随着开发工作流日趋复杂,你可能已经体会到:手里工具多,不等于效率高。为了完成一个任务,大量时间往往花在工具间来回跳转、反复敲相同命令、对接各种 API,或独自梳理多环节工作流上。
多数工具生来只为执行命令,而非与你协作。于是,你依然得靠自己统筹全局——在工具间切换、处理每一步骤、维持流程秩序。
而 Agentic AI 工具 的出现改变了这一切。它们不单是响应指令,更能理解任务、与代码库深度交互,帮你用更少的手动操作,把多步骤任务自动化。
下面,我们来看看一批正在推动这一理念向前演进的现代 Agentic 工具。
1. Goose 🦢

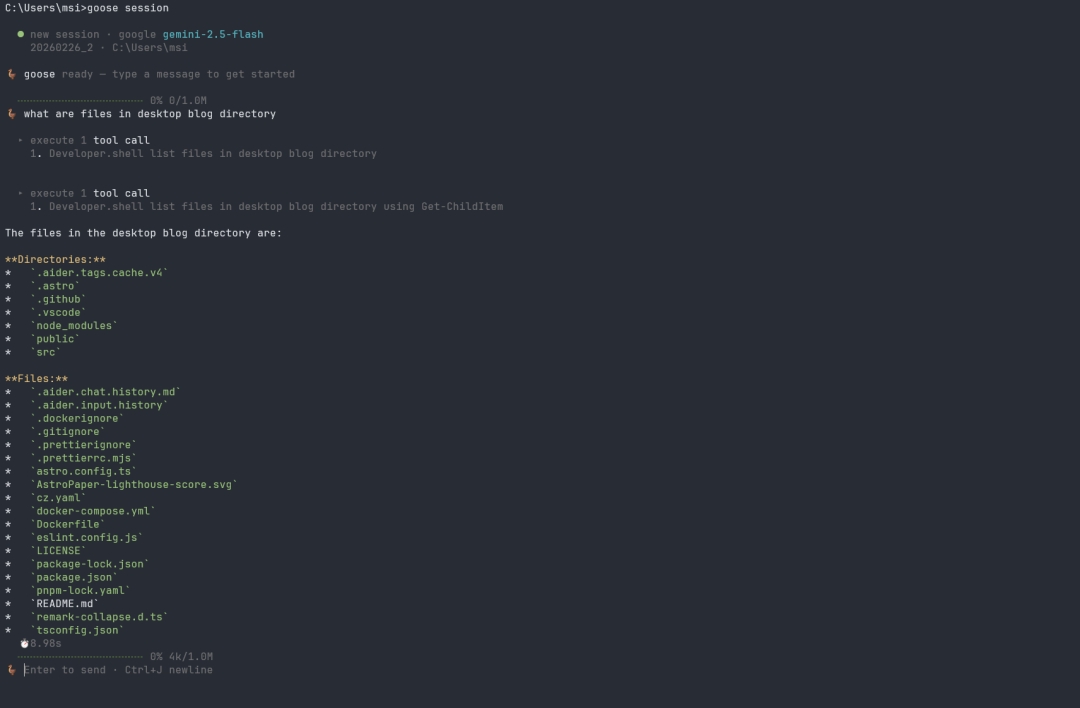
Goose 是一个完全自主的开发者 agent,直接运行在你的本机上。它通过 toolkits 实现高度可扩展。跟标准 chatbot 不同,Goose 能执行 shell 命令、编辑文件,并直接与 Jira、GitHub 等外部 API 交互。
最适合 🎯
- 自行处理代码重构、运行测试等任务。
- 学习并遵循你的自定义工作流。
- 理解整个代码库,而非局限于单个文件。
不适合的场景 ⛔
- 避免在敏感生产环境中使用,因为直接运行命令仍有风险。
- 对于快速提问而言,它显得过于重型。
https://github.com/aaif-goose/goose
2. Claude Code ⚡
Claude Code 是一款 CLI 工具,它让 Claude 3.7 及更新版本可以直接运行在你的 shell 中。它有权限执行终端命令、运行测试,并自行编辑文件。在尝试修改任何一行代码前,它会利用 Extended Thinking 预先规划复杂的重构。
最适合 🎯
- 非常适合需要谨慎推理的复杂重构。
- 非常适合 Vim 或 Neovim 这类 terminal-first 工作流。
- 有助于快速理解新代码库并上手。
不适合的场景 ⛔
- 预算紧张时不适用——它调用的是昂贵的模型,Token 消耗很快。
- 如果你习惯手动批准每一个细小的改动,它并不完美。
