如果你到现在还没用过 Codex,那你很可能错过了目前世界上最强大的 AI Agent。注意,这里说的是 Agent,而不仅仅是 Coding Agent。Codex 的能力远不止写代码,它同样是你学习、工作中的超级助手。
后续我计划写一系列文章,聊聊如何用 Codex 重构我们的编程、工作和学习方式。今天是这个系列的第一篇:如何将 Codex 和 Hyperframes 结合,快速打造一个 NoteBookLM 的平替方案。
在学习一个新概念时,如果只是面对枯燥、非结构化的文字,大脑的吸收效率往往很低。但如果把学习内容转化成结构化、可视化的视频,效果会大幅提升。有了 Codex,你现在每次只需大约 5 分钟,就能轻松生成下面这类知识讲解视频:
接下来,我们一步步拆解具体的操作流程。
步骤一:搞定视频生成框架 —— Hyperframes
演示视频里的幻灯片页面、动效,全部是通过 HeyGen 的 Hyperframes 生成的。你首先要做的,就是在 Codex 里搜索并安装 Hyperframes 插件。
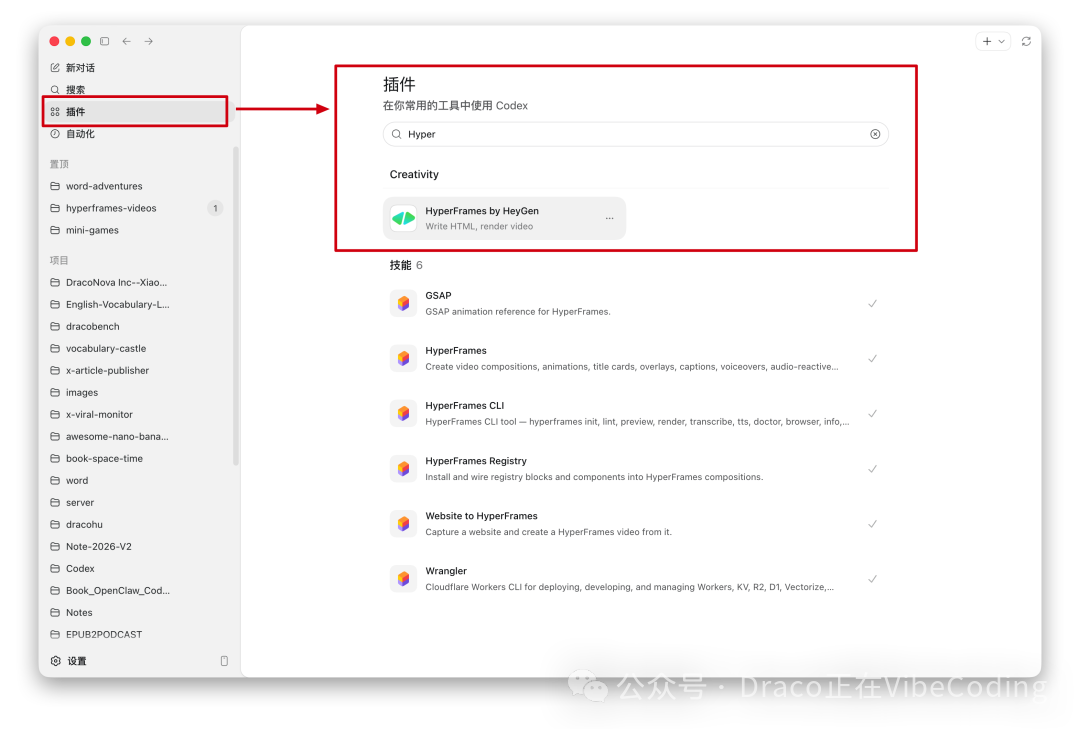
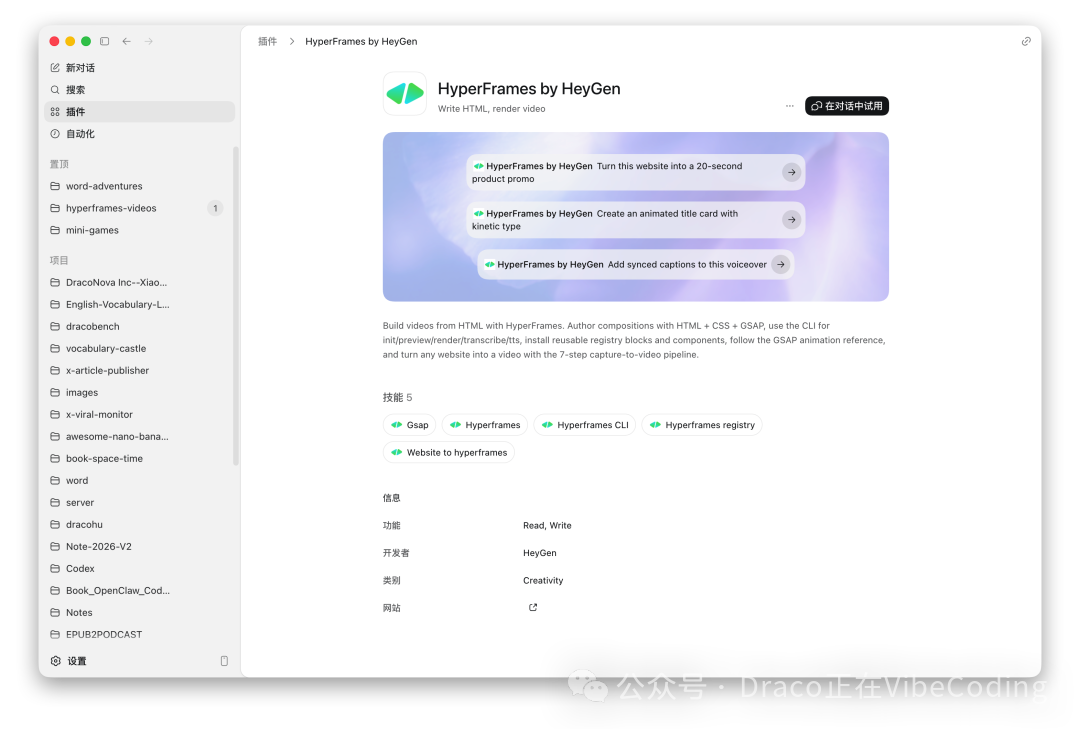
我强烈建议你现在就让 Codex 用 Hyperframes 针对某个知识点生成一条视频来感受一下。可以先尝试做一条 1 分钟以内的短片,Codex 大概 3 分钟就能搞定。
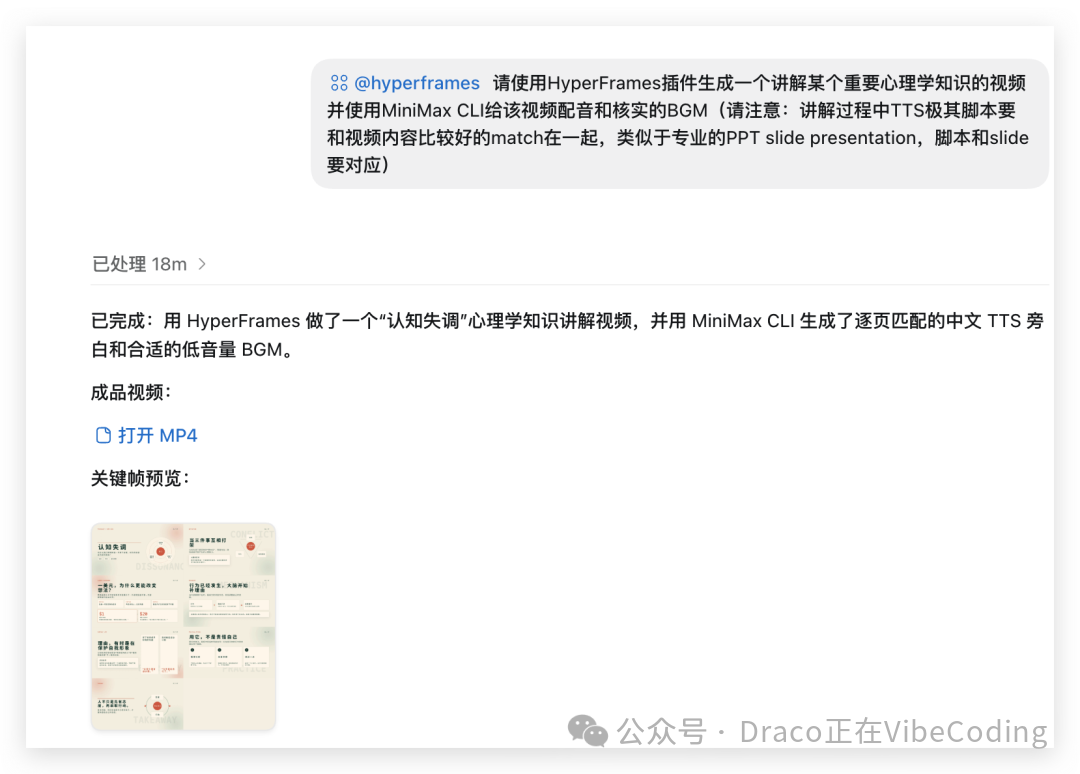
当然,用 Remotion 也能实现类似的功能,不过今天我们讨论的流程全部是基于 Hyperframes 实现的。
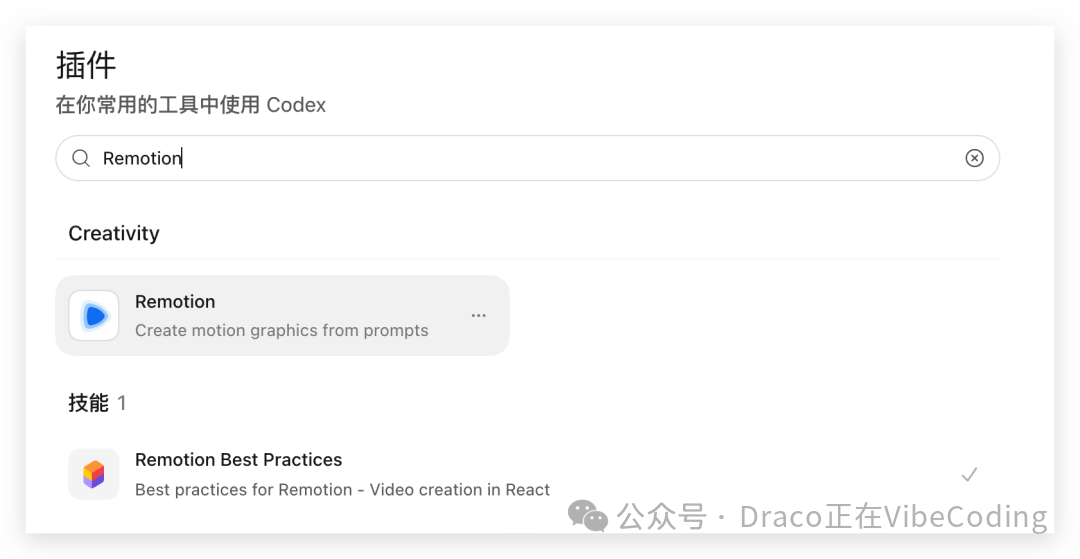
如果你要处理的内容偏数学、物理方向,还可以让 Codex 把 Manim 也整合进来。它在处理坐标、曲线等动效时,表现会更加丝滑。仓库地址是: https://github.com/3b1b/manim
