在 Go 语言中,启动一个 Goroutine 的代价极其低廉(初始仅需约 2KB 内存)。然而,“低廉”并不意味着“无节制”。在海量高并发场景下,无限制地并发创建 Goroutine 会导致内存暴涨、CPU 频繁切换,甚至因触及系统资源上限而引发 OOM(内存溢出)。
为了让高并发程序运行得更加平稳,协程池(Goroutine Pool) 成了每位 Go 程序员必须掌握的进阶利器。
一、核心价值:为什么我们需要协程池?
引入协程池,主要为了解决以下三大核心痛点:
- 控制并发上限,防止系统崩溃:协程池可以严格限制同时运行的 Goroutine 数量。即使面对百万级的突发请求,也能通过队列进行削峰填谷,确保系统在安全边界内运行。
- 复用 Goroutine,降低复利开销:避免频繁创建和销毁 Goroutine 带来的运行时开销,重复利用已存在的工作协程,减轻 GC(垃圾回收)的压力。
- 优雅的任务调度与排队:当并发任务超过处理能力时,协程池提供缓冲区(Channel)让任务安全排队,并按照既定策略分发给空闲的 Worker,实现任务的平滑消费。
二、架构设计:协程池的运转模型
一个标准的 Go 协程池通常由以下四个核心要素构成:
- Task(任务对象):封装了具体业务逻辑的实体,通常包含一个唯一的任务 ID 和实际执行的函数指针。
- Pool(协程池管理器):核心控制器,负责初始化指定数量的 Worker,维护任务缓冲队列,并控制整个池子的生命周期(如安全关闭)。
- Task Queue(任务队列):一般由 带缓冲的 Channel 充当,承载外部提交但尚未被消费的任务。
- Worker(工作协程):池子内部常驻的“常青树” Goroutine,它们通过循环不断地从任务队列中提取 Task 并执行。
工作流图解:外部调用者 → 提交 Task → 任务缓冲队列(Buffered Channel)→ 多个常驻 Worker 竞争消费 → 执行业务逻辑
三、实战演练:生产级协程池实现
以下是一份经重构后、符合 Go 语言工程实践的协程池实现方案。代码修正了原版中无缓冲阻塞的隐患,并加入了真正的 Worker 编号追踪:
package main
import (
"fmt"
"sync"
"time"
)
// Task 定义了任务结构体
type Task struct {
ID int
Job func() // 实际需要执行的业务逻辑
}
// Pool 定义了协程池结构体
type Pool struct {
taskQueue chan Task // 任务缓冲队列
wg sync.WaitGroup // 用于等待所有常驻 Worker 优雅退出
}
// NewPool 创建并初始化协程池
// numWorkers: 允许常驻的工作协程数量
// queueSize: 任务队列的缓冲区大小
func NewPool(numWorkers int, queueSize int) *Pool {
p := &Pool{
taskQueue: make(chan Task, queueSize), // 使用带缓冲的 Channel,防止提交任务时瞬间阻塞
}
p.wg.Add(numWorkers)
// 预先启动指定数量的常驻工作协程
for i := 1; i <= numWorkers; i++ {
go p.worker(i)
}
return p
}
// AddTask 向协程池提交一个任务
func (p *Pool) AddTask(task Task) {
p.taskQueue <- task
}
// worker 是内部常驻的工作协程逻辑
func (p *Pool) worker(workerID int) {
defer p.wg.Done()
// 通过 range 持续监听并消费通道中的任务,直到通道被关闭
for task := range p.taskQueue {
fmt.Printf("[Worker %d] 开始执行任务 %d\n", workerID, task.ID)
task.Job() // 执行具体的业务内容
fmt.Printf("[Worker %d] 任务 %d 执行完毕\n", workerID, task.ID)
}
}
// Shutdown 优雅关闭协程池
func (p *Pool) Shutdown() {
close(p.taskQueue) // 关闭任务队列,通知所有 Worker 停止接收新任务
p.wg.Wait() // 等待正在运行的 Worker 将手中剩余的任务处理完毕
}
func main() {
// 初始化一个包含 3 个工作协程、队列容量为 5 的协程池
pool := NewPool(3, 5)
// 模拟并发提交 10 个耗时任务
for i := 1; i <= 10; i++ {
taskID := i
task := Task{
ID: taskID,
Job: func() {
// 模拟业务处理耗时
time.Sleep(100 * time.Millisecond)
},
}
pool.AddTask(task)
}
// 所有任务提交完毕后,优雅关闭协程池
pool.Shutdown()
fmt.Println("成功:所有任务处理完毕,主程序平滑退出。")
}
四、行业应用场景
在实际的企业级开发中,协程池被广泛应用于以下场景:
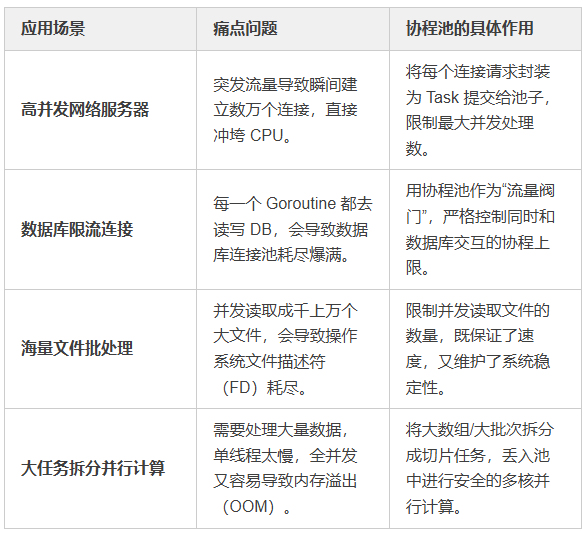
总结
在 Go 语言中,绝大多数简单的异步场景直接使用 go func() 即可完美胜任。但当面对 大规模、高突发、长生命周期 的复杂业务时,合理地引入协程池,可以帮助我们做到对系统资源的“精准把控”。
掌握协程池的设计与应用,是编写出高可用、工业级 Go 程序的必经之路。
关于协程池的更多优化技巧和 Go 高并发实践,欢迎访问 云栈社区 一起交流。 |  发表于 昨天 03:24
|
查看: 10|
回复: 0
发表于 昨天 03:24
|
查看: 10|
回复: 0