https://github.com/anthropics/claude-code
3. Repomix 📦
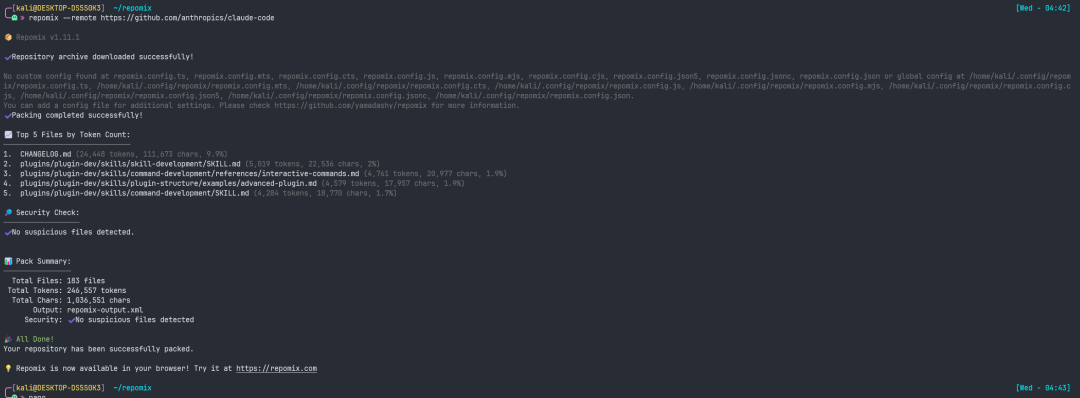
Repomix 是一款专为 Context Window 而生的工具。它会遍历整个项目、遵循你的 .gitignore,把代码库压缩成一个面向 AI 优化的文本文件。同时附上文件树与元数据,让 LLM 无需多问就能准确理解 utils.py 如何导入到 main.py 中。
repomix --remote https://github.com/yamadashy/repomix
最适合 🎯
- AI 需要审视完整项目时,非常适合用于大型重构。
- 非常适合用你的项目结构来初始化新的 AI session。
- 适合依据代码生成完整文档,比如 README。
不适合的场景 ⛔
- 无法处理体量过大的代码库。
- 不要上传
.env 或 secrets 等敏感文件。
- 对于小修小补或单函数调试来说,显得过于重型。
https://github.com/yamadashy/repomix
4. ScreenPipe 📼
大多数 AI agent 其实看不到你在电脑上具体在做什么。ScreenPipe 改变了这一点,它全天候录制你的屏幕和音频,并在本地处理后存入你机器上的数据库。它相当于给 AI 装上了眼睛和耳朵,让你能提出诸如“三小时前我看到的那个报错是什么?”或者“根据音频,总结一下我刚才的会议”这样的问题。
最适合 🎯
- 找回遗忘的代码片段、文档或消息。
- 从系统音频生成会议摘要。
- 构建能理解你当前屏幕内容的 agent。
不适合的场景 ⛔
- 磁盘空间紧张的机器请避开:录制内容会持续累积。
- 不适合明令禁止屏幕录制的严格企业环境。
- 如果你追求完全隐私,即使是本地处理,也应避免录到高度敏感数据。
https://github.com/screenpipe/screenpipe
5. Rivet 🔗