无论是 Hyperframes、Remotion 还是 Manim,它们的本质都是用代码直接生成视频。强烈建议你多花些时间去了解和使用这些开源框架。它们不仅是 开源的,你不仅能在 Codex 里用,也能在任何你觉得顺手的 Agent 工具里调用。
步骤二:扩充模板库 —— Open Design
如果你觉得 Hyperframes 自带模板的丰富度还不够,可以让 Codex 引入 Open Design 这个资源库。

直接将仓库地址 https://github.com/nexu-io/open-design 发给 Codex,让它引入即可。Codex 会对这个仓库进行提炼,把适合生成 Hyperframes 视频的模板提取并保存到你的项目文件夹中。

步骤三:解决背景音乐 —— MiniMax CLI
视频的背景音乐,我们全部通过 MiniMax CLI 来生成。现在,先来安装它。你完全可以直接在对话框里要求 Codex 帮你完成 MiniMax CLI(也就是 mmx CLI)的安装。
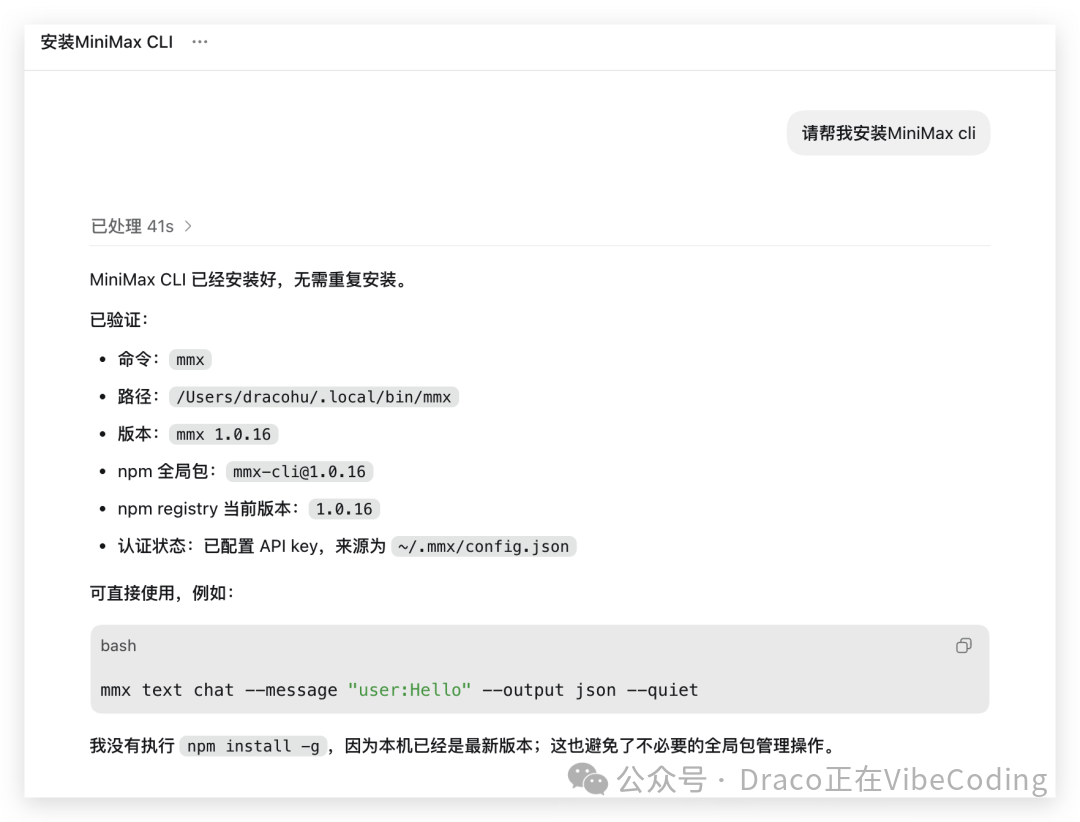
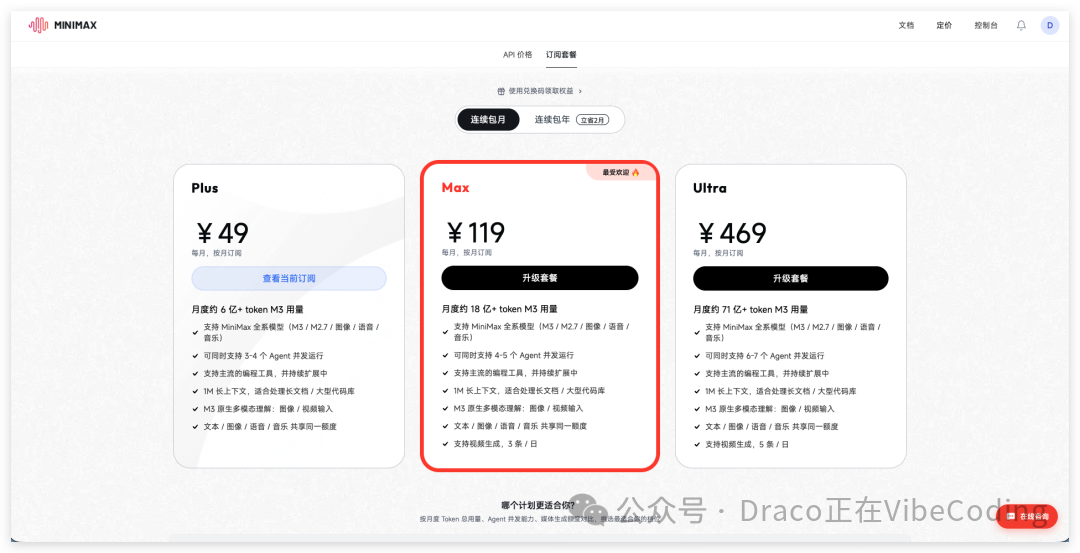
接着,你需要一个 MiniMax 的 token plan,它需支持音乐、TTS 语音和视频生成。因为我们并不需要用它的 token 来编程(毕竟已经有 Codex 了),所以直接买最便宜的、每月 ¥49 的套餐就够用了。
Token Plan 订阅地址: https://platform.minimaxi.com/subscribe/token-plan?tab=individual
开通成功后,在 Codex 所在的终端里运行下面这行命令,完成 MiniMax 账号的登录认证:
mmx auth login
注意:国内站的 API 地址是 api.minimax.com,国际站是 api.minimax.io。前面我提供的是国内站的购买地址,这里可别搞混了。
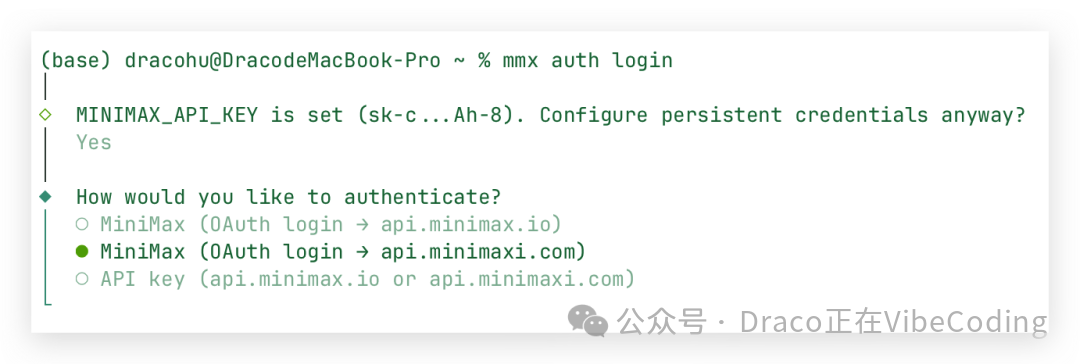
接着,在弹出的 MiniMax 网页上确认授权即可。
