用系统化的视角去审视和设计——这正是技术人从“能用”走向“可靠”的关键一步。
 发表于 昨天 19:19
|
查看: 6|
回复: 0
发表于 昨天 19:19
|
查看: 6|
回复: 0