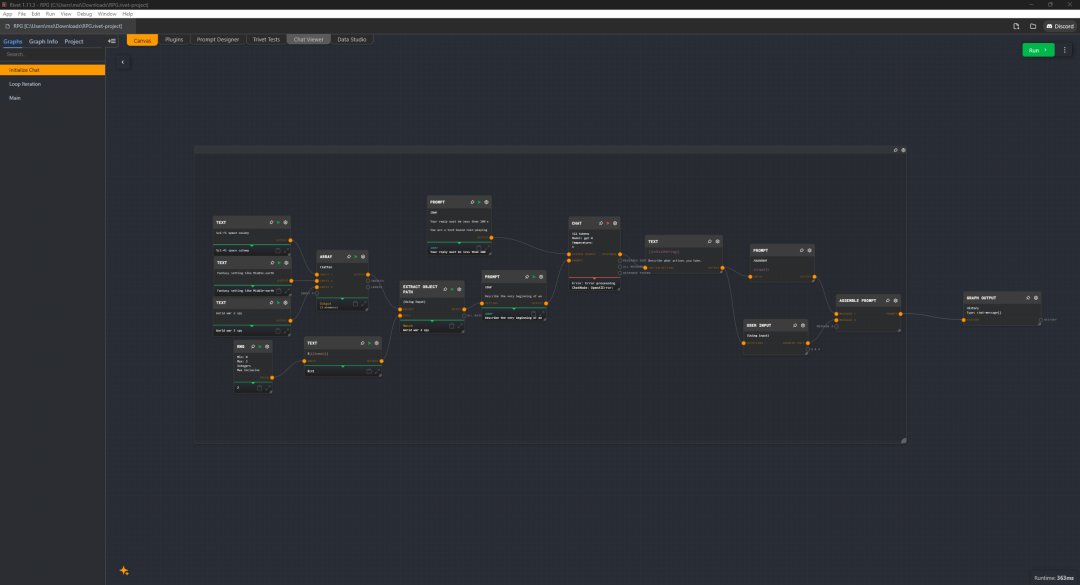
Rivet 是 Ironclad 为复杂 LLM 操作构建的开源可视化编程环境。它把你的 AI 逻辑呈现为节点图,让你能构建复杂的 prompt 链、逻辑门和数据转换。你可以实时观察数据在连线中流动,精准定位 agent 在哪个环节“跑偏”了。
最适合 🎯
- 可视化那些包含大量决策与 API 调用的复杂逻辑。
- 非常适合让非开发人员安全地调整 prompts。
- 适合追踪并调试每个节点的输入与输出。
不适合的场景 ⛔
- 对于简单的一次性任务来说,过于重型。
- 不适合偏好纯代码、不爱可视化工具的开发者。
https://github.com/Ironclad/rivet
6. Flowise 🦜
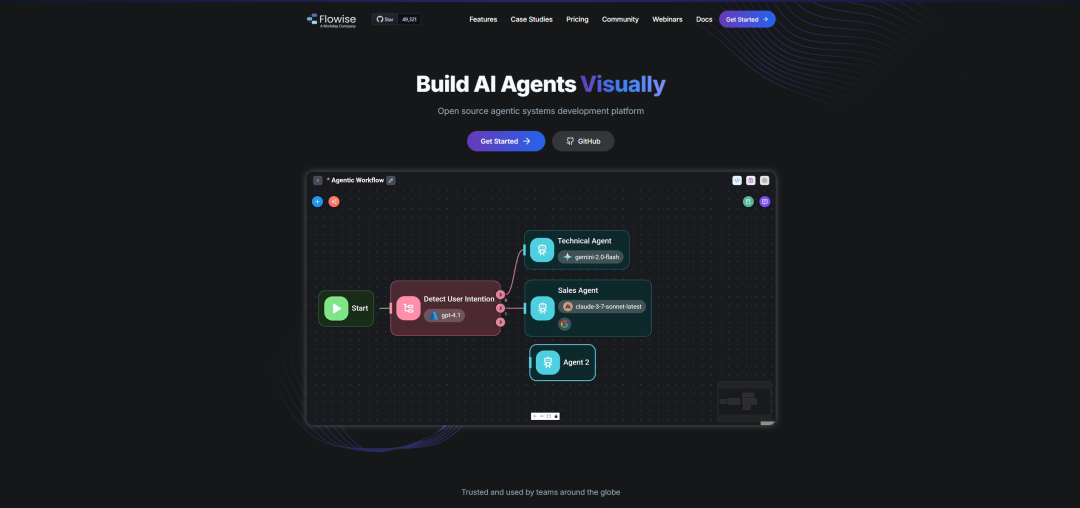
亲手从零搭建过 LangChain 应用就会知道,样板代码很快就会变得混乱不堪。Flowise 就是面向 LangChain(现在也支持 LlamaIndex)的开源可视化界面。你只需要拖放组件——PDF loaders、Vector Stores、Embeddings 和 LLMs——用线把它们连起来,就能立刻将整条 chain 暴露为一个简洁的 API endpoint。它将数小时的编码工作,变成了几分钟的连线游戏。
最适合 🎯
- 非常适合快速原型设计“与 PDF 聊天”的 bot。
- 非常适合非程序员在不碰代码的情况下调整 prompts。
- 适合从可视化逻辑直接部署 API。
不适合的场景 ⛔
- 由于存在轻微的可视化开销,不适合超低延迟需求。
- 对于 chain 内部需要高度自定义逻辑的情况,可能会有限制。
- 如果你不喜欢 LangChain 那种高度抽象的方式,它也不合适。
https://github.com/FlowiseAI/Flowise
7. Portkey 🔑
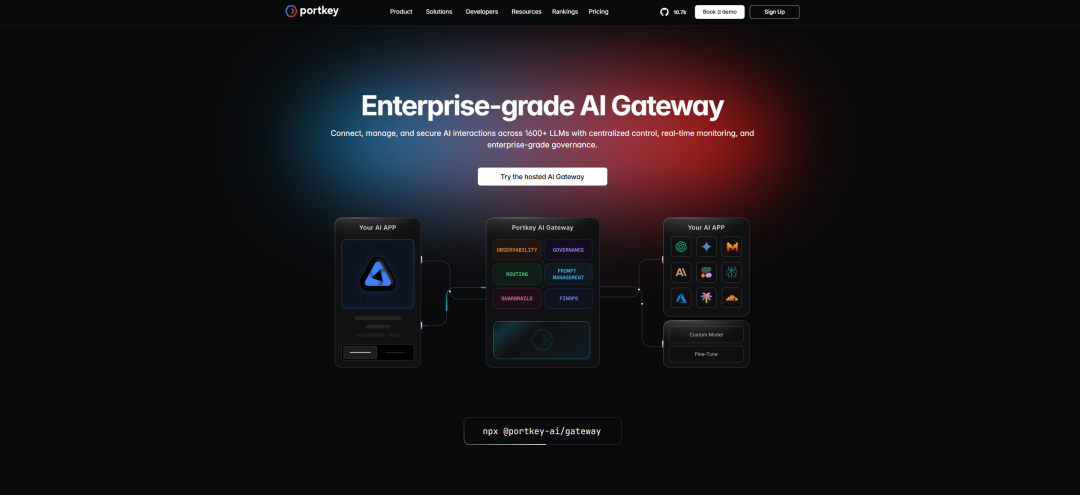