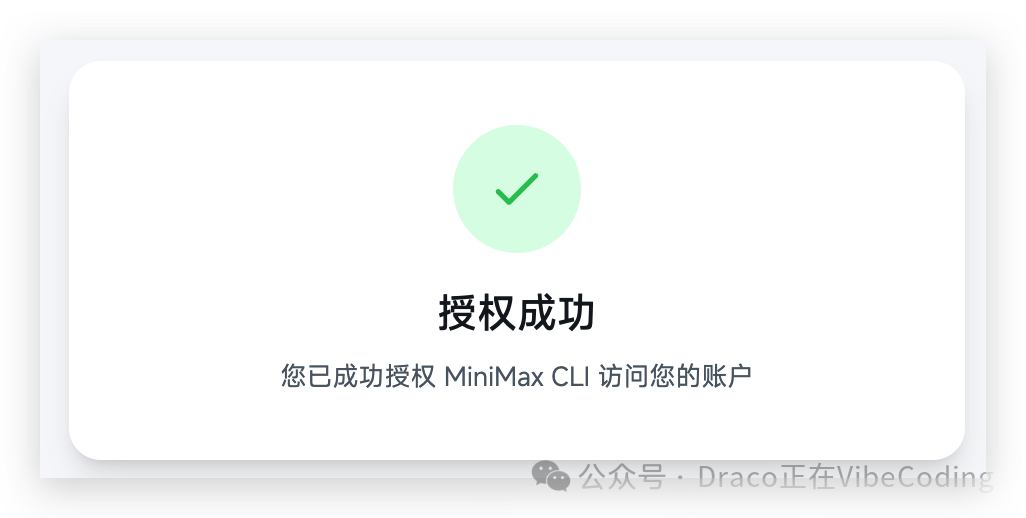
授权成功后返回终端,你就能看到 mmx 的相关信息和 token 余量了。
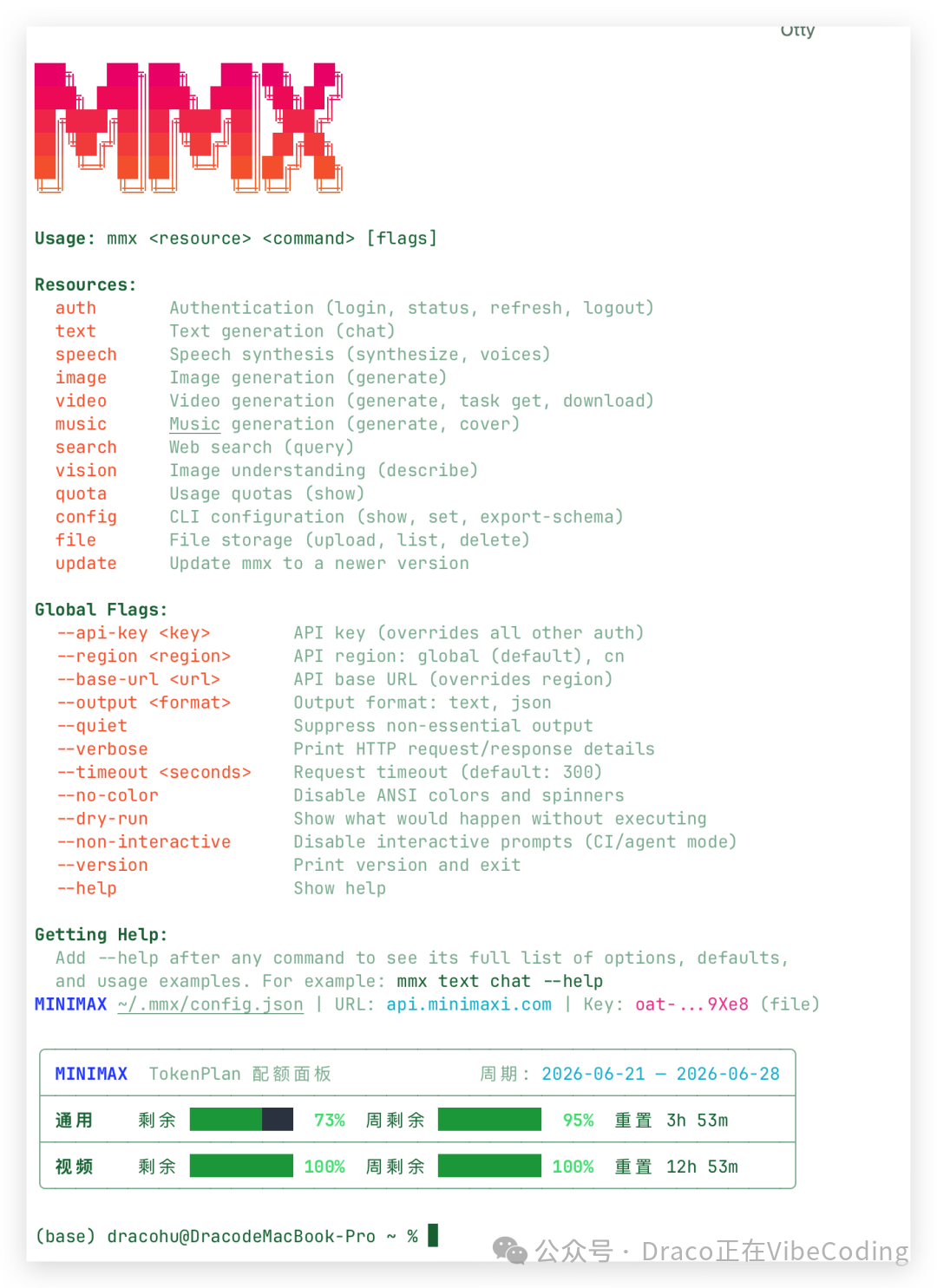
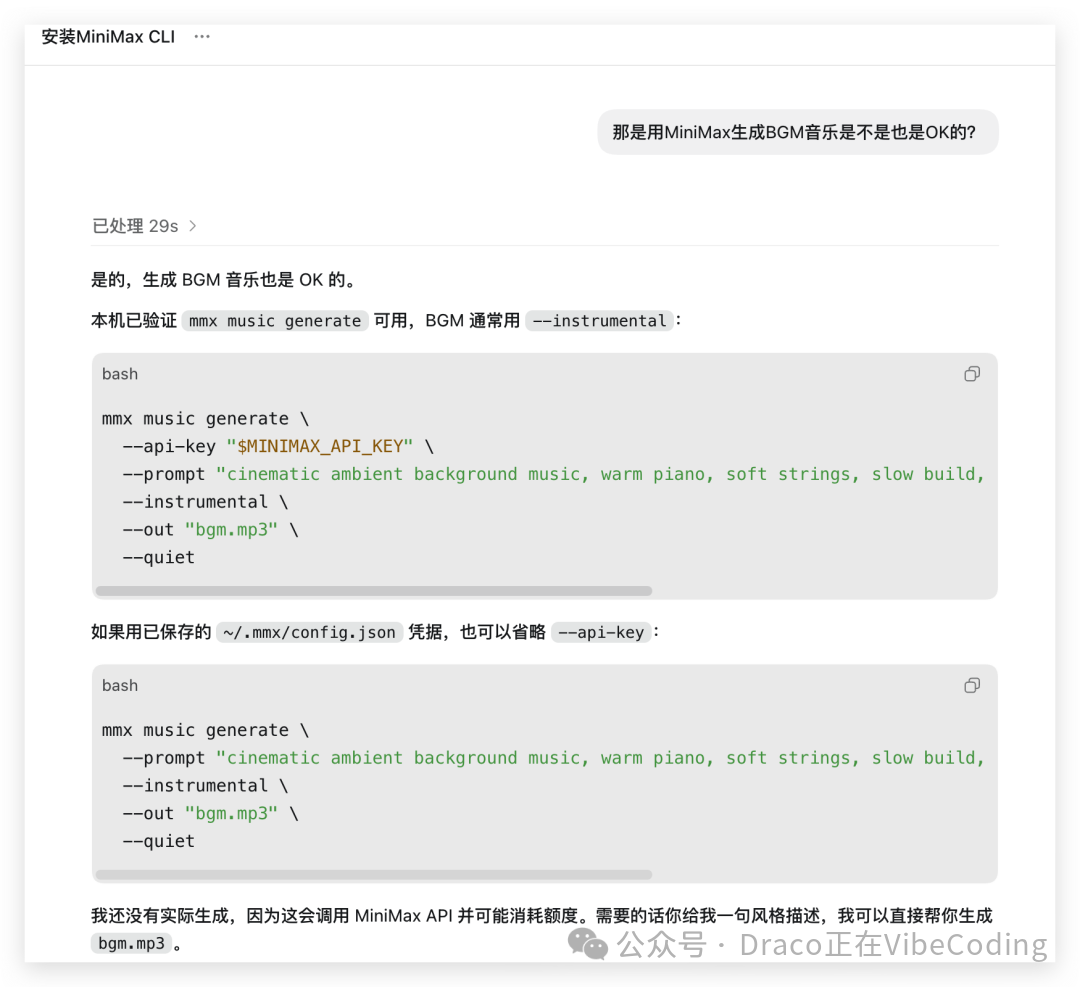
接下来,可以再让 Codex 确认一下它是否能顺利调用 mmx CLI 来生成音乐。
到这一步,你已经拥有了能生成视频的 Hyperframes 和能生成背景音乐(BGM)的 MiniMax CLI。实际上,MiniMax CLI 也能生成 TTS 语音,但听起来自然度一般。所以下一步,我们要接入一个我认为是目前自然度和性价比都最高的方案——火山引擎的 doubao-TTS-2.0。
步骤四:接入TTS语音 —— 火山引擎 doubao-TTS-2.0
首先,你得有一个火山引擎的账号,并且往里面充一点点钱。然后访问: https://console.volcengine.com/speech/app ,创建一个应用并获取 App ID。直接用默认的 default 项目也行。
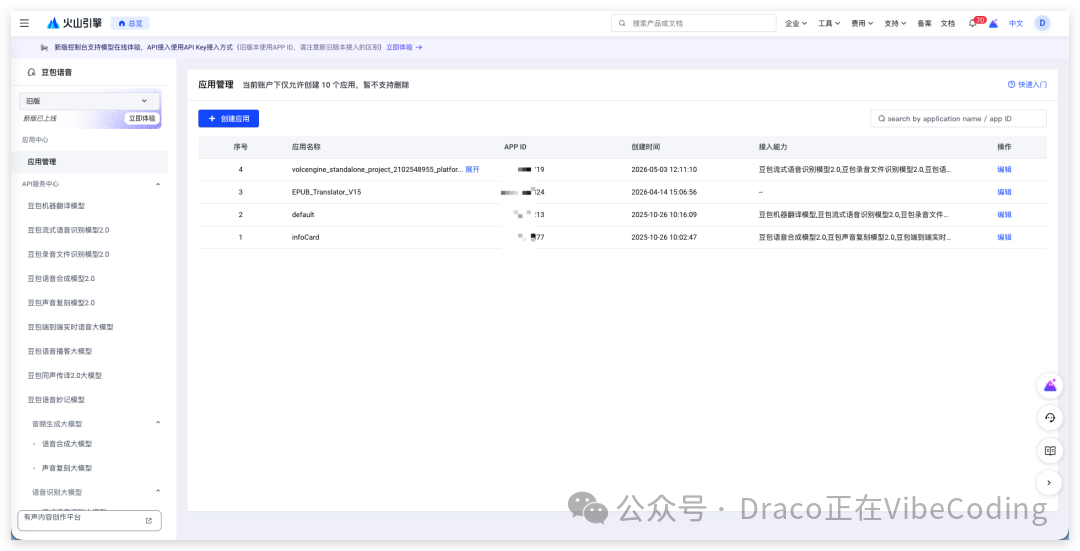
之后访问 doubao 语音页面: https://console.volcengine.com/speech/service/10035 ,开通语音合成 2.0 服务。
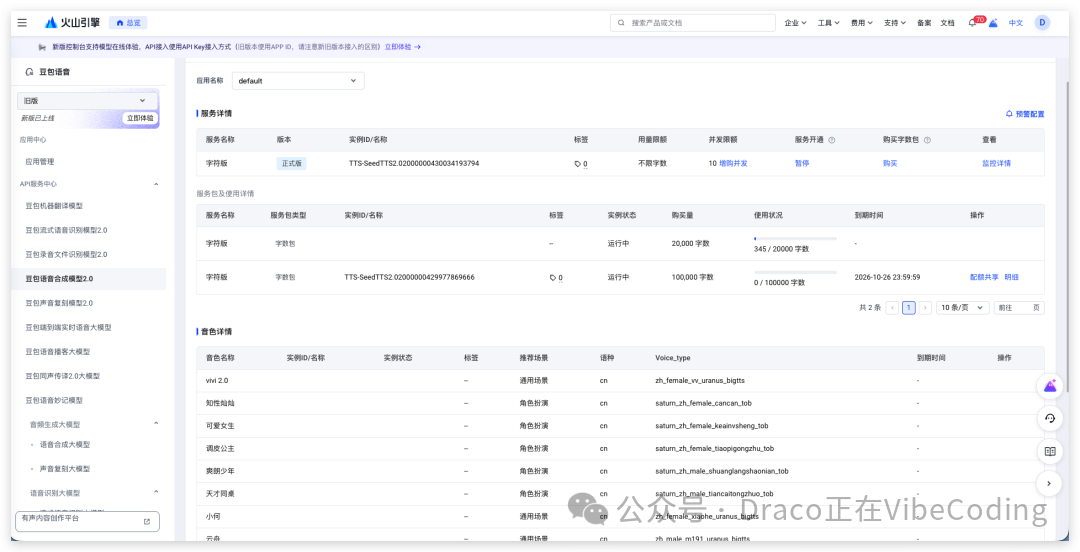
拉到页面底部,把这里的 App ID、Access Token 和 Secret Key 复制下来备用。

再访问这个地址来挑选你喜欢的音色: https://console.volcengine.com/speech/new/voices?projectName=default 。遇到喜欢的声音,就把它的 Voice ID 复制下来。
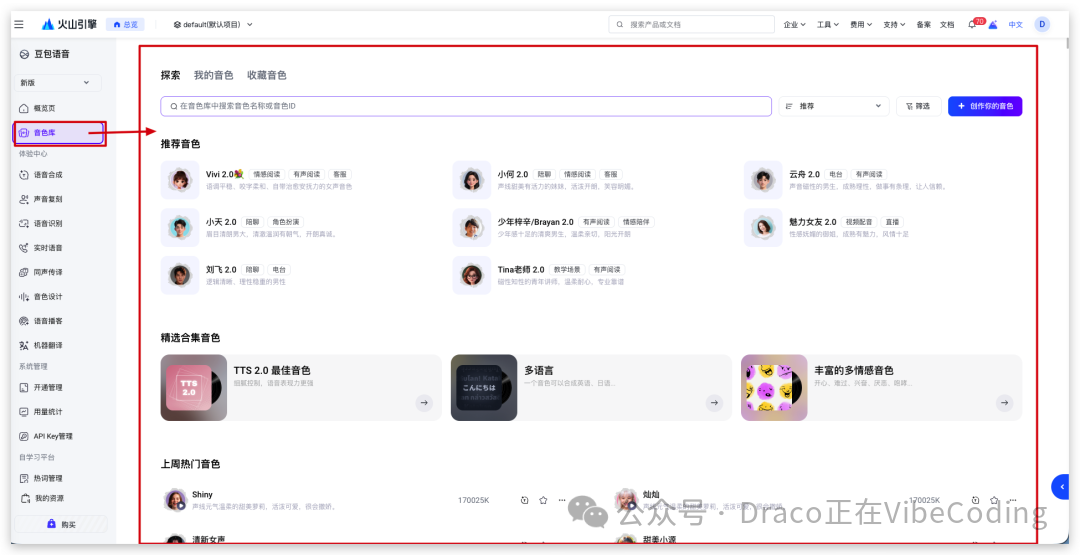
就像这样,通过菜单里的选项复制音色 ID。
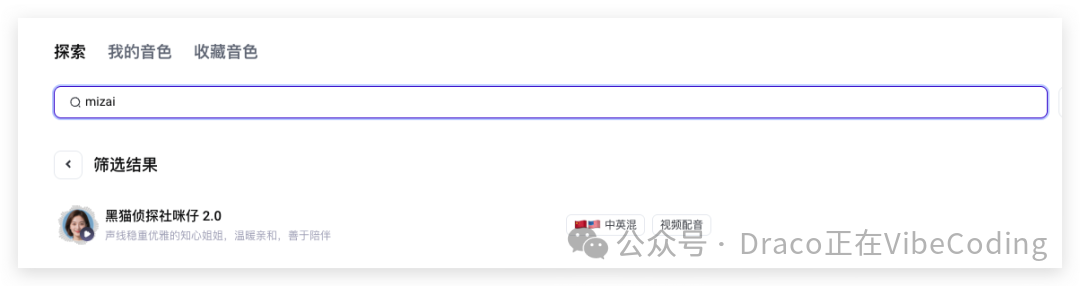
我个人比较喜欢的女性播客/对谈类音色 ID 是:zh_female_mizai_saturn_bigtts。
现在,请把以上步骤获取到的 VOLCENGINE_TTS_APP_ID、VOLCENGINE_TTS_ACCESS_TOKEN、VOLCENGINE_TTS_VOICE_TYPE 这三项写入你项目的 .env 文件中。另外,还有一个恒定值:VOLCENGINE_TTS_RESOURCE_ID="seed-tts-2.0"。
接下来,用下面这套方法让 Codex 来帮你调通火山引擎的 TTS 2.0。你可以直接把下面的内容复制粘贴给你的 Agent 去读。
1. 准备环境变量
export VOLCENGINE_TTS_ACCESS_TOKEN="你的 Access Token"
export VOLCENGINE_TTS_APP_ID="你的 App ID"
export VOLCENGINE_TTS_VOICE_TYPE="你的音色 voice_type"
export VOLCENGINE_TTS_RESOURCE_ID="seed-tts-2.0"
说明:
VOLCENGINE_TTS_ACCESS_TOKEN:接口鉴权 tokenVOLCENGINE_TTS_APP_ID:火山引擎应用 IDVOLCENGINE_TTS_VOICE_TYPE:要使用的音色 IDVOLCENGINE_TTS_RESOURCE_ID:模型资源 ID,Doubao TTS 2.0 通常为 seed-tts-2.0
2. 请求地址
POST https://openspeech.bytedance.com/api/v1/tts
请求头:
Content-Type: application/json
Authorization: Bearer; <VOLCENGINE_TTS_ACCESS_TOKEN>
如果碰到 401 或 403 错误,优先检查:
- token 是否正确或已过期