可以把 Portkey 想象成一个智能路由器,它横在你的代码与各 LLM 服务商之间。一旦 OpenAI 宕机,Portkey 会立刻检测到,并毫发无伤地把流量重新路由到另一个服务商,避免应用崩溃。它会自动处理重试、缓存和降级切换,让你的 agent 立刻具备生产级韧性。
最适合 🎯
- 就算主要服务商宕机,也能保持应用在线。
- 非常适合路由 prompts,以求在成本与速度间取得平衡。
- 适合在一个 dashboard 中跟踪 requests、costs 和 latency。
不适合的场景 ⛔
- 对于宕机时间不是关键问题的小型应用来说,过于重型。
- 如果你的 prompts 只适用于单一服务商,它就帮不上什么忙。
https://github.com/portkey-ai/gateway
8. Warp ⚡
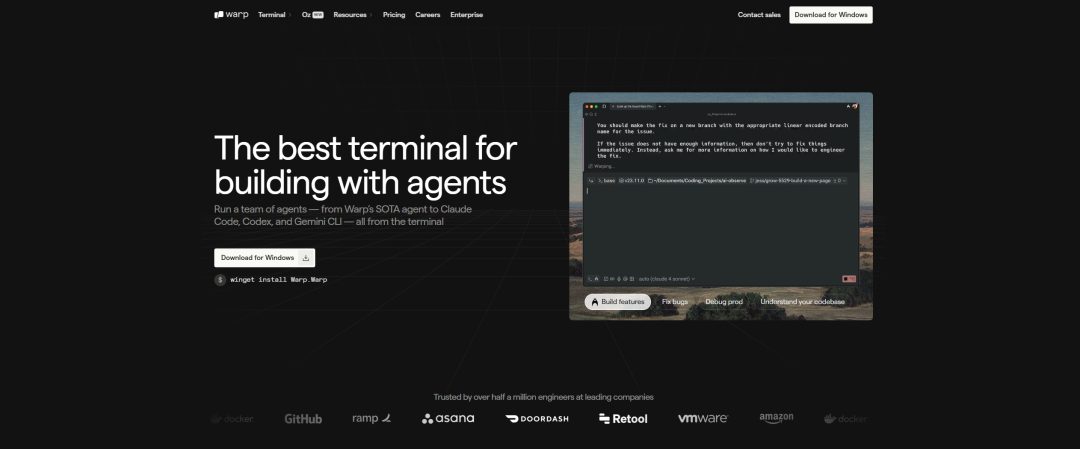
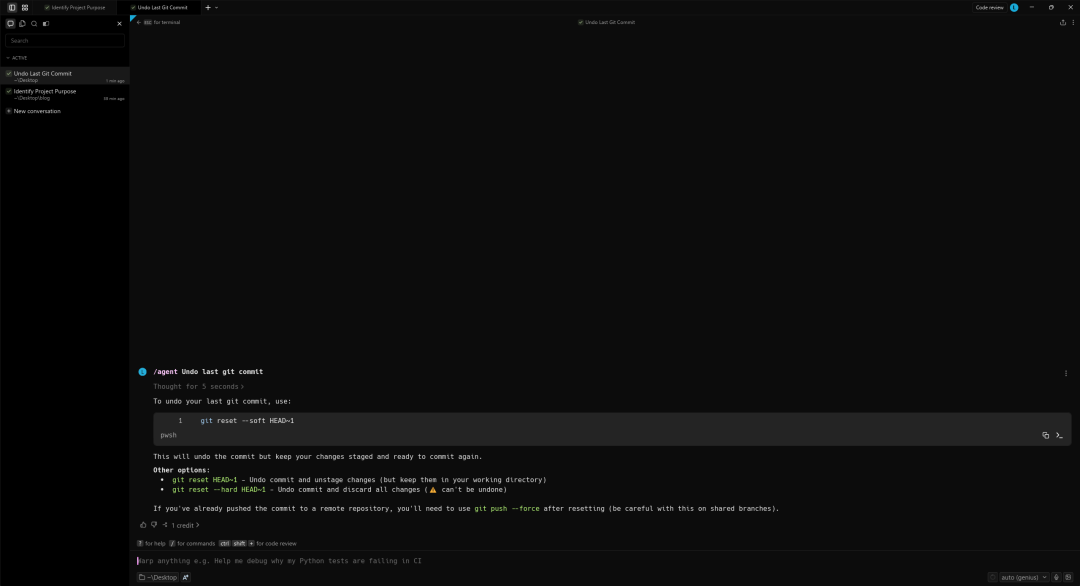
Warp 是一款用 Rust 构建的终端应用,但它的体验更偏向现代文本编辑器,而非传统终端。在多数终端里,所有内容都汇成一长串文本流,很难管理。Warp 则把每个命令及其输出整理成清晰的区块,称为 Blocks。这让阅读、复制、编辑和分享工作内容都变得更轻松。
Warp 还在命令行里内置了 AI。你不需要离开终端去搜诸如“how to untar a file”这样的问题,直接输入,Warp 就能理解你想做什么,并给出正确的命令建议。
最适合 🎯
- 非常适合不想死记命令参数 flags 的开发者。
- 适合 DevOps 和 SRE 轻松分享命令与输出。
不适合的场景 ⛔
- 不适合那些不想安装额外二进制文件的远程服务器纯粹主义者。
- 不适合严格离线或 air-gapped 的环境。
- 对于熟悉原生 keybindings 的重度 Vim/Tmux 用户,部分人可能会觉得操作不顺手。
https://www.warp.dev/
9. Aider 🤖