Authorization 的格式是否正确- appid 与 token 是否匹配
resource_id 是否已开通权限
3. 请求体结构
核心 JSON 结构如下:
{
"app": {
"appid": "${VOLCENGINE_TTS_APP_ID}",
"token": "${VOLCENGINE_TTS_ACCESS_TOKEN}",
"cluster": "volcano_tts"
},
"user": {
"uid": "demo-user"
},
"audio": {
"voice_type": "${VOLCENGINE_TTS_VOICE_TYPE}",
"encoding": "mp3",
"speed_ratio": 1.0,
"volume_ratio": 1.0,
"pitch_ratio": 1.0,
"sample_rate": 44100
},
"request": {
"reqid": "唯一请求 ID",
"text": "要合成的文本",
"operation": "query",
"with_frontend": 1,
"frontend_type": "unitTson",
"resource_id": "${VOLCENGINE_TTS_RESOURCE_ID}"
}
}
注意:resource_id 是放在 request 对象里,而不是 audio 里。
4. curl 调用示例
REQ_ID=$(python3 - <<'PY'
import uuid
print(uuid.uuid4())
PY
)
curl -X POST 'https://openspeech.bytedance.com/api/v1/tts' \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer; ${VOLCENGINE_TTS_ACCESS_TOKEN}" \
-d @- <<JSON > response.json
{
"app": {
"appid": "${VOLCENGINE_TTS_APP_ID}",
"token": "${VOLCENGINE_TTS_ACCESS_TOKEN}",
"cluster": "volcano_tts"
},
"user": {
"uid": "demo-user"
},
"audio": {
"voice_type": "${VOLCENGINE_TTS_VOICE_TYPE}",
"encoding": "mp3",
"speed_ratio": 1.0,
"volume_ratio": 1.0,
"pitch_ratio": 1.0,
"sample_rate": 44100
},
"request": {
"reqid": "${REQ_ID}",
"text": "你好,这是火山引擎 TTS 合成测试。",
"operation": "query",
"with_frontend": 1,
"frontend_type": "unitTson",
"resource_id": "${VOLCENGINE_TTS_RESOURCE_ID}"
}
}
JSON
接口调用成功后,会返回 base64 编码的 MP3 数据。
5. 返回值处理
一个成功的响应大概是这样的:
{
"code": 3000,
"message": "Success",
"data": "base64-encoded-mp3",
"reqid": "..."
}
把 data 字段解码后,就能写入 MP3 文件了:
python3 - <<'PY'
import base64, json
from pathlib import Path
result = json.loads(Path('response.json').read_text())
if result.get('code') != 3000 or not result.get('data'):
raise SystemExit(f"TTS failed: {result}")
Path('demo.mp3').write_bytes(base64.b64decode(result['data']))
print('saved: demo.mp3')