Aider 是一个强大的 CLI 工具,让你在本地的 Git 仓库中直接与现代 LLM 进行实实在在的结对编程(pair programming)。
Aider 不只是生成代码片段,而是构建结构化的 Map 来理解整个代码库。它可以在单次会话中修改多个文件,并自动为它所做更改生成干净、有意义的 commit messages。
最适合 🎯
- 适合独立开发者快速构建完整的 MVP 功能。
- 适合修复横跨多个文件的 linting 或 test 报错。
- 当你希望获得尊重 .gitignore 的干净 Git 集成时,再合适不过。
不适合的场景 ⛔
- 如果你偏爱可视化工具,那它就不合适。
- 对于需要搞懂每个修复细节的初学者,这也不是最佳选择。
- 避免在没有适当范围限定或过滤的情况下,加载超大体量的仓库。
https://github.com/Aider-AI/aider
10. Khoj 🧠
Khoj 是一个开源的、能索引你的 Obsidian、Emacs、Notion 以及 PDF 文件的个人 AI 助理。它在静态生产力工具与主动型 Agentic AI 之间架起桥梁。你再也不用大海捞针般搜索文件了——只需向 Khoj 提问,它就会立刻从你的笔记中检索出上下文。
最适合 🎯
- 非常适合使用原生编辑器插件的 Obsidian 和 Emacs 高级用户。
- 非常适合将知识完全保留在本地的 privacy-first 工作流。
- 适合在旧笔记与项目之间,建立意想不到的关联。
不适合的场景 ⛔
- 它并非为重度编码任务而设计。
- 除非你使用云端版本,否则需要自己动手配置,并且得有不错的硬件。
https://github.com/khoj-ai/khoj
虽然这些工具中的一部分仍处于早期开发阶段,但它们已经让我们得以窥见未来的一角:软件在开发过程中,将不再只是被动的工具,而是更像主动的协作者。
我们在 云栈社区 中也常常探讨这类趋势——当工具变得足够聪明,开发者的角色重心又会转向何方?这或许值得每个技术人思考。
 发表于 2 小时前
|
查看: 5|
回复: 0
发表于 2 小时前
|
查看: 5|
回复: 0