PY
6. Python 完整示例
import base64
import os
import uuid
from pathlib import Path
import requests
url = "https://openspeech.bytedance.com/api/v1/tts"
access_token = os.environ["VOLCENGINE_TTS_ACCESS_TOKEN"]
payload = {
"app": {
"appid": os.environ["VOLCENGINE_TTS_APP_ID"],
"token": access_token,
"cluster": "volcano_tts",
},
"user": {
"uid": "demo-user",
},
"audio": {
"voice_type": os.environ["VOLCENGINE_TTS_VOICE_TYPE"],
"encoding": "mp3",
"speed_ratio": 1.0,
"volume_ratio": 1.0,
"pitch_ratio": 1.0,
"sample_rate": 44100,
},
"request": {
"reqid": str(uuid.uuid4()),
"text": "你好,这是火山引擎 TTS 合成测试。",
"operation": "query",
"with_frontend": 1,
"frontend_type": "unitTson",
"resource_id": os.environ.get("VOLCENGINE_TTS_RESOURCE_ID", "seed-tts-2.0"),
},
}
resp = requests.post(
url,
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer; {access_token}",
},
json=payload,
timeout=60,
)
resp.raise_for_status()
result = resp.json()
if result.get("code") != 3000 or not result.get("data"):
raise RuntimeError(f"TTS failed: {result}")
Path("demo.mp3").write_bytes(base64.b64decode(result["data"]))
print("saved: demo.mp3")
再强调一遍,以上内容都是给 Codex 读的,你完全不必自己通读或弄懂它们。
好了,现在你的 .env 里已经有了环境变量配置,也有了火山的接入方法。让 Codex 去完成最后的配置吧,通常一两分钟,TTS 语音接口就能调通。

步骤五:搞定封面图 —— Codex 自带的 image_gen
因为 Codex 搭载了 GPT-Image-2 模型,所以,如果你希望内容能在小红书或视频号上获得更好的传播,我建议直接让 Codex 用 image_gen 来生成封面。

当然,如果你用的不是原生 Codex,没有 GPT-Image-2 能力也没关系。你完全可以让 Codex 用代码来绘制封面,或者进一步接入即梦等国内的绘图模型来实现。这些方案就不在本文展开了。
如果你已经一步步走到这里,那么恭喜你,你的 Codex 已经化身为 NoteBookLM 的绝佳平替了!你可以在几分钟内,将任何知识点或材料,转化成生动的视频解读。
这当然只是个起点。如果你使用的是原生的 Codex,并拥有 GPT-Image-2 的能力,你还能更进一步——用 AI 生成的图片替代 Hyperframes 里由代码绘制的页面,从而制作出类似下面这样视觉冲击力更强的视频,甚至是播客内容。
再次呼应一下本文的开篇,在最近深度使用 Codex 的日子里,我仿佛窥见了 AI Agent 时代,理想的教育应该是什么样子的。我会在未来的文章里,继续和大家分享我的思考与实践,敬请期待。
 发表于 3 小时前
|
查看: 5|
回复: 0
发表于 3 小时前
|
查看: 5|
回复: 0
